
このドキュメントは、Apache Kafka ワークロードを Google Cloud内のマネージド サービスである Google Cloud Managed Service for Apache Kafka に移行する際に役立ちます。
Managed Service for Apache Kafka を使用すると、 Google Cloudで Apache Kafka を実行できます。このドキュメントのソリューションでは、外部の Apache Kafka クラスタから Managed Service for Apache Kafka クラスタにデータを移行します。
Managed Service for Apache Kafka の詳細については、Managed Service for Apache Kafka の概要をご覧ください。
この移行には、Apache Kafka MirrorMaker 2.0 を使用することをおすすめします。
MirrorMaker 2.0 は、Apache Kafka クラスタ間でデータをリアルタイムに複製するツールです。データ移行、障害復旧、データ分離、データ集約に使用できます。
MirrorMaker 2.0 の詳細については、次のセクションをご覧ください。
MirrorMaker 2.0 とは
MirrorMaker 2.0 は、Kafka Connect フレームワークを使用して Kafka クラスタ間でデータを複製します。Kafka Connect は、Kafka クラスタと他のシステム間でデータをストリーミングするためのフレームワークです。スケーラブルで信頼性の高いパイプラインとして機能します。このフレームワークにより、すぐに使用できるコネクタを使用して、Kafka とデータベース、メッセージ キュー、オンライン ストレージなどのさまざまな外部システムとの統合が簡素化されます。MirrorMaker 2.0 を使用できるシナリオの例を次に示します。
データ移行: このガイドで説明するように、Kafka ワークロードを新しいクラスタに移動します。
障害復旧: 障害が発生した場合にビジネスの継続性を確保するために、バックアップ クラスタを作成します。
データ分離: 機密データをプライベート クラスタで安全に保ちながら、トピックをパブリック クラスタに選択的に複製します。
データ集約: 分析目的で、複数の Kafka クラスタのデータを中央クラスタに統合します。
MirrorMaker 2.0 は Kafka バージョン 2.4.0 以上をサポートしており、次の主な機能を提供します。
包括的なレプリケーション: トピック、データ、構成、オフセットを含むコンシューマー グループ、ACL など、必要なすべてのコンポーネントを複製します。
パーティションの保持: 移行先のクラスタで同じパーティショニング スキームを維持し、アプリケーションの移行を簡素化します。
トピックとパーティションの自動作成: 新しいトピックとパーティションを自動的に検出して複製し、手動構成を最小限に抑えます。
モニタリング機能: エンドツーエンドのレプリケーション レイテンシなどの重要な指標を提供し、レプリケーション プロセスの健全性とパフォーマンスを追跡できます。
フォールト トレランスとスケーラビリティ: 大量のデータでも信頼性の高いオペレーションを保証し、ワークロードの増加に対応するために水平方向にスケーリングできます。
堅牢性のための内部トピック: オフセット同期、チェックポイント、ハートビートに内部トピックを使用します。これらのトピックには、高可用性とフォールト トレランスを確保するための構成可能なレプリケーション ファクタ(
offset.syncs.topic.replication.factorなど)があります。
MirrorMaker 2.0 には次の 2 つのデプロイモードがあります。
専用クラスタ モード: MirrorMaker 2.0 はスタンドアロン クラスタとして実行され、独自のワーカーを管理します。このドキュメントでは、このモードに焦点を当て、デプロイと構成の実用的な例を示します。
Kafka Connect クラスタモード: MirrorMaker 2.0 は、既存の Kafka Connect クラスタ内のコネクタとして実行されます。
大まかなワークフロー
次の図は、MirrorMaker 2.0 を使用してソース Apache Kafka クラスタから Managed Service for Apache Kafka クラスタにデータを移行するアーキテクチャを示しています。
