
בדף הזה אנחנו מתייחסים לפרמטר
typeשהוא חלק מmeasure.אפשר להשתמש ב-
typeגם כחלק ממאפיין או מסנן, כמו שמתואר בדף התיעוד סוגי מאפיינים, מסננים ופרמטרים.אפשר להשתמש ב-
typeגם כחלק מקבוצת מאפיינים, כמו שמתואר בדף התיעוד של הפרמטרdimension_group.
Usage
view: view_name {
measure: field_name {
type: measure_field_type
}
}
|
היררכיה
type |
סוגי שדות אפשריים
מדידה
אישור
סוג המדד
|
בדף הזה מפורטים הסוגים השונים שאפשר להקצות למדד. למדד יכול להיות רק סוג אחד, וסוג ברירת המחדל הוא string אם לא מצוין סוג.
לחלק מסוגי המדדים יש פרמטרים תומכים, שמתוארים בקטע המתאים.
קטגוריות של סוגי מדידה
כל סוג של מדד משתייך לאחת מהקטגוריות הבאות. הקטגוריות האלה קובעות אם סוג המדד מבצע צבירות, את סוג השדות שסוג המדד יכול להפנות אליהם ואם אפשר לסנן את סוג המדד באמצעות הפרמטר filters:
- מדדים מצטברים: סוגי מדדים מצטברים מבצעים צבירות, כמו
sumו-average. מדדים מצטברים יכולים להפנות רק למאפיינים, ולא למדדים אחרים. זהו סוג המדידה היחיד שפועל עם הפרמטרfilters. - מדדים לא מצטברים: מדדים לא מצטברים הם, כפי שהשם מרמז, סוגי מדדים שלא מבצעים צבירות, כמו
numberו-yesno. סוגי המדדים האלה מבצעים טרנספורמציות בסיסיות, ומכיוון שהם לא מבצעים צבירות, הם יכולים להפנות רק למדדים מצטברים או למאפיינים מצטברים קודמים. אי אפשר להשתמש בפרמטרfiltersעם סוגי המדידה האלה. - מדדים מסוג Post-SQL: מדדים מסוג Post-SQL הם סוגים מיוחדים של מדדים שמבצעים חישובים ספציפיים אחרי ש-Looker יוצר שאילתת SQL. הם יכולים להתייחס רק למדדים מספריים או למאפיינים מספריים. אי אפשר להשתמש בפרמטר
filtersעם סוגי המדידה האלה.
רשימה של הגדרות סוג
| סוג | קטגוריה | תיאור |
|---|---|---|
average |
במצטבר | יצירת ממוצע של ערכים בעמודה |
average_distinct |
במצטבר | יוצרת ממוצע (mean) של ערכים בצורה נכונה כשמשתמשים בנתונים לא מנורמלים. תיאור מלא מופיע בקטע average_distinct. |
count |
במצטבר | יצירת ספירה של שורות |
count_distinct |
במצטבר | יצירת ספירה של ערכים ייחודיים בעמודה |
date |
לא מצטבר | למדדים שמכילים תאריכים |
list |
במצטבר | יצירת רשימה של הערכים הייחודיים בעמודה |
max |
במצטבר | יצירת הערך המקסימלי בעמודה |
median |
במצטבר | יוצרת את החציון (ערך נקודת האמצע) של הערכים בעמודה |
median_distinct |
במצטבר | יוצרת חציון (ערך אמצעי) של הערכים בצורה נכונה כשפעולת הצטרפות גורמת להתרחבות. תיאור מלא מופיע בקטע median_distinct. |
min |
במצטבר | יצירת הערך המינימלי בעמודה |
number |
לא מצטבר | למדדים שמכילים מספרים |
percent_of_previous |
Post-SQL | יצירת ההבדל באחוזים בין השורות שמוצגות |
percent_of_total |
Post-SQL | יצירת אחוז מהסך הכולל לכל שורה שמוצגת |
percentile |
במצטבר | יצירת הערך באחוזון שצוין בעמודה |
percentile_distinct |
במצטבר | הפונקציה יוצרת את הערך באחוזון שצוין בצורה תקינה כשפעולת הצטרפות גורמת להתרחבות. תיאור מלא מופיע בקטע percentile_distinct. |
running_total |
Post-SQL | יצירת סכום מצטבר לכל שורה שמוצגת |
period_over_period |
במצטבר | הפניה לצבירה מתקופה מוקדמת יותר |
string |
לא מצטבר | למדדים שמכילים אותיות או תווים מיוחדים (כמו בפונקציה GROUP_CONCAT של MySQL) |
sum |
במצטבר | יצירת סכום של ערכים בעמודה |
sum_distinct |
במצטבר | יוצר סכום של ערכים בצורה נכונה כשמשתמשים בנתונים לא מנורמלים.תיאור מלא מופיע בקטע sum_distinct. |
yesno |
לא מצטבר | בשדות שבהם מוצג הערך true או false |
int |
לא מצטבר |
הוסר 5.4
הוחלף על ידי type: number |
average
הפונקציה type: average מחשבת את הממוצע של הערכים בשדה נתון. היא דומה לפונקציה AVG ב-SQL. עם זאת, בניגוד ל-SQL גולמי, Looker יחשב את הממוצעים בצורה נכונה גם אם הצטרפויות השאילתה מכילות פיצולים.
הפרמטר sql למדדי type: average יכול לקבל כל ביטוי SQL תקין שמניב עמודה מספרית בטבלה, מאפיין LookML או שילוב של מאפייני LookML.
אפשר לעצב שדות type: average באמצעות הפרמטרים value_format או value_format_name.
לדוגמה, קוד ה-LookML הבא יוצר שדה בשם avg_order על ידי חישוב הממוצע של המאפיין sales_price, ואז מציג אותו בפורמט של כסף ($1,234.56):
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct מיועד לשימוש עם קבוצות נתונים לא מנורמלות. הפונקציה מחשבת את הממוצע של הערכים הלא חוזרים בשדה נתון, על סמך הערכים הייחודיים שמוגדרים על ידי הפרמטר sql_distinct_key.
