
本文將說明如何將 Apache Kafka 工作負載遷移至 Google Cloud Managed Service for Apache Kafka,這項服務是 Google Cloud中的代管服務。
Managed Service for Apache Kafka 可協助您在 Google Cloud上執行 Apache Kafka。在本解決方案文件中,您會將資料從外部 Apache Kafka 叢集移至 Managed Service for Apache Kafka 叢集。
如要進一步瞭解 Managed Service for Apache Kafka,請參閱「Managed Service for Apache Kafka 總覽」。
建議您使用 Apache Kafka MirrorMaker 2.0 進行這項遷移作業。
MirrorMaker 2.0 是一種工具,可在 Apache Kafka 叢集之間即時複製資料。可用於資料遷移、災難復原、資料隔離和資料匯總。
如要進一步瞭解 MirrorMaker 2.0,請參閱下一節。
什麼是 MirrorMaker 2.0
MirrorMaker 2.0 會使用 Kafka Connect 架構,在 Kafka 叢集之間複製資料。Kafka Connect 是一個架構,可在 Kafka 叢集和其他系統之間串流資料。可做為擴充性高且可靠的管道。這個架構可透過現成可用的連線器,簡化 Kafka 與各種外部系統的整合程序,例如資料庫、訊息佇列和線上儲存空間。以下列出可使用 MirrorMaker 2.0 的可能情境:
資料遷移:將 Kafka 工作負載遷移至新叢集,如本指南所示。
災難復原:建立備份叢集,確保業務持續運作,以防發生故障。
資料隔離:選擇性地將主題複製到公用叢集,同時在私有叢集中確保機密資料安全無虞。
資料匯總:將多個 Kafka 叢集的資料整合到中央叢集,以利進行分析。
MirrorMaker 2.0 支援 Kafka 2.4.0 以上版本,並提供下列主要功能:
完整複製:複製所有必要元件,包括主題、資料和設定、含有位移的消費者群組,以及存取控制清單。
保留分割區:在目標叢集中維持相同的分割區配置,簡化應用程式的轉換程序。
自動建立主題和分區:自動偵測並複製新主題和分區,減少手動設定。
監控功能:提供端對端複寫延遲等重要指標,方便您追蹤複寫程序的健康狀態和效能。
容錯能力和擴充性:即使資料量龐大,也能確保運作穩定,並可水平擴充,以處理不斷增加的工作負載。
內部主題,確保穩定性:使用內部主題進行位移同步、檢查點和心跳。這些主題具有可設定的複寫因數 (例如
offset.syncs.topic.replication.factor),可確保高可用性和容錯能力。
MirrorMaker 2.0 提供兩種部署模式:
專屬叢集模式:MirrorMaker 2.0 會以獨立叢集的形式執行,管理自己的工作人員。本文將著重說明這個模式,並提供部署和設定的實用範例。
Kafka Connect 叢集模式:MirrorMaker 2.0 會在現有的 Kafka Connect 叢集中以連接器形式執行。
高階工作流程
下圖說明使用 MirrorMaker 2.0,將資料從來源 Apache Kafka 叢集遷移至 Managed Service for Apache Kafka 叢集的架構。
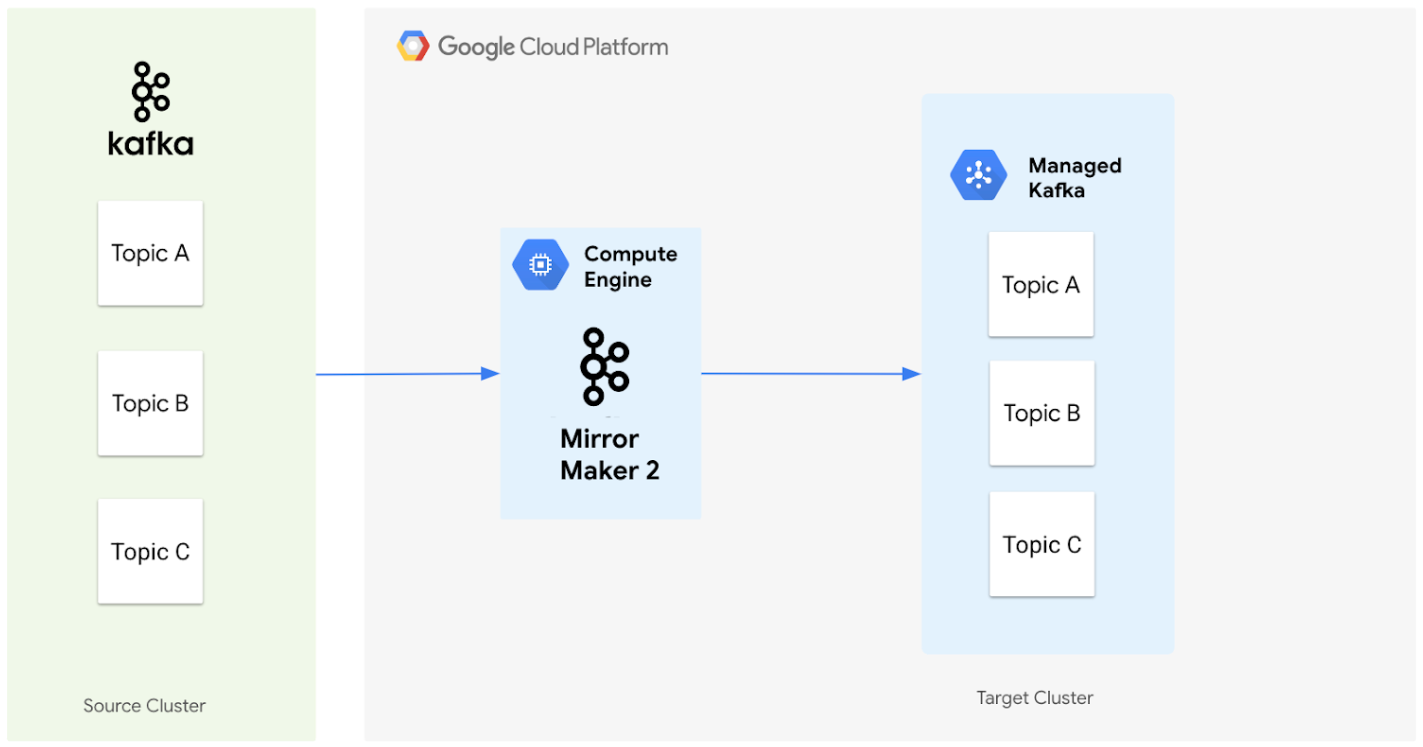
這些元件的協同運作方式如下:
來源叢集:這是指現有的 Apache Kafka 叢集,可能位於內部部署環境或其他雲端環境。其中包含要遷移的主題。在此圖表中,來源 Apache Kafka 叢集包含三個主題,分別是主題 A、B 和 C。
MirrorMaker 2.0:這個核心元件會部署在 Compute Engine VM 上,做為專屬的 MirrorMaker 2.0 叢集,並主動將來源 Apache Kafka 叢集的資料複製到目標 Managed Service for Apache Kafka 叢集。重要事項:如果目標叢集中沒有對應的主題和分割區,系統也會自動建立,與來源叢集設定相互呼應。
目標叢集:這是您的 Managed Service for Apache Kafka 叢集。這會成為 Kafka 資料的新家,MirrorMaker 2.0 會確保建立的主題和分割區與來源環境相符。
以下是遷移程序的基本工作流程。
初步評估
記錄現有的 Kafka 設定,包括叢集大小、主題、處理量和用戶群組。