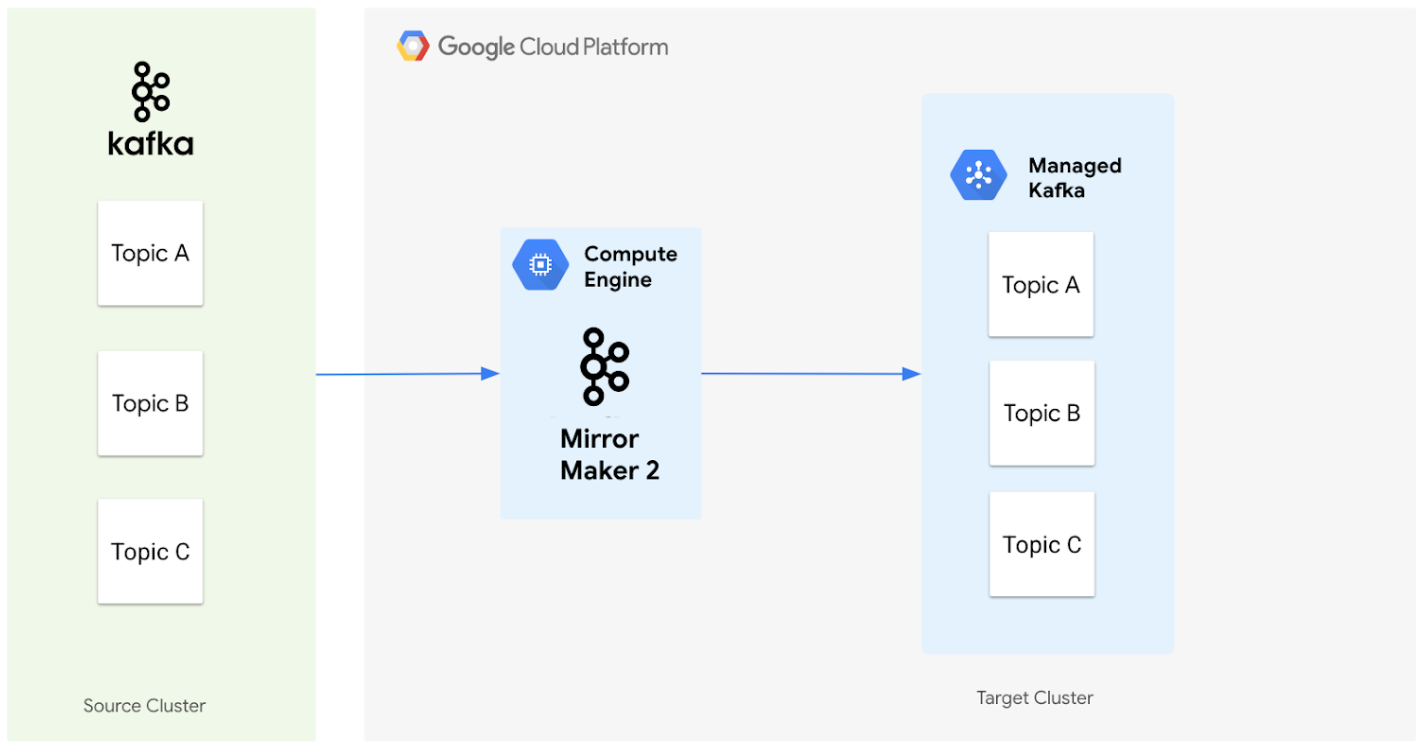
コンポーネントが連携して動作する仕組みは次のとおりです。
ソースクラスタ: オンプレミスまたは別のクラウド環境に配置できる既存の Apache Kafka クラスタを表します。移行するトピックが含まれています。この図では、ソース Apache Kafka クラスタにトピック A、B、C の 3 つのトピックが含まれています。
MirrorMaker 2.0: このコア コンポーネントは、専用の MirrorMaker 2.0 クラスタとして Compute Engine VM にデプロイされ、ソース Apache Kafka クラスタからターゲット Managed Service for Apache Kafka クラスタにデータを積極的に複製します。また、ターゲット クラスタに対応するトピックとパーティションが存在しない場合は、ソースクラスタの設定をミラーリングして、それらを自動的に作成します。
ターゲット クラスタ: Managed Service for Apache Kafka クラスタです。MirrorMaker 2.0 により、トピックとパーティションがソース環境に合わせて作成されるため、Kafka データの新しいホームになります。
移行プロセスの大まかなワークフローは次のとおりです。
初期評価
クラスタのサイズ、トピック、スループット、コンシューマー グループなど、既存の Kafka 設定を文書化します。
ダウンタイムの許容範囲やカットオーバー アプローチなど、移行の目標と戦略を計画します。
Managed Service for Apache Kafka クラスタに必要なリソースを見積もります。
準備
Managed Service for Apache Kafka クラスタを作成します。
既存の Kafka クラスタと、作成した Managed Service for Apache Kafka クラスタ間のネットワーク接続を構成します。
Google Cloud VM に MirrorMaker 2.0 をデプロイします。
移行の実行
既存の Kafka クラスタから Managed Service for Apache Kafka クラスタにデータを複製するように MirrorMaker 2.0 を構成します。
MirrorMaker 2.0 の指標を使用してレプリケーション プロセスをモニタリングします。
コンシューマーとプロデューサーを新しい Managed Service for Apache Kafka クラスタに段階的に移行します。
検証と切り替え
Managed Service for Apache Kafka クラスタでデータ整合性とアプリケーション機能を検証します。
最終的な切り替えを行い、Managed Service for Apache Kafka クラスタにトラフィックをリダイレクトします。
古い Kafka クラスタを廃止します。
移行後
Managed Service for Apache Kafka クラスタのパフォーマンスを継続的にモニタリングします。
変更を反映するようにドキュメントを確認して更新します。
移行のダウンタイムを最小限に抑える
このセクションでは、MirrorMaker 2.0 を使用してオープンソースの Kafka データを Managed Service for Apache Kafka に移行する際の考慮事項について説明します。MirrorMaker 2.0 は、コンシューマーが新しいクラスタの正しいポイントから再開できるようにするデータとオフセットの複製を容易にします。ただし、移行プロセス中のダウンタイムを最小限に抑えるには、慎重な計画が不可欠です。次の方法を検討してください。
並列デプロイ: 新しい Managed Service for Apache Kafka クラスタに切り替える際のダウンタイムを最小限に抑えるため、古いクラスタと新しいクラスタの両方でアプリケーションの並列インスタンスを実行できます。この移行中は、通知の送信など、メッセージごとに 1 回だけ実行する必要があるアプリケーション内のアクションを一時的に無効にします。これらの副作用を無効にして、同じメッセージが 2 回処理されることによる意図しない結果を防ぎます。新しいインスタンスが完全に追いついたら、すべてのトラフィックを新しいクラスタにリダイレクトし、すべての機能を再度有効にします。