זהו מושג מתקדם, שאולי יהיה קל יותר להבין אותו באמצעות דוגמה. נניח שיש לכם טבלה לא מנורמלת כזו:
| מזהה הפריט בהזמנה | מזהה ההזמנה | משלוח הזמנה |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
במצב כזה, אפשר לראות שיש כמה שורות לכל הזמנה. לכן, אם הוספתם מדד בסיסי type: average לעמודה order_shipping, תקבלו את הערך 16.00, למרות שהממוצע בפועל הוא 15.00.
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
כדי לקבל תוצאה מדויקת, אפשר להגדיר ב-Looker איך לזהות כל ישות ייחודית (במקרה הזה, כל הזמנה ייחודית) באמצעות הפרמטר sql_distinct_key. החישוב יהיה נכון ויניב את הסכום 15.00:
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
לכל ערך ייחודי של sql_distinct_key צריך להיות רק ערך תואם אחד ב-sql. במילים אחרות, הדוגמה הקודמת פועלת כי כל שורה עם ערך order_id של 1 כוללת את אותו ערך order_shipping של 10.00, וכל שורה עם ערך order_id של 2 כוללת את אותו ערך order_shipping של 20.00.
אפשר לעצב שדות type: average_distinct באמצעות הפרמטרים value_format או value_format_name.
count
type: count מבצעת ספירה בטבלה, בדומה לפונקציה COUNT ב-SQL. עם זאת, בניגוד ל-SQL גולמי, Looker יחשב את הספירות בצורה נכונה גם אם הצטרפות השאילתה מכילה פיצולים.
מדדי type: count מבצעים ספירות של טבלאות שמבוססות על המפתח הראשי של הטבלה, ולכן מדדי type: count לא תומכים בפרמטר sql.
אם רוצים לבצע ספירה של שורות בטבלה בשדה שהוא לא המפתח הראשי של הטבלה, צריך להשתמש במדד type: count_distinct. לחלופין, אם לא רוצים להשתמש ב-count_distinct, אפשר להשתמש במדד type: number (מידע נוסף זמין בפוסט לקהילה How to count a non-primary key).
לדוגמה, קוד ה-LookML הבא יוצר שדה number_of_products:
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
בדרך כלל, כשמגדירים מדד type: count, מציינים פרמטר drill_fields (לשדות) כדי שהמשתמשים יוכלו לראות את הרשומות הבודדות שמרכיבות את הספירה כשהם לוחצים עליה.
כשמשתמשים במדד של
type: countב'ניתוח נתונים', התוויות של הערכים שמתקבלים בתרשים הן השם של התצוגה ולא המילה 'ספירה'. כדי למנוע בלבול, מומלץ להשתמש בשם ברבים לתצוגה, לבחור באפשרות הצגת שם השדה המלא בקטע סדרה בהגדרות הוויזואליזציה, או להשתמש ב-view_labelעם גרסה ברבים של שם התצוגה.
אפשר להוסיף מסנן למדד type: count באמצעות הפרמטר filters.
count_distinct
type: count_distinct מחשבת את מספר הערכים הייחודיים בשדה נתון. היא משתמשת בפונקציה COUNT DISTINCT של SQL.
הפרמטר sql למדדים של type: count_distinct יכול לקבל כל ביטוי SQL תקין שיוצר עמודה בטבלה, מאפיין LookML או שילוב של מאפייני LookML.
לדוגמה, קוד ה-LookML הבא יוצר שדה number_of_unique_customers שסופר את מספר מזהי הלקוחות הייחודיים:
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
אפשר להוסיף מסנן למדד type: count_distinct באמצעות הפרמטר filters.
date
type: date משמש עם שדות שמכילים תאריכים.
הפרמטר sql למדדים של type: date יכול לקבל כל ביטוי SQL תקין שמניב תאריך. בפועל, השימוש בסוג הזה נדיר, כי רוב פונקציות הצבירה של SQL לא מחזירות תאריכים. דוגמה נפוצה היא MIN או MAX של מאפיין תאריך.
יצירת מדד של תאריך מקסימלי או מינימלי באמצעות type: date
אם רוצים ליצור מדד של תאריך מקסימלי או מינימלי, יכול להיות שתחשבו בהתחלה שאפשר להשתמש במדד של type: max או של type: min. עם זאת, סוגי המדידה האלה תואמים רק לשדות מספריים. במקום זאת, אפשר לתעד תאריך מקסימלי או מינימלי על ידי הגדרת מדד של type: date והוספת שדה התאריך שמפנים אליו בפרמטר sql לפונקציה MIN() או MAX().
נניח שיש לכם קבוצת מאפיינים של type: time, שנקראת updated:
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
כדי ליצור מדד של type: date שיציג את התאריך המקסימלי של קבוצת המאפיינים הזו, אפשר לפעול לפי השלבים הבאים:
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
בדוגמה הזו, במקום להשתמש במדד type: max כדי ליצור את המדד last_updated_date, הפונקציה MAX() מוחלת בפרמטר sql. בנוסף, הפרמטר last_updated_date של המדד last_updated_date מוגדר לערך no כדי למנוע המרה כפולה של אזור הזמן במדד, כי ההמרה של אזור הזמן כבר התרחשה בהגדרה של קבוצת המאפיינים updated.convert_tz מידע נוסף זמין במאמר בנושא הפרמטר convert_tz.
בדוגמה של LookML למדד last_updated_date, אפשר להשמיט את type: date, והערך יטופל כמחרוזת, כי string הוא ערך ברירת המחדל של type. עם זאת, אם תשתמשו ב-type: date, תוכלו לסנן את התוצאות בצורה טובה יותר עבור המשתמשים.
יכול להיות שתשימו לב גם שההגדרה של המדד last_updated_date מתייחסת למסגרת הזמן ${updated_raw} במקום למסגרת הזמן ${updated_date}. מכיוון שהערך שמוחזר מהפונקציה ${updated_date} הוא מחרוזת, צריך להשתמש בפונקציה ${updated_raw} כדי להפנות לערך התאריך בפועל.
אפשר גם להשתמש בפרמטר datatype עם type: date כדי לשפר את ביצועי השאילתות. לשם כך, צריך לציין את סוג נתוני התאריכים שמשמשים בטבלת מסד הנתונים.
