
이 페이지에서는 측정항목에 포함된
type매개변수를 참조합니다.
type는 측정기준, 필터, 매개변수 유형 문서 페이지에 설명된 대로 측정기준 또는 필터의 일부로도 사용할 수 있습니다.
type는dimension_group매개변수 문서 페이지에 설명된 대로 측정기준 그룹의 일부로 사용할 수도 있습니다.
사용
view: view_name {
measure: field_name {
type: measure_field_type
}
}
|
계층 구조
type |
가능한 필드 유형
측정
수락
측정 유형
|
이 페이지에는 측정에 할당할 수 있는 다양한 유형에 대한 세부정보가 포함되어 있습니다. 측정항목은 유형이 하나만 있을 수 있으며 유형이 지정되지 않은 경우 기본값은 string입니다.
일부 측정 유형에는 지원 매개변수가 있으며, 이는 해당 섹션에 설명되어 있습니다.
측정 유형 카테고리
각 측정값 유형은 다음 카테고리 중 하나에 해당합니다. 이러한 카테고리는 측정값 유형이 집계를 수행하는지, 측정값 유형이 참조할 수 있는 필드 유형, filters 매개변수를 사용하여 측정값 유형을 필터링할 수 있는지 여부를 결정합니다.
- 집계 측정값: 집계 측정값 유형은
sum및average과 같은 집계를 수행합니다. 집계 측정값은 다른 측정값이 아닌 측정기준만 참조할 수 있습니다.filters매개변수와 함께 사용할 수 있는 유일한 측정 유형입니다. - 비집계 측정: 비집계 측정은 이름에서 알 수 있듯이
number및yesno과 같이 집계를 수행하지 않는 측정 유형입니다. 이러한 측정 유형은 기본 변환을 실행하며 집계를 실행하지 않으므로 집계 측정값 또는 이전에 집계된 측정기준만 참조할 수 있습니다. 이러한 측정 유형에는filters매개변수를 사용할 수 없습니다. - SQL 후 측정: SQL 후 측정은 Looker에서 쿼리 SQL을 생성한 후 특정 계산을 실행하는 특수한 측정 유형입니다. 숫자 측정 또는 숫자 측정기준만 참조할 수 있습니다. 이러한 측정 유형에는
filters매개변수를 사용할 수 없습니다.
유형 정의 목록
| 유형 | 카테고리 | 설명 |
|---|---|---|
average |
집계 | 열 내 값의 평균을 생성합니다. |
average_distinct |
집계 | 비정규화된 데이터를 사용할 때 값의 평균을 적절하게 생성합니다. 자세한 내용은 average_distinct 섹션을 참고하세요. |
count |
집계 | 행 수를 생성합니다. |
count_distinct |
집계 | 열 내의 고유 값 수를 생성합니다. |
date |
비집계 | 날짜가 포함된 측정항목의 경우 |
list |
집계 | 열 내의 고유 값 목록을 생성합니다. |
max |
집계 | 열 내의 최댓값을 생성합니다. |
median |
집계 | 열 내 값의 중앙값 (중간값)을 생성합니다. |
median_distinct |
집계 | 조인으로 인해 팬아웃이 발생할 때 값의 중앙값 (중간값)을 올바르게 생성합니다. 자세한 내용은 median_distinct 섹션을 참고하세요. |
min |
집계 | 열 내의 최솟값을 생성합니다. |
number |
비집계 | 숫자가 포함된 측정값 |
percent_of_previous |
Post-SQL | 표시된 행 간의 차이(%)를 생성합니다. |
percent_of_total |
Post-SQL | 표시된 각 행의 총계 비율을 생성합니다. |
percentile |
집계 | 열 내에서 지정된 백분위수의 값을 생성합니다. |
percentile_distinct |
집계 | 조인으로 인해 팬아웃이 발생할 때 지정된 백분위수의 값을 올바르게 생성합니다. 자세한 내용은 percentile_distinct 섹션을 참고하세요. |
running_total |
Post-SQL | 표시된 각 행의 누계를 생성합니다. |
period_over_period |
집계 | 이전 기간의 집계를 참조합니다. |
string |
비집계 | 문자 또는 특수문자가 포함된 측정값 (MySQL의 GROUP_CONCAT 함수와 같이) |
sum |
집계 | 열 내 값의 합계를 생성합니다. |
sum_distinct |
집계 | 비정규화된 데이터를 사용할 때 값의 합계를 적절하게 생성합니다.자세한 내용은 sum_distinct 섹션을 참고하세요. |
yesno |
비집계 | 어떤 내용이 참인지 거짓인지 표시하는 필드 |
int |
비집계 |
5.4에서 삭제됨
type: number로 대체됨 |
average
type: average는 지정된 필드의 값을 평균합니다. SQL의 AVG 함수와 유사합니다. 하지만 원시 SQL과 달리 Looker는 쿼리의 조인에 팬아웃이 포함되어 있어도 평균을 올바르게 계산합니다.
type: average 측정의 sql 매개변수는 숫자 테이블 열, LookML 측정기준 또는 LookML 측정기준의 조합을 생성하는 유효한 SQL 표현식을 사용할 수 있습니다.
type: average 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
예를 들어 다음 LookML은 sales_price 측정기준을 평균하여 avg_order라는 필드를 만든 다음 이를 통화 형식 ($1,234.56)으로 표시합니다.
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct는 비정규화된 데이터 세트와 함께 사용됩니다. sql_distinct_key 매개변수로 정의된 고유 값을 기반으로 지정된 필드의 반복되지 않는 값을 평균합니다.