規劃遷移目標和策略,包括容許的停機時間和轉換方法。
預估 Managed Service for Apache Kafka 叢集所需的資源。
準備作業
建立 Managed Service for Apache Kafka 叢集。
設定現有 Kafka 叢集與您剛建立的 Managed Service for Apache Kafka 叢集之間的網路連線。
在 Google Cloud VM 上部署 MirrorMaker 2.0。
執行遷移作業
設定 MirrorMaker 2.0,將現有 Kafka 叢集的資料複製到 Managed Service for Apache Kafka 叢集。
使用 MirrorMaker 2.0 指標監控複製程序。
逐步將取用端和生產端遷移至新的 Managed Service for Apache Kafka 叢集。
驗證與轉換
在 Managed Service for Apache Kafka 叢集中驗證資料完整性和應用程式功能。
執行最終轉換,將流量重新導向至 Managed Service for Apache Kafka 叢集。
停用舊的 Kafka 叢集。
遷移後
持續監控 Managed Service for Apache Kafka 叢集的效能。
請檢查並更新說明文件,以反映變更。
盡量縮短遷移停機時間
本節將說明使用 MirrorMaker 2.0 將開放原始碼 Kafka 資料遷移至 Managed Service for Apache Kafka 時,需要考量的事項。MirrorMaker 2.0 可協助複製資料和位移,讓消費者從新叢集中的正確位置繼續作業。不過,謹慎規劃至關重要,可將遷移過程中的停機時間降至最低。請考慮採用下列策略:
平行部署:如要盡量減少切換至新版 Managed Service for Apache Kafka 叢集時的停機時間,您可以在舊叢集和新叢集上平行執行應用程式執行個體。在轉換期間,請暫時停用應用程式中每個訊息只能執行一次的動作,例如傳送通知。停用這些副作用,避免重複處理同一則訊息而產生非預期的後果。新執行個體完全趕上進度後,請將所有流量重新導向至新叢集,並重新啟用所有功能。
分階段推出:先從不那麼重要的應用程式開始,分階段遷移,每次遷移的規模較小,方便管理。這種做法有助於找出潛在問題,並盡量減少任何中斷情形造成的影響。
藍綠部署:在現有環境 (藍色) 旁,建立生產環境的完整副本 (綠色)。逐步將流量從藍色轉移至綠色,以便在最終轉換前進行測試和驗證。這個方法可縮短停機時間,但需要提高資源用量。
訊息處理需求:瞭解應用程式對重複或遺漏訊息的容許程度,並據此設定消費者。MirrorMaker 2.0 提供多種設定,可處理訊息傳送語意。舉例來說,
sync.group.offsets.enabled支援消費者偏移同步。 消費者可以使用同步的偏移量,從來源叢集上次停止讀取的位置繼續讀取。這樣做可以避免遺失訊息或收到太多重複訊息。溝通與協調:與應用程式團隊有效溝通,是順利遷移的關鍵。建立明確的溝通管道,並協調切換時間。
將地端 Apache Kafka 連線至 Google Cloud
如果來源 Apache Kafka 叢集位於地端,您必須在地端網路與 Managed Service for Apache Kafka 叢集所在的虛擬私有雲 (VPC) 之間建立安全連線。從 Google Cloud中選擇下列其中一個選項。
Cloud VPN:經濟實惠的解決方案,適合頻寬需求較低或初步遷移實驗。系統會透過公開網際網路建立加密通道。如要進一步瞭解 Cloud VPN,請參閱 Cloud VPN 總覽。
Cloud Interconnect:提供地端部署網路與 Google Cloud之間的高頻寬專屬連線。非常適合需要更高總處理量和更低延遲時間的企業級部署作業。您可以選擇專屬互連網路 (直接實體連線),或合作夥伴互連網路 (透過支援的服務供應商連線)。如要進一步瞭解互連說明文件,請參閱 Cloud Interconnect 總覽。 Google Cloud
建立 Managed Service for Apache Kafka 叢集時,您必須在虛擬私有雲中選取至少一個子網路。這個子網路會提供叢集用來與 VPC 中其他資源通訊的 IP 位址,讓叢集可在 VPC 網路中存取。