יצירת מדד מקסימום או מינימום לעמודה של תאריך ושעה
חישוב הערך המקסימלי בעמודה type: datetime מתבצע בצורה קצת שונה. במקרה כזה, כדאי ליצור מדד בלי להצהיר על הסוג, כך:
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list יוצרת רשימה של הערכים הייחודיים בשדה נתון. היא דומה לפונקציה GROUP_CONCAT ב-MySQL.
אין צורך לכלול פרמטר sql למדדי type: list. במקום זאת, אפשר להשתמש בפרמטר list_field כדי לציין את המימד שממנו רוצים ליצור רשימות.
השימוש הוא כדלקמן:
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
לדוגמה, קוד LookML הבא יוצר מדד name_list על סמך המאפיין name:
measure: name_list {
type: list
list_field: name
}
חשוב לזכור את הנקודות הבאות לגבי list:
- אי אפשר לסנן את סוג המדד
list. אי אפשר להשתמש בפרמטרfiltersבמדדtype: list. - אי אפשר להפנות לסוג המדד
listבאמצעות אופרטור ההחלפה ($). אי אפשר להשתמש בתחביר${}כדי להפנות למדדtype: list.
ניבים נתמכים של מסדי נתונים עבור list
כדי ש-Looker יתמוך ב-type: list בפרויקט Looker שלכם, הניב של מסד הנתונים שלכם צריך לתמוך בו גם כן. בטבלה הבאה מפורטות הניבים שכוללים תמיכה ב-type: list בגרסה האחרונה של Looker:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
max
הפונקציה type: max מוצאת את הערך הגדול ביותר בשדה נתון. היא משתמשת בפונקציה MAX של SQL.
הפרמטר sql למדדים של type: max יכול לקבל כל ביטוי SQL תקין שמניב עמודה מספרית בטבלה, מאפיין LookML או שילוב של מאפייני LookML.
מכיוון שהמדדים של type: max תואמים רק לשדות מספריים, אי אפשר להשתמש במדד של type: max כדי למצוא תאריך מקסימלי. במקום זאת, אפשר להשתמש בפונקציה MAX() בפרמטר sql של מדד type: date כדי לתעד תאריך מקסימלי, כמו שמוצג בדוגמאות הקודמות בקטע date.
אפשר לעצב שדות type: max באמצעות הפרמטרים value_format או value_format_name.
לדוגמה, קוד ה-LookML הבא יוצר שדה בשם largest_order על ידי עיון במאפיין sales_price, ואז מציג אותו בפורמט של כסף ($1,234.56):
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
אי אפשר להשתמש במדדים של type: max למחרוזות או לתאריכים, אבל אפשר להוסיף ידנית את הפונקציה MAX כדי ליצור שדה כזה, כמו בדוגמה הבאה:
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median מחזירה את ערך נקודת האמצע של הערכים בשדה נתון. האפשרות הזו שימושית במיוחד אם בנתונים יש כמה ערכים חריגים גדולים או קטנים מאוד שיגרמו להטיה בממוצע הבסיסי של הנתונים.
לדוגמה, נניח שיש לכם טבלה כזו:
| מזהה הפריט בהזמנה | עלות | נקודת אמצע? |
|---|---|---|
| 2 | 10.00 | |
| 4 | 10.00 | |
| 3 | 20.00 | ערך נקודת האמצע |
| 1 | 80.00 | |
| 5 | 90.00 |
הטבלה ממוינת לפי עלות, אבל זה לא משפיע על התוצאה. הפונקציה average תחזיר את הערך 42 (סכום כל הערכים חלקי 5), והפונקציה median תחזיר את ערך נקודת האמצע: 20.00.
אם יש מספר זוגי של ערכים, ערך החציון מחושב על ידי מציאת הממוצע של שני הערכים הקרובים ביותר לנקודת האמצע. נניח שיש לכם טבלה כזו עם מספר זוגי של שורות:
| מזהה הפריט בהזמנה | עלות | נקודת אמצע? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | הכי קרוב לפני אמצע המסלול |
| 1 | 80 | הקרוב ביותר אחרי אמצע המסלול |
| 4 | 90 |
החציון, הערך האמצעי, הוא (20 + 80)/2 = 50.
החציון שווה גם לערך באחוזון ה-50.
הפרמטר sql למדדי type: median יכול לקבל כל ביטוי SQL תקין שמניב עמודה מספרית בטבלה, מאפיין LookML או שילוב של מאפייני LookML.
אפשר לעצב שדות type: median באמצעות הפרמטרים value_format או value_format_name.
דוגמה
לדוגמה, קוד ה-LookML הבא יוצר שדה בשם median_order על ידי חישוב הממוצע של המאפיין sales_price, ואז מציג אותו בפורמט של כסף ($1,234.56):
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
נקודות שכדאי לקחת בחשבון לגבי median
אם משתמשים ב-median בשדה שמעורב בפיצול, Looker ינסה להשתמש ב-median_distinct במקום זאת. עם זאת, medium_distinct נתמך רק בניבים מסוימים. אם median_distinct לא זמין בניב שלכם, Looker מחזיר שגיאה. מכיוון שאפשר להתייחס ל-median כאחוזון ה-50, מצב השגיאה מציין שהדיאלקט לא תומך באחוזונים נפרדים.
ניבים נתמכים של מסדי נתונים עבור median
כדי ש-Looker יתמוך בסוג median בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בו גם כן. בטבלה הבאה מפורטים הניבים שתומכים בסוג median בגרסה האחרונה של Looker:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
כשיש פיצול שאילתה, Looker מנסה להמיר את median ל-median_distinct. ההצלחה של התהליך הזה תלויה בדיאלקטים שתומכים ב-median_distinct.
median_distinct
משתמשים ב-type: median_distinct כשמצטרפים לפגישה שכוללת פיצול. הפונקציה מחשבת את הממוצע של הערכים הלא חוזרים בשדה נתון, על סמך הערכים הייחודיים שמוגדרים על ידי הפרמטר sql_distinct_key. אם למדד אין פרמטר sql_distinct_key, Looker מנסה להשתמש בשדה primary_key.