이는 고급 개념으로, 예를 통해 더 명확하게 설명할 수 있습니다. 다음과 같은 비정규화된 테이블을 고려해 보세요.
| 주문 상품 ID | 주문 ID | 주문 배송 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
이 경우 각 주문에 여러 행이 표시됩니다. 따라서 order_shipping 열에 기본 type: average 측정항목을 추가하면 실제 평균이 15.00임에도 불구하고 16.00이라는 값이 표시됩니다.
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
정확한 결과를 얻으려면 sql_distinct_key 매개변수를 사용하여 Looker에서 각 고유 항목 (이 경우 각 고유 주문)을 식별하는 방법을 정의하면 됩니다. 이렇게 하면 올바른 금액인 15.00이 계산됩니다.
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key의 모든 고유 값에는 sql의 해당 값이 하나만 있어야 합니다. 즉, 앞의 예는 order_id가 1인 모든 행의 order_shipping가 10.00으로 동일하고 order_id가 2인 모든 행의 order_shipping가 20.00으로 동일하기 때문에 작동합니다.
type: average_distinct 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
count
type: count는 SQL의 COUNT 함수와 유사하게 테이블 수를 실행합니다. 하지만 원시 SQL과 달리 Looker는 쿼리의 조인에 팬아웃이 포함되어 있더라도 개수를 올바르게 계산합니다.
type: count 측정값은 테이블의 기본 키를 기반으로 테이블 수를 실행하므로 type: count 측정값은 sql 매개변수를 지원하지 않습니다.
테이블의 기본 키가 아닌 필드에서 테이블 개수를 실행하려면 type: count_distinct 측정항목을 사용하세요. 또는 count_distinct를 사용하지 않으려면 type: number 측정항목을 사용하면 됩니다 (자세한 내용은 커뮤니티 게시물 기본이 아닌 키를 계산하는 방법 참고).
예를 들어 다음 LookML은 number_of_products 필드를 만듭니다.
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
type: count 측정을 정의할 때 drill_fields (필드용) 매개변수를 제공하는 것이 매우 일반적입니다. 이렇게 하면 사용자가 클릭할 때 개수를 구성하는 개별 레코드를 볼 수 있습니다.
탐색에서
type: count측정값을 사용할 때 시각화는 '개수'라는 단어가 아닌 뷰 이름으로 결과 값에 라벨을 지정합니다. 혼동을 피하려면 뷰 이름을 복수화하거나, 시각화 설정의 시리즈에서 전체 필드 이름 표시를 선택하거나, 복수형의 뷰 이름과 함께view_label을 사용하는 것이 좋습니다.
filters 매개변수를 사용하여 type: count 측정항목에 필터를 추가할 수 있습니다.
count_distinct
type: count_distinct는 지정된 필드에서 고유 값의 개수를 계산합니다. SQL의 COUNT DISTINCT 함수를 사용합니다.
type: count_distinct 측정의 sql 매개변수는 테이블 열, LookML 측정기준 또는 LookML 측정기준의 조합을 생성하는 유효한 SQL 표현식을 사용할 수 있습니다.
예를 들어 다음 LookML은 고유 고객 ID 수를 집계하는 필드 number_of_unique_customers를 만듭니다.
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
filters 매개변수를 사용하여 type: count_distinct 측정항목에 필터를 추가할 수 있습니다.
date
type: date는 날짜가 포함된 필드와 함께 사용됩니다.
type: date 측정의 sql 파라미터는 날짜를 생성하는 유효한 SQL 표현식을 사용할 수 있습니다. 실제로 대부분의 SQL 집계 함수는 날짜를 반환하지 않으므로 이 유형은 거의 사용되지 않습니다. 일반적인 예외는 날짜 측정기준의 MIN 또는 MAX입니다.
type: date을 사용하여 최대 또는 최소 날짜 측정항목 만들기
최대 또는 최소 날짜의 측정값을 만들려면 처음에는 type: max 또는 type: min의 측정값을 사용하면 된다고 생각할 수 있습니다. 하지만 이러한 측정값 유형은 숫자 필드와만 호환됩니다. 대신 type: date의 측정값을 정의하고 sql 매개변수에서 참조되는 날짜 필드를 MIN() 또는 MAX() 함수로 래핑하여 최대 또는 최소 날짜를 캡처할 수 있습니다.
type: time의 측정기준 그룹이 updated이라고 가정해 보겠습니다.
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
다음과 같이 type: date 측정값을 만들어 이 측정기준 그룹의 최대 날짜를 포착할 수 있습니다.
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
이 예에서는 type: max 측정값을 사용하여 last_updated_date 측정값을 만드는 대신 sql 매개변수에 MAX() 함수가 적용됩니다. 또한 측정값의 시간대 변환이 이미 측정기준 그룹 updated의 정의에서 발생했으므로 측정값에서 시간대 변환이 두 번 발생하는 것을 방지하기 위해 last_updated_date 측정값의 convert_tz 매개변수가 no로 설정됩니다. 자세한 내용은 convert_tz 매개변수에 관한 문서를 참고하세요.
last_updated_date 측정항목의 LookML 예에서 string이 type의 기본값이므로 type: date을 생략할 수 있으며 값은 문자열로 처리됩니다. 하지만 type: date을 사용하면 사용자를 위한 필터링 기능이 향상됩니다.
last_updated_date 측정항목 정의가 ${updated_date} 기간 대신 ${updated_raw} 기간을 참조하는 것도 확인할 수 있습니다. ${updated_date}에서 반환되는 값은 문자열이므로 ${updated_raw}을 사용하여 실제 날짜 값을 대신 참조해야 합니다.
type: date와 함께 datatype 매개변수를 사용하여 데이터베이스 테이블에서 사용하는 날짜 데이터 유형을 지정하여 쿼리 성능을 향상할 수도 있습니다.
날짜 및 시간 열의 최대 또는 최소 측정값 만들기
type: datetime 열의 최댓값을 계산하는 것은 약간 다릅니다. 이 경우 다음과 같이 유형을 선언하지 않고 측정항목을 만듭니다.
