
Esta página se refere ao parâmetro
type, que faz parte de uma métrica.
typetambém pode ser usado como parte de uma dimensão ou um filtro, conforme descrito na página de documentação Tipos de dimensões, filtros e parâmetros.
typetambém pode ser usado como parte de um grupo de dimensões, descrito na página de documentação do parâmetrodimension_group.
Uso
view: view_name {
measure: field_name {
type: measure_field_type
}
}
|
Hierarquia
type |
Tipos de campo possíveis
Medida
Aceita
Um tipo de medida
|
Esta página inclui detalhes sobre os vários tipos que podem ser atribuídos a uma métrica. Uma métrica só pode ter um tipo, e o padrão é string se nenhum tipo for especificado.
Alguns tipos de métricas têm parâmetros de suporte, que são descritos na seção apropriada.
Categorias de tipo de medição
Cada tipo de métrica se enquadra em uma das seguintes categorias. Essas categorias determinam se o tipo de métrica realiza agregações, o tipo de campos que ele pode referenciar e se é possível filtrar o tipo de métrica usando o parâmetro filters:
- Medidas agregadas: os tipos de medidas agregadas realizam agregações, como
sumeaverage. As medidas agregadas só podem fazer referência a dimensões, não a outras medidas. Esse é o único tipo de métrica que funciona com o parâmetrofilters. - Medidas não agregadas: como o nome sugere, são tipos de medidas que não realizam agregações, como
numbereyesno. Esses tipos de medidas realizam transformações básicas e, como não fazem agregações, só podem referenciar medidas agregadas ou dimensões agregadas anteriormente. Não é possível usar o parâmetrofilterscom esses tipos de métricas. - Métricas pós-SQL: são tipos especiais de métricas que realizam cálculos específicos depois que o Looker gera o SQL da consulta. Elas só podem fazer referência a métricas ou dimensões numéricas. Não é possível usar o parâmetro
filterscom esses tipos de métricas.
Lista de definições de tipo
| Tipo | Categoria | Descrição |
|---|---|---|
average |
Agregar | Gera uma média de valores em uma coluna |
average_distinct |
Agregar | Gera corretamente uma média de valores ao usar dados desnormalizados. Consulte a seção average_distinct para uma descrição completa. |
count |
Agregar | Gera uma contagem de linhas |
count_distinct |
Agregar | Gera uma contagem de valores exclusivos em uma coluna |
date |
Não agregada | Para medidas que contêm datas |
list |
Agregar | Gera uma lista dos valores exclusivos em uma coluna |
max |
Agregar | Gera o valor máximo em uma coluna. |
median |
Agregar | Gera a mediana (valor do ponto médio) dos valores em uma coluna. |
median_distinct |
Agregar | Gera corretamente uma mediana (valor do ponto médio) dos valores quando uma junção causa um fanout. Consulte a seção median_distinct para uma descrição completa. |
min |
Agregar | Gera o valor mínimo em uma coluna. |
number |
Não agregada | Para medidas que contêm números |
percent_of_previous |
Pós-SQL | Gera a diferença percentual entre as linhas mostradas |
percent_of_total |
Pós-SQL | Gera a porcentagem do total para cada linha mostrada. |
percentile |
Agregar | Gera o valor no percentil especificado em uma coluna |
percentile_distinct |
Agregar | Gera corretamente o valor no percentil especificado quando uma junção causa um fanout. Consulte a seção percentile_distinct para uma descrição completa. |
running_total |
Pós-SQL | Gera o total acumulado de cada linha mostrada. |
period_over_period |
Agregar | Faz referência a uma agregação de um período anterior |
string |
Não agregada | Para medidas que contêm letras ou caracteres especiais (como a função GROUP_CONCAT do MySQL) |
sum |
Agregar | Gera uma soma de valores em uma coluna |
sum_distinct |
Agregar | Gera corretamente uma soma de valores ao usar dados desnormalizados.Consulte a seção sum_distinct para uma descrição completa. |
yesno |
Não agregada | Para campos que mostram se algo é verdadeiro ou falso |
int |
Não agregada |
Removido 5.4
Substituído por type: number |
average
type: average calcula a média dos valores em um determinado campo. É semelhante à função AVG do SQL. No entanto, ao contrário do SQL bruto, o Looker calcula as médias corretamente, mesmo que as junções da consulta contenham fanouts.
O parâmetro sql para medidas type: average pode usar qualquer expressão SQL válida que resulte em uma coluna numérica de tabela, dimensão do LookML ou combinação de dimensões do LookML.
Os campos type: average podem ser formatados usando os parâmetros value_format ou value_format_name.
Por exemplo, o LookML a seguir cria um campo chamado avg_order calculando a média da dimensão sales_price e o mostra em um formato de dinheiro (R$ 1.234,56):
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct é usado com conjuntos de dados desnormalizados. Ele calcula a média dos valores não repetidos em um determinado campo, com base nos valores únicos definidos pelo parâmetro sql_distinct_key.
Esse é um conceito avançado que pode ser explicado com mais clareza usando um exemplo. Considere uma tabela desnormalizada como esta:
| ID do item do pedido | ID do pedido | Frete do pedido |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
Nessa situação, há várias linhas para cada pedido. Consequentemente, se você adicionasse uma medida básica de type: average para a coluna order_shipping, receberia um valor de 16,00, mesmo que a média real seja 15,00.
