
許多 Looker 客戶希望使用者不只能在資料倉儲中製作資料報表,還能實際寫回及更新資料倉儲。
Looker 的 Action API 支援任何資料倉儲或目的地,因此可滿足這類用途。本說明文件頁面適用於使用 Google Cloud 基礎架構的客戶,說明如何在 Cloud Run 函式上部署解決方案,將資料寫回 BigQuery。本頁面涵蓋下列主題:
解決方案考量事項
請參考這份考量事項清單,確認這項解決方案是否符合您的需求。
- Cloud Run functions
- 為什麼要使用 Cloud Run 函式?Cloud Run functions 是 Google 的「無伺服器」產品,非常適合用來簡化作業和維護工作。請注意,延遲時間 (尤其是冷啟動) 可能會比使用專屬伺服器的解決方案更長。
- 語言和執行階段:Cloud Run functions 支援多種語言和執行階段,本文件頁面將著重於 JavaScript 和 Node.js 的範例。不過,這些概念可直接翻譯成其他支援的語言和執行階段。
- BigQuery
- 選用 BigQuery 的理由 雖然本說明文件頁面假設您已在使用 BigQuery,但 BigQuery 一般來說是資料倉儲的絕佳選擇。請注意下列事項:
- BigQuery Storage Write API:BigQuery 提供多種介面,可更新資料倉儲中的資料,包括 SQL 式作業中的資料操縱語言 (DML) 陳述式。不過,如果需要大量寫入資料,建議使用 BigQuery Storage Write API。
- 附加而非更新:即使這個解決方案只會附加資料列,不會更新資料列,您還是可以隨時從僅供附加的記錄中,在查詢時衍生「目前狀態」表格,藉此模擬更新。
- 選用 BigQuery 的理由 雖然本說明文件頁面假設您已在使用 BigQuery,但 BigQuery 一般來說是資料倉儲的絕佳選擇。請注意下列事項:
- 支援服務
- Secret Manager: Secret Manager 會保存密鑰值,確保這些值不會儲存在過於容易存取的位置,例如直接儲存在函式的設定中。
- 身分與存取權管理 (IAM): IAM 會授權函式在執行階段存取必要密鑰,並寫入預期 BigQuery 資料表。
- Cloud Build:本頁不會深入探討 Cloud Build,但 Cloud Run functions 會在背景使用這項服務,您也可以使用 Cloud Build,在 Git 存放區中的原始碼變更時,自動持續將更新部署至函式。
- 動作和使用者驗證
- Cloud Run 服務帳戶:如要將 Looker 動作與貴機構的第一方資產和資源整合,最簡單的主要方式是使用 Looker Action API 的權杖式驗證機制,將要求驗證為來自 Looker 執行個體,然後授權該函式使用服務帳戶更新 BigQuery 中的資料。
- OAuth:另一個選項是使用 Looker Action API 的 OAuth 功能,但本頁未涵蓋這項功能。這種做法較為複雜,一般來說並不需要,但如果您需要使用 IAM 定義使用者對資料表的寫入存取權,而不是使用 Looker 中的存取權或函式程式碼中的臨時邏輯,則可採用這種做法。
示範程式碼逐步解說
我們有一個檔案,其中包含示範動作的完整邏輯,可在 GitHub 上取得。在本節中,我們將逐步說明程式碼的重要元素。
設定碼
第一個部分有幾個示範常數,用於識別動作要寫入的表格。在本頁稍後的「部署指南」部分,我們會指示您將專案 ID 換成自己的 ID,這是程式碼唯一需要修改的地方。
/*** Demo constants */
const projectId = "your-project-id"
const datasetId = "demo_dataset"
const tableId = "demo_table"
下一節會宣告並初始化動作將使用的幾個程式碼依附元件。我們提供一個範例,說明如何使用 Secret Manager Node.js 模組「在程式碼中」存取 Secret Manager;不過,您也可以使用 Cloud Run functions 的內建功能,在初始化期間擷取密鑰,藉此消除這項程式碼依附元件。
/*** Code Dependencies ***/
const crypto = require("crypto")
const {SecretManagerServiceClient} = require('@google-cloud/secret-manager')
const secrets = new SecretManagerServiceClient()
const BigqueryStorage = require('@google-cloud/bigquery-storage')
const BQSManagedWriter = BigqueryStorage.managedwriter
請注意,參考的 @google-cloud 依附元件也會在 package.json 檔案中宣告,以便預先載入依附元件,並提供給 Node.js 執行階段使用。crypto 是內建的 Node.js 模組,且未在 package.json 中宣告。