段階的なロールアウト: 重要度の低いアプリケーションから始めて、管理しやすい小さなフェーズで移行します。このアプローチにより、潜在的な問題を特定し、中断の影響を最小限に抑えることができます。
Blue/Green デプロイ: 既存の環境(Blue)と並行して、本番環境(Green)の完全なレプリカを作成します。トラフィックを Blue から Green に徐々に移行し、最終的なカットオーバーの前にテストと検証を行います。このアプローチではダウンタイムを最小限に抑えることができますが、リソース使用率の増加が必要です。
メッセージ処理の要件: 重複または欠落したメッセージに対するアプリケーションの許容度を理解し、それに応じてコンシューマーを構成します。MirrorMaker 2.0 には、メッセージ配信セマンティクスを処理するための構成が用意されています。たとえば、
sync.group.offsets.enabledはコンシューマー オフセット同期をサポートしています。コンシューマーは、同期されたオフセットを使用して、ソースクラスタで中断した場所から読み取りを再開できます。これにより、メッセージの損失や重複の過剰な受信を防ぐことができます。コミュニケーションと調整: スムーズな移行には、アプリケーション チームとの効果的なコミュニケーションが不可欠です。明確なコミュニケーション チャネルを確立し、切り替えのタイミングを調整します。
オンプレミスの Apache Kafka を Google Cloudに接続する
ソースの Apache Kafka クラスタがオンプレミスにある場合は、オンプレミス ネットワークと Managed Service for Apache Kafka クラスタが存在する Virtual Private Cloud(VPC)の間に安全な接続を確立する必要があります。 Google Cloudから次のいずれかのオプションを使用します。
Cloud VPN: 低帯域幅のニーズや初期移行テストに適した費用対効果の高いソリューション。公共のインターネット上に暗号化されたトンネルを作成します。Cloud VPN の詳細については、Cloud VPN の概要をご覧ください。
Cloud Interconnect: オンプレミス ネットワークと Google Cloudの間に専用の高帯域幅接続を提供します。これは、高スループットと低レイテンシを必要とするエンタープライズ グレードのデプロイに最適です。Dedicated Interconnect(直接物理接続用)または Partner Interconnect(サポートされているサービス プロバイダ経由の接続)のいずれかを選択できます。 Google CloudInterconnect のドキュメントの詳細については、Cloud Interconnect の概要をご覧ください。
Managed Service for Apache Kafka クラスタを作成するときは、VPC で 1 つ以上のサブネットを選択する必要があります。このサブネットは、クラスタが VPC 内の他のリソースとの通信に使用する IP アドレスを提供し、クラスタを VPC ネットワーク内でアクセス可能にします。
オンプレミス ネットワークや他の VPC ネットワークから Managed Service for Apache Kafka クラスタに安全に接続するには、Cloud VPN または Cloud Interconnect 経由で Private Service Connect(PSC)を使用します。PSC エンドポイントを明示的に設定する必要はありません。クラスタの作成時にサブネットを選択すると、Managed Service for Apache Kafka サービスは必要な PSC エンドポイントを自動的に作成します。これにより、複雑なファイアウォール ルールやパブリック IP アドレスを管理することなく、VPC 内の内部 IP アドレスを使用してクラスタにアクセスできるようになり、ネットワーク構成が簡素化されます。
Managed Service for Apache Kafka のネットワーキング設定の詳細については、Managed Service for Apache Kafka のネットワーキングをご覧ください。
始める前に