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
Para ter um resultado preciso, defina para o Looker como ele deve identificar cada entidade exclusiva (neste caso, cada pedido exclusivo) usando o parâmetro sql_distinct_key. Isso vai calcular o valor correto de 15,00:
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Cada valor exclusivo de sql_distinct_key precisa ter apenas um valor correspondente em sql. Em outras palavras, o exemplo anterior funciona porque todas as linhas com um order_id de 1 têm o mesmo order_shipping de 10,00, e todas as linhas com um order_id de 2 têm o mesmo order_shipping de 20,00.
Os campos type: average_distinct podem ser formatados usando os parâmetros value_format ou value_format_name.
count
type: count realiza uma contagem de tabelas, semelhante à função COUNT do SQL. No entanto, ao contrário do SQL bruto, o Looker calcula corretamente as contagens, mesmo que as junções da consulta contenham fanouts.
As medidas type: count realizam contagens de tabelas com base na chave primária delas. Por isso, não são compatíveis com o parâmetro sql.type: count
Se você quiser fazer uma contagem de tabela em um campo diferente da chave primária dela, use uma métrica type: count_distinct. Se não quiser usar count_distinct, use uma métrica de type: number. Consulte a postagem da comunidade Como contar uma chave não primária para mais informações.
Por exemplo, o LookML a seguir cria um campo number_of_products:
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
É muito comum fornecer um parâmetro drill_fields (para campos) ao definir uma medida type: count para que os usuários possam ver os registros individuais que compõem uma contagem ao clicar nela.
Quando você usa uma métrica de
type: countem uma análise detalhada, a visualização rotula os valores resultantes com o nome da visualização em vez da palavra "Contagem". Para evitar confusão, recomendamos usar o plural no nome da visualização, selecionar Mostrar nome completo do campo em Série nas configurações de visualização ou usar umview_labelcom uma versão no plural do nome da visualização.
É possível adicionar um filtro a uma medida de type: count usando o parâmetro filters.
count_distinct
type: count_distinct calcula o número de valores distintos em um determinado campo. Ele usa a função COUNT DISTINCT do SQL.
O parâmetro sql para medidas type: count_distinct pode usar qualquer expressão SQL válida que resulte em uma coluna de tabela, dimensão do LookML ou combinação de dimensões do LookML.
Por exemplo, o LookML a seguir cria um campo number_of_unique_customers, que conta o número de IDs de clientes exclusivos:
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
É possível adicionar um filtro a uma medida de type: count_distinct usando o parâmetro filters.
date
type: date é usado com campos que contêm datas.
O parâmetro sql para métricas de type: date pode usar qualquer expressão SQL válida que resulte em uma data. Na prática, esse tipo raramente é usado, porque a maioria das funções agregadas de SQL não retorna datas. Uma exceção comum é um MIN ou MAX de uma dimensão de data.
Como criar uma medida de data máxima ou mínima com type: date
Se você quiser criar uma métrica de data máxima ou mínima, talvez pense que usar uma métrica de type: max ou type: min funcionaria. No entanto, esses tipos de medida são compatíveis apenas com campos numéricos. Em vez disso, é possível capturar uma data máxima ou mínima definindo uma métrica de type: date e agrupando o campo de data referenciado no parâmetro sql em uma função MIN() ou MAX().
Suponha que você tenha um grupo de dimensões de type: time, chamado updated:
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
Você pode criar uma medida de type: date para capturar a data máxima desse grupo de dimensões da seguinte forma:
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
Neste exemplo, em vez de usar uma medida de type: max para criar a medida last_updated_date, a função MAX() é aplicada no parâmetro sql. A métrica last_updated_date também tem o parâmetro convert_tz definido como no para evitar a conversão dupla de fuso horário na métrica, já que ela já ocorreu na definição do grupo de dimensões updated. Para mais informações, consulte a documentação sobre o parâmetro convert_tz.
No exemplo de LookML para a métrica last_updated_date, type: date pode ser omitido, e o valor será tratado como uma string, porque string é o valor padrão de type. No entanto, você terá uma capacidade de filtragem melhor para os usuários se usar type: date.
Você também pode notar que a definição de métrica last_updated_date faz referência ao período ${updated_raw} em vez de ${updated_date}. Como o valor retornado de ${updated_date} é uma string, é necessário usar ${updated_raw} para referenciar o valor de data real.
Você também pode usar o parâmetro datatype com type: date para melhorar a performance da consulta especificando o tipo de dados de data usado na tabela do banco de dados.
Criar uma medida máxima ou mínima para uma coluna de data e hora
Calcular o máximo de uma coluna type: datetime é um pouco diferente. Nesse caso, crie uma medida sem declarar o tipo, assim:
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list cria uma lista dos valores distintos em um determinado campo. É semelhante à função GROUP_CONCAT do MySQL.
Não é necessário incluir um parâmetro sql para medidas type: list. Em vez disso, use o parâmetro list_field para especificar a dimensão de que você quer criar listas.