處理及轉送 HTTP 要求
程式碼向 Cloud Run 函式執行階段公開的主要介面,是遵循 Node.js Express 網路伺服器慣例的已匯出 JavaScript 函式。具體來說,函式會收到兩個引數:第一個代表 HTTP 要求,您可以從中讀取各種要求參數和值;第二個代表回應物件,您會將回應資料發送至該物件。函式名稱可以隨意命名,但稍後必須提供名稱給 Cloud Run 函式,詳情請參閱「部署指南」一節。
/*** Entry-point for requests ***/
exports.httpHandler = async function httpHandler(req,res) {
httpHandler 函式的第一個部分會宣告動作可辨識的各種路徑,與單一動作的動作 API 必要端點密切相符,以及稍後在檔案中定義的各個路徑處理函式。
雖然部分動作 + Cloud Run functions 範例會為每個這類路徑部署個別函式,與 Cloud Run functions 的預設路徑一一對應,但函式仍可在程式碼中套用額外的「子路徑」,如這裡所示。這最終取決於偏好設定,但透過程式碼執行這項額外路由作業,可將我們必須部署的函式數量降至最低,並協助我們在所有動作端點中維持單一連貫的程式碼狀態。
const routes = {
"/": [hubListing],
"/status": [hubStatus], // Debugging endpoint. Not required.
"/action-0/form": [
requireInstanceAuth,
action0Form
],
"/action-0/execute": [
requireInstanceAuth,
processRequestBody,
action0Execute
]
}
HTTP 處理常式函式的其餘部分會針對上述路徑宣告實作 HTTP 要求處理作業,並將這些處理常式的傳回值連結至回應物件。
try {
const routeHandlerSequence = routes[req.path] || [routeNotFound]
for(let handler of routeHandlerSequence) {
let handlerResponse = await handler(req)
if (!handlerResponse) continue
return res
.status(handlerResponse.status || 200)
.json(handlerResponse.body || handlerResponse)
}
}
catch(err) {
console.error(err)
res.status(500).json("Unhandled error. See logs for details.")
}
}
處理完 HTTP 處理常式和路徑宣告後,我們將深入探討必須實作的三個主要動作端點:
動作清單端點
Looker 管理員首次將 Looker 執行個體連結至動作伺服器時,Looker 會呼叫提供的網址 (稱為「動作清單端點」),以取得透過伺服器提供的動作相關資訊。
在先前顯示的路徑宣告中,我們在函式網址的根路徑 (/) 下提供這個端點,並指出該端點會由 hubListing 函式處理。
從下列函式定義可以看出,這段程式碼並不多,每次都只會傳回相同的 JSON 資料。請注意,這項功能會動態將「自己的」網址納入部分欄位,讓 Looker 執行個體稍後將要求傳回同一個函式。
async function hubListing(req){
return {
integrations: [
{
name: "demo-bq-insert",
label: "Demo BigQuery Insert",
supported_action_types: ["cell", "query", "dashboard"],
form_url:`${process.env.CALLBACK_URL_PREFIX}/action-0/form`,
url: `${process.env.CALLBACK_URL_PREFIX}/action-0/execute`,
icon_data_uri: "data:image/png;base64,...",
supported_formats:["inline_json"],
supported_formattings:["unformatted"],
required_fields:[
// You can use this to make your action available
// for specific queries/fields
// {tag:"user_id"}
],
params: [
// You can use this to require parameters, either
// from the Action's administrative configuration,
// or from the invoking user's user attributes.
