
Usage
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
היררכיה
aggregate_table |
ערך ברירת המחדל
ללא
אישור
שם לטבלה מסכמת, תת-פרמטר query להגדרת הטבלה ותת-פרמטר materialization להגדרת אסטרטגיית ההתמדה של הטבלה
כללים מיוחדים
|
הגדרה
הפרמטר aggregate_table משמש ליצירת טבלאות מצטברות שיצמצמו את מספר השאילתות שנדרשות לטבלאות הגדולות במסד הנתונים.
Looker משתמש בלוגיקה של מודעות לטבלאות מסכמות כדי למצוא את טבלת המסכמות הקטנה והיעילה ביותר שזמינה במסד הנתונים שלכם, ולהריץ שאילתה תוך שמירה על דיוק. (במאמר בנושא מודעות מצטברת מוסבר על טבלאות מצטברות ומוצעות אסטרטגיות ליצירתן).
אם יש לכם טבלאות גדולות מאוד במסד הנתונים, אתם יכולים ליצור טבלאות קטנות יותר של נתונים מסוכמים, שמקובצים לפי שילובים שונים של מאפיינים. הטבלאות המסכמות משמשות כטבלאות סיכום ש-Looker יכול להשתמש בהן לשאילתות כשאפשר, במקום בטבלה המקורית הגדולה.
אחרי שיוצרים את הטבלאות המצטברות, אפשר להריץ שאילתות בכלי הניתוחים כדי לראות באילו טבלאות מצטברות Looker משתמש. מידע נוסף מופיע בקטע קביעה של הטבלה המצטברת שמשמשת לשאילתה בדף התיעוד בנושא מודעות לטבלאות מצטברות.
בקטע פתרון בעיות בדף התיעוד בנושא מודעות מצטברת מפורטות סיבות נפוצות לכך שלא נעשה שימוש בטבלאות מצטברות.
הגדרת טבלה מסכמת ב-LookML
לכל פרמטר aggregate_table צריך להיות שם ייחודי בתוך explore נתון.
הפרמטר aggregate_table כולל את הפרמטרים המשניים query ו-materialization.
query
הפרמטר query מגדיר את השאילתה לטבלה מסכמת, כולל המאפיינים והמדדים שבהם יש להשתמש. הפרמטר query כולל את פרמטרי המשנה הבאים:
| שם הפרמטר | תיאור | דוגמה |
|---|---|---|
dimensions |
רשימה מופרדת בפסיקים של המאפיינים מ-Explore שרוצים לכלול בטבלה מסכמת. השדה dimensions הוא בפורמט הבא: dimensions: [dimension1, dimension2, ...]
כל מאפיין ברשימה הזו צריך להיות מוגדר כ-dimension בקובץ התצוגה של הניתוח של השאילתה. אם רוצים לכלול בשאילתת הניתוח שדה שמוגדר כשדה filter, אפשר להוסיף אותו לרשימה filters בשאילתת הטבלה המצטברת.
|
dimensions: [orders.created_month, orders.country] |
measures |
רשימה מופרדת בפסיקים של המדדים מ-Explore שרוצים לכלול בטבלה מסכמת. השדה measures הוא בפורמט הבא: measures: [measure1, measure2, ...]
מידע על סוגי המדדים שנתמכים ב'מודעות לצבירה' מופיע בקטע גורמים שמשפיעים על סוג המדד בדף התיעוד בנושא מודעות לצבירה.
|
measures: [orders.count] |
filters |
אופציונלי: מוסיף מסנן לquery. המסננים מתווספים לסעיף WHERE של ה-SQL שיוצר את הטבלה המצטברת.
השדה filters הוא בפורמט הבא: filters: [field1: "value1", field2: "value2", ...]
מידע על האופן שבו מסננים יכולים למנוע שימוש בטבלה מסכמת מופיע בקטע גורמי סינון בדף התיעוד בנושא מודעות לצבירה. |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
אופציונלי: מציין את שדות המיון ואת כיוון המיון (עולה או יורד) של query.
השדה sorts הוא בפורמט הבא: sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
מגדיר את אזור הזמן של query. אם לא מציינים אזור זמן, טבלה מסכמת לא תבצע המרה של אזור זמן, אלא תשתמש באזור הזמן של מסד הנתונים.
מידע על הגדרת אזור הזמן כדי להשתמש בטבלת הצבירה כמקור לשאילתה מופיע בקטע גורמים שקשורים לאזור הזמן בדף התיעוד בנושא צבירה.