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list는 지정된 필드의 고유 값 목록을 생성합니다. MySQL의 GROUP_CONCAT 함수와 유사합니다.
type: list 측정항목에는 sql 매개변수를 포함할 필요가 없습니다. 대신 list_field 매개변수를 사용하여 목록을 만들 측정기준을 지정할 수 있습니다.
사용법은 다음과 같습니다.
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
예를 들어 다음 LookML은 name 측정기준을 기반으로 name_list 측정값을 만듭니다.
measure: name_list {
type: list
list_field: name
}
list에 관해 다음 사항을 참고하세요.
list측정 유형은 필터링을 지원하지 않습니다.type: list측정항목에는filters매개변수를 사용할 수 없습니다.list측정 유형은 대체 연산자 ($)를 사용하여 참조할 수 없습니다.${}구문을 사용하여type: list측정항목을 참조할 수 없습니다.
list에 지원되는 데이터베이스 언어
Looker가 Looker 프로젝트에서 type: list를 지원하려면 데이터베이스 언어에서도 이를 지원해야 합니다. 다음 표에서는 최신 버전의 Looker에서 type: list를 지원하는 언어를 보여줍니다.
| 언어 | 지원 여부 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
max
type: max는 지정된 필드에서 가장 큰 값을 찾습니다. SQL의 MAX 함수를 사용합니다.
type: max 측정값의 sql 매개변수는 숫자 테이블 열, LookML 측정기준 또는 LookML 측정기준의 조합을 생성하는 유효한 SQL 표현식을 사용할 수 있습니다.
type: max 측정값은 숫자 필드와만 호환되므로 type: max 측정값을 사용하여 최대 날짜를 찾을 수는 없습니다. 대신 date 섹션의 예에서 이전에 표시된 대로 type: date 측정값의 sql 매개변수에서 MAX() 함수를 사용하여 최대 날짜를 캡처할 수 있습니다.
type: max 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
예를 들어 다음 LookML은 sales_price 측정기준을 살펴 largest_order라는 필드를 만든 다음, 이를 통화 형식 ($1,234.56)으로 표시합니다.
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
문자열이나 날짜에는 type: max 측정항목을 사용할 수 없지만 다음과 같이 MAX 함수를 수동으로 추가하여 이러한 필드를 만들 수 있습니다.
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median는 지정된 필드의 값에 대한 중간값을 반환합니다. 이는 데이터의 기본 평균을 왜곡할 수 있는 매우 크거나 작은 이상치 값이 몇 개 있는 경우에 특히 유용합니다.
다음과 같은 테이블을 생각해 보세요.
| 주문 상품 ID | 비용 | 중간 지점? |
|---|---|---|
| 2 | 10.00 | |
| 4 | 10.00 | |
| 3 | 20.00 | 중간값 |
| 1 | 80.00 | |
| 5 | 90.00 |
표는 비용별로 정렬되지만 결과에는 영향을 미치지 않습니다. average 유형은 모든 값을 더하고 5로 나누어 42를 반환하지만 median 유형은 중간값인 20.00을 반환합니다.
값이 짝수 개인 경우 중앙값은 중간점에 가장 가까운 두 값의 평균을 구하여 계산합니다. 행 수가 짝수인 다음과 같은 테이블을 살펴보세요.
| 주문 상품 ID | 비용 | 중간 지점? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | 중간 지점 전 가장 가까운 위치 |
| 1 | 80 | 중간 지점 이후 가장 가까운 값 |
| 4 | 90 |
중앙값인 중간값은 (20 + 80)/2 = 50입니다.
중앙값은 50번째 백분위수의 값과도 같습니다.
type: median 측정의 sql 매개변수는 숫자 테이블 열, LookML 측정기준 또는 LookML 측정기준의 조합을 생성하는 유효한 SQL 표현식을 사용할 수 있습니다.
type: median 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
예
예를 들어 다음 LookML은 sales_price 측정기준을 평균하여 median_order라는 필드를 만든 다음 이를 통화 형식 ($1,234.56)으로 표시합니다.
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
median 관련 고려사항
팬아웃에 포함된 필드에 median를 사용하면 Looker에서 대신 median_distinct를 사용하려고 시도합니다. 하지만 medium_distinct는 특정 언어에서만 지원됩니다. 언어에서 median_distinct를 사용할 수 없는 경우 Looker에서 오류를 반환합니다. median는 50번째 백분위수로 간주될 수 있으므로 오류에는 언어에서 고유한 백분위수를 지원하지 않는다고 명시됩니다.
median에 지원되는 데이터베이스 언어
Looker가 Looker 프로젝트에서 median 유형을 지원하려면 데이터베이스 언어에서도 이를 지원해야 합니다. 다음 표에서는 최신 버전의 Looker에서 median 유형을 지원하는 언어를 보여줍니다.
| 언어 | 지원 여부 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
쿼리에 팬아웃이 포함된 경우 Looker는 median를 median_distinct로 변환하려고 합니다. 이는 median_distinct를 지원하는 언어에서만 성공합니다.
median_distinct
조인에 팬아웃이 포함된 경우 type: median_distinct를 사용합니다. sql_distinct_key 매개변수로 정의된 고유 값을 기반으로 지정된 필드의 반복되지 않는 값을 평균합니다. 측정에 sql_distinct_key 매개변수가 없는 경우 Looker는 primary_key 필드를 사용하려고 시도합니다.
주문 항목과 주문 테이블을 조인하는 쿼리의 결과를 고려해 보세요.
| 주문 상품 ID | 주문 ID | 주문 배송 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
이 경우 각 주문에 여러 행이 표시됩니다. 각 주문이 여러 주문 항목에 매핑되므로 이 쿼리에는 팬아웃이 포함되었습니다. median_distinct는 이를 고려하여 고유 값 10, 20, 50 사이의 중앙값을 찾으므로 값은 20이 됩니다.
