
Uso
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
Hierarquia
aggregate_table |
Valor padrão
Nenhum
Aceita Um nome para a tabela de agregação, o subparâmetro query para definir a tabela e o subparâmetro materialization para definir a estratégia de persistência da tabela.
Regras especiais
|
Definição
O parâmetro aggregate_table é usado para criar tabelas agregadas que minimizam o número de consultas necessárias para as tabelas grandes no banco de dados.
O Looker usa a lógica de reconhecimento agregado para encontrar a menor e mais eficiente tabela de agregação disponível no seu banco de dados para executar uma consulta, mantendo a correção. Consulte a página de documentação Reconhecimento de agregação para uma visão geral e estratégias de criação de tabelas de agregação.
Para tabelas muito grandes no seu banco de dados, é possível criar tabelas agregadas menores de dados, agrupados por várias combinações de atributos. As tabelas agregadas atuam como resumos ou tabelas de resumo que o Looker pode usar para consultas sempre que possível, em vez da tabela grande original.
Depois de criar as tabelas de agregação, você pode executar consultas na Análise para ver quais tabelas de agregação o Looker usa. Para mais informações, consulte a seção Como determinar qual tabela de agregação é usada para uma consulta na página de documentação Reconhecimento de agregação.
Consulte a seção Solução de problemas na página de documentação Reconhecimento de agregação para saber os motivos comuns de não uso das tabelas agregadas.
Como definir uma tabela de agregação em LookML
Cada parâmetro aggregate_table precisa ter um nome exclusivo em um determinado explore.
O parâmetro aggregate_table tem os subparâmetros query e materialization.
query
O parâmetro query define a consulta para a tabela de agregação, incluindo quais dimensões e métricas usar. O parâmetro query inclui os seguintes subparâmetros:
| Nome do parâmetro | Descrição | Exemplo |
|---|---|---|
dimensions |
Uma lista separada por vírgulas das dimensões da Análise a serem incluídas na sua tabela de agregação. O campo dimensions usa este formato: dimensions: [dimension1, dimension2, ...]
Cada dimensão nessa lista precisa ser definida como um dimension no arquivo de visualização da Análise da consulta. Se você quiser incluir um campo definido como filter na consulta do recurso Detalhar, adicione-o à lista filters na consulta da tabela de agregação.
|
dimensions: [orders.created_month, orders.country] |
measures |
Uma lista separada por vírgulas das métricas da Análise a serem incluídas na tabela de agregação. O campo measures usa este formato: measures: [measure1, measure2, ...]
Para informações sobre os tipos de métricas compatíveis com a percepção de agregação, consulte a seção Fatores do tipo de métrica na página de documentação Percepção de agregação.
|
measures: [orders.count] |
filters |
Opcionalmente, adiciona um filtro a uma query. Os filtros são adicionados à cláusula WHERE do SQL que gera a tabela de agregação.
O campo filters usa este formato: filters: [field1: "value1", field2: "value2", ...]
Para saber como os filtros podem impedir que sua tabela de agregação seja usada, consulte a seção Fatores de filtro na página de documentação Conscientização de agregação. |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
Especifica opcionalmente os campos e a direção de classificação (crescente ou decrescente) para o query.
O campo sorts usa este formato: sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
Define o fuso horário para o query. Se um fuso horário não for especificado, a tabela de agregação não fará nenhuma conversão de fuso horário e usará o fuso horário do banco de dados.Para informações sobre como definir o fuso horário para que sua tabela de agregação seja usada como uma fonte de consulta, consulte a seção Fatores de fuso horário na página de documentação Reconhecimento de agregação.
O ambiente de desenvolvimento integrado sugere automaticamente o valor do fuso horário quando você digita o parâmetro timezone no ambiente. O IDE também mostra a lista de valores de fuso horário compatíveis no painel de Ajuda rápida. |
timezone: America/Los_Angeles |
materialization
O parâmetro materialization especifica a estratégia de persistência da tabela de agregação, além de outras opções de distribuição, particionamento, índices e clustering que podem ser compatíveis com seu dialeto SQL.