סביבת הפיתוח המשולבת מציעה הצעות אוטומטיות לערך של אזור הזמן כשמקלידים את הפרמטר timezone בסביבת הפיתוח המשולבת. בנוסף, רשימת הערכים הנתמכים של אזורי הזמן מוצגת ב-Quick Help panel (חלונית העזרה המהירה) של IDE. |
timezone: America/Los_Angeles |
materialization
הפרמטר materialization מציין את אסטרטגיית השמירה של טבלת הצבירה, וגם אפשרויות אחרות לחלוקה, לחלוקה למחיצות, לאינדקסים ולקיבוץ באשכולות, שאולי נתמכות בניב ה-SQL שלכם.
כדי שהטבלה המצטברת תהיה נגישה לצורך מודעות מצטברת, היא צריכה להיות קבועה במסד הנתונים. הפרמטר materialization בטבלה המסכמת צריך לכלול אחד מתת-הפרמטרים הבאים כדי לציין את אסטרטגיית השמירה:
datagroup_triggersql_trigger_value-
persist_for(לא מומלץ)
בנוסף, ייתכן שהתת-פרמטרים הבאים של materialization ייתמכו בטבלה המסכמת, בהתאם לדיאלקט ה-SQL:
כדי ליצור טבלת צבירה מצטברת, משתמשים בפרמטרים המשניים הבאים של materialization:
datagroup_trigger
משתמשים בפרמטר datagroup_trigger כדי להפעיל את היצירה מחדש של טבלה מסכמת על סמך קבוצת נתונים קיימת שמוגדרת בקובץ המודל:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
משתמשים בפרמטר sql_trigger_value כדי להפעיל את היצירה מחדש של הטבלה המצטברת על סמך הצהרת SQL שאתם מספקים. אם התוצאה של הצהרת ה-SQL שונה מהערך הקודם, הטבלה נוצרת מחדש. ההצהרה sql_trigger_value הזו תגרום ליצירה מחדש של הנתונים כשהתאריך ישתנה:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
יש תמיכה גם בפרמטר persist_for בטבלאות מצטברות. עם זאת, יכול להיות ששיטת persist_for לא תניב את הביצועים הכי טובים מבחינת המודעות המצטברת למותג. הסיבה לכך היא שכאשר משתמש מריץ שאילתה שמסתמכת על טבלת persist_for, Looker בודק את גיל הטבלה בהשוואה להגדרה של persist_for. אם הטבלה ישנה יותר מההגדרה persist_for, המערכת יוצרת מחדש את הטבלה לפני הפעלת השאילתה. אם הגיל נמוך מההגדרה persist_for, נעשה שימוש בטבלה הקיימת. לכן, אלא אם משתמש מריץ שאילתה בתוך פרק הזמן של persist_for, צריך לבנות מחדש את הטבלה המסכמת כדי שאפשר יהיה להשתמש בה לצורך צבירה.
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
אלא אם אתם מבינים את המגבלות ויש לכם תרחיש שימוש ספציפי להטמעה של persist_for, עדיף להשתמש ב-datagroup_trigger או ב-sql_trigger_value כאסטרטגיית שמירה של טבלאות מצטברות.
cluster_keys
הפרמטר cluster_keys מאפשר להוסיף עמודה מסודרת באשכולות לטבלאות מחולקות למחיצות ב-BigQuery או ב-Snowflake. האשכולות ממיינים את הנתונים במחיצה על סמך הערכים בעמודות האשכולות, ומארגנים את עמודות האשכולות בבלוקים של אחסון בגודל אופטימלי.
מידע נוסף מופיע בדף התיעוד של הפרמטר cluster_keys.
distribution
הפרמטר distribution מאפשר לציין את העמודה מטבלת צבירה שבה רוצים להחיל מפתח חלוקה. distribution פועל רק עם מסדי נתונים של Redshift ו-Aster. עבור ניבים אחרים של SQL (כמו MySQL ו-Postgres), משתמשים במקום זאת ב-indexes.
מידע נוסף מופיע בדף התיעוד של הפרמטר distribution.
distribution_style
הפרמטר distribution_style מאפשר לכם לציין איך השאילתה לטבלת צבירה מפוזרת בין הצמתים במסד נתונים של Redshift:
-
distribution_style: allמציין שכל השורות מועתקות באופן מלא לכל צומת. -
distribution_style: evenמציין חלוקה שווה, כך שהשורות מחולקות לצמתים שונים בשיטת Round Robin.