정확한 결과를 얻으려면 sql_distinct_key 매개변수를 사용하여 Looker에서 각 고유 항목 (이 경우 각 고유 주문)을 식별하는 방법을 정의하면 됩니다. 이렇게 하면 올바른 금액이 계산됩니다.
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key의 모든 고유 값에는 측정항목의 sql 매개변수에 해당하는 값이 하나만 있어야 합니다. 즉, 앞의 예는 order_id이 1인 모든 행의 order_shipping이 10이고 order_id이 2인 모든 행의 order_shipping이 20이기 때문에 작동합니다.
type: median_distinct 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
median_distinct 관련 고려사항
medium_distinct 측정 유형은 특정 언어에서만 지원됩니다. 언어에서 median_distinct를 사용할 수 없는 경우 Looker에서 오류를 반환합니다. median은 50번째 백분위수로 간주될 수 있으므로 오류에는 언어가 고유 백분위수를 지원하지 않는다고 표시됩니다.
median_distinct에 지원되는 데이터베이스 언어
Looker가 Looker 프로젝트에서 median_distinct 유형을 지원하려면 데이터베이스 언어에서도 이를 지원해야 합니다. 다음 표에서는 최신 버전의 Looker에서 median_distinct 유형을 지원하는 언어를 보여줍니다.
| 언어 | 지원 여부 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
min
type: min은 지정된 필드에서 가장 작은 값을 찾습니다. SQL의 MIN 함수를 사용합니다.
type: min 측정값의 sql 매개변수는 숫자 테이블 열, LookML 측정기준 또는 LookML 측정기준의 조합을 생성하는 유효한 SQL 표현식을 사용할 수 있습니다.
type: min 측정값은 숫자 필드와만 호환되므로 type: min 측정값을 사용하여 최소 날짜를 찾을 수 없습니다. 대신 type: date 측정항목의 sql 매개변수에서 MIN() 함수를 사용하여 최솟값을 캡처할 수 있습니다. type: date 측정항목에서 MAX() 함수를 사용하여 최대 날짜를 캡처할 수 있는 것과 마찬가지입니다. 이는 이 페이지의 date 섹션에 나와 있습니다. 여기에는 sql 매개변수에서 MAX() 함수를 사용하여 최대 날짜를 찾는 예가 포함되어 있습니다.
type: min 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
예를 들어 다음 LookML은 sales_price 측정기준을 살펴 smallest_order라는 필드를 만든 다음, 이를 통화 형식 ($1,234.56)으로 표시합니다.
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
문자열이나 날짜에는 type: min 측정항목을 사용할 수 없지만 다음과 같이 MIN 함수를 수동으로 추가하여 이러한 필드를 만들 수 있습니다.
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number는 숫자 또는 정수와 함께 사용됩니다. type: number 측정은 집계를 수행하지 않으며 다른 측정에 대한 기본 변환을 수행하기 위한 것입니다. 다른 측정값을 기반으로 하는 측정값을 정의하는 경우 중첩된 집계 오류를 방지하려면 새 측정값이 type: number여야 합니다.
type: number 측정의 sql 매개변수는 숫자 또는 정수를 생성하는 유효한 SQL 표현식을 사용할 수 있습니다.
type: number 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
예를 들어 다음 LookML은 total_sale_price 및 total_gross_margin 집계 측정값을 기반으로 total_gross_margin_percentage라는 측정값을 만든 다음 소수점 두 자리 (12.34%)가 있는 백분율 형식으로 표시합니다.
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
이 예에서는 NULLIF() SQL 함수를 사용하여 0으로 나누기 오류의 가능성을 없앱니다.
type: number 관련 고려사항
type: number 측정항목을 사용할 때는 몇 가지 중요한 사항에 유의해야 합니다.
type: number측정값은 다른 측정값에 대해서만 산술 연산을 실행할 수 있으며 다른 측정기준에 대해서는 실행할 수 없습니다.- 조인에서 계산될 때 Looker 대칭 집계는 측정값
type: number의 SQL에서 집계 함수를 보호하지 않습니다. filters매개변수는type: number측정과 함께 사용할 수 없지만filters문서에 해결 방법이 설명되어 있습니다.type: number측정항목은 사용자에게 추천을 제공하지 않습니다.
percent_of_previous
type: percent_of_previous은 셀과 해당 열의 이전 셀 간의 비율 차이를 계산합니다.
type: percent_of_previous 측정값의 sql 매개변수는 다른 숫자 측정값을 참조해야 합니다.
type: percent_of_previous 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다. 하지만 value_format_name 매개변수의 백분율 형식은 type: percent_of_previous 측정항목과 함께 사용할 수 없습니다. 이러한 백분율 형식은 값에 100을 곱하므로 이전 비율 계산 결과가 왜곡됩니다.
이 예시 LookML은 count 측정값을 기반으로 하는 count_growth 측정값을 만듭니다.