Para ser acessível para reconhecimento de agregados, a tabela de agregação precisa ser persistida no banco de dados. O parâmetro materialization da tabela de agregação precisa ter um dos seguintes subparâmetros para especificar a estratégia de persistência:
datagroup_triggersql_trigger_valuepersist_for(não recomendado)
Além disso, os seguintes subparâmetros materialization podem ser compatíveis com sua tabela de agregação, dependendo do dialeto SQL:
Para criar uma tabela de agregação incremental, use os seguintes subparâmetros materialization:
datagroup_trigger
Use o parâmetro datagroup_trigger para acionar a regeneração da tabela de agregação com base em um datagroup definido no arquivo modelo:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
Use o parâmetro sql_trigger_value para acionar a regeneração da tabela de agregação com base em uma instrução SQL fornecida por você. Se o resultado da instrução SQL for diferente do valor anterior, a tabela será gerada novamente. Esta instrução sql_trigger_value vai acionar a regeneração quando a data mudar:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
O parâmetro persist_for também é compatível com tabelas de agregação. No entanto, a estratégia persist_for pode não oferecer o melhor desempenho para o reconhecimento agregado. Isso acontece porque, quando um usuário executa uma consulta que depende de uma tabela persist_for, o Looker verifica a idade da tabela em relação à configuração persist_for. Se a tabela for mais antiga do que a configuração persist_for, ela será regenerada antes da execução da consulta. Se a idade for menor que a configuração persist_for, a tabela atual será usada. Portanto, a menos que um usuário execute uma consulta dentro do período persist_for, a tabela de agregação precisará ser reconstruída antes de ser usada para o reconhecimento agregado.
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
A menos que você entenda as limitações e tenha um caso de uso específico para a implementação do persist_for, é melhor usar datagroup_trigger ou sql_trigger_value como uma estratégia de persistência para tabelas agregadas.
cluster_keys
O parâmetro cluster_keys permite adicionar uma coluna em cluster a tabelas particionadas no BigQuery ou no Snowflake. O clustering classifica os dados em uma partição com base nos valores das colunas em cluster e organiza essas colunas em blocos de armazenamento com o tamanho ideal.
Consulte a página de documentação de parâmetros do cluster_keys para mais informações.
distribution
O parâmetro distribution permite especificar a coluna de uma tabela de agregação em que uma chave de distribuição será aplicada. distribution funciona apenas com bancos de dados Redshift e Aster. Para outros dialetos SQL (como MySQL e Postgres), use indexes.
Consulte a página de documentação de parâmetros do distribution para mais informações.
distribution_style
O parâmetro distribution_style permite especificar como a consulta de uma tabela de agregação é distribuída entre os nós em um banco de dados do Redshift:
distribution_style: allindica que todas as linhas foram totalmente copiadas para cada nó.distribution_style: evenespecifica uma distribuição uniforme, para que as linhas sejam distribuídas para diferentes nós de maneira rotativa.
Consulte a página de documentação de parâmetros do distribution_style para mais informações.
indexes
O parâmetro indexes permite aplicar índices às colunas de uma tabela de agregação.
Consulte a página de documentação de parâmetros do indexes para mais informações.
partition_keys
O parâmetro partition_keys define uma matriz de colunas por que a tabela de agregação será particionada. partition_keys é compatível com dialetos de banco de dados que podem particionar colunas. Quando uma consulta filtrada em uma coluna particionada é executada, o banco de dados verifica apenas as partições que incluem os dados filtrados, em vez de verificar a tabela inteira. partition_keys é compatível apenas com dialetos do Presto e do BigQuery.
Consulte a página de documentação de parâmetros do partition_keys para mais informações.
publish_as_db_view
O parâmetro publish_as_db_view permite sinalizar uma tabela de agregação para consulta fora do Looker. Para tabelas de agregação com publish_as_db_view definido como yes, o Looker cria uma visualização estável do banco de dados para a tabela de agregação. A visualização estável do banco de dados é criada no próprio banco de dados para que possa ser consultada fora do Looker.
Consulte a página de documentação de parâmetros do publish_as_db_view para mais informações.
sortkeys
O parâmetro sortkeys permite especificar uma ou mais colunas de uma tabela de agregação em que uma chave de classificação regular será aplicada.
Consulte a página de documentação de parâmetros do sortkeys para mais informações.
increment_key
É possível criar TDPs incrementais no seu projeto se o dialeto for compatível com elas. Uma TDP incremental é uma tabela derivada persistente (TDP) que o Looker cria adicionando dados novos à tabela, em vez de recriá-la por completo. Consulte a página de documentação TDPs incrementais para mais informações.