מידע נוסף מופיע בדף התיעוד של הפרמטר distribution_style.
indexes
הפרמטר indexes מאפשר להחיל אינדקסים על העמודות של טבלה מסכמת.
מידע נוסף מופיע בדף התיעוד של הפרמטר indexes.
partition_keys
הפרמטר partition_keys מגדיר מערך של עמודות שלפיו טבלת הצבירה תחולק למחיצות. partition_keys תומך בניבים של מסדי נתונים שיש להם אפשרות לחלק עמודות. כשמריצים שאילתה שמסוננת בעמודה עם מחיצות, מסד הנתונים יסרוק רק את המחיצות שכוללות את הנתונים המסוננים, במקום לסרוק את כל הטבלה. partition_keys נתמך רק בדיאלקטים של Presto ו-BigQuery.
מידע נוסף מופיע בדף התיעוד של הפרמטר partition_keys.
publish_as_db_view
הפרמטר publish_as_db_view מאפשר לסמן טבלת צבירה לשליחת שאילתות מחוץ ל-Looker. בטבלאות מצטברות עם publish_as_db_view שהוגדר ל-yes, Looker יוצר תצוגת מסד נתונים יציבה במסד הנתונים עבור הטבלה המצטברת. התצוגה היציבה של מסד הנתונים נוצרת במסד הנתונים עצמו, כך שאפשר להריץ עליה שאילתות מחוץ ל-Looker.
מידע נוסף מופיע בדף התיעוד של הפרמטר publish_as_db_view.
sortkeys
הפרמטר sortkeys מאפשר לציין עמודה אחת או יותר בטבלת צבירה שבהן רוצים להחיל מפתח מיון רגיל.
מידע נוסף מופיע בדף התיעוד של הפרמטר sortkeys.
increment_key
אם הניב שלכם תומך ב-PDT מצטבר, אתם יכולים ליצור PDT מצטבר בפרויקט. טבלת PDT מצטברת היא טבלה נגזרת מתמידה (PDT) ש-Looker בונה על ידי הוספת נתונים חדשים לטבלה, במקום לבנות מחדש את הטבלה כולה. מידע נוסף זמין בדף התיעוד בנושא טבלאות PDT מצטברות.
טבלאות מצטברות הן סוג של PDT, ואפשר ליצור אותן באופן מצטבר על ידי הוספת הפרמטר increment_key. הפרמטר increment_key מציין את מרווח הזמן שלגביו צריך לשלוח שאילתה לנתונים עדכניים ולצרף אותם לטבלה מסכמת.