移行設定の作成を開始する前に、現在の Apache Kafka の設定を文書化する必要があります。これは、新しい Managed Service for Apache Kafka クラスタに必要な vCPU、メモリ、ストレージなどのリソースを計算するために必要です。移行元の Apache Kafka 環境に関する次の情報を収集します。
Apache Kafka のバージョンが 2.4.0 以降であることを確認します。
Apache Kafka クラスタのバージョンを確認するには、Kafka インストール ディレクトリに移動して、コマンド
bin/kafka-topics.sh --versionを実行します。移行が必要なクラスタとトピックを特定します。
各トピックに関連付けられているプロデューサーとコンシューマーを特定します。
すべての消費者グループを特定します。
クラスタレベルとトピックレベルの両方でメッセージ スループットを決定します。
クラスタとトピックのレプリケーション係数を決定します。
コンシューマー構成(特にセキュリティ プロトコルと他の Google Cloud サービスとの統合)を文書化します。
移行中の中断を避けるため、移行元の Kafka クラスタに関連するすべてのアプリケーションの依存関係をマッピングします。本番環境を移行する前に、開発環境のクリティカルでないクラスタを使用してテスト移行を実施します。プロセスを検証し、潜在的な問題を特定します。最後に、必要に応じて元のクラスタに戻すための包括的なロールバック計画を作成します。
宛先クラスタのサイズを計算する
Managed Service for Apache Kafka クラスタに必要な vCPU の数とメモリのサイズを見積もるには、Kafka クラスタのサイズを計画するをご覧ください。ディスクとブローカーの構成は自動的に行われ、調整できません。
オープンソースの Kafka は JMX 指標を提供します。Managed Service for Apache Kafka に必要なクラスタサイズを正確に計算するには、次の JMX 指標を使用します。これらの指標はブローカー レベルで報告されます。クラスタのスループットを計算するには、すべてのブローカーのデータを集計する必要があります。
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec: この指標は、すべてのトピックのクライアントからの受信バイトレートを報告します。topic={...}パラメータを省略すると、すべてのトピックの集計レートが取得されます。kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: この指標は、すべてのトピックのクライアントへの送信バイトレートをレポートします。全体的なレートを取得するには、topic={...}パラメータを省略します。
これらの JMX 指標を一定期間モニタリングすることで、次の計算に使用するデータポイントを収集できます。
平均データ入力(MB/秒): この指標は、データが Kafka クラスタに取り込まれる平均速度を表します。
ピーク データ入力(MB/秒): この指標は、データが Kafka クラスタに取り込まれる最大レートを表します。
平均データ出力(MB/秒): この指標は、Kafka クラスタからデータが消費される平均レートを表します。
ピーク データ出力(MB/秒): この指標は、Kafka クラスタからデータが消費される最大レートを表します。
データを集計してバイトを MB に変換するには、指標の計算が必要になる場合があります。これらの計算値を使用して、次のように書き込み相当率を見積もることができます。
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
この書き込み相当率により、クラスタの全体的な書き込み負荷を判断できます。これは、Managed Service for Apache Kafka クラスタのサイズを適切に設定するために必要です。
Managed Service for Apache Kafka クラスタを作成する
Managed Service for Apache Kafka クラスタは、特定のGoogle Cloud プロジェクトとリージョンに配置されます。これには、任意の Virtual Private Cloud(VPC)内の 1 つ以上のサブネット内の IP アドレスのセットを使用してアクセスできます。