O uso é o seguinte:
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
Por exemplo, o LookML a seguir cria uma medida name_list com base na dimensão name:
measure: name_list {
type: list
list_field: name
}
Observações sobre list:
- O tipo de métrica
listnão aceita filtragem. Não é possível usar o parâmetrofiltersem uma medidatype: list. - O tipo de métrica
listnão pode ser referenciado usando o operador de substituição ($). Não é possível usar a sintaxe${}para se referir a uma métricatype: list.
Dialetos de banco de dados compatíveis com list
Para que o Looker ofereça suporte a type: list no seu projeto do Looker, o dialeto do banco de dados também precisa oferecer. A tabela a seguir mostra quais dialetos são compatíveis com o type: list na versão mais recente do Looker:
| Dialeto | Compatível? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
max
type: max encontra o maior valor em um determinado campo. Ele usa a função MAX do SQL.
O parâmetro sql para medidas de type: max pode usar qualquer expressão SQL válida que resulte em uma coluna numérica de tabela, dimensão do LookML ou combinação de dimensões do LookML.
Como as medidas de type: max são compatíveis apenas com campos numéricos, não é possível usar uma medida de type: max para encontrar uma data máxima. Em vez disso, use a função MAX() no parâmetro sql de uma métrica de type: date para capturar uma data máxima, conforme mostrado anteriormente nos exemplos da seção date.
Os campos type: max podem ser formatados usando os parâmetros value_format ou value_format_name.
Por exemplo, o LookML a seguir cria um campo chamado largest_order ao analisar a dimensão sales_price e o mostra em um formato de dinheiro (R$ 1.234,56):
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
Não é possível usar medidas type: max para strings ou datas, mas você pode adicionar manualmente a função MAX para criar um campo assim:
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median retorna o valor do ponto médio para os valores em um determinado campo. Isso é útil principalmente quando os dados têm alguns valores discrepantes muito grandes ou pequenos que distorceriam uma média básica (média) dos dados.
Considere uma tabela como esta:
| ID do item do pedido | Custo | Ponto médio? |
|---|---|---|
| 2 | 10.00 | |
| 4 | 10.00 | |
| 3 | 20,00 | Valor do ponto médio |
| 1 | 80,00 | |
| 5 | 90,00 |
A tabela é classificada por custo, mas isso não afeta o resultado. Enquanto o tipo average retornaria 42 (somando todos os valores e dividindo por 5), o tipo median retornaria o valor do ponto médio: 20,00.
Se houver um número par de valores, a mediana será calculada usando a média dos dois valores mais próximos do ponto médio. Considere uma tabela como esta com um número par de linhas:
| ID do item do pedido | Custo | Ponto médio? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | Mais próximo antes do ponto médio |
| 1 | 80 | Mais próximo depois do ponto médio |
| 4 | 90 |
A mediana, o valor do meio, é (20 + 80)/2 = 50.
A mediana também é igual ao valor no 50º percentil.
O parâmetro sql para medidas type: median pode usar qualquer expressão SQL válida que resulte em uma coluna numérica de tabela, dimensão do LookML ou combinação de dimensões do LookML.
Os campos type: median podem ser formatados usando os parâmetros value_format ou value_format_name.
Exemplo
Por exemplo, o LookML a seguir cria um campo chamado median_order calculando a média da dimensão sales_price e o mostra em um formato de dinheiro (R$ 1.234,56):
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
Considerações sobre median
Se você estiver usando median para um campo envolvido em um fanout, o Looker vai tentar usar median_distinct. No entanto, medium_distinct é compatível apenas com alguns dialetos. Se median_distinct não estiver disponível para seu dialeto, o Looker vai retornar um erro. Como o median pode ser considerado o 50º percentil, o erro afirma que o dialeto não é compatível com percentis distintos.
Dialetos de banco de dados compatíveis com median
Para que o Looker seja compatível com o tipo median no seu projeto do Looker, o dialeto do banco de dados também precisa ser compatível. A tabela a seguir mostra quais dialetos são compatíveis com o tipo median na versão mais recente do Looker:
| Dialeto | Compatível? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
Quando há um fanout envolvido em uma consulta, o Looker tenta converter o median em median_distinct. Isso só funciona em dialetos que aceitam median_distinct.
median_distinct
Use type: median_distinct quando sua junção envolver um fanout. Ele calcula a média dos valores não repetidos em um determinado campo, com base nos valores únicos definidos pelo parâmetro sql_distinct_key. Se a métrica não tiver um parâmetro sql_distinct_key, o Looker tentará usar o campo primary_key.
Considere o resultado de uma consulta que une as tabelas "Item do pedido" e "Pedido":
| ID do item do pedido | ID do pedido | Frete do pedido |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
Nessa situação, é possível ver que há várias linhas para cada pedido. Essa consulta envolveu um fanout porque cada pedido é mapeado para vários itens de pedido. O median_distinct considera isso e encontra a mediana entre os valores distintos 10, 20 e 50, resultando em um valor de 20.
