
派生表是一个查询,其结果可以像数据库中的物理表一样使用。原生派生表基于您使用 LookML 术语定义的查询。这与基于您使用 SQL 术语定义的查询的 基于 SQL 的派生表 不同。与基于 SQL 的派生表相比,原生派生表在您对数据进行建模时更容易阅读和理解。如需了解详情,请参阅 Looker 中的派生表文档页面的 原生派生表和基于 SQL 的派生表部分。
原生派生表和基于 SQL 的派生表都在 LookML 中使用 derived_table 参数在 视图 级别进行定义。不过,对于原生派生表,您无需创建 SQL 查询。相反,您可以使用 explore_source 参数指定派生表所基于的探索、所需的列和其他所需特征。
您还可以让 Looker 根据 SQL Runner 查询创建派生表 LookML,如使用 SQL Runner 创建派定表文档页面中所述。
使用探索开始定义原生派生表
从探索开始,Looker 可以为您的所有或大部分派生表生成 LookML。只需创建一个探索,然后选择要包含在派生表中的所有字段即可。然后,如需生成原生派生表 LookML,请按以下步骤操作:
选择探索操作 齿轮菜单,然后选择 Get LookML 。
点击派生表 标签页,查看用于为探索创建原生派生表的 LookML。
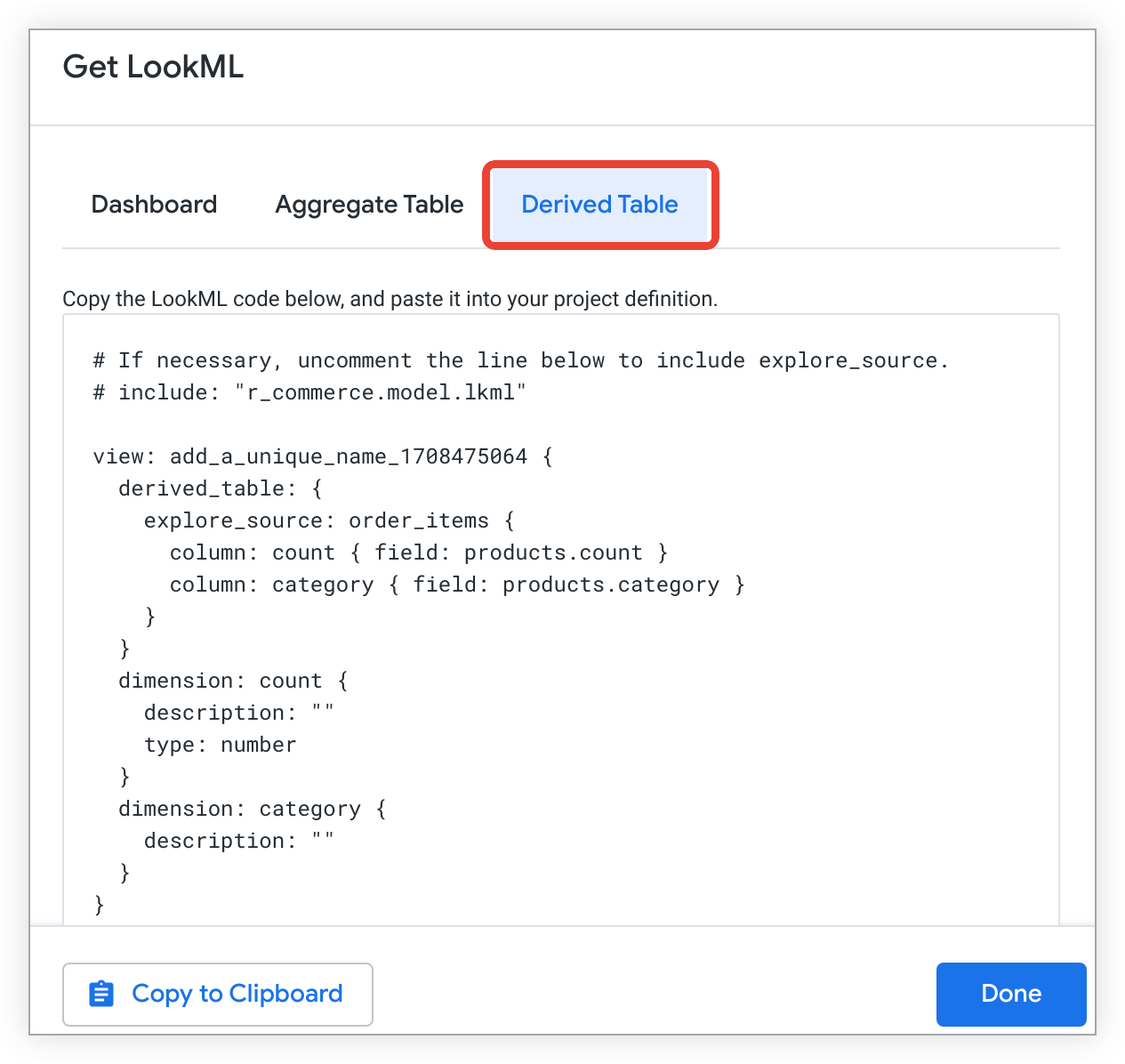
复制 LookML。
现在,您已复制生成的 LookML,请将其粘贴到视图文件中:
点击 Looker IDE 中项目文件列表顶部的 + ,然后选择创建视图 。或者,您可以点击文件夹的菜单,然后从菜单中选择创建视图,以在文件夹内创建文件。
将视图名称设置为有意义的名称。
(可选)更改列名称、指定派生列和添加过滤条件。
在探索中使用 measure 的
type: count时,可视化图表会使用视图名称(而不是“Count”一词)为结果值添加标签。为避免混淆,请将视图名称设为复数形式。您可以通过以下任一方式更改视图名称:在可视化图表设置中选择系列 下的显示完整字段名称 ,或者使用view_label参数并使用视图名称的复数形式。
在 LookML 中定义原生派生表
无论您使用在 SQL 中声明的派生表还是原生 LookML,derived_table's 的查询输出都是包含一组列的表。当派生表以 SQL 表示时,输出列名称由 SQL 查询暗示。例如,以下 SQL 查询将具有输出列 user_id、lifetime_number_of_orders 和 lifetime_customer_value:
SELECT
user_id
, COUNT(DISTINCT order_id) as lifetime_number_of_orders
, SUM(sale_price) as lifetime_customer_value
FROM order_items
GROUP BY 1
在 Looker 中,查询基于探索,包含度量和维度字段,添加任何适用的过滤条件,并且还可以指定排序顺序。原生派生表包含所有这些元素以及列的输出名称。
以下简单示例生成一个包含三列的派生表:user_id、lifetime_customer_value 和 lifetime_number_of_orders。您无需在 SQL 中手动编写查询,而是由 Looker 使用指定的探索 order_items 和该探索的一些字段(order_items.user_id、order_items.total_revenue 和 order_items.order_count)为您创建查询。
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
}
使用 include 语句启用字段引用
在原生派生表的视图文件中,您可以使用 explore_source 参数指向探索,并为原生派生表定义列和其他特征。
在原生派生表的视图文件中,您无需使用 include 参数指向包含探索定义的文件。如果您没有 include 语句,Looker IDE 在您构建原生派生表时不会 autosuggest 字段名称或验证您的字段引用。不过,您可以使用 LookML 验证器 来验证您在原生派生表中引用的字段。
但是,如果您想在 Looker IDE 中启用自动建议和即时字段验证,或者您有一个复杂的 LookML 项目,其中包含多个同名探索或可能存在循环引用,则可以使用 include 参数指向探索定义的位置。
探索通常在模型文件中定义,但对于原生派生表,为探索创建单独的文件会更简洁。LookML 探索文件的文件扩展名为 .explore.lkml,如 创建探索文件文档中所述。这样,在原生派生表视图文件中,您可以包含单个探索文件,而不是整个模型文件。