// A common use case might be to have the Looker
// instance pass along the user's identification to
// allow you to conditionally authorize the action:
{name: "email", label: "Email", user_attribute_name: "email", required: true}
]
}
]
}
}
為了進行示範,我們的程式碼不需要驗證即可擷取這項房源資訊。不過,如果您認為動作中繼資料屬於機密資訊,也可以要求這條路徑必須通過驗證,詳情請參閱下一節。
另請注意,我們的 Cloud Run 函式可能會公開及處理多項動作,這說明瞭 /action-X/... 的路徑慣例。不過,我們的示範 Cloud Run 函式只會實作一個動作。
動作表單端點
雖然並非所有用途都需要表單,但表單很適合用於資料庫回寫用途,因為使用者可以在 Looker 中檢查資料,然後提供要插入資料庫的值。由於我們的動作清單提供 form_url 參數,因此當使用者開始與動作互動時,Looker 會叫用這個動作表單端點,判斷要從使用者擷取哪些額外資料。
在路徑宣告中,我們在 /action-0/form 路徑下提供這個端點,並將兩個處理常式與其建立關聯:requireInstanceAuth 和 action0Form。
我們設定了路徑宣告,允許使用多個處理常式,因為有些邏輯可重複用於多個端點。
舉例來說,我們可以看到 requireInstanceAuth 用於多條路線。只要想要求要求必須來自 Looker 執行個體,我們就會使用這個處理常式。處理常式會從 Secret Manager 擷取預期的密鑰權杖值,並拒絕任何沒有該預期權杖值的要求。
async function requireInstanceAuth(req) {
const lookerSecret = await getLookerSecret()
if(!lookerSecret){return}
const expectedAuthHeader = `Token token="${lookerSecret}"`
if(!timingSafeEqual(req.headers.authorization,expectedAuthHeader)){
return {
status:401,
body: {error: "Looker instance authentication is required"}
}
}
return
function timingSafeEqual(a, b) {
if(typeof a !== "string"){return}
if(typeof b !== "string"){return}
var aLen = Buffer.byteLength(a)
var bLen = Buffer.byteLength(b)
const bufA = Buffer.allocUnsafe(aLen)
bufA.write(a)
const bufB = Buffer.allocUnsafe(aLen) //Yes, aLen
bufB.write(b)
return crypto.timingSafeEqual(bufA, bufB) && aLen === bLen;
}
}
請注意,我們使用 timingSafeEqual 實作,而非標準等式檢查 (==),目的是防止洩漏側通道時間資訊,讓攻擊者快速找出密碼值。
假設要求通過執行個體驗證檢查,就會由 action0Form 處理常式處理。
async function action0Form(req){
return [
{name: "choice", label: "Choose", type:"select", options:[
{name:"Yes", label:"Yes"},
{name:"No", label:"No"},
{name:"Maybe", label:"Maybe"}
]},
{name: "note", label: "Note", type: "textarea"}
]
}
雖然我們的示範範例非常靜態,但表單程式碼可以更具互動性,適用於特定用途。舉例來說,根據使用者在初始下拉式選單中的選取項目,系統可能會顯示不同的欄位。
動作執行端點
動作執行端點是任何動作邏輯的大宗所在,也是我們將深入探討 BigQuery 插入用途專屬邏輯的地方。
在路徑宣告中,我們在 /action-0/execute 路徑下提供這個端點,並將三個處理常式與其建立關聯:requireInstanceAuth、processRequestBody 和 action0Execute。
我們已介紹過 requireInstanceAuth,而 processRequestBody 處理常式主要提供不重要的前置處理作業,可將 Looker 要求主體中不方便的欄位轉換為更方便的格式,但您可以在完整程式碼檔案中參閱。
action0Execute 函式會先顯示從動作要求的多個部分擷取資訊的範例,這些資訊可能很有用。請注意,在實務上,程式碼中稱為 formParams 和 actionParams 的要求元素可能包含不同欄位,具體取決於您在「目錄」和「表單」端點中宣告的內容。
async function action0Execute (req){
try{
// Prepare some data that we will insert
const scheduledPlanId = req.body.scheduled_plan && req.body.scheduled_plan.scheduled_plan_id
const formParams = req.body.form_params || {}
const actionParams = req.body.data || {}
const queryData = req.body.attachment.data //If using a standard "push" action
/*In case any fields require datatype-specific preparation, check this example:
https://github.com/googleapis/nodejs-bigquery-storage/blob/main/samples/append_rows_proto2.js
*/
const newRow = {
invoked_at: new Date(),
invoked_by: actionParams.email,
scheduled_plan_id: scheduledPlanId || null,
query_result_size: queryData.length,
choice: formParams.choice,
note: formParams.note,
}
接著,程式碼會轉換為一些標準 BigQuery 程式碼,實際插入資料。請注意,BigQuery Storage Write API 提供其他更複雜的變體,更適合用於持續串流連線或大量插入多筆記錄;但若要在 Cloud Run 函式的環境中回應個別使用者互動,這是最直接的變體。
await bigqueryConnectAndAppend(newRow)
...