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
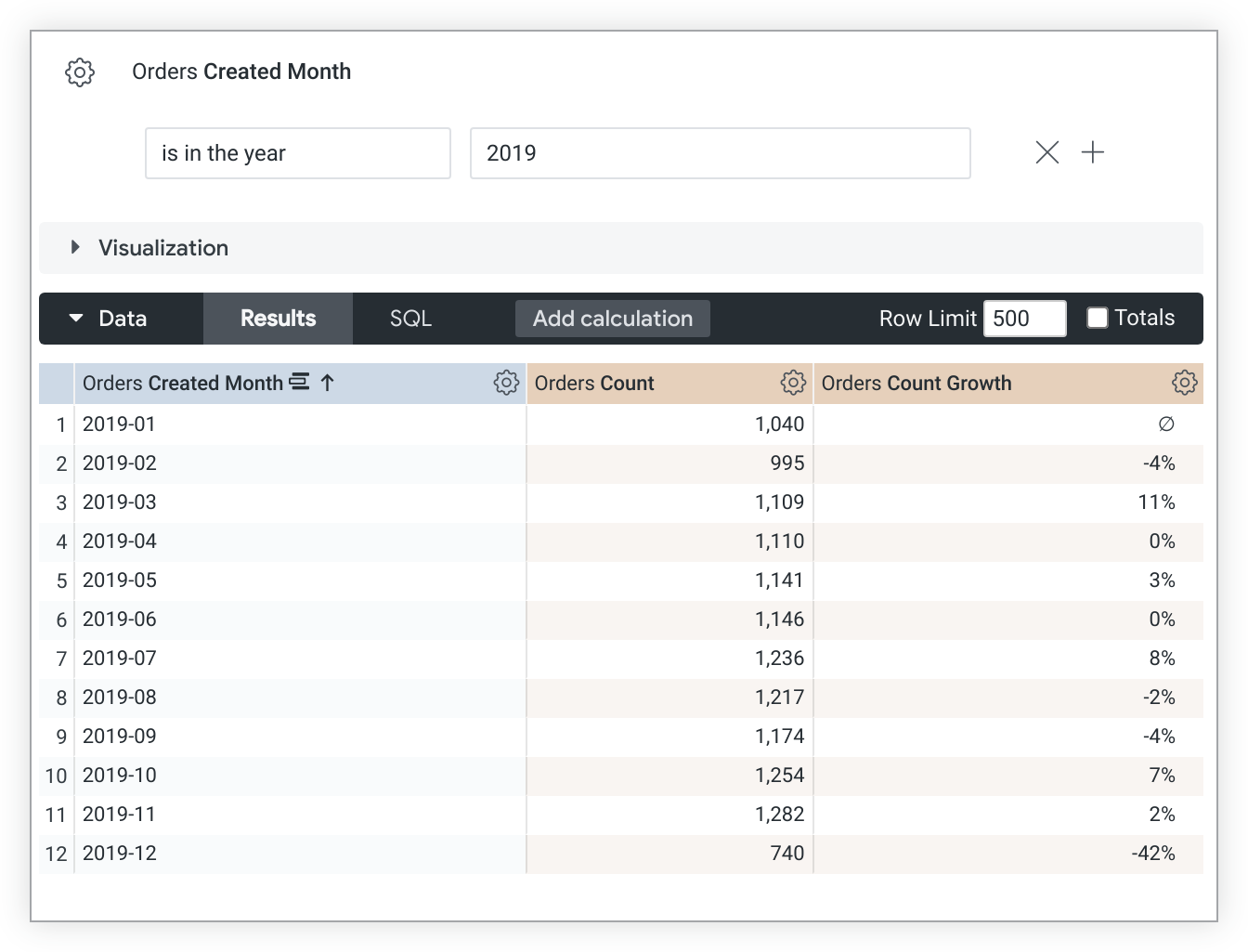
percent_of_previous 값은 정렬 순서에 따라 달라집니다. 정렬을 변경하는 경우 쿼리를 다시 실행하여 percent_of_previous 값을 다시 계산해야 합니다. 쿼리가 피벗된 경우 percent_of_previous는 열 아래가 아닌 행 전체에 걸쳐 실행됩니다. 이 동작은 변경할 수 없습니다.
또한 percent_of_previous 측정항목은 데이터베이스에서 데이터가 반환된 후에 계산됩니다. 즉, 다른 측정항목 내에서 percent_of_previous 측정항목을 참조해서는 안 됩니다. 다른 시점에 계산될 수 있으므로 정확한 결과를 얻지 못할 수 있습니다. 또한 percent_of_previous 측정값은 필터링할 수 없습니다.
이러한 유형의 측정의 한 가지 적용 사례는 기간별 (PoP) 분석입니다. 이는 현재의 무언가를 측정하고 과거의 유사한 기간의 동일한 측정과 비교하는 분석 패턴입니다. PoP에 대한 자세한 내용은 Looker 커뮤니티 도움말 기간별 분석을 수행하는 방법 및 Looker에서 기간별 (PoP) 분석을 수행하는 방법을 참고하세요.
percent_of_total
type: percent_of_total는 열 합계에서 셀이 차지하는 비율을 계산합니다. 비율은 쿼리에서 반환된 행의 합계를 기준으로 계산되며, 가능한 모든 행의 합계를 기준으로 계산되는 것은 아닙니다. 하지만 쿼리에서 반환된 데이터가 행 한도를 초과하는 경우 합계 비율을 계산하려면 전체 결과가 필요하므로 필드의 값이 null로 표시됩니다.
type: percent_of_total 측정값의 sql 매개변수는 다른 숫자 측정값을 참조해야 합니다.
type: percent_of_total 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다. 하지만 value_format_name 매개변수의 백분율 형식은 type: percent_of_total 측정항목과 함께 사용할 수 없습니다. 이러한 백분율 형식은 값에 100을 곱하므로 percent_of_total 계산 결과가 왜곡됩니다.
이 예시 LookML은 total_gross_margin 측정값을 기반으로 하는 percent_of_total_gross_margin 측정값을 만듭니다.