如果您确实想创建单独的探索文件,并使用 include 参数指向原生派生表视图文件中的探索文件,请确保您的 LookML 文件满足以下要求:
- 原生派生表的视图文件应包含探索的文件。例如:
include: "/explores/order_items.explore.lkml"
- 探索的文件应包含所需的视图文件。例如:
include: "/views/order_items.view.lkml"include: "/views/users.view.lkml"
- 模型应包含探索的文件。例如:
include: "/explores/order_items.explore.lkml"
定义原生派生表列
指定列名称
对于 user_id 列,列名称与原始探索中指定字段的名称一致。
通常,您希望输出表中的列名称与原始探索中的字段名称不同。上例使用 order_items 探索生成了按用户计算的生命周期价值。在输出表中,total_revenue 实际上是客户的 lifetime_customer_value。
column 声明支持声明与输入字段不同的输出名称。例如,以下代码指示 Looker“根据字段 order_items.total_revenue 创建名为 lifetime_value 的输出列”:
column: lifetime_value {
field: order_items.total_revenue
}
隐含列名称
如果列声明中缺少 field 参数,则假定为 <explore_name>.<field_name>。例如,如果您指定了 explore_source: order_items,则
column: user_id {
field: order_items.user_id
}
等效于
column: user_id {}
为计算值创建派生列
您可以添加 derived_column 参数,以指定 explore_source 参数的探索中不存在的列。每个 derived_column 参数都有一个 sql 参数,用于指定如何构造值。
您的 sql 计算可以使用您使用 column 参数指定的任何列。派生列不能包含聚合函数,但可以包含可在表的单行上执行的计算。
以下示例生成的派生表与之前的示例相同,不同之处在于它添加了一个计算出的 average_customer_order 列,该列根据原生派生表中的 lifetime_customer_value 和 lifetime_number_of_orders 列计算得出。
view: user_order_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: lifetime_number_of_orders {
field: order_items.order_count
}
column: lifetime_customer_value {
field: order_items.total_revenue
}
derived_column: average_customer_order {
sql: lifetime_customer_value / lifetime_number_of_orders ;;
}
}
}
# Define the view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: lifetime_number_of_orders {
type: number
}
dimension: lifetime_customer_value {
type: number
}
dimension: average_customer_order {
type: number
}
}
使用 SQL 窗口函数
某些数据库方言支持窗口函数,尤其是用于创建序列号、主键、运行总计和累计总计以及其他有用的多行计算。在主查询执行完毕后,任何 derived_column 声明都会在单独的传递中执行。
如果您的数据库方言支持窗口函数,则可以在原生派生表中使用它们。创建一个 derived_column 参数,其中包含一个包含所需窗口函数的 sql 参数。引用值时,应使用在原生派生表中定义的列名称。
以下示例创建一个原生派生表,其中包含 user_id、order_id 和 created_time 列。然后,它使用带有 SQL ROW_NUMBER() 窗口函数的派生列,计算包含客户订单序列号的列。
view: user_order_sequences {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: order_id {
field: order_items.order_id
}
column: created_time {
field: order_items.created_time