מידע נוסף מופיע בדף התיעוד של הפרמטר increment_key.
increment_offset
הפרמטר increment_offset מגדיר את מספר התקופות הקודמות (ברמת הפירוט של מפתח התוספת) שייבנו מחדש כשמוסיפים נתונים לטבלה מסכמת. הפרמטר increment_offset הוא אופציונלי ב-PDT מצטבר ובטבלאות מצטברות.
מידע נוסף מופיע בדף התיעוד של הפרמטר increment_offset.
קבלת LookML של טבלה מסכמת מחיפוש
כקיצור דרך, מפתחי Looker יכולים להשתמש בשאילתת Explore כדי ליצור טבלה מסכמת ואז להעתיק את ה-LookML לפרויקט של LookML:
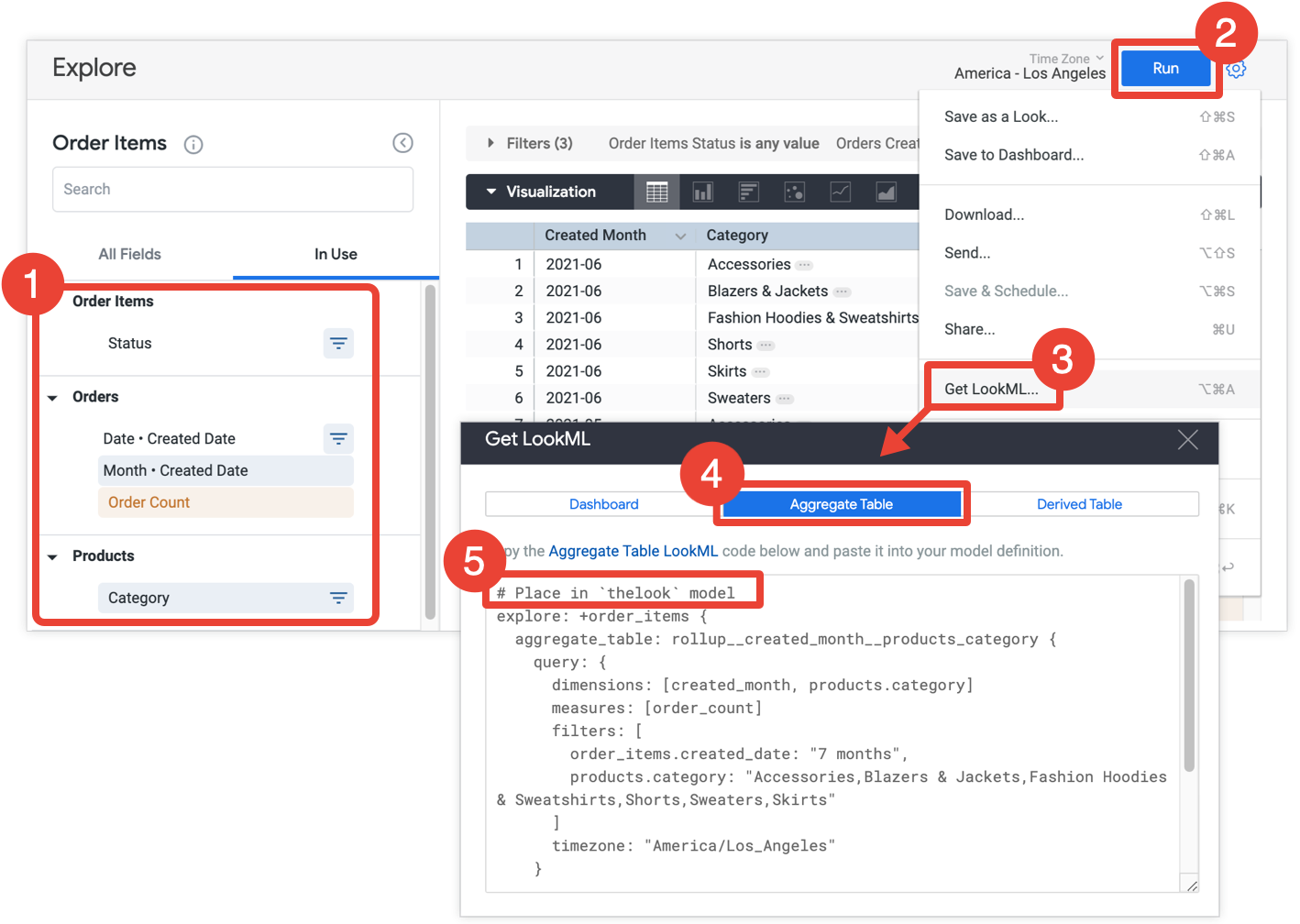
- ב-Explore, בוחרים את כל השדות והמסננים שרוצים לכלול בטבלה המסכמת.
- לוחצים על Run כדי לקבל את התוצאות.
- בתפריט גלגל השיניים של הכלי 'ניתוח נתונים', בוחרים באפשרות קבלת LookML. האפשרות הזו זמינה רק למפתחים ב-Looker.
- לוחצים על הכרטיסייה טבלת צבירה.
- Looker מספק את LookML עבור שיפור של Explore שיוסיף את הטבלה המסכמת ל-Explore. מעתיקים את קוד ה-LookML ומדביקים אותו בקובץ המודל המשויך, שמצוין בתגובה שלפני שיפור הניתוח. אם ה-Explore מוגדר בקובץ Explore נפרד ולא בקובץ מודל, אפשר להוסיף את השיפור לקובץ ה-Explore במקום לקובץ המודל. כל אחד מהמיקומים יפעל.
אם אתם צריכים לשנות את טבלת הצבירה ב-LookML, אתם יכולים לעשות זאת באמצעות הפרמטרים שמתוארים בקטע הגדרת טבלת צבירה ב-LookML בדף הזה. אתם יכולים לשנות את השם של טבלה מסכמת בלי לשנות את הרלוונטיות שלה לשאילתת העיון המקורית. עם זאת, שינויים אחרים בטבלה המסכמת עשויים להשפיע על היכולת של Looker להשתמש בטבלה המסכמת בשאילתת ה-Explore. בקטע עיצוב טבלאות מצטברות בדף התיעוד בנושא מודעות מצטברת מופיעים טיפים לאופטימיזציה של הטבלאות המצטברות כדי לוודא שהן משמשות למודעות מצטברת.