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
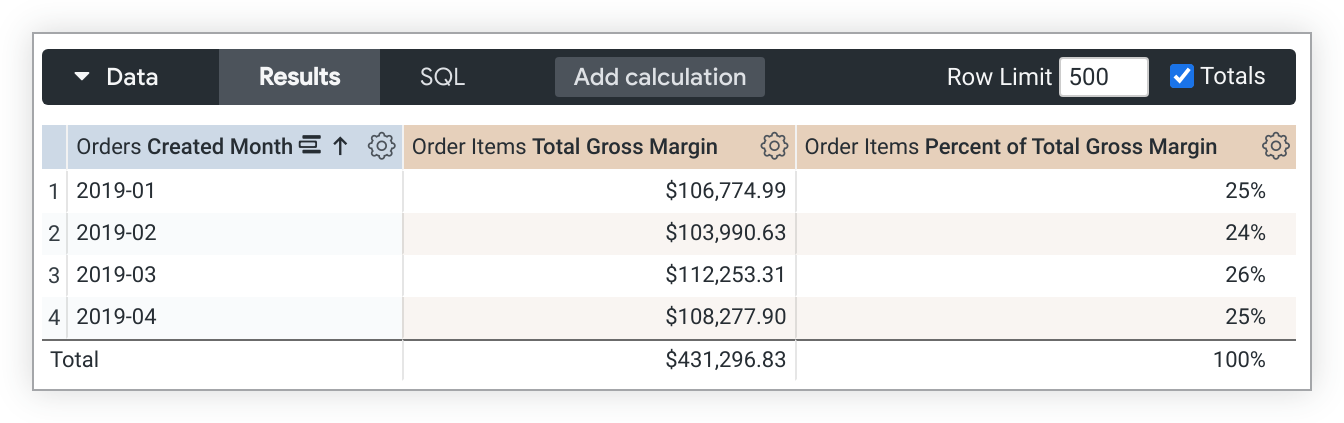
쿼리가 피벗된 경우 percent_of_total은 열이 아닌 행을 따라 실행됩니다. 원하는 결과가 아닌 경우 측정값 정의에 direction: "column"을 추가하세요.
또한 percent_of_total 측정항목은 데이터베이스에서 데이터가 반환된 후에 계산됩니다. 즉, 다른 측정항목 내에서 percent_of_total 측정항목을 참조해서는 안 됩니다. 다른 시점에 계산될 수 있으므로 정확한 결과를 얻지 못할 수 있습니다. 또한 percent_of_total 측정값은 필터링할 수 없습니다.
percentile
type: percentile는 지정된 백분위수의 값을 지정된 필드에서 반환합니다. 예를 들어 75번째 백분위수를 지정하면 데이터 세트의 다른 값 중 75% 보다 큰 값이 반환됩니다.
반환할 값을 식별하기 위해 Looker는 총 데이터 값 수를 계산하고 지정된 백분위수에 총 데이터 값 수를 곱합니다. 데이터의 실제 정렬 방식과 관계없이 Looker는 값이 증가하는 데이터 값의 상대적 순서를 식별합니다. Looker가 반환하는 데이터 값은 다음 두 섹션에 설명된 대로 계산 결과가 정수인지 여부에 따라 달라집니다.
계산된 값이 정수가 아닌 경우
Looker는 계산된 값을 올림하여 반환할 데이터 값을 식별하는 데 사용합니다. 이 19개 시험 점수 예시에서 75번째 백분위수는 19 * 0.75 = 14.25로 식별됩니다. 즉, 값의 75% 가 첫 14개 데이터 값에 있습니다(15번째 위치 아래). 따라서 Looker는 15번째 데이터 값 (87)이 데이터 값의 75% 보다 크다고 반환합니다.

계산된 값이 정수인 경우
이보다 약간 더 복잡한 경우 Looker는 해당 위치의 데이터 값과 다음 데이터 값의 평균을 반환합니다. 이를 이해하기 위해 20개의 시험 점수 세트를 생각해 보겠습니다. 75번째 백분위수는 20 * 0.75 = 15로 식별됩니다. 즉, 15번째 위치의 데이터 값이 75번째 백분위수에 속하며 데이터 값의 75% 보다 높은 값을 반환해야 합니다. 15번째 위치 (82)와 16번째 위치 (87)의 값의 평균을 반환하여 Looker는 75%를 보장합니다. 이 평균 (84.5)은 데이터 값 집합에 없지만 데이터 값의 75% 보다 큽니다.

필수 매개변수 및 선택적 매개변수
percentile: 키워드를 사용하여 분수 값을 지정합니다. 이는 반환된 값보다 작아야 하는 데이터의 비율을 의미합니다. 예를 들어 percentile: 75를 사용하여 데이터 순서의 75번째 백분위수의 값을 지정하거나 percentile: 10를 사용하여 10번째 백분위수의 값을 반환합니다. 50번째 백분위수의 값을 찾으려면 percentile: 50를 지정하거나 median 유형을 사용하면 됩니다.
type: percentile 측정의 sql 매개변수는 숫자 테이블 열, LookML 측정기준 또는 LookML 측정기준의 조합을 생성하는 유효한 SQL 표현식을 사용할 수 있습니다.
type: percentile 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
예
예를 들어 다음 LookML은 test_scores 측정기준의 75번째 백분위수 값을 반환하는 test_scores_75th_percentile라는 필드를 만듭니다.
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
percentile 관련 고려사항
팬아웃과 관련된 필드에 percentile을 사용하는 경우 Looker는 대신 percentile_distinct을 사용하려고 시도합니다. percentile_distinct을 언어에서 사용할 수 없는 경우 Looker는 오류를 반환합니다. 자세한 내용은 percentile_distinct의 지원되는 언어를 참고하세요.
percentile에 지원되는 데이터베이스 언어
Looker가 Looker 프로젝트에서 percentile 유형을 지원하려면 데이터베이스 언어에서도 이를 지원해야 합니다. 다음 표에서는 최신 버전의 Looker에서 percentile 유형을 지원하는 언어를 보여줍니다.
| 언어 | 지원 여부 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
percentile_distinct
type: percentile_distinct은(는) 백분위수의 특수화된 형태이며 조인에 팬아웃이 포함된 경우에 사용해야 합니다. sql_distinct_key 매개변수로 정의된 고유 값을 기반으로 지정된 필드의 반복되지 않는 값을 사용합니다. 측정에 sql_distinct_key 매개변수가 없는 경우 Looker는 primary_key 필드를 사용하려고 시도합니다.
주문 항목과 주문 테이블을 조인하는 쿼리의 결과를 고려해 보세요.
| 주문 상품 ID | 주문 ID | 주문 배송 |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
이 경우 각 주문에 여러 행이 표시됩니다. 각 주문이 여러 주문 항목에 매핑되므로 이 쿼리에는 팬아웃이 포함되었습니다. percentile_distinct는 이를 고려하여 고유한 값 10, 20, 50, 70, 110을 사용하여 백분위수 값을 찾습니다. 25번째 백분위수는 두 번째 고유 값인 20을 반환하고 80번째 백분위수는 네 번째와 다섯 번째 고유 값의 평균인 90을 반환합니다.
필수 매개변수 및 선택적 매개변수
percentile: 키워드를 사용하여 분수 값을 지정합니다. 예를 들어 percentile: 75를 사용하여 데이터 순서에서 75번째 백분위수의 값을 지정하거나 percentile: 10를 사용하여 10번째 백분위수의 값을 반환할 수 있습니다. 50번째 백분위수의 값을 찾으려는 경우 median_distinct 유형을 대신 사용할 수 있습니다.
정확한 결과를 얻으려면 sql_distinct_key 매개변수를 사용하여 Looker가 각 고유 항목 (이 경우 각 고유 주문)을 식별하는 방법을 지정하세요.
다음은 percentile_distinct를 사용하여 90번째 백분위수의 값을 반환하는 예입니다.
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key의 모든 고유 값에는 측정항목의 sql 매개변수에 해당하는 값이 하나만 있어야 합니다. 즉, 앞의 예는 order_id이 1인 모든 행의 order_shipping이 10으로 동일하고 order_id이 2인 모든 행의 order_shipping이 20으로 동일하기 때문에 작동합니다.
type: percentile_distinct 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
percentile_distinct 관련 고려사항
percentile_distinct을 언어에서 사용할 수 없는 경우 Looker는 오류를 반환합니다. 자세한 내용은 percentile_distinct의 지원되는 언어를 참고하세요.
percentile_distinct에 지원되는 데이터베이스 언어
Looker가 Looker 프로젝트에서 percentile_distinct 유형을 지원하려면 데이터베이스 언어에서도 이를 지원해야 합니다. 다음 표에서는 최신 버전의 Looker에서 percentile_distinct 유형을 지원하는 언어를 보여줍니다.
| 언어 | 지원 여부 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
period_over_period
기간별 측정값을 지원하는 언어의 경우 type: period_over_period의 LookML 측정값을 만들어 기간별 (PoP) 측정값을 만들 수 있습니다. PoP 측정값은 이전 기간의 집계를 참조합니다.
다음은 이전 달의 주문 수를 제공하는 PoP 측정값의 예입니다.
measure: orders_last_month {
type: period_over_period
based_on: orders.count
based_on_time: orders.created_month
period: month
kind: previous
}
type: period_over_period가 있는 측정항목에는 다음 하위 매개변수도 있어야 합니다.
자세한 내용과 예시는 Looker의 기간별 측정을 참고하세요.
running_total
type: running_total는 열을 따라 셀의 누적 합계를 계산합니다. 행이 피벗된 결과가 아닌 경우 행을 따라 합계를 계산하는 데 사용할 수 없습니다.
type: running_total 측정값의 sql 매개변수는 다른 숫자 측정값을 참조해야 합니다.
type: running_total 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
다음 LookML 예에서는 total_sale_price 측정값을 기반으로 하는 cumulative_total_revenue 측정값을 만듭니다.
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
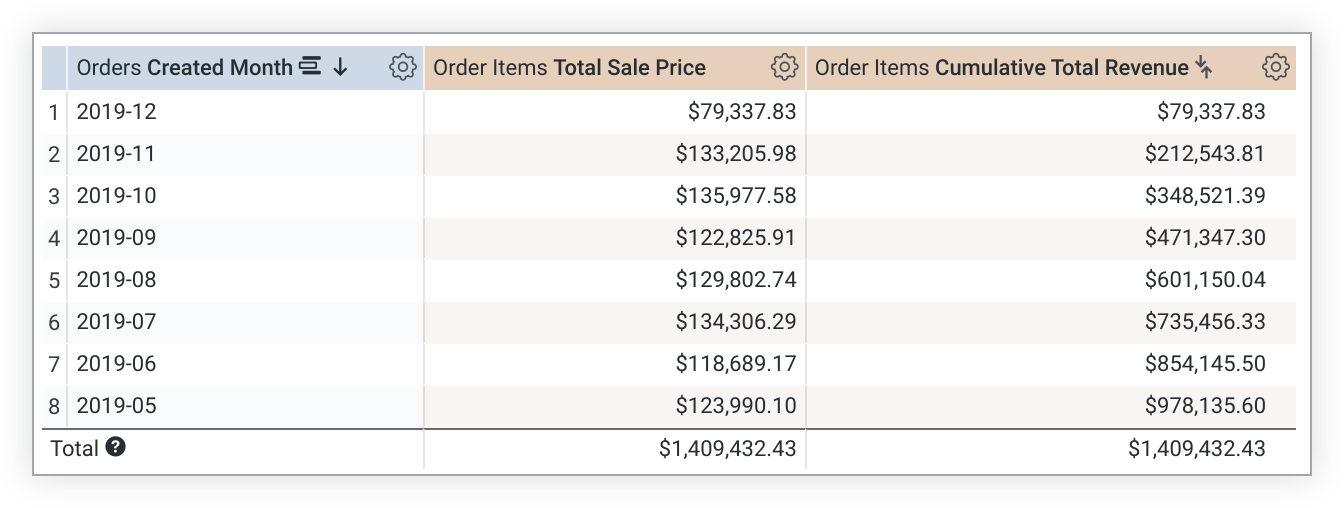
running_total 값은 정렬 순서에 따라 달라집니다. 정렬을 변경하는 경우 쿼리를 다시 실행하여 running_total 값을 다시 계산해야 합니다. 쿼리가 피벗된 경우 running_total는 열 아래가 아닌 행 전체에 걸쳐 실행됩니다. 원하는 결과가 아닌 경우 측정항목 정의에 direction: "column"를 추가하세요.