クラスタのサイズは、クラスタに割り当てる CPU の数と合計 RAM によって決まります。この場合、クラスタのサイズは移行元の Apache Kafka クラスタのサイズと同じにする必要があります。この計算を行う方法の詳細については、宛先クラスタのサイズを計算するをご覧ください。
クラスタの作成に必要な権限を取得するには、クラスタを作成するユーザーまたはサービス アカウントに、プロジェクトに対する Managed Kafka 管理者(roles/managedkafka.admin)IAM ロールを付与するよう管理者に依頼してください。ロールの付与の詳細については、プロジェクト、フォルダ、組織へのアクセスを管理するをご覧ください。
Managed Service for Apache Kafka クラスタを作成するには、CLI でメッセージを生成して使用するのクイックスタートの手順に沿って操作します。通常、クラスタの作成には 20~30 分かかります。
スタンドアロン クラスタ モードで MirrorMaker 2.0 を設定する
MirrorMaker 2.0 と Terraform を使用して Kafka データを Google Cloudに転送する方法を示す概念実証ドキュメントとサンプルコードについては、こちらの GitHub リポジトリをご覧ください。
このセクションでは、 Google Cloud VM のスタンドアロン クラスタモードで MirrorMaker 2.0 をインストールして構成する手順について説明します。この設定により、既存の Apache Kafka クラスタから Managed Service for Apache Kafka クラスタにデータを複製できます。
Managed Service for Apache Kafka クラスタへのアクセス権が付与された同じネットワークに VM を作成します。gcloud compute instances create コマンドを使用します。
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
次のように置き換えます。
VM_NAME: 作成する VM の名前。ZONE: VM を作成するゾーン。IMAGEまたはIMAGE_FAMILY: VM に使用するイメージまたはイメージ ファミリー。IMAGE_PROJECT: イメージが配置されているプロジェクト。MACHINE_TYPE: VM に使用するマシンタイプ。
新しく作成した VM にアクセスするには、SSH を使用します。
SSH 接続の詳細については、SSH 接続についてをご覧ください。
Kafka をダウンロードして抽出するには、新しい VM のターミナル ウィンドウで次のコマンドを実行します。
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgzJava をダウンロードし、パッケージを抽出して、Java パスを設定します。
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/path/to/kafka/config/mm2.propertiesファイルを編集して、次のプロパティを更新します。clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10source_kafka_bootstrap_serversとtarget_kafka_bootstrap_serversは、それぞれ移行元と移行先の Kafka クラスタのブートストラップ サーバーのアドレスに置き換えます。Managed Service for Apache Kafka のブートストラップ サーバー アドレスは、managed-kafka clusters describeGoogle Cloud CLI コマンドを使用して取得できます。source_kafka_usernameとsource_kafka_passwordは、移行元 Kafka クラスタの認証情報に置き換えます。target_kafka_usernameとtarget_kafka_passwordは、ターゲットの Managed Service for Apache Kafka クラスタの認証情報に置き換えます。ユーザー名とパスワードを構成するには、SASL/PLAIN 認証をご覧ください。topics = .\*とgroups = .\*の設定では、すべてのトピックとコンシューマー グループが複製されます。必要に応じて、これらの設定をより具体的に変更できます。