async function bigqueryConnectAndAppend(row){
let writerClient
try{
const destinationTablePath = `projects/${projectId}/datasets/${datasetId}/tables/${tableId}`
const streamId = `${destinationTablePath}/streams/_default`
writerClient = new BQSManagedWriter.WriterClient({projectId})
const writeMetadata = await writerClient.getWriteStream({
streamId,
view: 'FULL',
})
const protoDescriptor = BigqueryStorage.adapt.convertStorageSchemaToProto2Descriptor(
writeMetadata.tableSchema,
'root'
)
const connection = await writerClient.createStreamConnection({
streamId,
destinationTablePath,
})
const writer = new BQSManagedWriter.JSONWriter({
streamId,
connection,
protoDescriptor,
})
let result
if(row){
// The API expects an array of rows, so wrap the single row in an array
const rowsToAppend = [row]
result = await writer.appendRows(rowsToAppend).getResult()
}
return {
streamId: connection.getStreamId(),
protoDescriptor,
result
}
}
catch (e) {throw e}
finally{
if(writerClient){writerClient.close()}
}
}
為了方便進行疑難排解,範例程式碼也包含「狀態」端點,但整合 Action API 時不需要這個端點。
部署指南
最後,我們會提供逐步指南,協助您自行部署這個範例,內容涵蓋必要條件、Cloud Run 函式部署、BigQuery 設定和 Looker 設定。
專案和服務的必要條件
開始設定任何具體項目之前,請先查看這份清單,瞭解解決方案需要哪些服務和政策:
- 新專案:您需要新專案來存放範例中的資源。
- 服務:首次在 Cloud 控制台 UI 中使用 BigQuery 和 Cloud Run 函式時,系統會提示您啟用必要服務的必要 API,包括 BigQuery、Artifact Registry、Cloud Build、Cloud Functions、Cloud Logging、Pub/Sub、Cloud Run Admin 和 Secret Manager。
- 未經驗證的叫用政策:這個用途需要我們部署「允許公開存取」的 Cloud Run 函式,因為我們會根據 Action API 在程式碼中處理傳入要求的驗證,而不是使用 IAM。雖然預設允許這麼做,但組織政策通常會限制這類用途。具體來說,