如要從內部部署網路或其他虛擬私有雲網路安全地連線至 Managed Service for Apache Kafka 叢集,可以透過 Cloud VPN 或 Cloud Interconnect 使用 Private Service Connect (PSC)。您不需要明確設定 PSC 端點。在建立叢集時選取子網路後,Managed Service for Apache Kafka 服務會自動建立必要的 PSC 端點。這樣一來,您就能在虛擬私有雲中使用內部 IP 位址存取叢集,不必管理複雜的防火牆規則或公開 IP 位址,網路設定也變得簡單。
如要進一步瞭解 Managed Service for Apache Kafka 的網路設定,請參閱「Managed Service for Apache Kafka 的網路」。
事前準備
開始建立遷移設定前,請務必記錄目前的 Apache Kafka 設定。您需要這項資訊,才能計算新 Managed Service for Apache Kafka 叢集所需的資源,例如 vCPU、記憶體和儲存空間。請收集來源 Apache Kafka 環境的下列資訊:
確認 Apache Kafka 版本為 2.4.0 以上。
如要查看 Apache Kafka 叢集的版本,請前往 Kafka 安裝目錄,然後執行
bin/kafka-topics.sh --version找出需要遷移的叢集和主題。
找出與每個主題相關聯的生產者和消費者。
找出所有消費者群組。
判斷叢集和主題層級的訊息總處理量。
決定叢集和主題的複寫係數。
記錄消費者設定,尤其是安全通訊協定,以及與其他 Google Cloud 服務的任何整合。
為避免遷移期間發生中斷情形,請繪製與來源 Kafka 叢集相關的所有應用程式依附元件。遷移正式環境前,請先在開發環境中使用非重要叢集進行測試遷移。驗證程序並找出任何潛在問題。最後,請建立完整的復原計畫,以便在必要時還原至原始叢集。
計算目的地叢集大小
如要預估 Managed Service for Apache Kafka 叢集所需的 vCPU 數量和記憶體大小,請參閱「規劃 Kafka 叢集大小」。磁碟和代理程式設定是自動進行,無法調整。
開放原始碼 Kafka 提供 JMX 指標。如要準確計算 Managed Service for Apache Kafka 的叢集大小需求,可以使用下列 JMX 指標。這些指標會回報至經紀人層級。您必須匯總所有代理程式的資料,才能計算叢集輸送量。
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec:這項指標會回報所有主題中,來自用戶端的傳入位元組速率。如要取得所有主題的匯總比率,請省略topic={...}參數。kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec: 這項指標會回報所有主題的用戶端輸出位元組速率。 如要取得整體比率,請省略topic={...}參數。
長期監控這些 JMX 指標,即可收集資料點,進而計算下列項目:
平均資料輸入量 (MB/秒):這個指標代表資料輸入 Kafka 叢集的平均速率。
資料輸入峰值 (MB/s):這項指標代表資料輸入 Kafka 叢集的最高速率。
平均資料輸出量 (MB/s):這項指標代表從 Kafka 叢集取用資料的平均速率。
資料輸出量峰值 (MB/s):這項指標代表從 Kafka 叢集取用資料的最高速率。
您可能需要進行一些指標運算,才能匯總資料並將位元組轉換為 MB。使用這些計算值,即可估算寫入等效率,計算方式如下:
Write-equivalent rate (Avg/Peak) = (total write bandwidth) + (total read bandwidth / 4)
這個等同寫入的速率有助於判斷叢集的整體寫入負載,這是適當調整 Managed Service for Apache Kafka 叢集大小的必要條件。
建立 Managed Service for Apache Kafka 叢集
Managed Service for Apache Kafka 叢集位於特定Google Cloud 專案和區域。您可以使用任何虛擬私有雲 (VPC) 中一或多個子網路內的一組 IP 位址存取。
叢集的大小取決於您為叢集分配的 CPU 數量和 RAM 總量。在這種情況下,叢集大小必須與來源 Apache Kafka 叢集的大小相同。如要進一步瞭解如何執行這項計算,請參閱「計算目的地叢集大小」。
如要取得建立叢集所需的權限,請要求管理員授予您或建立叢集的服務帳戶專案的「Managed Kafka 管理員」(roles/managedkafka.admin) IAM 角色。如要進一步瞭解如何授予角色,請參閱「管理專案、資料夾和機構的存取權」。