נניח שזו התוצאה של שאילתה שמצטרפת לטבלאות Order Item ו-Order:
| מזהה הפריט בהזמנה | מזהה ההזמנה | משלוח הזמנה |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
במצב כזה, אפשר לראות כמה שורות לכל הזמנה. השאילתה הזו כללה פיצול (fanout) כי כל הזמנה ממופה לכמה פריטים בהזמנה. הפונקציה median_distinct לוקחת את זה בחשבון ומוצאת את החציון בין הערכים השונים 10, 20 ו-50, כך שהערך שמתקבל הוא 20.
כדי לקבל תוצאה מדויקת, אפשר להגדיר ב-Looker איך לזהות כל ישות ייחודית (במקרה הזה, כל הזמנה ייחודית) באמצעות הפרמטר sql_distinct_key. המערכת תחשב את הסכום הנכון:
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
לכל ערך ייחודי של sql_distinct_key צריך להיות רק ערך תואם אחד בפרמטר sql של המדד. במילים אחרות, הדוגמה הקודמת פועלת כי כל שורה עם ערך order_id של 1 כוללת ערך order_shipping של 10, וכל שורה עם ערך order_id של 2 כוללת ערך order_shipping של 20.
אפשר לעצב שדות type: median_distinct באמצעות הפרמטרים value_format או value_format_name.
נקודות שכדאי לקחת בחשבון לגבי median_distinct
סוג המדד medium_distinct נתמך רק בניבים מסוימים. אם median_distinct לא זמין לדיאלקט, Looker מחזיר שגיאה. מכיוון שאפשר להתייחס ל-median כאחוזון ה-50, מצב השגיאה מציין שהדיאלקט לא תומך באחוזונים נפרדים.
ניבים נתמכים של מסדי נתונים עבור median_distinct
כדי ש-Looker יתמוך בסוג median_distinct בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בו גם כן. בטבלה הבאה מפורטים הניבים שתומכים בסוג median_distinct בגרסה האחרונה של Looker:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
min
type: min מוצאת את הערך הקטן ביותר בשדה נתון. היא משתמשת בפונקציה MIN של SQL.
הפרמטר sql למדדים של type: min יכול לקבל כל ביטוי SQL תקין שמניב עמודה מספרית בטבלה, מאפיין LookML או שילוב של מאפייני LookML.
מכיוון שהמדדים של type: min תואמים רק לשדות מספריים, אי אפשר להשתמש במדד של type: min כדי למצוא תאריך מינימלי. במקום זאת, אפשר להשתמש בפונקציה MIN() בפרמטר sql של מדד type: date כדי לתעד תאריך מינימלי, בדיוק כמו שאפשר להשתמש בפונקציה MAX() עם מדד type: date כדי לתעד תאריך מקסימלי. הסבר על כך מופיע בקטע date בדף הזה, שכולל דוגמאות לשימוש בפונקציה MAX() בפרמטר sql כדי למצוא תאריך מקסימלי.
אפשר לעצב שדות type: min באמצעות הפרמטרים value_format או value_format_name.
לדוגמה, קוד ה-LookML הבא יוצר שדה בשם smallest_order על ידי עיון במאפיין sales_price, ואז מציג אותו בפורמט של כסף ($1,234.56):
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
אי אפשר להשתמש במדדים של type: min למחרוזות או לתאריכים, אבל אפשר להוסיף ידנית את הפונקציה MIN כדי ליצור שדה כזה, כמו בדוגמה הבאה:
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number משמש עם מספרים או מספרים שלמים. מדד type: number לא מבצע צבירה, והוא נועד לבצע טרנספורמציות בסיסיות במדדים אחרים. אם מגדירים מדד שמבוסס על מדד אחר, המדד החדש צריך להיות מסוג type: number כדי למנוע שגיאות של צבירה מקוננת.
הפרמטר sql של מדדי type: number יכול לקבל כל ביטוי SQL תקין שמחזיר מספר או מספר שלם.
אפשר לעצב שדות type: number באמצעות הפרמטרים value_format או value_format_name.
לדוגמה, קוד ה-LookML הבא יוצר מדד בשם total_gross_margin_percentage על סמך המדדים המצטברים total_sale_price ו-total_gross_margin, ואז מציג אותו בפורמט של אחוז עם שתי ספרות אחרי הנקודה העשרונית (12.34%):
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
בדוגמה הזו נעשה שימוש גם בפונקציית ה-SQL NULLIF() כדי למנוע שגיאות של חלוקה באפס.
נקודות שכדאי לקחת בחשבון לגבי type: number
יש כמה דברים חשובים שכדאי לזכור כשמשתמשים במדדים של type: number:
- מדד
type: numberיכול לבצע פעולות אריתמטיות רק על מדדים אחרים, ולא על מאפיינים אחרים. - צבירות סימטריות ב-Looker לא יגנו על פונקציות צבירה ב-SQL של מדד
type: numberכשהן מחושבות על פני שאילתת איחוד (join). - אי אפשר להשתמש בפרמטר
filtersעם מדדיtype: number, אבל במסמכי התיעוד שלfiltersמוסבר על פתרון עקיף. - המשתמשים לא יקבלו הצעות לגבי מדדי
type: number.
percent_of_previous
type: percent_of_previous מחשבת את ההפרש באחוזים בין תא לבין התא הקודם בעמודה שלו.
הפרמטר sql של מדדי type: percent_of_previous חייב להפנות למדד מספרי אחר.
אפשר לעצב שדות type: percent_of_previous באמצעות הפרמטרים value_format או value_format_name. עם זאת, פורמטים של אחוזים של הפרמטר value_format_name לא פועלים עם מדדים של type: percent_of_previous. בפורמטים האלה של אחוזים, הערכים מוכפלים ב-100, ולכן התוצאות של חישוב אחוז מהקודם מוטות.