Para ter um resultado preciso, defina para o Looker como ele deve identificar cada entidade exclusiva (neste caso, cada pedido exclusivo) usando o parâmetro sql_distinct_key. Isso vai calcular o valor correto:
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Cada valor único de sql_distinct_key precisa ter apenas um valor correspondente no parâmetro sql da métrica. Em outras palavras, o exemplo anterior funciona porque todas as linhas com um order_id de 1 têm o mesmo order_shipping de 10, e todas as linhas com um order_id de 2 têm o mesmo order_shipping de 20.
Os campos type: median_distinct podem ser formatados usando os parâmetros value_format ou value_format_name.
Considerações sobre median_distinct
O tipo de métrica medium_distinct só é compatível com alguns dialetos. Se median_distinct não estiver disponível para o dialeto, o Looker vai retornar um erro. Como o median pode ser considerado o 50º percentil, o erro afirma que o dialeto não é compatível com percentis distintos.
Dialetos de banco de dados compatíveis com median_distinct
Para que o Looker seja compatível com o tipo median_distinct no seu projeto do Looker, o dialeto do banco de dados também precisa ser compatível. A tabela a seguir mostra quais dialetos são compatíveis com o tipo median_distinct na versão mais recente do Looker:
| Dialeto | Compatível? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
min
type: min encontra o menor valor em um determinado campo. Ele usa a função MIN do SQL.
O parâmetro sql para medidas de type: min pode usar qualquer expressão SQL válida que resulte em uma coluna numérica de tabela, dimensão do LookML ou combinação de dimensões do LookML.
Como as medidas de type: min são compatíveis apenas com campos numéricos, não é possível usar uma medida de type: min para encontrar uma data mínima. Em vez disso, use a função MIN() no parâmetro sql de uma métrica de type: date para capturar um mínimo, assim como você pode usar a função MAX() com uma métrica de type: date para capturar uma data máxima. Isso foi mostrado anteriormente nesta página na seção date, que inclui exemplos de uso da função MAX() no parâmetro sql para encontrar uma data máxima.
Os campos type: min podem ser formatados usando os parâmetros value_format ou value_format_name.
Por exemplo, o LookML a seguir cria um campo chamado smallest_order ao analisar a dimensão sales_price e o mostra em um formato de dinheiro (R$ 1.234,56):
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
Não é possível usar medidas type: min para strings ou datas, mas você pode adicionar manualmente a função MIN para criar um campo assim:
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number é usado com números ou números inteiros. Uma medida de type: number não faz agregação e destina-se a realizar transformações básicas em outras medidas. Se você estiver definindo uma métrica com base em outra, a nova métrica precisa ser do tipo type: number para evitar erros de agregação aninhada.
O parâmetro sql para medidas type: number pode usar qualquer expressão SQL válida que resulte em um número ou um inteiro.
Os campos type: number podem ser formatados usando os parâmetros value_format ou value_format_name.
Por exemplo, o LookML a seguir cria uma medida chamada total_gross_margin_percentage com base nas medidas agregadas total_sale_price e total_gross_margin e a mostra em um formato de porcentagem com duas casas decimais (12, 34%):
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
Este exemplo também usa a função SQL NULLIF() para remover a possibilidade de erros de divisão por zero.
Considerações sobre type: number
Há vários pontos importantes a serem considerados ao usar medidas de type: number:
- Uma medida de
type: numbersó pode realizar operações aritméticas em outras medidas, não em outras dimensões. - Os conjuntos simétricos do Looker não protegem as funções de agregação no SQL de uma métrica
type: numberquando calculadas em uma junção. - O parâmetro
filtersnão pode ser usado com medidastype: number, mas a documentação dofiltersexplica uma solução alternativa. - As medidas
type: numbernão vão fornecer sugestões aos usuários.
percent_of_previous
type: percent_of_previous calcula a diferença percentual entre uma célula e a anterior na mesma coluna.
O parâmetro sql para medidas de type: percent_of_previous precisa fazer referência a outra medida numérica.
Os campos type: percent_of_previous podem ser formatados usando os parâmetros value_format ou value_format_name. No entanto, os formatos de porcentagem do parâmetro value_format_name não funcionam com as métricas type: percent_of_previous. Esses formatos multiplicam os valores por 100, o que distorce os resultados de um cálculo de porcentagem anterior.