또한 running_total 측정항목은 데이터베이스에서 데이터가 반환된 후에 계산됩니다. 즉, 다른 측정항목 내에서 running_total 측정항목을 참조해서는 안 됩니다. 다른 시점에 계산될 수 있으므로 정확한 결과를 얻지 못할 수 있습니다. 또한 running_total 측정값은 필터링할 수 없습니다.
string
type: string는 문자 또는 특수문자가 포함된 필드와 함께 사용됩니다.
type: string 측정항목의 sql 매개변수는 문자열을 생성하는 유효한 SQL 표현식을 사용할 수 있습니다. 대부분의 SQL 집계 함수는 문자열을 반환하지 않으므로 실제로 이 유형은 거의 사용되지 않습니다. 일반적인 예외는 MySQL의 GROUP_CONCAT 함수이지만 Looker는 이 사용 사례에 type: list를 제공합니다.
예를 들어 다음 LookML은 category이라는 필드의 고유 값을 결합하여 category_list 필드를 만듭니다.
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
이 예시에서는 type의 기본값이 string이므로 type: string를 생략할 수 있습니다.
sum
type: sum은 지정된 필드의 값을 합산합니다. SQL의 SUM 함수와 유사합니다. 하지만 원시 SQL과 달리 Looker는 쿼리의 조인에 팬아웃이 포함되어 있어도 합계를 올바르게 계산합니다.
type: sum 측정의 sql 매개변수는 숫자 테이블 열, LookML 측정기준 또는 LookML 측정기준의 조합을 생성하는 유효한 SQL 표현식을 사용할 수 있습니다.
type: sum 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
예를 들어 다음 LookML은 sales_price 측정기준을 합산하여 total_revenue라는 필드를 만든 다음 이를 통화 형식 ($1,234.56)으로 표시합니다.
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct는 정규화되지 않은 데이터 세트와 함께 사용됩니다. sql_distinct_key 매개변수로 정의된 고유 값을 기반으로 지정된 필드의 반복되지 않는 값을 합산합니다.
이는 고급 개념으로, 예를 통해 더 명확하게 설명할 수 있습니다. 다음과 같은 비정규화된 테이블을 고려해 보세요.
| 주문 상품 ID | 주문 ID | 주문 배송 |
|---|---|---|
| 1 | 1 | 10.00 |
| 2 | 1 | 10.00 |
| 3 | 2 | 20.00 |
| 4 | 2 | 20.00 |
| 5 | 2 | 20.00 |
이 경우 각 주문에 여러 행이 표시됩니다. 따라서 order_shipping 열에 type: sum 측정항목을 추가하면 실제로 수집된 총 배송비는 30.00이지만 총 80.00이 표시됩니다.
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
정확한 결과를 얻으려면 sql_distinct_key 매개변수를 사용하여 Looker에서 각 고유 항목 (이 경우 각 고유 주문)을 식별하는 방법을 정의하면 됩니다. 이렇게 하면 올바른 금액인 30.00이 계산됩니다.
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
sql_distinct_key의 모든 고유 값에는 sql의 해당 값이 하나만 있어야 합니다. 즉, 앞의 예는 order_id가 1인 모든 행의 order_shipping가 10.00으로 동일하고 order_id가 2인 모든 행의 order_shipping가 20.00으로 동일하기 때문에 작동합니다.
type: sum_distinct 필드는 value_format 또는 value_format_name 매개변수를 사용하여 형식을 지정할 수 있습니다.
yesno
type: yesno는 어떤 것이 참인지 거짓인지를 나타내는 필드를 만듭니다. 값은 Explore UI에 Yes 및 No로 표시됩니다.
type: yesno 측정항목의 sql 매개변수는 TRUE 또는 FALSE로 평가되는 유효한 SQL 표현식을 사용합니다. 조건이 TRUE로 평가되면 사용자에게 예가 표시되고, 그렇지 않으면 아니요가 표시됩니다.
type: yesno 측정값의 SQL 표현식에는 집계만 포함되어야 합니다. 즉, SQL 집계 또는 LookML 측정값에 대한 참조만 포함되어야 합니다. LookML 측정기준에 대한 참조 또는 집계가 아닌 SQL 표현식을 포함하는 yesno 필드를 만들려면 측정값이 아닌 type: yesno이 있는 측정기준을 사용하세요.
type: number이 있는 측정값과 마찬가지로 type: yesno이 있는 측정값은 집계를 수행하지 않고 다른 집계만 참조합니다.
예를 들어 다음 total_sale_price 측정값 예시는 주문의 주문 항목 총 판매 가격의 합계입니다. is_large_total이라는 두 번째 측정값은 type: yesno입니다. is_large_total 측정값에는 total_sale_price 값이 1,000달러보다 큰지 평가하는 sql 매개변수가 있습니다.
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
다른 필드에서 type: yesno 필드를 참조하려면 type: yesno 필드를 불리언으로 처리해야 합니다 (즉, 이미 true 또는 false 값이 포함된 것처럼). 예를 들면 다음과 같습니다.
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
# This is correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}