איך מקבלים LookML של טבלה מסכמת ממרכז בקרה
אפשרות נוספת למפתחי Looker היא לקבל את LookML של טבלה מסכמת לכל המשבצות בלוח בקרה, ואז להעתיק את LookML לפרויקט של LookML.
יצירת טבלאות מצטברות יכולה לשפר באופן משמעותי את הביצועים של לוח בקרה, במיוחד כשמדובר במשבצות שמריצות שאילתות על קבוצות נתונים גדולות.
אם יש לכם הרשאה develop, אתם יכולים לפתוח את לוח הבקרה, ללחוץ על סמל האפשרויות הנוספות (3 נקודות) בתפריט של לוח הבקרה, לבחור באפשרות Get LookML (קבלת LookML) ולבחור בכרטיסייה Aggregate Tables (טבלאות מצטברות) כדי לקבל את LookML ליצירת טבלאות מצטברות עבור לוח הבקרה:
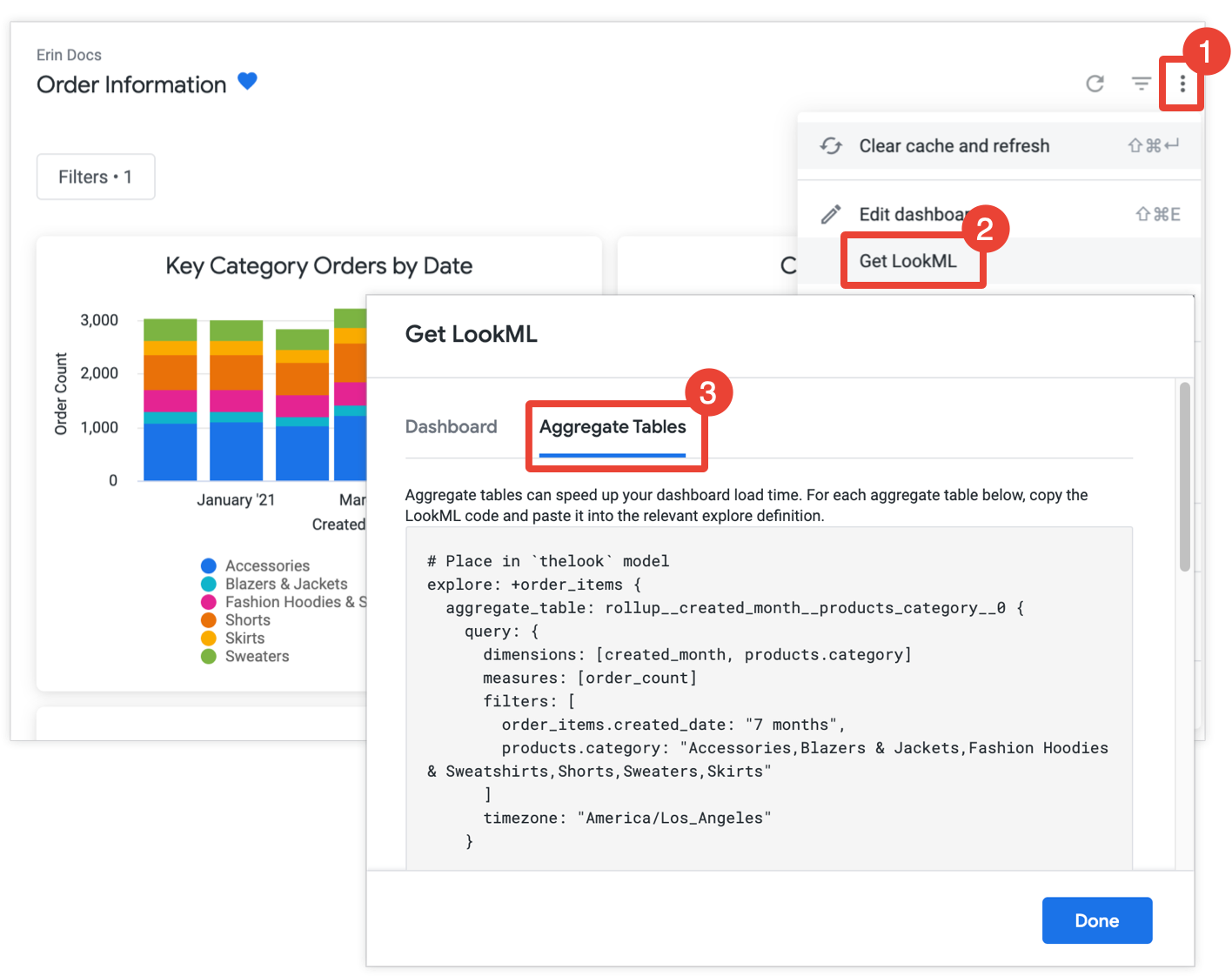
לכל משבצת שלא עברה אופטימיזציה באמצעות מודעות לטבלאות מסכמות, Looker מספק את קוד ה-LookML לשיפור של Explore, שיוסיף את הטבלה המסכמת ל-Explore. אם מרכז הבקרה כולל כמה משבצות מאותו ניתוח, Looker מציב את כל הטבלאות המצטברות בשיפור אחד של הניתוח. כדי לצמצם את מספר הטבלאות המצטברות שנוצרות, Looker קובע אם אפשר להשתמש בטבלה מצטברת שנוצרה ליותר מטייל אחד. אם כן, המערכת מסירה טבלאות מצטברות מיותרות שאפשר להשתמש בהן לפחות טיילים.