Este exemplo de LookML cria uma medida count_growth com base na medida count:
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
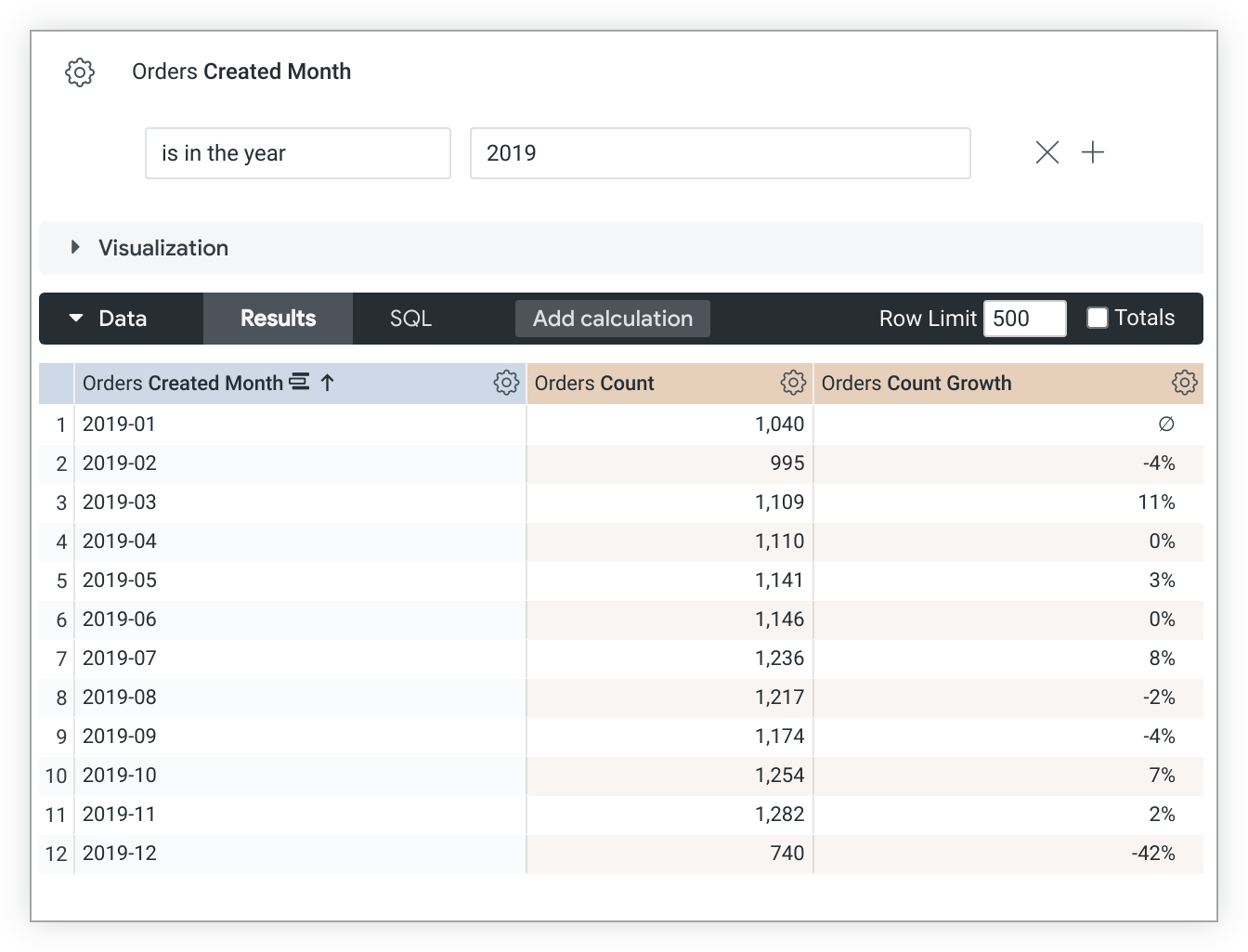
Os valores de percent_of_previous dependem da ordem de classificação. Se você mudar a classificação, será necessário executar a consulta novamente para recalcular os valores de percent_of_previous. Quando uma consulta é dinamizada, percent_of_previous é executado na linha em vez de na coluna. Não é possível alterar esse comportamento.
Além disso, as medidas percent_of_previous são calculadas depois que os dados são retornados do seu banco de dados. Isso significa que você não deve referenciar uma medida percent_of_previous em outra. Como elas podem ser calculadas em momentos diferentes, talvez você não receba resultados precisos. Isso também significa que as medidas percent_of_previous não podem ser filtradas.
Uma aplicação desse tipo de medida é a análise de período a período (PoP, na sigla em inglês), que mede algo no presente e compara com a mesma medição em um período comparável no passado. Para mais informações sobre o PoP, consulte os artigos da Comunidade do Looker Como fazer uma análise comparativa de períodos e Métodos para análise comparativa de períodos (PoP) no Looker.
percent_of_total
type: percent_of_total calcula a parte de uma célula no total da coluna. A porcentagem é calculada com base no total de linhas retornadas pela consulta, e não no total de todas as linhas possíveis. No entanto, se os dados retornados pela consulta excederem um limite de linhas, os valores do campo vão aparecer como nulos, já que ele precisa dos resultados completos para calcular a porcentagem do total.
O parâmetro sql para medidas de type: percent_of_total precisa fazer referência a outra medida numérica.
Os campos type: percent_of_total podem ser formatados usando os parâmetros value_format ou value_format_name. No entanto, os formatos de porcentagem do parâmetro value_format_name não funcionam com as métricas type: percent_of_total. Esses formatos de porcentagem multiplicam os valores por 100, o que distorce os resultados de um cálculo de percent_of_total.
Este exemplo de LookML cria uma medida percent_of_total_gross_margin com base na medida total_gross_margin:
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
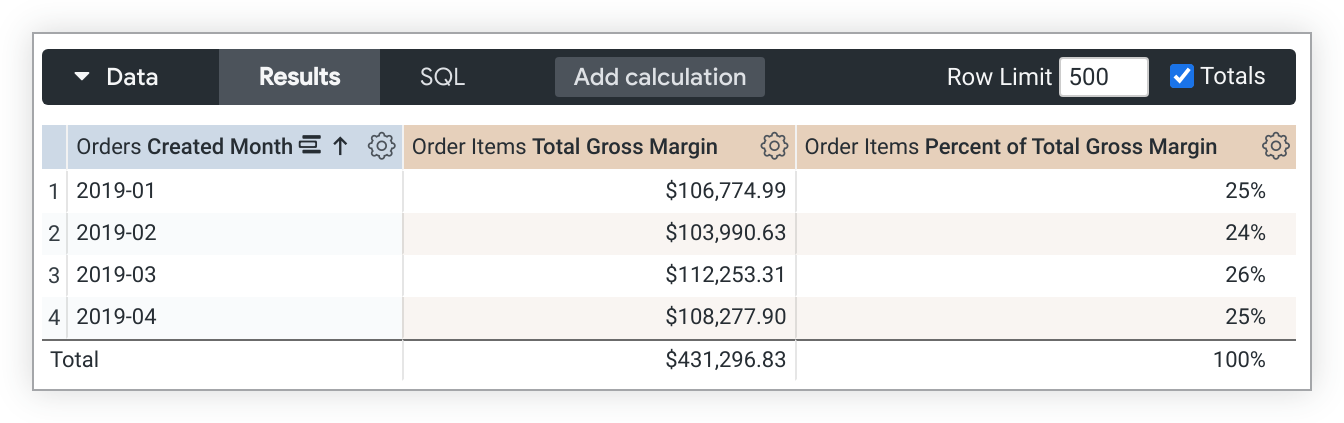
Quando uma consulta é dinamizada, percent_of_total é executado na linha em vez de na coluna. Se não for isso que você quer, adicione direction: "column" à definição da métrica.
Além disso, as medidas percent_of_total são calculadas depois que os dados são retornados do seu banco de dados. Isso significa que você não deve referenciar uma medida percent_of_total em outra. Como elas podem ser calculadas em momentos diferentes, talvez você não receba resultados precisos. Isso também significa que as medidas percent_of_total não podem ser filtradas.
percentile
type: percentile retorna o valor no percentil especificado de valores em um determinado campo. Por exemplo, especificar o 75º percentil vai retornar o valor maior que 75% dos outros valores no conjunto de dados.
Para identificar o valor a ser retornado, o Looker calcula o número total de valores de dados e multiplica o percentil especificado pelo número total de valores de dados. Independente de como os dados são classificados, o Looker identifica a ordem relativa dos valores de dados em ordem crescente. O valor de dados retornado pelo Looker depende de a conta resultar em um número inteiro ou não, conforme discutido nas duas seções a seguir.
Se o valor calculado não for um número inteiro
O Looker arredonda o valor calculado para cima e o usa para identificar o valor de dados a ser retornado. Neste exemplo de 19 notas de teste, o 75º percentil seria identificado por 19 * 0,75 = 14,25, o que significa que 75% dos valores estão nos primeiros 14 valores de dados, abaixo da 15ª posição. Assim, o Looker retorna o 15º valor de dados (87) como maior que 75% dos valores de dados.

Se o valor calculado for um número inteiro
Nesse caso um pouco mais complexo, o Looker retorna uma média do valor de dados nessa posição e do valor de dados seguinte. Para entender isso, considere um conjunto de 20 notas de teste: o 75º percentil seria identificado por 20 * 0,75 = 15, o que significa que o valor de dados na 15ª posição faz parte do 75º percentil, e precisamos retornar um valor maior que 75% dos valores de dados. Ao retornar a média dos valores na 15ª posição (82) e na 16ª posição (87), o Looker garante que 75%. Essa média (84,5) não existe no conjunto de valores de dados, mas seria maior que 75% dos valores de dados.

Parâmetros obrigatórios e opcionais
Use a palavra-chave percentile: para especificar o valor fracionário, ou seja, a porcentagem dos dados que deve estar abaixo do valor retornado. Por exemplo, use percentile: 75 para especificar o valor no 75º percentil na ordem dos dados ou percentile: 10 para retornar o valor no 10º percentil. Se você quiser encontrar o valor no 50º percentil, especifique percentile: 50 ou use o tipo mediana.
O parâmetro sql para medidas type: percentile pode usar qualquer expressão SQL válida que resulte em uma coluna numérica de tabela, dimensão do LookML ou combinação de dimensões do LookML.
Os campos type: percentile podem ser formatados usando os parâmetros value_format ou value_format_name.
Exemplo
Por exemplo, o LookML a seguir cria um campo chamado test_scores_75th_percentile que retorna o valor no 75º percentil na dimensão test_scores:
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
Considerações sobre percentile
Se você estiver usando percentile em um campo envolvido em um fanout, o Looker vai tentar usar percentile_distinct. Se percentile_distinct não estiver disponível para o dialeto, o Looker vai retornar um erro. Para mais informações, consulte os dialetos compatíveis com percentile_distinct.
Dialetos de banco de dados compatíveis com percentile
Para que o Looker seja compatível com o tipo percentile no seu projeto do Looker, o dialeto do banco de dados também precisa ser compatível. A tabela a seguir mostra quais dialetos são compatíveis com o tipo percentile na versão mais recente do Looker:
| Dialeto | Compatível? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
percentile_distinct
O type: percentile_distinct é uma forma especializada de percentil e deve ser usado quando a junção envolve um fanout. Ele usa os valores não repetidos em um determinado campo, com base nos valores únicos definidos pelo parâmetro sql_distinct_key. Se a métrica não tiver um parâmetro sql_distinct_key, o Looker vai tentar usar o campo primary_key.