בדוגמה הזו של LookML נוצר מדד count_growth שמבוסס על המדד count:
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
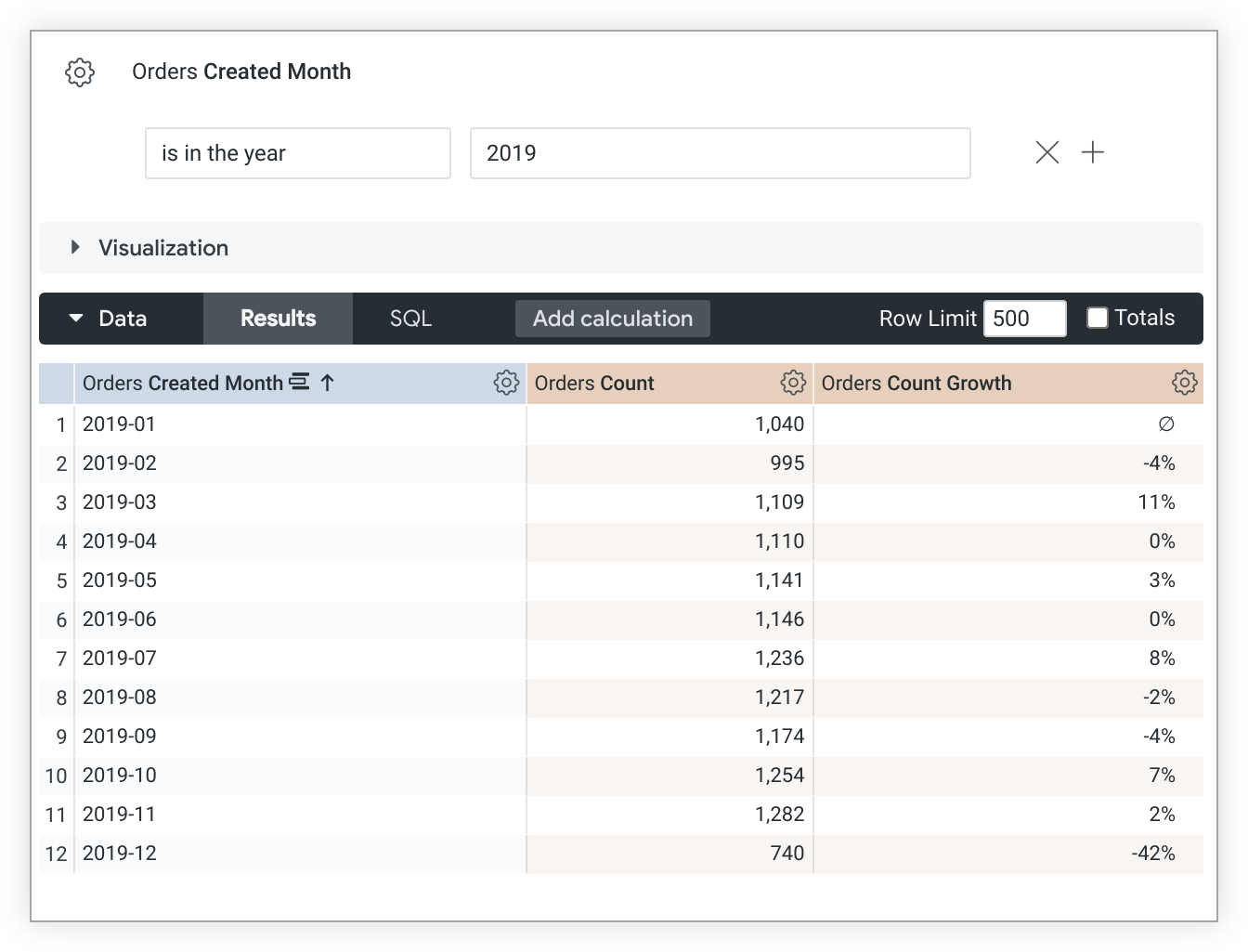
שימו לב שהערכים של percent_of_previous תלויים בסדר המיון. אם משנים את המיון, צריך להריץ מחדש את השאילתה כדי לחשב מחדש את הערכים של percent_of_previous. במקרים שבהם שאילתה מסובבת, הפונקציה percent_of_previous פועלת לאורך השורה ולא לאורך העמודה. אי אפשר לשנות את ההתנהגות הזו.
בנוסף, חישוב המדדים percent_of_previous מתבצע אחרי שהנתונים מוחזרים ממסד הנתונים. המשמעות היא שאסור להפנות לpercent_of_previous מדד בתוך מדד אחר, כי יכול להיות שהחישובים שלהם יתבצעו בזמנים שונים, ולכן התוצאות לא יהיו מדויקות. זה גם אומר שאי אפשר לסנן את המדדים percent_of_previous.
אחד היישומים של סוג המדידה הזה הוא ניתוח תקופה לתקופה (PoP), שהוא תבנית ניתוח שמודדת משהו בהווה ומשווה אותו למדידה זהה בתקופה מקבילה בעבר. מידע נוסף על השוואה לתקופה הקודמת זמין במאמרים בקהילת Looker בנושאים How to do Period-over-Period Analysis (איך לבצע ניתוח של תקופה לעומת תקופה) ו-Methods for Period Over Period (PoP) Analysis in Looker (שיטות לניתוח של תקופה לעומת תקופה ב-Looker).
percent_of_total
type: percent_of_total מחשבת את החלק של התא מתוך הסכום הכולל של העמודה. האחוז מחושב ביחס לסכום הכולל של השורות שמוחזרות על ידי השאילתה, ולא ביחס לסכום הכולל של כל השורות האפשריות. עם זאת, אם הנתונים שמוחזרים על ידי השאילתה חורגים ממגבלת השורות, הערכים של השדה יופיעו כערכי null, כי צריך את התוצאות המלאות כדי לחשב את אחוז הערך הכולל.
הפרמטר sql של מדדי type: percent_of_total חייב להפנות למדד מספרי אחר.
אפשר לעצב שדות type: percent_of_total באמצעות הפרמטרים value_format או value_format_name. עם זאת, פורמטים של אחוזים של הפרמטר value_format_name לא פועלים עם מדדים של type: percent_of_total. הפורמטים האלה של אחוזים מכפילים את הערכים ב-100, מה שמשבש את התוצאות של חישוב percent_of_total.