מעתיקים ומדביקים כל שיפור של ה-Explore בקובץ המודל המשויך, שמצוין בהערה שלפני השיפור של ה-Explore. אם ה-Explore מוגדר בקובץ Explore נפרד ולא בקובץ מודל, אפשר להוסיף את השיפור לקובץ ה-Explore במקום לקובץ המודל. כל אחד מהמיקומים יפעל.
אם מסנן של לוח בקרה מוחל על משבצת, Looker מוסיף את המאפיין של המסנן לטבלה המסכמת של המשבצת, כדי שאפשר יהיה להשתמש בטבלה המסכמת עבור המשבצת. הסיבה לכך היא שאפשר להשתמש בטבלאות מצטברות לשאילתה רק אם המסננים של השאילתה מפנים לשדות שזמינים כמאפיינים בטבלה המצטברת. מידע נוסף זמין בדף התיעוד בנושא מודעות מצטברת.
אם אתם צריכים לשנות את טבלת הצבירה ב-LookML, אתם יכולים לעשות זאת באמצעות הפרמטרים שמתוארים בקטע הגדרת טבלת צבירה ב-LookML בדף הזה. אפשר לשנות את השם של טבלת הצבירה בלי לשנות את הרלוונטיות שלה למשבצת המקורית במרכז הבקרה, אבל כל שינוי אחר בטבלת הצבירה עלול להשפיע על היכולת של Looker להשתמש בטבלת הצבירה בשביל מרכז הבקרה. בקטע עיצוב טבלאות מצטברות בדף התיעוד בנושא מודעות מצטברת מופיעים טיפים לאופטימיזציה של הטבלאות המצטברות כדי לוודא שהן משמשות למודעות מצטברת.
דוגמה
בדוגמה הבאה נוצרת טבלה מסכמת monthly_orders עבור event Explore. בטבלה המסכמת נוצר מספר הזמנות חודשי. Looker ישתמש בטבלה מסכמת עבור שאילתות של ספירת הזמנות שיכולות להסתמך על רמת הפירוט החודשית, כמו שאילתות של ספירת הזמנות שנתית, רבעונית וחודשית.
הטבלה המצטברת מוגדרת עם התמדה באמצעות datagroup orders_datagroup. בנוסף, הטבלה המצטברת מוגדרת עם publish_as_db_view: yes, כלומר Looker ייצור תצוגת מסד נתונים יציבה במסד הנתונים עבור הטבלה המצטברת.
הגדרת טבלה מסכמת נראית כך:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
דברים שכדאי לקחת בחשבון
בקטע תכנון טבלאות צבירה בדף התיעוד בנושא צבירת נתונים יש טיפים ליצירת טבלאות צבירה באופן אסטרטגי:
- גורמים שקשורים למסגרת הזמן
- גורמים שקשורים לאזור זמן
- גורמי סינון
- גורמים בשדה
- גורמים שמשפיעים על סוג המדידה
תמיכה בניבים להבנה של נתונים מצטברים
היכולת להשתמש ב-Aggregate Awareness תלויה בניב מסד הנתונים שבו משתמש החיבור שלכם ל-Looker. בגרסה האחרונה של Looker, הדיאלקטים הבאים תומכים ב-Aggregate Awareness:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13.x - 0.17.x | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud AlloyDB for PostgreSQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |