
Questa pagina si riferisce al parametro
type, che fa parte di una misura.
typepuò essere utilizzato anche nell'ambito di una dimensione o di un filtro, come descritto nella pagina della documentazione Tipi di dimensioni, filtri e parametri.
typepuò essere utilizzato anche nell'ambito di un gruppo di dimensioni, come descritto nella pagina della documentazione dedicata al parametrodimension_group.
Utilizzo
view: view_name {
measure: field_name {
type: measure_field_type
}
}
|
Gerarchia
type |
Tipi di campi possibili
Misura
Accetta
Un tipo di misura
|
Questa pagina include dettagli sui vari tipi che possono essere assegnati a una misura. Una misura può avere un solo tipo e il valore predefinito è string se non viene specificato alcun tipo.
Alcuni tipi di misura hanno parametri di supporto, descritti nella sezione appropriata.
Categorie di tipi di misura
Ogni tipo di misura rientra in una delle seguenti categorie. Queste categorie determinano se il tipo di misura esegue aggregazioni, il tipo di campi a cui può fare riferimento e se puoi filtrare il tipo di misura utilizzando il parametro filters:
- Misure aggregate: i tipi di misure aggregate eseguono aggregazioni, ad esempio
sumeaverage. Le misure aggregate possono fare riferimento solo a dimensioni, non ad altre misure. Questo è l'unico tipo di misura che funziona con il parametrofilters. - Misure non aggregate: come suggerisce il nome, le misure non aggregate sono tipi di misure che non eseguono aggregazioni, ad esempio
numbereyesno. Questi tipi di misure eseguono trasformazioni di base e, poiché non eseguono aggregazioni, possono fare riferimento solo a misure aggregate o a dimensioni aggregate in precedenza. Non puoi utilizzare il parametrofilterscon questi tipi di misure. - Misure post-SQL: le misure post-SQL sono tipi di misure speciali che eseguono calcoli specifici dopo che Looker ha generato l'SQL della query. Possono fare riferimento solo a misure numeriche o dimensioni numeriche. Non puoi utilizzare il parametro
filterscon questi tipi di misurazione.
Elenco delle definizioni dei tipi
| Tipo | Categoria | Descrizione |
|---|---|---|
average |
Aggregazione | Genera una media dei valori all'interno di una colonna |
average_distinct |
Aggregazione | Genera correttamente una media dei valori quando utilizza dati denormalizzati. Per una descrizione completa, consulta la sezione average_distinct. |
count |
Aggregazione | Genera un conteggio delle righe |
count_distinct |
Aggregazione | Genera un conteggio dei valori univoci all'interno di una colonna |
date |
Non aggregato | Per le misure che contengono date |
list |
Aggregazione | Genera un elenco dei valori univoci all'interno di una colonna |
max |
Aggregazione | Genera il valore massimo all'interno di una colonna |
median |
Aggregazione | Genera la mediana (valore centrale) dei valori all'interno di una colonna |
median_distinct |
Aggregazione | Genera correttamente una mediana (valore intermedio) dei valori quando un'unione causa un fanout. Per una descrizione completa, consulta la sezione median_distinct. |
min |
Aggregazione | Genera il valore minimo all'interno di una colonna |
number |
Non aggregato | Per le misure che contengono numeri |
percent_of_previous |
Post-SQL | Genera la differenza percentuale tra le righe visualizzate |
percent_of_total |
Post-SQL | Genera la percentuale del totale per ogni riga visualizzata |
percentile |
Aggregazione | Genera il valore al percentile specificato all'interno di una colonna |
percentile_distinct |
Aggregazione | Genera correttamente il valore al percentile specificato quando un'unione causa un fanout. Per una descrizione completa, consulta la sezione percentile_distinct. |
running_total |
Post-SQL | Genera il totale parziale per ogni riga visualizzata |
period_over_period |
Aggregazione | Fa riferimento a un'aggregazione di un periodo di tempo precedente |
string |
Non aggregato | Per le misure che contengono lettere o caratteri speciali (come la funzione GROUP_CONCAT di MySQL) |
sum |
Aggregazione | Genera una somma dei valori all'interno di una colonna |
sum_distinct |
Aggregazione | Genera correttamente una somma di valori quando vengono utilizzati dati denormalizzati.Per una descrizione completa, consulta la sezione sum_distinct. |
yesno |
Non aggregato | Per i campi che mostrano se qualcosa è vero o falso |
int |
Non aggregato |
Rimosso 5.4
Sostituito da type: number |
average
type: average calcola la media dei valori in un determinato campo. È simile alla funzione AVG di SQL. Tuttavia, a differenza di SQL non elaborato, Looker calcolerà correttamente le medie anche se i join della query contengono fanout.
Il parametro sql per le misure type: average può accettare qualsiasi espressione SQL valida che restituisca una colonna della tabella numerica, una dimensione LookML o una combinazione di dimensioni LookML.
I campi type: average possono essere formattati utilizzando i parametri value_format o value_format_name.
Ad esempio, il seguente codice LookML crea un campo denominato avg_order calcolando la media della dimensione sales_price, quindi lo visualizza in un formato monetario (1234,56 $):
measure: avg_order {
type: average
sql: ${sales_price} ;;
value_format_name: usd
}
average_distinct
type: average_distinct è da utilizzare con set di dati denormalizzati. Calcola la media dei valori non ripetuti in un determinato campo, in base ai valori univoci definiti dal parametro sql_distinct_key.
Si tratta di un concetto avanzato che può essere spiegato più chiaramente con un esempio. Prendi in considerazione una tabella denormalizzata come questa:
| ID articolo ordine | ID ordine | Spedizione dell'ordine |
|---|---|---|
| 1 | 1 | 10,00 |
| 2 | 1 | 10,00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
In questa situazione, puoi notare che ci sono più righe per ogni ordine. Di conseguenza, se hai aggiunto una misura type: average di base per la colonna order_shipping, otterresti un valore di 16,00, anche se la media effettiva è 15,00.
# Will NOT calculate the correct average
measure: avg_shipping {
type: average
sql: ${order_shipping} ;;
}
Per ottenere un risultato accurato, puoi definire per Looker come identificare ogni entità univoca (in questo caso, ogni ordine univoco) utilizzando il parametro sql_distinct_key. In questo modo verrà calcolato l'importo corretto di 15,00:
# Will calculate the correct average
measure: avg_shipping {
type: average_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Ogni valore univoco di sql_distinct_key deve avere un solo valore corrispondente in sql. In altre parole, l'esempio precedente funziona perché ogni riga con un order_id di 1 ha lo stesso order_shipping di 10,00 e ogni riga con un order_id di 2 ha lo stesso order_shipping di 20,00.
I campi type: average_distinct possono essere formattati utilizzando i parametri value_format o value_format_name.
count
type: count esegue un conteggio delle tabelle, in modo simile alla funzione COUNT di SQL. Tuttavia, a differenza di SQL non elaborato, Looker calcolerà correttamente i conteggi anche se i join della query contengono fanout.
Le misure type: count eseguono conteggi delle tabelle basati sulla chiave primaria della tabella, pertanto le misure type: count non supportano il parametro sql.
Se vuoi eseguire un conteggio delle tabelle su un campo diverso dalla chiave primaria della tabella, utilizza una misura type: count_distinct. In alternativa, se non vuoi utilizzare count_distinct, puoi utilizzare una misura di type: number (per maggiori informazioni, consulta il post della community How to count a non-primary key).
Ad esempio, il seguente codice LookML crea un campo number_of_products:
view: products {
measure: number_of_products {
type: count
drill_fields: [product_details*] # optional
}
}
È molto comune fornire un parametro drill_fields (per i campi) quando si definisce una misura type: count, in modo che gli utenti possano visualizzare i singoli record che compongono un conteggio quando fanno clic.
Quando utilizzi una misura di
type: countin un'esplorazione, la visualizzazione etichetta i valori risultanti con il nome della visualizzazione anziché con la parola "Conteggio". Per evitare confusione, ti consigliamo di mettere al plurale il nome della visualizzazione, selezionare Mostra nome completo del campo in Serie nelle impostazioni di visualizzazione o utilizzare unview_labelcon una versione al plurale del nome della visualizzazione.
Puoi aggiungere un filtro a una misura di type: count utilizzando il parametro filters.
count_distinct
type: count_distinct calcola il numero di valori distinti in un determinato campo. Utilizza la funzione COUNT DISTINCT di SQL.
Il parametro sql per le misure type: count_distinct può accettare qualsiasi espressione SQL valida che restituisce una colonna della tabella, una dimensione LookML o una combinazione di dimensioni LookML.
Ad esempio, il seguente codice LookML crea un campo number_of_unique_customers, che conta il numero di ID cliente unici:
measure: number_of_unique_customers {
type: count_distinct
sql: ${customer_id} ;;
}
Puoi aggiungere un filtro a una misura di type: count_distinct utilizzando il parametro filters.
date
type: date viene utilizzato con i campi che contengono date.
Il parametro sql per le misure type: date può accettare qualsiasi espressione SQL valida che restituisce una data. In pratica, questo tipo viene utilizzato raramente, perché la maggior parte delle funzioni di aggregazione SQL non restituisce date. Un'eccezione comune è un MIN o un MAX di una dimensione data.
Creazione di una misura della data massima o minima con type: date
Se vuoi creare una misura di una data massima o minima, potresti inizialmente pensare che funzioni utilizzare una misura di type: max o di type: min. Tuttavia, questi tipi di misura sono compatibili solo con i campi numerici. Puoi invece acquisire una data massima o minima definendo una misura di type: date e racchiudendo il campo data a cui viene fatto riferimento nel parametro sql in una funzione MIN() o MAX().
Supponiamo di avere un gruppo di dimensioni di type: time, chiamato updated:
dimension_group: updated {
type: time
timeframes: [time, date, week, month, raw]
sql: ${TABLE}.updated_at ;;
}
Puoi creare una misura di type: date per acquisire la data massima di questo gruppo di dimensioni nel seguente modo:
measure: last_updated_date {
type: date
sql: MAX(${updated_raw}) ;;
convert_tz: no
}
In questo esempio, anziché utilizzare una misura di type: max per creare la misura last_updated_date, la funzione MAX() viene applicata nel parametro sql. La misura last_updated_date ha anche il parametro convert_tz impostato su no per evitare la doppia conversione del fuso orario nella misura, poiché la conversione del fuso orario è già avvenuta nella definizione del gruppo di dimensioni updated. Per saperne di più, consulta la documentazione relativa al parametro convert_tz.
Nell'esempio di LookML per la misura last_updated_date, type: date potrebbe essere omesso e il valore verrebbe trattato come una stringa, perché string è il valore predefinito per type. Tuttavia, se utilizzi type: date, otterrai una migliore funzionalità di filtro per gli utenti.
Potresti anche notare che la definizione della misura last_updated_date fa riferimento al periodo di tempo ${updated_raw} anziché al periodo di tempo ${updated_date}. Poiché il valore restituito da ${updated_date} è una stringa, è necessario utilizzare ${updated_raw} per fare riferimento al valore della data effettivo.
Puoi anche utilizzare il parametro datatype con type: date per migliorare il rendimento delle query specificando il tipo di dati di data utilizzato dalla tabella del database.
Creazione di una misura massima o minima per una colonna data/ora
Il calcolo del valore massimo per una colonna type: datetime è leggermente diverso. In questo caso, vuoi creare una misura senza dichiarare il tipo, come segue:
measure: last_updated_datetime {
sql: MAX(${TABLE}.datetime_string_field) ;;
}
list
type: list crea un elenco dei valori univoci in un determinato campo. È simile alla funzione GROUP_CONCAT di MySQL.
Non è necessario includere un parametro sql per le misure type: list. Puoi invece utilizzare il parametro list_field per specificare la dimensione da cui vuoi creare gli elenchi.
L'utilizzo è il seguente:
view: view_name {
measure: field_name {
type: list
list_field: my_field_name
}
}
Ad esempio, il seguente codice LookML crea una misura name_list basata sulla dimensione name:
measure: name_list {
type: list
list_field: name
}
Tieni presente quanto segue per list:
- Il tipo di misura
listnon supporta il filtraggio. Non puoi utilizzare il parametrofiltersin una misuratype: list. - Non è possibile fare riferimento al tipo di misura
listutilizzando l'operatore di sostituzione ($). Non puoi utilizzare la sintassi${}per fare riferimento a una misuratype: list.
Dialetti del database supportati per list
Affinché Looker supporti type: list nel tuo progetto Looker, deve supportarlo anche il dialetto del database. La tabella seguente mostra quali dialetti supportano type: list nell'ultima release di Looker:
| Dialetto | Supportata? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
max
type: max trova il valore più grande in un determinato campo. Utilizza la funzione MAX di SQL.
Il parametro sql per le misure di type: max può accettare qualsiasi espressione SQL valida che restituisca una colonna della tabella numerica, una dimensione LookML o una combinazione di dimensioni LookML.
Poiché le misure di type: max sono compatibili solo con i campi numerici, non puoi utilizzare una misura di type: max per trovare una data massima. Puoi invece utilizzare la funzione MAX() nel parametro sql di una misura di type: date per acquisire una data massima, come mostrato in precedenza negli esempi della sezione date.
I campi type: max possono essere formattati utilizzando i parametri value_format o value_format_name.
Ad esempio, il seguente codice LookML crea un campo denominato largest_order esaminando la dimensione sales_price, quindi lo visualizza in un formato monetario (1234,56 $):
measure: largest_order {
type: max
sql: ${sales_price} ;;
value_format_name: usd
}
Non puoi utilizzare le misure type: max per stringhe o date, ma puoi aggiungere manualmente la funzione MAX per creare un campo di questo tipo, ad esempio:
measure: latest_name_in_alphabet {
type: string
sql: MAX(${name}) ;;
}
median
type: median restituisce il valore medio per i valori in un determinato campo. Questa funzione è particolarmente utile quando i dati presentano alcuni valori anomali molto grandi o piccoli che falserebbero una media di base (media aritmetica) dei dati.
Considera una tabella come questa:
| ID articolo ordine | Costo | Punto medio? |
|---|---|---|
| 2 | 10,00 | |
| 4 | 10,00 | |
| 3 | 20,00 | Valore intermedio |
| 1 | 80,00 | |
| 5 | 90,00 |
La tabella è ordinata per costo, ma ciò non influisce sul risultato. Mentre il tipo average restituirebbe 42 (sommando tutti i valori e dividendo per 5), il tipo median restituirebbe il valore medio: 20.00.
Se è presente un numero pari di valori, il valore mediano viene calcolato prendendo la media dei due valori più vicini al punto medio. Considera una tabella come questa con un numero pari di righe:
| ID articolo ordine | Costo | Punto medio? |
|---|---|---|
| 2 | 10 | |
| 3 | 20 | Il più vicino prima del punto centrale |
| 1 | 80 | Più vicino dopo il punto medio |
| 4 | 90 |
La mediana, il valore medio, è (20 + 80)/2 = 50.
La mediana è anche uguale al valore del 50° percentile.
Il parametro sql per le misure type: median può accettare qualsiasi espressione SQL valida che restituisca una colonna della tabella numerica, una dimensione LookML o una combinazione di dimensioni LookML.
I campi type: median possono essere formattati utilizzando i parametri value_format o value_format_name.
Esempio
Ad esempio, il seguente codice LookML crea un campo denominato median_order calcolando la media della dimensione sales_price, quindi lo visualizza in un formato monetario (1234,56 $):
measure: median_order {
type: median
sql: ${sales_price} ;;
value_format_name: usd
}
Aspetti da considerare per median
Se utilizzi median per un campo coinvolto in un fanout, Looker tenterà di utilizzare median_distinct. Tuttavia, medium_distinct è supportato solo per alcuni dialetti. Se median_distinct non è disponibile per il tuo dialetto, Looker restituisce un errore. Poiché median può essere considerato il 50° percentile, l'errore indica che il dialetto non supporta percentili distinti.
Dialetti del database supportati per median
Affinché Looker supporti il tipo median nel tuo progetto Looker, deve supportarlo anche il dialetto del database. La tabella seguente mostra quali dialetti supportano il tipo median nell'ultima release di Looker:
| Dialetto | Supportata? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
Quando una query include una distribuzione, Looker tenta di convertire median in median_distinct. Questa operazione ha esito positivo solo nei dialetti che supportano median_distinct.
median_distinct
Utilizza type: median_distinct quando l'unione comporta una distribuzione. Calcola la media dei valori non ripetuti in un determinato campo, in base ai valori univoci definiti dal parametro sql_distinct_key. Se la misura non ha un parametro sql_distinct_key, Looker tenta di utilizzare il campo primary_key.
Considera il risultato di una query che unisce le tabelle Elemento ordine e Ordine:
| ID articolo ordine | ID ordine | Spedizione dell'ordine |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
In questa situazione puoi notare che ci sono più righe per ogni ordine. Questa query ha comportato un fanout perché ogni ordine viene mappato a più articoli dell'ordine. La median_distinct tiene conto di questo e trova la mediana tra i valori distinti 10, 20 e 50, quindi otterrai un valore di 20.
Per ottenere un risultato accurato, puoi definire per Looker come identificare ogni entità univoca (in questo caso, ogni ordine univoco) utilizzando il parametro sql_distinct_key. In questo modo verrà calcolato l'importo corretto:
measure: median_shipping {
type: median_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Ogni valore univoco di sql_distinct_key deve avere un solo valore corrispondente nel parametro sql della metrica. In altre parole, l'esempio precedente funziona perché ogni riga con un order_id pari a 1 ha lo stesso order_shipping pari a 10 e ogni riga con un order_id pari a 2 ha lo stesso order_shipping pari a 20.
I campi type: median_distinct possono essere formattati utilizzando i parametri value_format o value_format_name.
Aspetti da considerare per median_distinct
Il tipo di misura medium_distinct è supportato solo per determinati dialetti. Se median_distinct non è disponibile per il dialetto, Looker restituisce un errore. Poiché median può essere considerato il 50° percentile, l'errore indica che il dialetto non supporta percentili distinti.
Dialetti del database supportati per median_distinct
Affinché Looker supporti il tipo median_distinct nel tuo progetto Looker, deve supportarlo anche il dialetto del database. La tabella seguente mostra quali dialetti supportano il tipo median_distinct nell'ultima release di Looker:
| Dialetto | Supportata? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
min
type: min trova il valore più piccolo in un determinato campo. Utilizza la funzione MIN di SQL.
Il parametro sql per le misure di type: min può accettare qualsiasi espressione SQL valida che restituisca una colonna della tabella numerica, una dimensione LookML o una combinazione di dimensioni LookML.
Poiché le misure di type: min sono compatibili solo con i campi numerici, non puoi utilizzare una misura di type: min per trovare una data minima. Puoi invece utilizzare la funzione MIN() nel parametro sql di una misura di type: date per acquisire un valore minimo, proprio come puoi utilizzare la funzione MAX() con una misura di type: date per acquisire una data massima. Questa operazione è stata mostrata in precedenza in questa pagina nella sezione date, che include esempi di utilizzo della funzione MAX() nel parametro sql per trovare una data massima.
I campi type: min possono essere formattati utilizzando i parametri value_format o value_format_name.
Ad esempio, il seguente codice LookML crea un campo denominato smallest_order esaminando la dimensione sales_price, quindi lo visualizza in un formato monetario (1234,56 $):
measure: smallest_order {
type: min
sql: ${sales_price} ;;
value_format_name: usd
}
Non puoi utilizzare le misure type: min per stringhe o date, ma puoi aggiungere manualmente la funzione MIN per creare un campo di questo tipo, ad esempio:
measure: earliest_name_in_alphabet {
type: string
sql: MIN(${name}) ;;
}
number
type: number viene utilizzato con numeri o interi. Una misura di type: number non esegue alcuna aggregazione e ha lo scopo di eseguire trasformazioni di base su altre misure. Se stai definendo una metrica basata su un'altra metrica, la nuova metrica deve essere di tipo type: number per evitare errori di aggregazione nidificata.
Il parametro sql per le misure type: number può accettare qualsiasi espressione SQL valida che restituisca un numero o un numero intero.
I campi type: number possono essere formattati utilizzando i parametri value_format o value_format_name.
Ad esempio, il seguente codice LookML crea una misura denominata total_gross_margin_percentage basata sulle misure aggregate total_sale_price e total_gross_margin, quindi la visualizza in formato percentuale con due decimali (12,34%):
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
}
measure: total_gross_margin {
type: sum
value_format_name: usd
sql: ${gross_margin} ;;
}
measure: total_gross_margin_percentage {
type: number
value_format_name: percent_2
sql: ${total_gross_margin}/ NULLIF(${total_sale_price},0) ;;
}
Questo esempio utilizza anche la funzione SQL NULLIF() per eliminare la possibilità di errori di divisione per zero.
Aspetti da considerare per type: number
Quando utilizzi le metriche type: number, tieni presente alcuni aspetti importanti:
- Una misura di
type: numberpuò eseguire operazioni aritmetiche solo su altre misure, non su altre dimensioni. - Gli aggregati simmetrici di Looker non proteggono le funzioni di aggregazione nell'SQL di una misura
type: numberquando vengono calcolati in un join. - Il parametro
filtersnon può essere utilizzato con le metrichetype: number, ma la documentazione relativa afiltersspiega una soluzione alternativa. type: numbernon forniranno suggerimenti agli utenti.
percent_of_previous
type: percent_of_previous calcola la differenza percentuale tra una cella e la cella precedente nella stessa colonna.
Il parametro sql per le misure type: percent_of_previous deve fare riferimento a un'altra misura numerica.
I campi type: percent_of_previous possono essere formattati utilizzando i parametri value_format o value_format_name. Tuttavia, i formati percentuali del parametro value_format_name non funzionano con le misure type: percent_of_previous. Questi formati di percentuale moltiplicano i valori per 100, il che distorce i risultati di un calcolo della percentuale del precedente.
Questo codice LookML di esempio crea una misura count_growth basata sulla misura count:
measure: count_growth {
type: percent_of_previous
sql: ${count} ;;
}
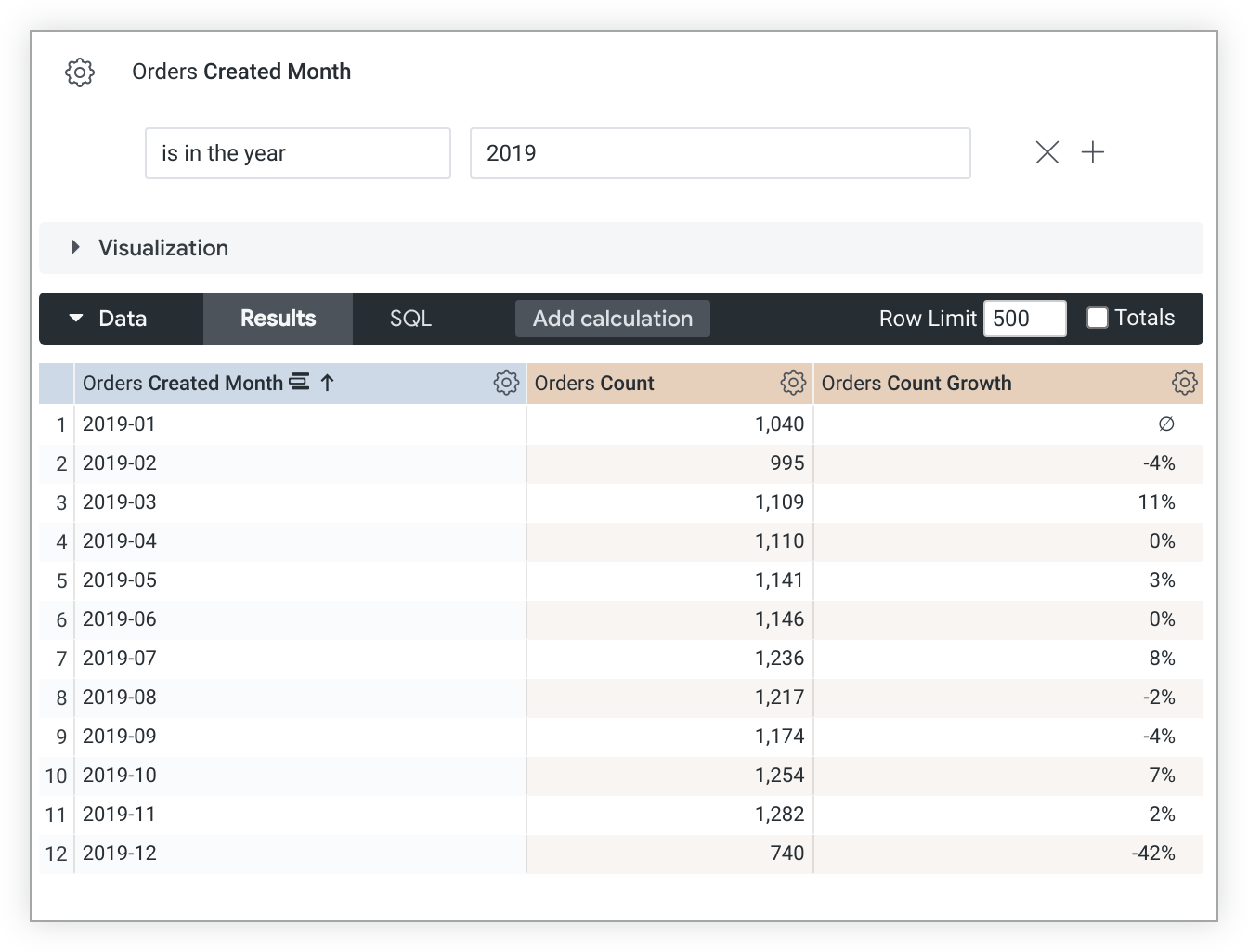
Tieni presente che i valori di percent_of_previous dipendono dall'ordine di ordinamento. Se modifichi l'ordinamento, devi eseguire di nuovo la query per ricalcolare i valori percent_of_previous. Nei casi in cui una query viene ruotata, percent_of_previous viene eseguito sulla riga anziché sulla colonna. Non puoi modificare questo comportamento.
Inoltre, le misure percent_of_previous vengono calcolate dopo la restituzione dei dati dal database. Ciò significa che non devi fare riferimento a una misura percent_of_previous all'interno di un'altra misura, poiché potrebbero essere calcolate in momenti diversi e potresti non ottenere risultati accurati. Significa anche che le misure percent_of_previous non possono essere filtrate.
Un'applicazione di questo tipo di misurazione è l'analisi periodo per periodo (PoP), un modello di analisi che misura qualcosa nel presente e lo confronta con la stessa misurazione in un periodo di tempo comparabile nel passato. Per ulteriori informazioni sul periodo precedente, consulta gli articoli della community di Looker How to do Period-over-Period Analysis e Methods for Period Over Period (PoP) Analysis in Looker.
percent_of_total
type: percent_of_total calcola la porzione di una cella del totale della colonna. La percentuale viene calcolata in base al totale delle righe restituite dalla query e non al totale di tutte le righe possibili. Tuttavia, se i dati restituiti dalla query superano un limite di righe, i valori del campo verranno visualizzati come null, poiché è necessario l'intero risultato per calcolare la percentuale del totale.
Il parametro sql per le misure type: percent_of_total deve fare riferimento a un'altra misura numerica.
I campi type: percent_of_total possono essere formattati utilizzando i parametri value_format o value_format_name. Tuttavia, i formati percentuali del parametro value_format_name non funzionano con le misure type: percent_of_total. Questi formati di percentuale moltiplicano i valori per 100, il che distorce i risultati di un calcolo percent_of_total.
Questo codice LookML di esempio crea una misura percent_of_total_gross_margin basata sulla misura total_gross_margin:
measure: percent_of_total_gross_margin {
type: percent_of_total
sql: ${total_gross_margin} ;;
}
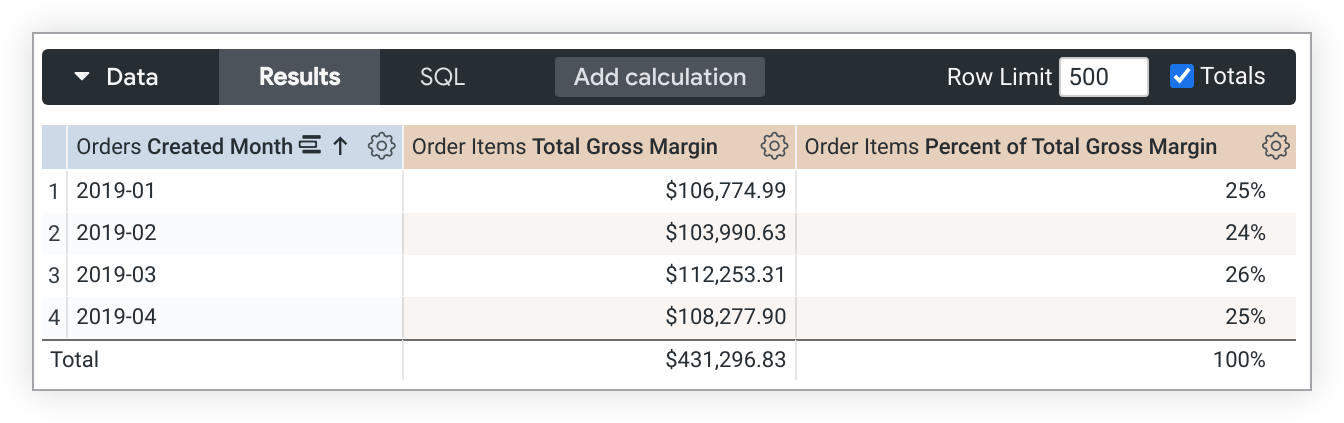
Nei casi in cui una query viene ruotata, percent_of_total viene eseguito sulla riga anziché sulla colonna. Se non è quello che vuoi, aggiungi direction: "column" alla definizione della metrica.
Inoltre, le misure percent_of_total vengono calcolate dopo la restituzione dei dati dal database. Ciò significa che non devi fare riferimento a una misura percent_of_total all'interno di un'altra misura, poiché potrebbero essere calcolate in momenti diversi e potresti non ottenere risultati accurati. Significa anche che le misure percent_of_total non possono essere filtrate.
percentile
type: percentile restituisce il valore al percentile specificato dei valori in un determinato campo. Ad esempio, se specifichi il 75° percentile, verrà restituito il valore maggiore del 75% degli altri valori nel set di dati.
Per identificare il valore da restituire, Looker calcola il numero totale di valori dei dati e moltiplica il percentile specificato per il numero totale di valori dei dati. Indipendentemente da come vengono ordinati i dati, Looker identifica l'ordine relativo dei valori dei dati in ordine crescente. Il valore dei dati restituito da Looker dipende dal fatto che il calcolo produca o meno un numero intero, come descritto nelle due sezioni seguenti.
Se il valore calcolato non è un numero intero
Looker arrotonda per eccesso il valore calcolato e lo utilizza per identificare il valore dei dati da restituire. In questo insieme di 19 punteggi dei test, il 75° percentile sarebbe identificato da 19 * 0,75 = 14,25, il che significa che il 75% dei valori si trova nei primi 14 valori di dati, al di sotto della 15ª posizione. Pertanto, Looker restituisce il quindicesimo valore dei dati (87) come maggiore del 75% dei valori dei dati.

Se il valore calcolato è un numero intero
In questo caso leggermente più complesso, Looker restituisce una media del valore dei dati in quella posizione e del valore dei dati successivo. Per capire questo concetto, considera un insieme di 20 punteggi del test: il 75° percentile verrebbe identificato da 20 * 0, 75 = 15, il che significa che il valore dei dati nella 15ª posizione fa parte del 75° percentile e dobbiamo restituire un valore superiore al 75% dei valori dei dati. Restituendo la media dei valori nella 15ª posizione (82) e nella 16ª posizione (87), Looker garantisce che il 75%. Questa media (84,5) non esiste nel set di valori dei dati, ma sarebbe maggiore del 75% dei valori dei dati.

Parametri obbligatori e facoltativi
Utilizza la parola chiave percentile: per specificare il valore frazionario, ovvero la percentuale di dati che deve essere inferiore al valore restituito. Ad esempio, utilizza percentile: 75 per specificare il valore al 75° percentile nell'ordine dei dati oppure percentile: 10 per restituire il valore al 10° percentile. Se vuoi trovare il valore al 50° percentile, puoi specificare percentile: 50 o utilizzare il tipo mediana.
Il parametro sql per le misure type: percentile può accettare qualsiasi espressione SQL valida che restituisca una colonna della tabella numerica, una dimensione LookML o una combinazione di dimensioni LookML.
I campi type: percentile possono essere formattati utilizzando i parametri value_format o value_format_name.
Esempio
Ad esempio, il seguente codice LookML crea un campo denominato test_scores_75th_percentile che restituisce il valore al 75° percentile nella dimensione test_scores:
measure: test_scores_75th_percentile {
type: percentile
percentile: 75
sql: ${TABLE}.test_scores ;;
}
Aspetti da considerare per percentile
Se utilizzi percentile per un campo coinvolto in una distribuzione, Looker tenterà di utilizzare percentile_distinct. Se percentile_distinct non è disponibile per il dialetto, Looker restituisce un errore. Per saperne di più, consulta i dialetti supportati per percentile_distinct.
Dialetti del database supportati per percentile
Affinché Looker supporti il tipo percentile nel tuo progetto Looker, deve supportarlo anche il dialetto del database. La tabella seguente mostra quali dialetti supportano il tipo percentile nell'ultima release di Looker:
| Dialetto | Supportata? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
percentile_distinct
type: percentile_distinct è una forma specializzata di percentile e deve essere utilizzato quando il join comporta un fanout. Utilizza i valori non ripetuti in un determinato campo, in base ai valori univoci definiti dal parametro sql_distinct_key. Se la misura non ha un parametro sql_distinct_key, Looker tenta di utilizzare il campo primary_key.