如要建立 Managed Service for Apache Kafka 叢集,請按照「使用 CLI 產生及取用訊息」的快速入門操作說明進行。建立叢集通常需要 20 到 30 分鐘。
在獨立叢集模式中設定 MirrorMaker 2.0
如需概念驗證文件和範例程式碼,瞭解如何使用 MirrorMaker 2.0 和 Terraform 將 Kafka 資料轉移至 Google Cloud,請參閱這個 GitHub 存放區。
本節將逐步說明如何在 Google Cloud VM 上以獨立叢集模式安裝及設定 MirrorMaker 2.0。完成這項設定後,您就能將現有 Apache Kafka 叢集的資料,複製到 Managed Service for Apache Kafka 叢集。
在已獲准存取 Managed Service for Apache Kafka 叢集的網路中建立 VM。使用 gcloud compute instances create 指令。
gcloud compute instances create VM_NAME\ --zone=ZONE\ [--image=IMAGE | --image-family=IMAGE_FAMILY]\ --image-project=IMAGE_PROJECT\ --machine-type=MACHINE_TYPE
更改下列內容:
VM_NAME:要建立的 VM 名稱。ZONE:要建立 VM 的可用區。IMAGE或IMAGE_FAMILY:要用於 VM 的映像檔或映像檔系列。IMAGE_PROJECT:圖片所在的專案。MACHINE_TYPE:要用於 VM 的機器類型。
如要存取新建立的 VM,可以使用 SSH。
如要進一步瞭解 SSH 連線,請參閱「關於 SSH 連線」一文。
如要下載並解壓縮 Kafka,請在新的 VM 終端機視窗中執行下列指令:
wget https://downloads.apache.org/kafka/3.7.1/kafka_2.13-3.7.1.tgz tar -xzvf kafka_2.13-3.7.1.tgz下載 Java、解壓縮套件,然後設定 Java 路徑。
# Download Java wget https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz # Extract Java tar -xzvf openjdk-11.0.2_linux-x64_bin.tar.gz # Set Java path export PATH=$PATH:/java/jdk-11.0.2/bin/編輯
path/to/kafka/config/mm2.properties檔案,並更新下列屬性:clusters = source, target source.bootstrap.servers = <source_kafka_bootstrap_servers> target.bootstrap.servers = <target_kafka_bootstrap_servers> source.security.protocol = SASL_SSL source.sasl.mechanism = PLAIN source.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<source_kafka_username>" password="<source_kafka_password>"; target.security.protocol = SASL_SSL target.sasl.mechanism = PLAIN target.sasl.jaas.config = org.apache.kafka.common.security.plain.PlainLoginModule required username="<target_kafka_username>" password="<target_kafka_password>"; mirrors = source->target source->target.enabled=true topics = .* groups = .* offset.syncs.topic.replication.factor = 3 checkpoints.topic.replication.factor = 3 heartbeats.topic.replication.factor = 3 emit.checkpoints.interval.seconds = 10請將