בדוגמה הזו של LookML נוצר מדד percent_of_total_gross_margin שמבוסס על המדד total_gross_margin:
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
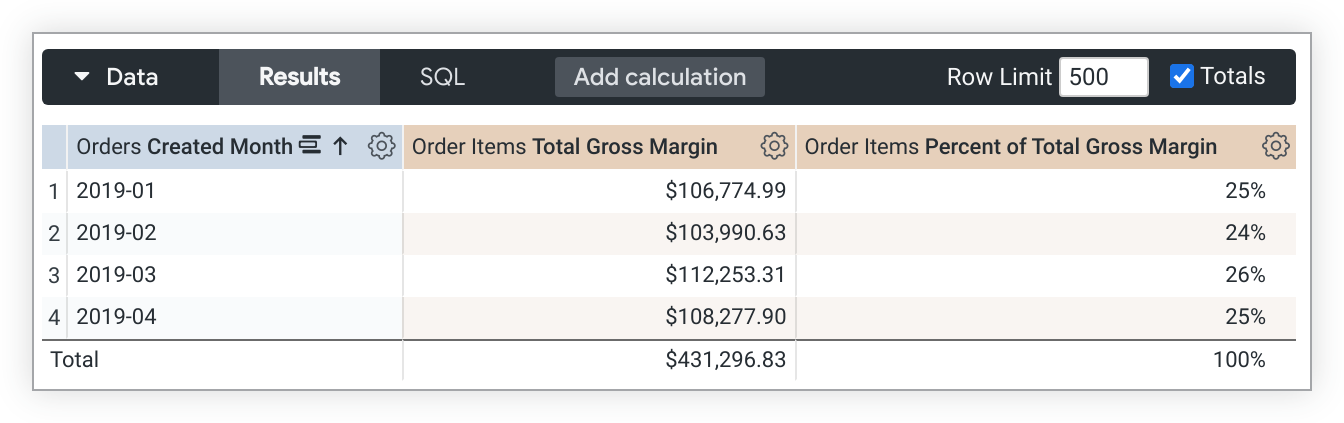
במקרים שבהם שאילתה מסובבת, הפונקציה percent_of_total פועלת לאורך השורה ולא לאורך העמודה. אם אתם לא רוצים את זה, מוסיפים direction: "column" להגדרת המדד.
בנוסף, חישוב המדדים percent_of_total מתבצע אחרי שהנתונים מוחזרים ממסד הנתונים. המשמעות היא שאסור להפנות לpercent_of_total מדד בתוך מדד אחר, כי יכול להיות שהחישובים שלהם יתבצעו בזמנים שונים, ולכן התוצאות לא יהיו מדויקות. זה גם אומר שאי אפשר לסנן את המדדים percent_of_total.
percentile
type: percentile מחזירה את הערך באחוזון שצוין מתוך הערכים בשדה נתון. לדוגמה, אם מציינים את האחוזון ה-75, הפונקציה תחזיר את הערך שגדול מ-75% מהערכים האחרים במערך הנתונים.
כדי לזהות את הערך להחזרה, Looker מחשב את המספר הכולל של ערכי הנתונים ומכפיל את האחוזון שצוין במספר הכולל של ערכי הנתונים. לא משנה איך הנתונים ממוינים בפועל, Looker מזהה את הסדר היחסי של ערכי הנתונים בסדר עולה. ערך הנתונים שמוחזר על ידי Looker תלוי בשאלה אם תוצאת החישוב היא מספר שלם או לא, כפי שמוסבר בשני הקטעים הבאים.
אם הערך המחושב הוא לא מספר שלם
מערכת Looker מעגלת את הערך המחושב כלפי מעלה ומשתמשת בו כדי לזהות את ערך הנתונים שיוחזר. בסט הזה של 19 ציונים במבחן, האחוזון ה-75 יהיה 19 כפול 0.75, כלומר 14.25. המשמעות היא ש-75% מהערכים נמצאים ב-14 הערכים הראשונים – מתחת למיקום ה-15. לכן, Looker מחזיר את ערך הנתונים ה-15 (87) כגדול מ-75% מערכי הנתונים.

אם הערך המחושב הוא מספר שלם
במקרה הזה, שהוא קצת יותר מורכב, Looker מחזיר ממוצע של ערך הנתונים במיקום הזה וערך הנתונים הבא. כדי להבין את זה, נסתכל על קבוצה של 20 ציונים במבחן: האחוזון ה-75 יזוהה על ידי 20 * 0.75 = 15, כלומר ערך הנתונים במיקום ה-15 הוא חלק מהאחוזון ה-75, ואנחנו צריכים להחזיר ערך שהוא גבוה מ-75% מערכי הנתונים. הפונקציה מחזירה את הממוצע של הערכים במיקום ה-15 (82) ובמיקום ה-16 (87), וכך Looker מוודא ש-75%. הממוצע הזה (84.5) לא קיים בקבוצת ערכי הנתונים, אבל הוא גדול מ-75% מערכי הנתונים.

פרמטרים נדרשים ואופציונליים
משתמשים במילת המפתח percentile: כדי לציין את הערך השברי, כלומר אחוז הנתונים שצריך להיות מתחת לערך שמוחזר. לדוגמה, אפשר להשתמש ב-percentile: 75 כדי לציין את הערך באחוזון ה-75 בסדר הנתונים, או ב-percentile: 10 כדי להחזיר את הערך באחוזון ה-10. אם רוצים למצוא את הערך באחוזון ה-50, אפשר לציין percentile: 50 או פשוט להשתמש בסוג median.
הפרמטר sql למדדי type: percentile יכול לקבל כל ביטוי SQL תקין שמניב עמודה מספרית בטבלה, מאפיין LookML או שילוב של מאפייני LookML.
אפשר לעצב שדות type: percentile באמצעות הפרמטרים value_format או value_format_name.
דוגמה
לדוגמה, קוד ה-LookML הבא יוצר שדה בשם test_scores_75th_percentile שמחזיר את הערך באחוזון ה-75 במאפיין test_scores:
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
נקודות שכדאי לקחת בחשבון לגבי percentile
אם משתמשים ב-percentile בשדה שמעורב בפיצול, Looker ינסה להשתמש ב-percentile_distinct במקום זאת. אם percentile_distinct לא זמין לדיאלקט, Looker מחזיר שגיאה. מידע נוסף זמין במאמר בנושא ניבים נתמכים של percentile_distinct.