As tabelas de agregação são um tipo de TDP e podem ser criadas de forma incremental adicionando o parâmetro increment_key, que especifica o incremento de tempo para o qual os dados novos devem ser consultados e anexados à tabela de agregação.increment_key
Consulte a página de documentação de parâmetros do increment_key para mais informações.
increment_offset
O parâmetro increment_offset define o número de períodos anteriores (na granularidade da chave de incremento) que serão recriados ao anexar dados à tabela de agregação. O parâmetro increment_offset é opcional para PDTs incrementais e tabelas agregadas.
Consulte a página de documentação de parâmetros do increment_offset para mais informações.
Como acessar a tabela de agregação do LookML em uma Análise
Como um atalho, os desenvolvedores do Looker podem usar uma consulta de Análise para criar uma tabela de agregação e copiar o LookML para o projeto do LookML:
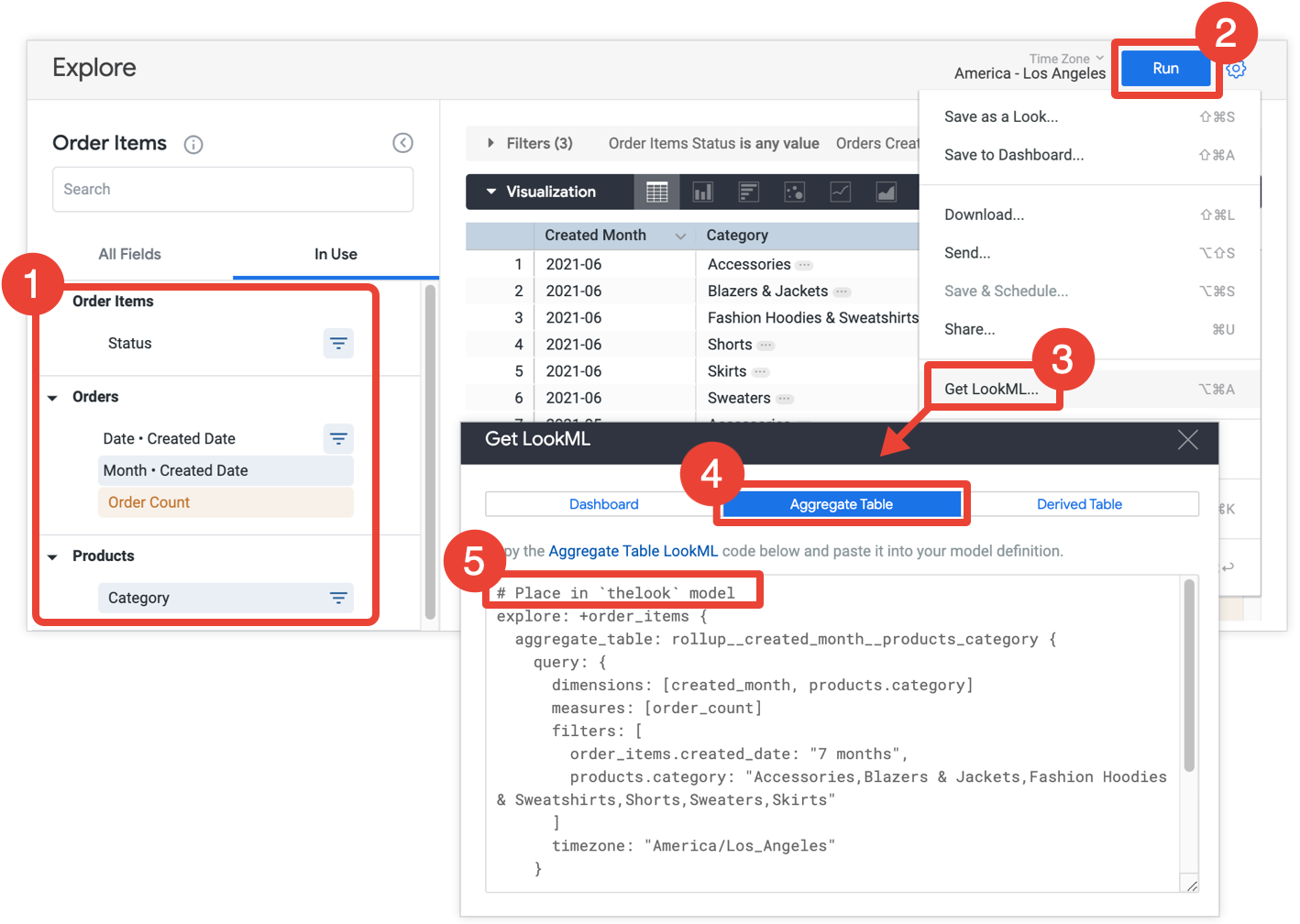
- Na análise detalhada, selecione todos os campos e filtros que você quer incluir na tabela de agregação.