Considere o resultado de uma consulta que une as tabelas "Item do pedido" e "Pedido":
| ID do item do pedido | ID do pedido | Frete do pedido |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
Nessa situação, é possível ver que há várias linhas para cada pedido. Essa consulta envolveu um fanout porque cada pedido é mapeado para vários itens de pedido. O percentile_distinct considera isso e encontra o valor do percentil usando os valores distintos 10, 20, 50, 70 e 110. O 25º percentil vai retornar o segundo valor distinto, ou seja, 20, enquanto o 80º percentil vai retornar a média do quarto e do quinto valores distintos, ou seja, 90.
Parâmetros obrigatórios e opcionais
Use a palavra-chave percentile: para especificar o valor fracionário. Por exemplo, use percentile: 75 para especificar o valor no 75º percentil na ordem dos dados ou percentile: 10 para retornar o valor no 10º percentil. Se você estiver tentando encontrar o valor no 50º percentil, use o tipo median_distinct.
Para ter um resultado preciso, especifique como o Looker deve identificar cada entidade exclusiva (neste caso, cada pedido exclusivo) usando o parâmetro sql_distinct_key.
Confira um exemplo de uso de percentile_distinct para retornar o valor no 90º percentil:
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Cada valor único de sql_distinct_key precisa ter apenas um valor correspondente no parâmetro sql da métrica. Em outras palavras, o exemplo anterior funciona porque todas as linhas com order_id de 1 têm o mesmo order_shipping de 10, e todas as linhas com um order_id de 2 têm o mesmo order_shipping de 20.
Os campos type: percentile_distinct podem ser formatados usando os parâmetros value_format ou value_format_name.
Considerações sobre percentile_distinct
Se percentile_distinct não estiver disponível para o dialeto, o Looker vai retornar um erro. Para mais informações, consulte os dialetos compatíveis com percentile_distinct.
Dialetos de banco de dados compatíveis com percentile_distinct
Para que o Looker seja compatível com o tipo percentile_distinct no seu projeto do Looker, o dialeto do banco de dados também precisa ser compatível. A tabela a seguir mostra quais dialetos são compatíveis com o tipo percentile_distinct na versão mais recente do Looker:
| Dialeto | Compatível? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
period_over_period
Para dialetos que aceitam medidas de período a período, é possível criar uma medida do LookML de type: period_over_period para criar uma medida de período a período (PoP, na sigla em inglês). Uma medida de PoP faz referência a uma agregação de um período anterior.
Confira um exemplo de métrica de PoP que fornece a contagem de pedidos do mês anterior:
measure: orders_last_month {
type: period_over_period
based_on: orders.count
based_on_time: orders.created_month
period: month
kind: previous
}
As métricas com type: period_over_period também precisam ter os seguintes subparâmetros:
Consulte Medidas de período a período no Looker para mais informações e exemplos.
running_total
type: running_total calcula uma soma cumulativa das células em uma coluna. Não pode ser usado para calcular somas ao longo de uma linha, a menos que ela seja resultado de uma tabela dinâmica.
O parâmetro sql para medidas de type: running_total precisa fazer referência a outra medida numérica.
Os campos type: running_total podem ser formatados usando os parâmetros value_format ou value_format_name.
O exemplo de LookML a seguir cria uma medida cumulative_total_revenue com base na medida total_sale_price:
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
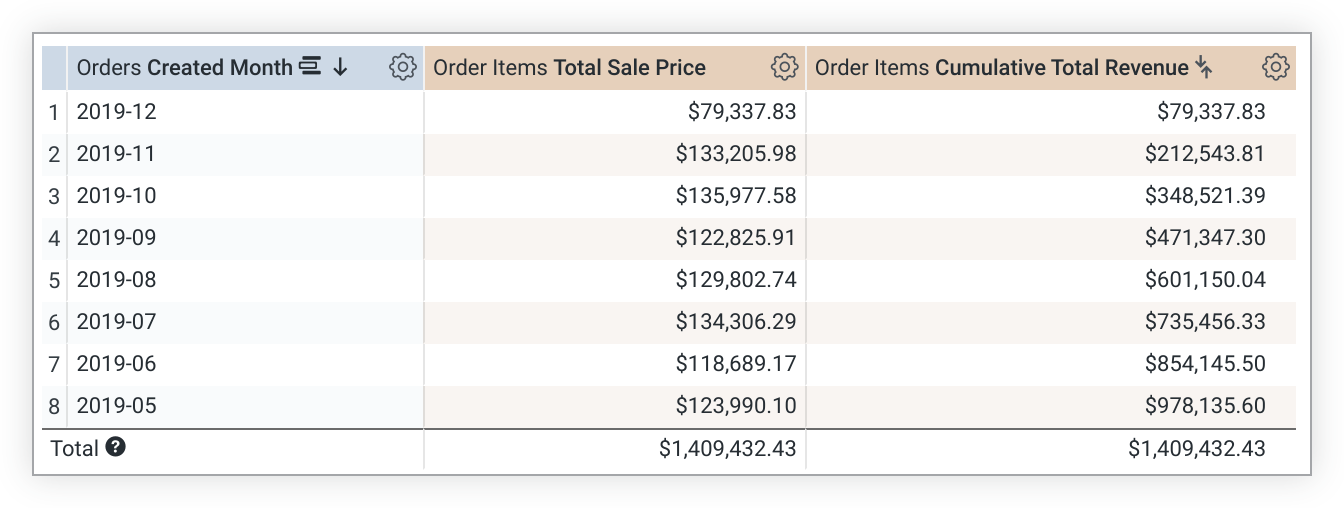
Os valores de running_total dependem da ordem de classificação. Se você mudar a classificação, será necessário executar a consulta novamente para recalcular os valores de running_total. Quando uma consulta é dinamizada, running_total é executado na linha em vez de na coluna. Se não for isso que você quer, adicione direction: "column" à definição da métrica.