constraints/iam.allowedPolicyMemberDomains政策會限制可獲派 IAM 權限的對象,您可能需要調整這項政策,允許allUsers主體進行未經驗證的存取。如果無法允許公開存取,請參閱「如何強制執行網域限定共用時建立公開 Cloud Run 服務」指南,瞭解詳情。 - 其他政策:請注意,其他Google Cloud 機構政策限制也可能禁止部署預設允許的服務。
部署 Cloud Run 函式
建立新專案後,請按照下列步驟部署 Cloud Run 函式:
- 在「Cloud Run functions」中,按一下「建立函式」。
- 為函式選擇任意名稱 (例如「demo-bq-insert-action」)。
- 在「觸發條件」設定下方:
- 觸發條件類型應已設為「HTTPS」。
- 將「Authentication」(驗證) 設為「Allow unauthenticated invocations」(允許未經驗證的叫用)。
- 將「URL」值複製到剪貼簿。
- 在「執行階段」>「執行階段環境變數」設定下方:
- 按一下「新增變數」。
- 將變數名稱設為
CALLBACK_URL_PREFIX。 - 將上一步的網址貼為值。
- 點選「下一步」。
- 按一下
package.json檔案,然後貼上內容。 - 按一下
index.js檔案,然後貼上內容。 - 在檔案頂端將
projectId變數指派給您自己的專案 ID。 - 將「Entry Point」(進入點) 設為
httpHandler。 - 點選「Deploy」(部署)。
- 將要求的權限 (如有) 授予建構服務帳戶。
- 等待部署作業完成。
- 如果後續步驟發生錯誤,並要求您查看 Google Cloud 記錄,請注意,您可以在這個頁面的「記錄」分頁中存取這項函式的記錄。
- 在離開 Cloud Run 函式頁面之前,請在「詳細資料」分頁下方,找到並記下函式所用的「服務帳戶」。我們會在後續步驟中使用這個值,確保函式具備所需權限。
- 在瀏覽器中前往網址,直接測試函式部署作業。您應該會看到包含整合項目清單的 JSON 回應。
- 如果收到 403 錯誤,表示您嘗試設定「允許未經驗證的叫用作業」可能因組織政策而無聲無息地失敗。檢查函式是否允許未經驗證的叫用,查看組織政策設定,然後嘗試更新設定。
BigQuery 目的地資料表的存取權
實務上,要插入的目標資料表可以位於不同的 Google Cloud 專案中,但為了示範,我們會在同一個專案中建立新的目的地資料表。無論是哪種情況,您都需要確保 Cloud Run 函式的服務帳戶有權寫入資料表。
- 前往 BigQuery 控制台。
建立示範資料表:
- 在「Explorer」列中,使用專案旁邊的省略號選單,然後選取「建立資料集」。
- 將資料集 ID 設為
demo_dataset,然後按一下「建立資料集」。 - 使用新建立資料集中的省略號選單,然後選取「建立資料表」。
- 將資料表命名為
demo_table。 選取「結構定義」下方的「以文字形式編輯」,使用下列結構定義,然後按一下「建立資料表」。