Considera il risultato di una query che unisce le tabelle Elemento ordine e Ordine:
| ID articolo ordine | ID ordine | Spedizione dell'ordine |
|---|---|---|
| 1 | 1 | 10 |
| 2 | 1 | 10 |
| 3 | 2 | 20 |
| 4 | 3 | 50 |
| 5 | 3 | 50 |
| 6 | 3 | 50 |
| 7 | 4 | 70 |
| 8 | 4 | 70 |
| 9 | 5 | 110 |
| 10 | 5 | 110 |
In questa situazione puoi notare che ci sono più righe per ogni ordine. Questa query ha comportato un fanout perché ogni ordine viene mappato a più articoli dell'ordine. percentile_distinct tiene conto di questo e trova il valore percentile utilizzando i valori distinti 10, 20, 50, 70 e 110. Il 25° percentile restituirà il secondo valore distinto, ovvero 20, mentre l'80° percentile restituirà la media del quarto e del quinto valore distinto, ovvero 90.
Parametri obbligatori e facoltativi
Utilizza la parola chiave percentile: per specificare il valore frazionario. Ad esempio, utilizza percentile: 75 per specificare il valore al 75° percentile nell'ordine dei dati oppure percentile: 10 per restituire il valore al 10° percentile. Se stai cercando il valore al 50° percentile, puoi utilizzare il tipo median_distinct.
Per ottenere un risultato accurato, specifica in che modo Looker deve identificare ogni entità univoca (in questo caso, ogni ordine univoco) utilizzando il parametro sql_distinct_key.
Ecco un esempio di utilizzo di percentile_distinct per restituire il valore al 90° percentile:
measure: order_shipping_90th_percentile {
type: percentile_distinct
percentile: 90
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Ogni valore univoco di sql_distinct_key deve avere un solo valore corrispondente nel parametro sql della metrica. In altre parole, l'esempio precedente funziona perché ogni riga con order_id pari a 1 ha lo stesso order_shipping pari a 10 e ogni riga con order_id pari a 2 ha lo stesso order_shipping pari a 20.
I campi type: percentile_distinct possono essere formattati utilizzando i parametri value_format o value_format_name.
Aspetti da considerare per percentile_distinct
Se percentile_distinct non è disponibile per il dialetto, Looker restituisce un errore. Per saperne di più, consulta i dialetti supportati per percentile_distinct.
Dialetti del database supportati per percentile_distinct
Affinché Looker supporti il tipo percentile_distinct nel tuo progetto Looker, deve supportarlo anche il dialetto del database. La tabella seguente mostra quali dialetti supportano il tipo percentile_distinct nell'ultima release di Looker:
| Dialetto | Supportata? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |
period_over_period
Per i dialetti che supportano le misure periodo per periodo, puoi creare una misura LookML di type: period_over_period per creare una misura periodo per periodo (PoP). Una misura PoP fa riferimento a un'aggregazione di un periodo di tempo precedente.
Ecco un esempio di misura PoP che fornisce il conteggio degli ordini del mese precedente:
measure: orders_last_month {
type: period_over_period
based_on: orders.count
based_on_time: orders.created_month
period: month
kind: previous
}
Le misure con type: period_over_period devono avere anche i seguenti sottoparametri:
Per ulteriori informazioni ed esempi, consulta Misure periodo per periodo in Looker.
running_total
type: running_total calcola una somma cumulativa delle celle lungo una colonna. Non può essere utilizzato per calcolare le somme lungo una riga, a meno che la riga non sia il risultato di una tabella pivot.
Il parametro sql per le misure type: running_total deve fare riferimento a un'altra misura numerica.
I campi type: running_total possono essere formattati utilizzando i parametri value_format o value_format_name.
Il seguente esempio di LookML crea una misura cumulative_total_revenue basata sulla misura total_sale_price:
measure: cumulative_total_revenue {
type: running_total
sql: ${total_sale_price} ;;
value_format_name: usd
}
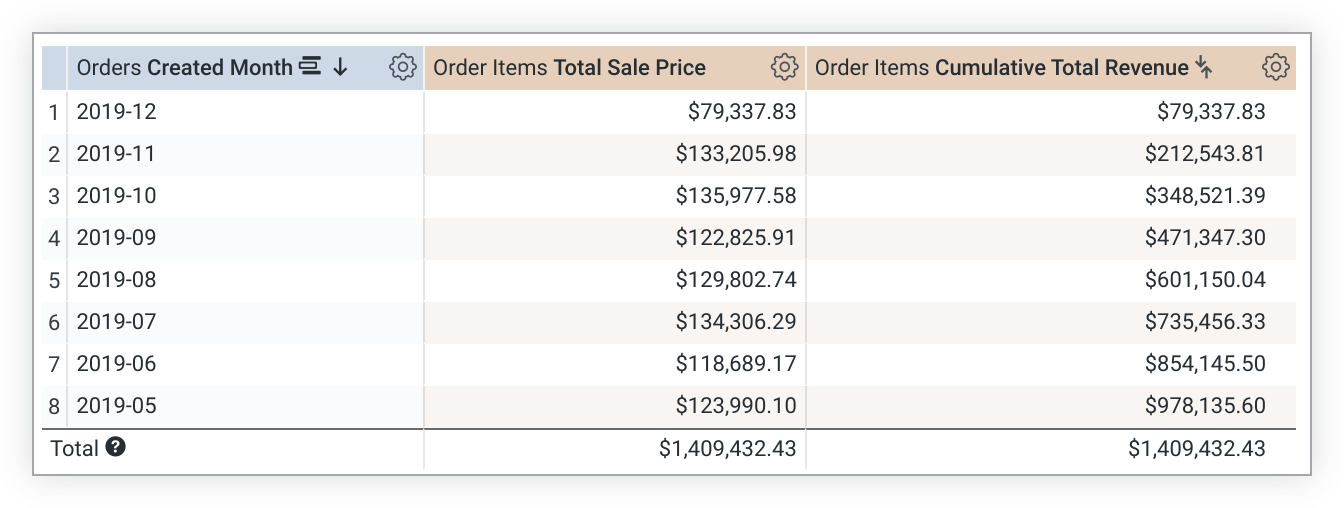
Tieni presente che i valori di running_total dipendono dall'ordine di ordinamento. Se modifichi l'ordinamento, devi eseguire di nuovo la query per ricalcolare i valori running_total. Nei casi in cui una query viene ruotata, running_total viene eseguito sulla riga anziché sulla colonna. Se non è quello che vuoi, aggiungi direction: "column" alla definizione della metrica.
Inoltre, le misure running_total vengono calcolate dopo la restituzione dei dati dal database. Ciò significa che non devi fare riferimento a una misura running_total all'interno di un'altra misura, poiché potrebbero essere calcolate in momenti diversi e potresti non ottenere risultati accurati. Significa anche che le misure running_total non possono essere filtrate.
string
type: string viene utilizzato con i campi che contengono lettere o caratteri speciali.
Il parametro sql per le misure type: string può accettare qualsiasi espressione SQL valida che restituisce una stringa. In pratica, questo tipo viene utilizzato raramente, perché la maggior parte delle funzioni di aggregazione SQL non restituisce stringhe. Un'eccezione comune è la funzione GROUP_CONCAT di MySQL, anche se Looker fornisce type: list per questo caso d'uso.
Ad esempio, il seguente codice LookML crea un campo category_list combinando i valori unici di un campo denominato category:
measure: category_list {
type: string
sql: GROUP_CONCAT(${category}) ;;
}
In questo esempio, type: string potrebbe essere omesso, perché string è il valore predefinito per type.
sum
type: sum somma i valori in un determinato campo. È simile alla funzione SUM di SQL. Tuttavia, a differenza di SQL non elaborato, Looker calcolerà correttamente le somme anche se i join della query contengono fanout.
Il parametro sql per le misure type: sum può accettare qualsiasi espressione SQL valida che restituisca una colonna della tabella numerica, una dimensione LookML o una combinazione di dimensioni LookML.
I campi type: sum possono essere formattati utilizzando i parametri value_format o value_format_name.
Ad esempio, il seguente codice LookML crea un campo denominato total_revenue sommando la dimensione sales_price, quindi lo visualizza in un formato monetario (1234,56 $):
measure: total_revenue {
type: sum
sql: ${sales_price} ;;
value_format_name: usd
}
sum_distinct
type: sum_distinct è da utilizzare con set di dati denormalizzati. Somma i valori non ripetuti in un determinato campo, in base ai valori univoci definiti dal parametro sql_distinct_key.
Si tratta di un concetto avanzato che può essere spiegato più chiaramente con un esempio. Prendi in considerazione una tabella denormalizzata come questa:
| ID articolo ordine | ID ordine | Spedizione dell'ordine |
|---|---|---|
| 1 | 1 | 10,00 |
| 2 | 1 | 10,00 |
| 3 | 2 | 20,00 |
| 4 | 2 | 20,00 |
| 5 | 2 | 20,00 |
In questa situazione, puoi notare che ci sono più righe per ogni ordine. Di conseguenza, se hai aggiunto una misura type: sum per la colonna order_shipping, otterrai un totale di 80,00, anche se la spedizione totale raccolta è in realtà pari a 30,00.
# Will NOT calculate the correct shipping amount
measure: total_shipping {
type: sum
sql: ${order_shipping} ;;
}
Per ottenere un risultato accurato, puoi definire per Looker come identificare ogni entità univoca (in questo caso, ogni ordine univoco) utilizzando il parametro sql_distinct_key. In questo modo verrà calcolato l'importo corretto di 30,00:
# Will calculate the correct shipping amount
measure: total_shipping {
type: sum_distinct
sql_distinct_key: ${order_id} ;;
sql: ${order_shipping} ;;
}
Ogni valore univoco di sql_distinct_key deve avere un solo valore corrispondente in sql. In altre parole, l'esempio precedente funziona perché ogni riga con un order_id di 1 ha lo stesso order_shipping di 10,00 e ogni riga con un order_id di 2 ha lo stesso order_shipping di 20,00.
I campi type: sum_distinct possono essere formattati utilizzando i parametri value_format o value_format_name.
yesno
type: yesno crea un campo che indica se un valore è true o false. I valori vengono visualizzati come Sì e No nell'interfaccia utente di Esplora.
Il parametro sql per una misura type: yesno accetta un'espressione SQL valida che restituisce TRUE o FALSE. Se la condizione restituisce TRUE, all'utente viene visualizzato Yes; in caso contrario, viene visualizzato No.
L'espressione SQL per le misure type: yesno deve includere solo aggregazioni, ovvero aggregazioni SQL o riferimenti a misure LookML. Se vuoi creare un campo yesno che includa un riferimento a una dimensione LookML o a un'espressione SQL che non sia un'aggregazione, utilizza una dimensione con type: yesno, non una misura.
Analogamente alle misure con type: number, una misura con type: yesno non esegue aggregazioni, ma fa riferimento ad altre aggregazioni.
Ad esempio, la seguente misura total_sale_price è una somma del prezzo di vendita totale degli articoli di un ordine. Una seconda misura chiamata is_large_total è type: yesno. La misura is_large_total ha un parametro sql che valuta se il valore total_sale_price è superiore a 1000 $.
measure: total_sale_price {
type: sum
value_format_name: usd
sql: ${sale_price} ;;
drill_fields: [detail*]
}
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
Se vuoi fare riferimento a un campo type: yesno in un altro campo, devi trattare il campo type: yesno come un valore booleano (ovvero come se contenesse già un valore true o false). Ad esempio:
measure: is_large_total {
description: "Is order total over $1000?"
type: yesno
sql: ${total_sale_price} > 1000 ;;
}
# This is correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} THEN 200 ELSE 100 END ;;
}
# This is NOT correct:
measure: reward_points {
type: number
sql: CASE WHEN ${is_large_total} = 'Yes' THEN 200 ELSE 100 END ;;
}