offset.syncs.topic.replication.factor = 3設定は、MirrorMaker 2.0 がソース クラスタとターゲット クラスタ間でコンシューマー オフセットを同期するために使用する内部トピックのレプリケーション ファクタを設定します。レプリケーション係数が3の場合、オフセット データはターゲット クラスタの 3 つのブローカーに複製され、可用性とフォールト トレランスが向上します。checkpoints.topic.replication.factor = 3設定は、MirrorMaker 2.0 がチェックポイントの保存に使用する別の内部トピックのレプリケーション ファクタを設定します。チェックポイントは、MirrorMaker 2.0 が進行状況を追跡し、障害や再起動が発生した場合に正しい時点からレプリケーションを再開するのに役立ちます。heartbeats.topic.replication.factor = 3設定は、MirrorMaker 2.0 がハートビートの送信に使用する内部トピックのレプリケーション ファクタを設定します。ハートビートは、MirrorMaker 2.0 プロセスが動作中であることを示します。レプリケーション係数を大きくすると、これらのハートビートが確実に保存され、レプリケーション プロセスの健全性をモニタリングするために使用できます。emit.checkpoints.interval.seconds = 10設定は、MirrorMaker 2.0 がチェックポイントを生成する頻度を制御します。この場合、チェックポイントは 10 秒ごとに発行されます。この頻度により、進行状況の追跡とチェックポイントの書き込みのオーバーヘッドの最小化のバランスが取れます。
MirrorMaker 2.0 を起動します。
connect-mirror-maker.shスクリプトを使用してプロセスを開始します。スクリプトは、スタンドアロン モードで MirrorMaker 2.0 を起動し、ソース Kafka クラスタから Managed Service for Apache Kafka クラスタへのデータの複製を開始します。
その他の考慮事項:
ネットワーキング: Google Cloud VM に、移行元の Kafka クラスタと移行先の Managed Service for Apache Kafka クラスタの両方へのネットワーク接続があることを確認します。ソース クラスタがオンプレミスにある場合は、VPN または Interconnect の構成が必要になることがあります。
セキュリティ: MirrorMaker 2.0 インスタンスと Kafka クラスタを保護するために、適切なセキュリティ プロトコルとファイアウォール ルールを構成します。
これらの手順に沿って操作すると、 Google Cloud VM にスタンドアロン クラスタモードで MirrorMaker 2.0 をインストールして構成し、Kafka データを Managed Service for Apache Kafka に移行できます。
モニタリング
MirrorMaker 2.0 プロセスをモニタリングして、プロセスが正しく実行され、データが想定どおりに複製されていることを確認します。MirrorMaker 2 の組み込み指標または他のモニタリング ツールを使用できます。アプリケーションを移行したら、次の項目をモニタリングして、移行が成功したことを確認します。
下りスループット レート: 下りスループット レートに大きな変化がないことを確認します。たとえば、Dataflow をダウンストリームで使用している場合、スループットと Kafka に関連する指標は一貫性を保つ必要があります。
CPU とメモリの使用率: Cloud Monitoring を使用して、Managed Service for Apache Kafka クラスタの CPU とメモリの使用率をモニタリングします。最適なパフォーマンスを確保するには、使用率を 75% 未満に保つことが理想的です。
エラーログ: Cloud Logging を定期的にチェックして、Managed Service for Apache Kafka クラスタまたはアプリケーションに関連するエラーログがないか確認します。中断を防ぐため、エラーが発生した場合は速やかに対応してください。
制限事項
- MirrorMaker 2.0 では、ソース Apache Kafka クラスタのバージョンが 2.4.0 以降である必要があります。