}
derived_column: user_sequence {
sql: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_time) ;;
}
}
}
dimension: order_id {
hidden: yes
}
dimension: user_sequence {
type: number
}
}
向原生派生表添加过滤条件
假设您想构建一个派生表,其中包含客户在过去 90 天内的价值。您希望执行与上例相同的计算,但只希望包含过去 90 天内的购买交易。
您只需向 derived_table 添加一个过滤条件,以过滤过去 90 天内的交易。派生表的 filters 参数使用的语法与您创建 过滤后的度量 时使用的语法相同。
view: user_90_day_facts {
derived_table: {
explore_source: order_items {
column: user_id {
field: order_items.user_id
}
column: number_of_orders_90_day {
field: order_items.order_count
}
column: customer_value_90_day {
field: order_items.total_revenue
}
filters: [order_items.created_date: "90 days"]
}
}
# Add define view's fields as desired
dimension: user_id {
hidden: yes
}
dimension: number_of_orders_90_day {
type: number
}
dimension: customer_value_90_day {
type: number
}
}
当 Looker 为派生表编写 SQL 时,过滤条件将添加到 WHERE 子句中。
此外,您还可以将 dev_filters 子参数与 explore_source 搭配原生派生表使用。借助 dev_filters 参数,您可以指定 Looker 仅应用于派生表的开发版本的过滤条件,这意味着您可以构建较小的过滤后的表版本,以便在每次更改后进行迭代和测试,而无需等待完整表构建完毕。
dev_filters 参数与 filters 参数结合使用,以便将所有过滤条件应用于表的开发版本。如果 dev_filters 和 filters 都为同一列指定了过滤条件,则 dev_filters 优先用于表的开发版本。
如需了解详情,请参阅在开发模式下更快地工作。
使用模板化过滤条件
您可以使用 bind_filters 来包含 模板化过滤条件:
bind_filters: {
to_field: users.created_date
from_field: filtered_lookml_dt.filter_date
}
这与在 sql 代码块中使用以下代码基本相同:
{% condition filtered_lookml_dt.filter_date %} users.created_date {% endcondition %}
to_field 是应用过滤条件的字段。to_field 必须是底层 explore_source 中的字段。
from_field 用于指定从哪个字段获取过滤条件(如果在运行时存在过滤条件)。
在上面的 bind_filters 示例中,Looker 会获取应用于 filtered_lookml_dt.filter_date 字段的任何过滤条件,并将该过滤条件应用于 users.created_date 字段。
您还可以使用 bind_all_filters 子参数,将探索中的所有运行时过滤条件传递给原生派生表子查询。explore_source如需了解详情,请参阅 explore_source 参数文档页面。
对原生派生表进行排序和限制
sorts: [order_items.count: desc]
limit: 10
请注意,探索可能会以与底层排序不同的顺序显示行。
将原生派生表转换为不同的时区
您可以使用 timezone 子参数为原生派生表指定时区:
timezone: "America/Los_Angeles"
使用 timezone 子参数时,原生派生表中的所有基于时间的数据都将转换为您指定的时区。如需查看受支持的时区列表,请参阅 timezone 值 文档页面。
如果您未在原生派生表定义中指定时区,则原生派生表不会对基于时间的数据执行任何时区转换,而是将基于时间的数据默认为您的 数据库时区。
如果原生派生表不是 永久性的,您可以将时区值设置为 "query_timezone",以自动使用当前运行的查询的时区。