ניבים נתמכים של מסדי נתונים עבור percentile
כדי ש-Looker יתמוך בסוג percentile בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בו גם כן. בטבלה הבאה מפורטים הניבים שתומכים בסוג percentile בגרסה האחרונה של Looker:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
percentile_distinct
type: percentile_distinct היא צורה מיוחדת של אחוזון, וצריך להשתמש בה כשמצטרפים לפעולת fanout. היא משתמשת בערכים שלא חוזרים על עצמם בשדה נתון, על סמך הערכים הייחודיים שמוגדרים על ידי הפרמטר sql_distinct_key. אם למדד אין פרמטר sql_distinct_key, Looker מנסה להשתמש בשדה primary_key.
נניח שזו התוצאה של שאילתה שמצטרפת לטבלאות Order Item ו-Order:
| מזהה הפריט בהזמנה | מזהה ההזמנה | משלוח הזמנה |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
במצב כזה, אפשר לראות כמה שורות לכל הזמנה. השאילתה הזו כללה פיצול (fanout) כי כל הזמנה ממופה לכמה פריטים בהזמנה. הפונקציה percentile_distinct לוקחת את זה בחשבון ומוצאת את ערך האחוזון באמצעות הערכים הייחודיים 10, 20, 50, 70 ו-110. האחוזון ה-25 יחזיר את הערך השני הייחודי, כלומר 20, ואילו האחוזון ה-80 יחזיר את הממוצע של הערכים הייחודיים הרביעי והחמישי, כלומר 90.
פרמטרים נדרשים ואופציונליים
כדי לציין את הערך השברי, משתמשים במילת המפתח percentile:. לדוגמה, אפשר להשתמש ב-percentile: 75 כדי לציין את הערך באחוזון ה-75 בסדר הנתונים, או ב-percentile: 10 כדי להחזיר את הערך באחוזון ה-10. אם אתם מנסים למצוא את הערך באחוזון ה-50, אתם יכולים להשתמש במקום זאת בסוג median_distinct.
כדי לקבל תוצאה מדויקת, צריך לציין איך Looker צריך לזהות כל ישות ייחודית (במקרה הזה, כל הזמנה ייחודית) באמצעות הפרמטר sql_distinct_key.
דוגמה לשימוש בפונקציה percentile_distinct כדי להחזיר את הערך באחוזון ה-90:
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
לכל ערך ייחודי של sql_distinct_key צריך להיות רק ערך תואם אחד בפרמטר sql של המדד. במילים אחרות, הדוגמה הקודמת פועלת כי כל שורה עם ערך order_id של 1 כוללת ערך order_shipping של 10, וכל שורה עם ערך order_id של 2 כוללת ערך order_shipping של 20.
אפשר לעצב שדות type: percentile_distinct באמצעות הפרמטרים value_format או value_format_name.
נקודות שכדאי לקחת בחשבון לגבי percentile_distinct
אם percentile_distinct לא זמין לדיאלקט, Looker מחזיר שגיאה. מידע נוסף זמין במאמר בנושא ניבים נתמכים של percentile_distinct.
ניבים נתמכים של מסדי נתונים עבור percentile_distinct
כדי ש-Looker יתמוך בסוג percentile_distinct בפרויקט Looker, הניב של מסד הנתונים צריך לתמוך בו גם כן. בטבלה הבאה מפורטים הניבים שתומכים בסוג percentile_distinct בגרסה האחרונה של Looker:
| דיאלקט | האם יש תמיכה? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
period_over_period
בניבים שתומכים במדדים של השוואה לתקופה קודמת, אפשר ליצור מדד LookML של type: period_over_period כדי ליצור מדד של השוואה לתקופה קודמת (PoP). מדד PoP מתייחס לצבירה מתקופה מוקדמת יותר.
דוגמה למדד PoP שמספק את מספר ההזמנות בחודש הקודם:
measure: orders_last_month {
type: period_over_period
based_on: orders.count
based_on_time: orders.created_month
period: month
kind: previous
}
בנוסף, למדדים עם type: period_over_period צריכים להיות גם הפרמטרים המשניים הבאים:
מידע נוסף ודוגמאות זמינים במאמר בנושא השוואה בין תקופות ב-Looker.
running_total
type: running_total מחשבת סכום מצטבר של התאים לאורך עמודה. אי אפשר להשתמש בו כדי לחשב סכומים לאורך שורה, אלא אם השורה נוצרה מטבלת צירים.
הפרמטר sql של מדדי type: running_total חייב להפנות למדד מספרי אחר.
אפשר לעצב שדות type: running_total באמצעות הפרמטרים value_format או value_format_name.
בדוגמה הבאה של LookML נוצר מדד cumulative_total_revenue שמבוסס על המדד total_sale_price:
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
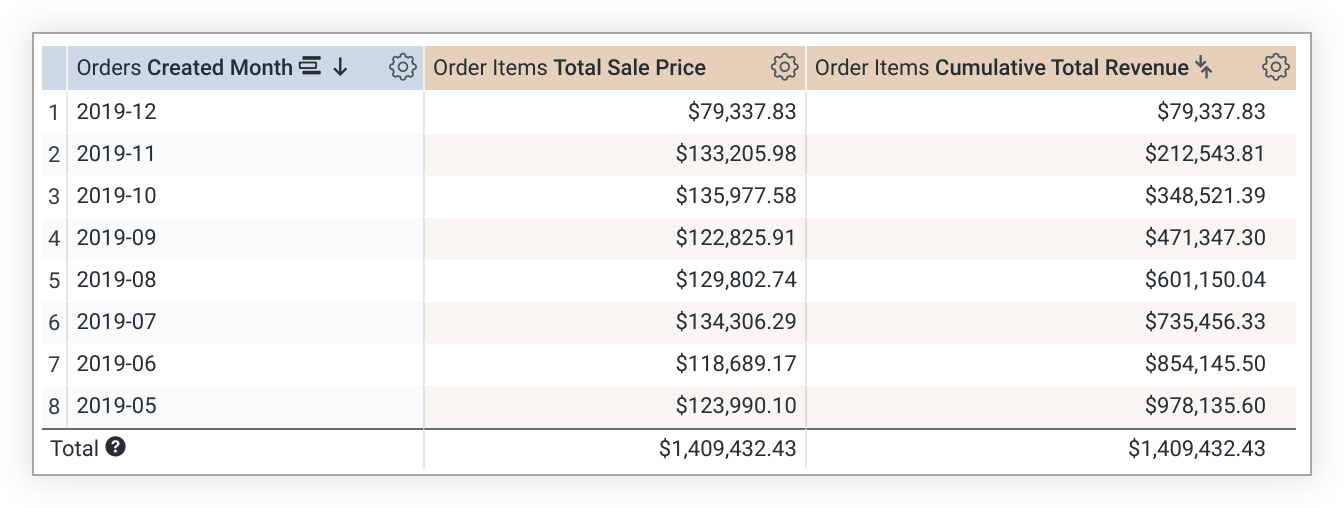
שימו לב שהערכים של running_total תלויים בסדר המיון. אם משנים את המיון, צריך להריץ מחדש את השאילתה כדי לחשב מחדש את הערכים של running_total. במקרים שבהם שאילתה מסובבת, הפונקציה running_total פועלת לאורך השורה ולא לאורך העמודה. אם אתם לא רוצים את זה, מוסיפים direction: "column" להגדרת המדד.