Além disso, as medidas running_total são calculadas depois que os dados são retornados do seu banco de dados. Isso significa que você não deve referenciar uma medida running_total em outra. Como elas podem ser calculadas em momentos diferentes, talvez você não receba resultados precisos. Isso também significa que as medidas running_total não podem ser filtradas.
string
type: string é usado com campos que contêm letras ou caracteres especiais.
O parâmetro sql para métricas de type: string pode usar qualquer expressão SQL válida que resulte em uma string. Na prática, esse tipo raramente é usado, porque a maioria das funções agregadas de SQL não retorna strings. Uma exceção comum é a função GROUP_CONCAT do MySQL, embora o Looker forneça type: list para esse caso de uso.
Por exemplo, o LookML a seguir cria um campo category_list combinando os valores únicos de um campo chamado category:
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
Neste exemplo, type: string pode ser omitido porque string é o valor padrão de type.
sum
type: sum soma os valores em um determinado campo. É semelhante à função SUM do SQL. No entanto, ao contrário do SQL bruto, o Looker calcula corretamente as somas, mesmo que as junções da consulta contenham fanouts.
O parâmetro sql para medidas type: sum pode usar qualquer expressão SQL válida que resulte em uma coluna numérica de tabela, dimensão do LookML ou combinação de dimensões do LookML.
Os campos type: sum podem ser formatados usando os parâmetros value_format ou value_format_name.
Por exemplo, o LookML a seguir cria um campo chamado total_revenue somando a dimensão sales_price e o mostra em um formato de dinheiro (R$ 1.234,56):
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct é usado com conjuntos de dados desnormalizados. Ele soma os valores não repetidos em um determinado campo com base nos valores únicos definidos pelo parâmetro sql_distinct_key.
Esse é um conceito avançado que pode ser explicado com mais clareza usando um exemplo. Considere uma tabela desnormalizada como esta:
| ID do item do pedido | ID do pedido | Frete do pedido |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
Nessa situação, há várias linhas para cada pedido. Consequentemente, se você adicionasse uma medida type: sum à coluna order_shipping, receberia um total de 80,00, mesmo que o frete total cobrado seja de 30,00.
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
Para ter um resultado preciso, defina para o Looker como ele deve identificar cada entidade exclusiva (neste caso, cada pedido exclusivo) usando o parâmetro sql_distinct_key. Isso vai calcular o valor correto de 30,00:
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Cada valor exclusivo de sql_distinct_key precisa ter apenas um valor correspondente em sql. Em outras palavras, o exemplo anterior funciona porque todas as linhas com um order_id de 1 têm o mesmo order_shipping de 10,00, e todas as linhas com um order_id de 2 têm o mesmo order_shipping de 20,00.
Os campos type: sum_distinct podem ser formatados usando os parâmetros value_format ou value_format_name.
yesno
type: yesno cria um campo que indica se algo é verdadeiro ou falso. Os valores aparecem como Sim e Não na interface do usuário do recurso Detalhar.
O parâmetro sql de uma métrica type: yesno usa uma expressão SQL válida que é avaliada como TRUE ou FALSE. Se a condição for avaliada como TRUE, Sim será mostrado ao usuário. Caso contrário, Não será exibido.
A expressão SQL para medidas type: yesno precisa incluir apenas agregações, ou seja, agregações SQL ou referências a medidas do LookML. Se você quiser criar um campo yesno que inclua uma referência a uma dimensão do LookML ou uma expressão SQL que não seja uma agregação, use uma dimensão com type: yesno, não uma métrica.
Assim como as medidas com type: number, uma medida com type: yesno não faz agregações, apenas faz referência a outras.
Por exemplo, a métrica total_sale_price a seguir é a soma do preço total de venda dos itens em um pedido. Uma segunda métrica chamada is_large_total é type: yesno. A métrica is_large_total tem um parâmetro sql que avalia se o valor de total_sale_price é maior que US $1.000.
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
Se você quiser fazer referência a um campo type: yesno em outro campo, trate o campo type: yesno como um booleano (ou seja, como se ele já contivesse um valor verdadeiro ou falso). Exemplo:
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
# This is correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}