[ {"name":"invoked_at","type":"TIMESTAMP"}, {"name":"invoked_by","type":"STRING"}, {"name":"scheduled_plan_id","type":"STRING"}, {"name":"query_result_size","type":"INTEGER"}, {"name":"choice","type":"STRING"}, {"name":"note","type":"STRING"} ]
指派權限:
- 在「Explorer」列中,按一下您的資料集。
- 在資料集頁面中,依序點選「共用」>「權限」。
- 按一下「新增主體」。
- 將「New Principal」(新增主體) 設為函式的服務帳戶,如本頁稍早所述。
- 指派「BigQuery 資料編輯者」角色。
- 按一下 [儲存]。
正在連線至 Looker
函式部署完成後,我們將連結 Looker。
- 我們需要您動作的共用密鑰,才能驗證要求是否來自 Looker 執行個體。產生長隨機字串並妥善保管。我們會在後續步驟中將其做為 Looker 密鑰值。
- 前往 Cloud 控制台的「Secret Manager」。
- 點選「建立密鑰」。
- 將「Name」(名稱) 設為
LOOKER_SECRET。(這是這個試用版程式碼中的硬式編碼,但使用自己的程式碼時,您可以有效選擇任何名稱)。 - 將「Secret Value」設為您產生的密碼值。
- 點選「建立密鑰」。
- 在「Secret」(密鑰) 頁面上,按一下「Permissions」(權限) 分頁標籤。
- 點選「授予存取權」。
- 將「New Principals」(新增主體) 設為先前記下的函式服務帳戶。
- 指派「Secret Manager Secret Accessor」角色。
- 按一下 [儲存]。
- 如要確認函式是否成功存取密鑰,請前往函式網址後方附加的
/status路由。
- 在 Looker 執行個體中:
- 依序前往「管理」>「平台」>「動作」。
- 前往頁面底部,然後按一下「新增動作中心」。
- 提供函式的網址 (例如 https://your-region-your-project.cloudfunctions.net/demo-bq-insert-action),然後按一下「新增動作中心」確認。
- 您現在應該會看到新的 Action Hub 項目,其中包含一個名為「Demo BigQuery Insert」的動作。
- 在「動作中心」項目中,按一下「設定授權」。
- 在「Authorization Token」(授權權杖) 欄位中輸入產生的 Looker 密鑰,然後按一下「Update Token」(更新權杖)。
- 在「Demo BigQuery Insert」動作中,按一下「Enable」。
- 將「Enabled」(啟用狀態)切換為開啟。
- 系統應會自動執行動作測試,確認函式接受 Looker 的要求,並正確回應表單端點。
- 按一下 [儲存]。
端對端測試
現在應該可以使用新動作了。這項動作已設定為可搭配任何查詢使用,因此請選取任一「探索」(例如內建的「系統活動」探索),然後將一些欄位新增至新查詢、執行查詢,再從齒輪選單中選擇「傳送」。您應該會看到這項動作是其中一個可用目的地,並收到一些欄位輸入提示:
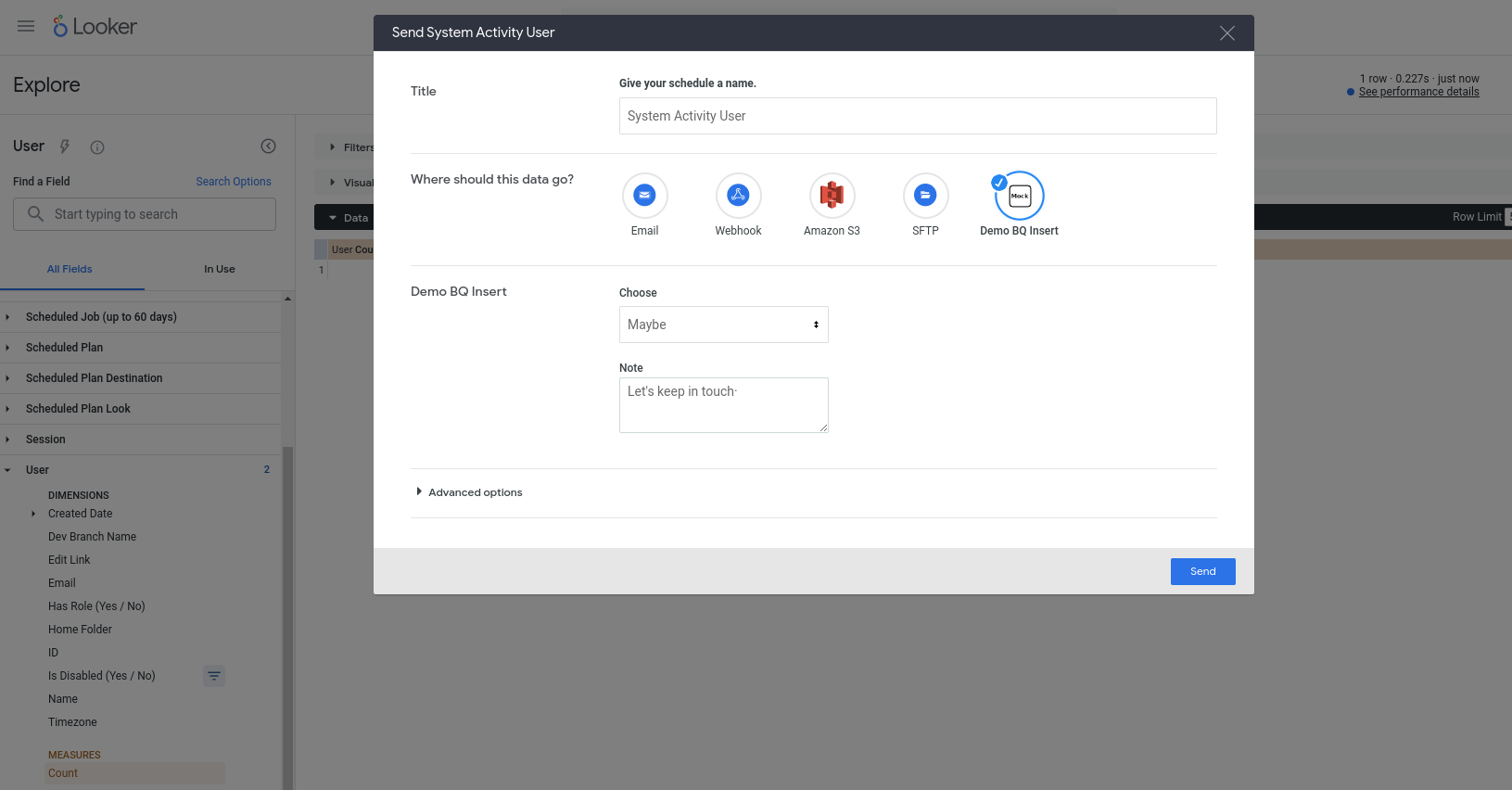
按下「傳送」後,您應該會在 BigQuery 資料表中插入新資料列 (並在 invoked_by 欄中識別出 Looker 使用者帳戶的電子郵件地址)!