בנוסף, חישוב המדדים running_total מתבצע אחרי שהנתונים מוחזרים ממסד הנתונים. המשמעות היא שאסור להפנות לrunning_total מדד בתוך מדד אחר, כי יכול להיות שהחישובים שלהם יתבצעו בזמנים שונים, ולכן התוצאות לא יהיו מדויקות. זה גם אומר שאי אפשר לסנן את המדדים running_total.
string
type: string משמש עם שדות שמכילים אותיות או תווים מיוחדים.
הפרמטר sql למדדים מסוג type: string יכול לקבל כל ביטוי SQL תקין שמניב מחרוזת. בפועל, השימוש בסוג הזה נדיר, כי רוב פונקציות הצבירה של SQL לא מחזירות מחרוזות. יוצא דופן נפוץ הוא הפונקציה GROUP_CONCAT של MySQL, אבל Looker מספקת את type: list לתרחיש השימוש הזה.
לדוגמה, קוד ה-LookML הבא יוצר שדה category_list על ידי שילוב של הערכים הייחודיים של שדה שנקרא category:
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
בדוגמה הזו אפשר להשמיט את type: string, כי string הוא ערך ברירת המחדל של type.
sum
type: sum מסכם את הערכים בשדה נתון. היא דומה לפונקציה SUM ב-SQL. עם זאת, בניגוד ל-SQL גולמי, Looker יחשב את הסכומים בצורה נכונה גם אם הצטרפויות השאילתה מכילות פיצולים.
הפרמטר sql למדדי type: sum יכול לקבל כל ביטוי SQL תקין שמניב עמודה מספרית בטבלה, מאפיין LookML או שילוב של מאפייני LookML.
אפשר לעצב שדות type: sum באמצעות הפרמטרים value_format או value_format_name.
לדוגמה, קוד ה-LookML הבא יוצר שדה בשם total_revenue על ידי חיבור של הממד sales_price, ואז מציג אותו בפורמט של כסף ($1,234.56):
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct מיועד לשימוש עם קבוצות נתונים לא מנורמלות. הפונקציה מחשבת את סכום הערכים הלא חוזרים בשדה נתון, על סמך הערכים הייחודיים שמוגדרים על ידי הפרמטר sql_distinct_key.
זהו מושג מתקדם, שאולי יהיה קל יותר להבין אותו באמצעות דוגמה. נניח שיש לכם טבלה לא מנורמלת כזו:
| מזהה הפריט בהזמנה | מזהה ההזמנה | משלוח הזמנה |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
במצב כזה, אפשר לראות שיש כמה שורות לכל הזמנה. לכן, אם הוספתם מדד type: sum לעמודה order_shipping, תקבלו סכום כולל של 80.00, למרות שהסכום הכולל של עלויות המשלוח שנאספו הוא 30.00.
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
כדי לקבל תוצאה מדויקת, אפשר להגדיר ב-Looker איך לזהות כל ישות ייחודית (במקרה הזה, כל הזמנה ייחודית) באמצעות הפרמטר sql_distinct_key. החישוב יהיה נכון ויניב את הסכום 30.00:
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
לכל ערך ייחודי של sql_distinct_key צריך להיות רק ערך תואם אחד ב-sql. במילים אחרות, הדוגמה הקודמת פועלת כי כל שורה עם ערך order_id של 1 כוללת את אותו ערך order_shipping של 10.00, וכל שורה עם ערך order_id של 2 כוללת את אותו ערך order_shipping של 20.00.
אפשר לעצב שדות type: sum_distinct באמצעות הפרמטרים value_format או value_format_name.
yesno
type: yesno יוצר שדה שמציין אם משהו הוא True או False. הערכים שמופיעים בממשק המשתמש של התכונה 'ניתוח נתונים' הם כן ולא.
הפרמטר sql למדד type: yesno מקבל ביטוי SQL תקין שהערך המחושב שלו הוא TRUE או FALSE. אם התנאי הוא TRUE, המשתמש יראה את התשובה Yes. אחרת, הוא יראה את התשובה No.
ביטויי ה-SQL למדדים type: yesno צריכים לכלול רק צבירות, כלומר צבירות SQL או הפניות למדדי LookML. אם רוצים ליצור שדה yesno שכולל הפניה למאפיין LookML או לביטוי SQL שהוא לא צבירה, צריך להשתמש במאפיין עם type: yesno, ולא במדד.
בדומה למדדים עם type: number, מדד עם type: yesno לא מבצע צבירות, אלא רק מפנה לצבירות אחרות.
לדוגמה, המדד הבא total_sale_price הוא סכום המחיר הכולל של פריטים בהזמנה. מדד שני שנקרא is_large_total הוא type: yesno. למדד is_large_total יש פרמטר sql שבודק אם הערך total_sale_price גדול מ-1,000$.
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
אם רוצים להפנות לשדה type: yesno בשדה אחר, צריך להתייחס לשדה type: yesno כאל שדה בוליאני (כלומר, כאילו הוא כבר מכיל ערך true או false). לדוגמה:
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
# This is correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}