- Clique em Executar para ver os resultados.
- Selecione Receber LookML no menu de engrenagem da análise. Essa opção está disponível apenas para desenvolvedores do Looker.
- Clique na guia Tabela de agregação.
- O Looker fornece o LookML para um refinamento de Análise que adiciona a tabela de agregação à Análise. Copie o LookML e cole no arquivo modelo associado, indicado no comentário que precede o refinamento da Análise. Se o Explore estiver definido em um arquivo do Explore separado, e não em um arquivo modelo, adicione o refinamento ao arquivo do Explore em vez do arquivo modelo. Qualquer um dos locais funciona.
Se você precisar modificar a LookML da tabela de agregação, use os parâmetros descritos na seção Definir uma tabela de agregação em LookML desta página. Você pode renomear a tabela de agregação sem mudar a aplicabilidade dela à consulta original do recurso "Análise". No entanto, outras mudanças na tabela de agregação podem afetar a capacidade do Looker de usar a tabela de agregação para a consulta da Análise. Consulte a seção Como criar tabelas agregadas na página de documentação Reconhecimento de agregados para dicas sobre como otimizar suas tabelas agregadas e garantir que elas sejam usadas para o reconhecimento de agregados.
Como acessar a tabela de agregação do LookML em um painel
Outra opção para desenvolvedores do Looker é acessar a tabela de agregação do LookML para todos os blocos em um painel e copiar o LookML para o projeto do LookML.
Criar tabelas de agregação pode melhorar drasticamente a performance de um painel, especialmente para blocos que consultam conjuntos de dados enormes.
Se você tiver a permissão develop, poderá acessar o LookML para criar tabelas de agregação em um painel. Para isso, abra o painel, selecione Acessar LookML no menu de três pontos do painel e escolha a guia Tabelas de agregação:
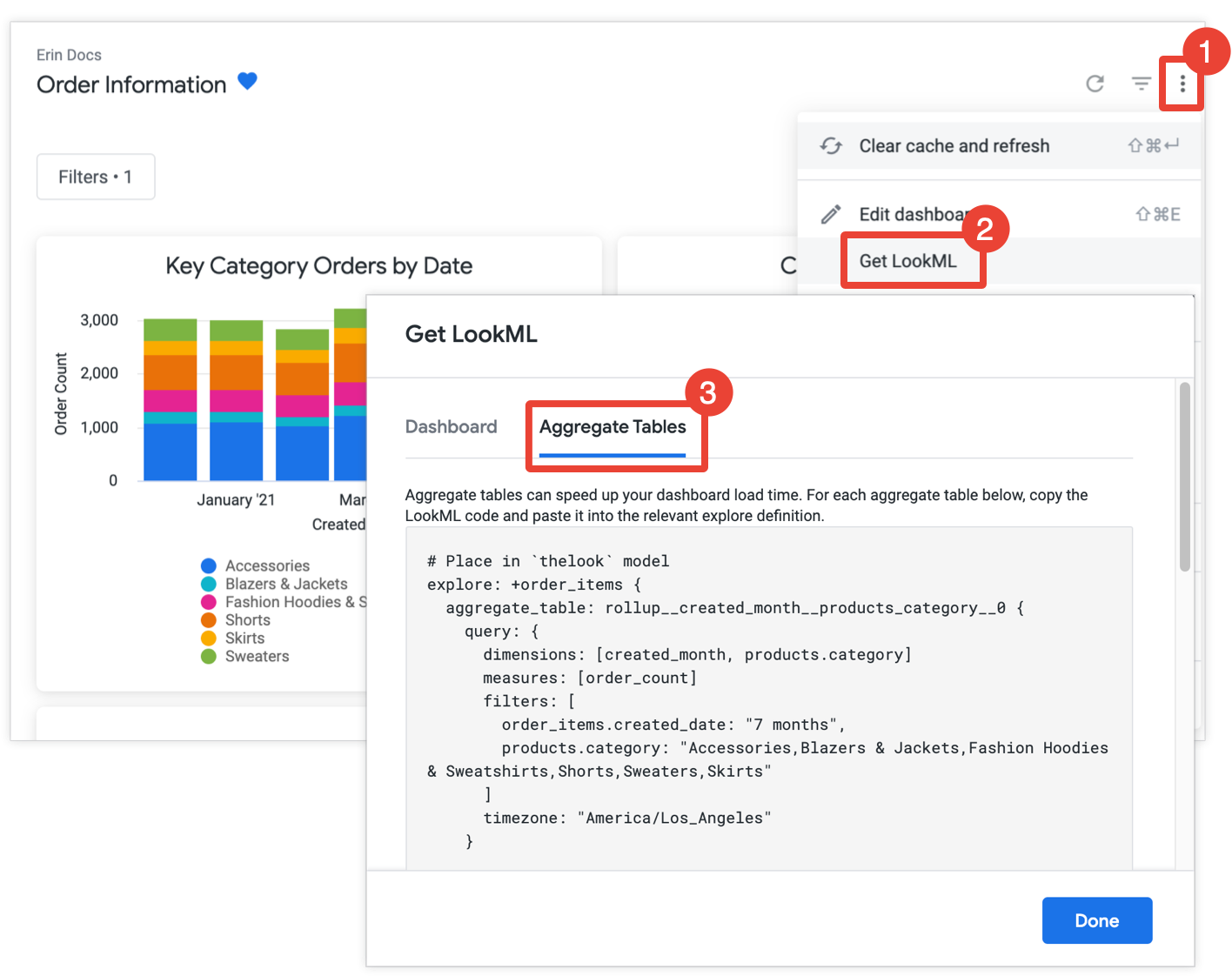
Para cada bloco que ainda não está otimizado com reconhecimento de tabela de agregação, o Looker fornece a LookML para um refinamento de Análise que adiciona a tabela de agregação à Análise. Se o painel incluir vários blocos da mesma Análise, o Looker vai colocar todas as tabelas agregadas em um único refinamento de Análise. Para reduzir o número de tabelas de agregação geradas, o Looker determina se uma tabela de agregação gerada pode ser usada em mais de um bloco e, se for o caso, descarta as tabelas de agregação redundantes que podem ser usadas em menos blocos.