source_kafka_bootstrap_servers和target_kafka_bootstrap_servers分別替換為來源和目標 Kafka 叢集的啟動伺服器位址。您可以使用managed-kafka clusters describeGoogle Cloud CLI 指令,取得 Managed Service for Apache Kafka 的啟動伺服器位址。將
source_kafka_username和source_kafka_password替換為來源 Kafka 叢集的憑證。將
target_kafka_username和target_kafka_password替換為目標 Managed Service for Apache Kafka 叢集的憑證。如要設定使用者名稱和密碼,請參閱「SASL/PLAIN 驗證」。topics = .\*和groups = .\*設定會複製所有主題和消費者群組。如有需要,可以修改這些設定,讓條件更具體。offset.syncs.topic.replication.factor = 3設定會為 MirrorMaker 2.0 內部使用的主題設定複寫因數,以便在來源和目標叢集之間同步處理消費者偏移量。複製係數為3表示偏移資料會複製到目標叢集中的三個代理程式,確保更高的可用性和容錯能力。checkpoints.topic.replication.factor = 3設定會為 MirrorMaker 2.0 用於儲存檢查點的另一個內部主題設定複寫因數。檢查點可協助 MirrorMaker 2.0 追蹤進度,並在發生故障或重新啟動時,從正確的時間點繼續複製。heartbeats.topic.replication.factor = 3設定會為 MirrorMaker 2.0 用於傳送活動訊號的內部主題設定複製因數。活動訊號表示 MirrorMaker 2.0 程序正在運作。 較高的複寫係數可確保這些心跳訊號能可靠地儲存,並用於監控複寫程序的健康狀態。emit.checkpoints.interval.seconds = 10設定可控制 MirrorMaker 2.0 發出檢查點的頻率。在本例中,每 10 秒會發出檢查點。這個頻率可兼顧追蹤進度和盡量減少寫入檢查點的負擔。
啟動 MirrorMaker 2.0。使用
connect-mirror-maker.sh指令碼啟動程序。這個指令碼會以獨立模式啟動 MirrorMaker 2.0,並開始將來源 Kafka 叢集的資料複製到 Managed Service for Apache Kafka 叢集。
其他注意事項:
網路:確認 VM 具有網路連線能力,可連線至來源 Kafka 叢集和目標 Managed Service for Apache Kafka 叢集。 Google Cloud 如果來源叢集位於地端部署環境,您可能需要設定 VPN 或互連網路。
安全性:設定適當的安全通訊協定和防火牆規則,確保 MirrorMaker 2.0 執行個體和 Kafka 叢集安全無虞。
按照這些步驟操作,即可在 VM 上以獨立叢集模式成功安裝及設定 MirrorMaker 2.0,方便您將 Kafka 資料遷移至 Managed Service for Apache Kafka。 Google Cloud
監控
監控 MirrorMaker 2.0 程序,確保程序正常運作,並如預期複製資料。您可以使用 MirrorMaker 2 的內建指標或其他監控工具。遷移應用程式後,請監控下列項目,確認遷移作業是否成功:
下游輸送量速率:確認下游輸送量速率沒有大幅變動。舉例來說,如果您使用 Dataflow 下游,與 Kafka 相關的輸送量和指標必須保持一致。
CPU 和記憶體使用率:使用 Cloud Monitoring 監控 Managed Service for Apache Kafka 叢集的 CPU 和記憶體使用率。為確保最佳效能,使用率最好維持在 75% 以下。
錯誤記錄:定期檢查 Cloud Logging,找出與 Managed Service for Apache Kafka 叢集或應用程式相關的錯誤記錄。請盡快修正所有錯誤,以免服務中斷。
限制
- MirrorMaker 2.0 必須使用 2.4.0 以上版本的來源 Apache Kafka 叢集。