Copie e cole cada refinamento do Explore no arquivo modelo associado, indicado no comentário antes do refinamento do Explore. Se o Explore estiver definido em um arquivo separado do Explore, e não em um arquivo modelo, adicione o refinamento ao arquivo do Explore em vez do arquivo modelo. Qualquer um dos locais funciona.
Se um filtro de painel for aplicado a um bloco, o Looker vai adicionar a dimensão do filtro à tabela de agregação do bloco para que ela possa ser usada no bloco. Isso acontece porque as tabelas de agregação só podem ser usadas em uma consulta se os filtros dela fizerem referência a campos disponíveis como dimensões na tabela de agregação. Consulte a página de documentação Aggregate awareness para mais informações.
Se você precisar modificar a LookML da tabela de agregação, use os parâmetros descritos na seção Definir uma tabela de agregação em LookML desta página. É possível renomear a tabela de agregação sem mudar a aplicabilidade dela ao bloco original do painel. No entanto, outras mudanças na tabela de agregação podem afetar a capacidade do Looker de usar a tabela de agregação no painel. Consulte a seção Como criar tabelas agregadas na página de documentação Reconhecimento de agregados para dicas sobre como otimizar suas tabelas agregadas e garantir que elas sejam usadas para o reconhecimento de agregados.
Exemplo
O exemplo a seguir cria uma monthly_orders tabela de agregação para a Análise event. A tabela de agregação cria uma contagem mensal de pedidos. O Looker vai usar a tabela de agregação para consultas de contagem de pedidos que podem aproveitar a granularidade mensal, como consultas de contagens de pedidos anuais, trimestrais e mensais.
A tabela de agregação é configurada com persistência usando o datagroup orders_datagroup. Além disso, a tabela de agregação é definida com publish_as_db_view: yes, o que significa que o Looker vai criar uma visualização estável do banco de dados para a tabela de agregação.
A definição da tabela de agregação é semelhante a esta:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
Informações importantes
Consulte a seção Como criar tabelas de agregação na página de documentação Reconhecimento de agregação para dicas sobre como criar estrategicamente suas tabelas de agregação:
- Fatores de período
- Fatores de fuso horário
- Fatores de filtro
- Fatores de campo
- Fatores do tipo de medida
Compatibilidade com dialetos para reconhecimento agregado
A capacidade de usar o reconhecimento de agregação depende do dialeto do banco de dados usado pela conexão do Looker. Na versão mais recente do Looker, os seguintes dialetos são compatíveis com o reconhecimento de agregação:
| Dialeto | Compatível? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |