
用途
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
階層
aggregate_table |
デフォルト値
なし
許可 サマリー表の名前、テーブルを定義する query サブパラメータ、テーブルの永続性戦略を定義する materialization サブパラメータ
特別なルール
|
定義
aggregate_table パラメータは、データベース内の大きなテーブルに必要なクエリの数を最小限に抑える集計テーブルを作成するために使用されます。
Looker は、集約認識ロジックを使用して、データベース内で最も小規模の効率的なサマリー表を検出し、正確性を維持しながらクエリを実行します。(集約テーブルの概要と作成戦略については、集約テーブルの自動認識のドキュメント ページをご覧ください)。
データベース内の非常に大きなテーブルに対して、さまざまな属性の組み合わせによってグループ化されたデータのより小さな集約テーブルを作成できます。集約テーブルは、元の大きなテーブルの代わりに、Looker が可能であれば常にクエリに使用できるロールアップまたはサマリー テーブルとして機能します。
集約テーブルを作成したら、Explore でクエリを実行して、Looker がどの集約テーブルを使用するかを確認できます。詳細については、集約テーブルの自動認識のドキュメント ページのクエリに使用されるサマリー表を決定するのセクションをご覧ください。
集計テーブルが使用されない一般的な理由については、集計テーブルの自動認識のドキュメント ページのトラブルシューティング セクションをご覧ください。
LookML でのサマリー表の定義
各 aggregate_table パラメータには、特定の explore 内で一意の名前を付ける必要があります。
aggregate_table パラメータには query と materialization のサブパラメータがあります。
query
query パラメータは、使用するディメンションとメジャーを含む、サマリー表のクエリを定義します。query パラメータには、次のサブパラメータが含まれます。
| パラメータ名 | 説明 | 例 |
|---|---|---|
dimensions |
集計テーブルに含める Explore のディメンションのカンマ区切りリスト。dimensions フィールドの形式は次のとおりです。dimensions: [dimension1, dimension2, ...]
このリストの各ディメンションは、クエリの Explore のビューファイルで dimension として定義する必要があります。Explore クエリで filter フィールドとして定義されているフィールドを含める場合は、集約テーブルのクエリの filters リストに追加できます。 |
dimensions: [orders.created_month, orders.country] |
measures |
サマリー表に含める Explore のメジャーのカンマ区切りのリスト。measures フィールドでは次の形式が使用されます。measures: [measure1, measure2, ...]
集約テーブルの自動認識でサポートされているメジャータイプについては、集約テーブルの自動認識のドキュメント ページのメジャータイプの要因のセクションをご覧ください。 |
measures: [orders.count] |
filters |
必要に応じて、query にフィルタを追加します。フィルタは、サマリー表を生成する SQL の WHERE 句に追加されます。
filters フィールドの形式は次のとおりです。filters: [field1: "value1", field2: "value2", ...]
フィルタによってサマリー表が使用されなくなる仕組みについては、集約テーブルの自動認識のドキュメント ページのフィルタの要因のセクションをご覧ください。 |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
必要に応じて、query の並べ替えフィールドと並べ替えの方向(昇順または降順)を指定します。
sorts フィールドの形式は次のとおりです。sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
query のタイムゾーンを設定します。タイムゾーンが指定されていない場合、サマリー表はタイムゾーン変換を行わず、代わりにデータベースのタイムゾーンを使用します。集約テーブルがクエリソースとして使用されるようにタイムゾーンを設定する方法については、集約テーブルの自動認識のドキュメント ページのタイムゾーンの要因のセクションをご覧ください。
IDE で timezone パラメータを入力すると、IDE がタイムゾーン値を自動提案します。IDE のクイックヘルプ パネルにも、サポートされているタイムゾーン値のリストが表示されます。 |
timezone: America/Los_Angeles |
materialization
materialization パラメータは、サマリー表の永続性戦略と、SQL 言語でサポートされている可能性のある分散、パーティショニング、インデックス、クラスタリングのその他のオプションを指定します。
集約テーブルの自動認識にアクセスするには、集約テーブルがデータベースに保持されている必要があります。集約テーブルの materialization パラメータには、永続化戦略を指定する次のいずれかのサブパラメータが必要です。
また、SQL 言語によっては、サマリー表で次の materialization サブパラメータがサポートされている場合があります。
増分サマリー表を作成するには、次の materialization サブパラメータを使用します。
datagroup_trigger
datagroup_trigger パラメータを使用して、モデルファイルで定義された既存のデータグループに基づいてサマリー表の再生成をトリガーします。
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
sql_trigger_value パラメータを使用して、指定した SQL ステートメントに基づいてサマリー表の再生成をトリガーします。SQL ステートメントの結果が前の値と異なる場合、テーブルは再生成されます。次の sql_trigger_value ステートメントは、日付が変わったときに再生成をトリガーします。
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
persist_for パラメータはサマリー表でもサポートされています。ただし、persist_for 戦略では、集約テーブルの自動認識で最高のパフォーマンスが得られない場合があります。これは、ユーザーが persist_for テーブルに依存するクエリを実行すると、Looker がテーブルの経過時間を persist_for 設定と照合するためです。テーブルが persist_for 設定よりも古い場合、クエリが実行される前にテーブルが再生成されます。経過時間が persist_for 設定よりも短い場合は、既存のテーブルが使用されます。したがって、ユーザーが persist_for 時間内にクエリを実行しない限り、サマリー表は集約テーブルの自動認識に使用する前に再構築する必要があります。
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
persist_for の実装の制限事項を理解し、特定のユースケースがある場合を除き、集計テーブルの永続化戦略として datagroup_trigger または sql_trigger_value を使用することをおすすめします。
cluster_keys
cluster_keys パラメータを使用すると、BigQuery または Snowflake のパーティション分割テーブルにクラスタ列を追加できます。クラスタリングでは、クラスタ化列の値に基づいてパーティション内のデータを並べ替え、クラスタ化列を最適なサイズのストレージ ブロックに整理します。
詳しくは、cluster_keys パラメータのドキュメント ページをご覧ください。
distribution
distribution パラメータを使用すると、分散キーを適用するサマリー表の列を指定できます。distribution は、Redshift データベースと Aster データベースでのみ機能します。他の SQL 言語(MySQL や Postgres など)では、代わりに indexes を使用します。
詳しくは、distribution パラメータのドキュメント ページをご覧ください。
distribution_style
distribution_style パラメータを使用すると、サマリー表のクエリを Redshift データベースのノードに分散する方法を指定できます。
distribution_style: allは、すべての行が各ノードに完全にコピーされることを示します。distribution_style: evenは均等な分散を指定するため、行はラウンドロビン方式で異なるノードに分散されます。
詳しくは、distribution_style パラメータのドキュメント ページをご覧ください。
indexes
indexes パラメータを使用すると、サマリー表の列にインデックスを適用できます。
詳しくは、indexes パラメータのドキュメント ページをご覧ください。
partition_keys
partition_keys パラメータは、サマリー表のパーティショニングに使用する列の配列を定義します。partition_keys は、列をパーティショニングできるデータベース言語をサポートしています。パーティショニングされた列でフィルタリングされたクエリが実行されると、データベースはテーブル全体をスキャンするのではなく、フィルタリングされたデータを含むパーティションのみをスキャンします。partition_keys は、Presto と BigQuery の言語でのみサポートされています。
詳しくは、partition_keys パラメータのドキュメント ページをご覧ください。
publish_as_db_view
publish_as_db_view パラメータを使用すると、Looker の外部でクエリを実行するサマリー表にフラグを設定できます。publish_as_db_view が yes に設定されているサマリー表の場合、Looker はサマリー表の安定したデータベース ビューをデータベースに作成します。安定したデータベース ビューはデータベース自体に作成されるため、Looker の外部でクエリを実行できます。
詳しくは、publish_as_db_view パラメータのドキュメント ページをご覧ください。
sortkeys
sortkeys パラメータを使用すると、通常の並べ替えキーを適用するサマリー表の 1 つ以上の列を指定できます。
詳しくは、sortkeys パラメータのドキュメント ページをご覧ください。
increment_key
言語がサポートしている場合は、プロジェクトで増分 PDT を作成できます。増分 PDT は、テーブル全体を再構築するのではなく、Looker がテーブルに新しいデータを追加して構築する永続的な派生テーブル(PDT)です。詳しくは、増分 PDT のドキュメント ページをご覧ください。
集約テーブルは PDT の一種であり、increment_key パラメータを追加することで段階的に構築できます。increment_key パラメータは、新しいデータをクエリしてサマリー表に追加する時間増分を指定します。
詳しくは、increment_key パラメータのドキュメント ページをご覧ください。
increment_offset
increment_offset パラメータは、集計テーブルにデータを追加するときに再構築される、以前の期間(インクリメント キーの粒度)の数を定義します。increment_offset パラメータは、増分 PDT と集約テーブルでは省略可能です。
詳しくは、increment_offset パラメータのドキュメント ページをご覧ください。
Explore からサマリー表 LookML を取得する
ショートカットとして、Looker デベロッパーは Explore クエリを使用してサマリー表を作成し、LookML を LookML プロジェクトにコピーできます。
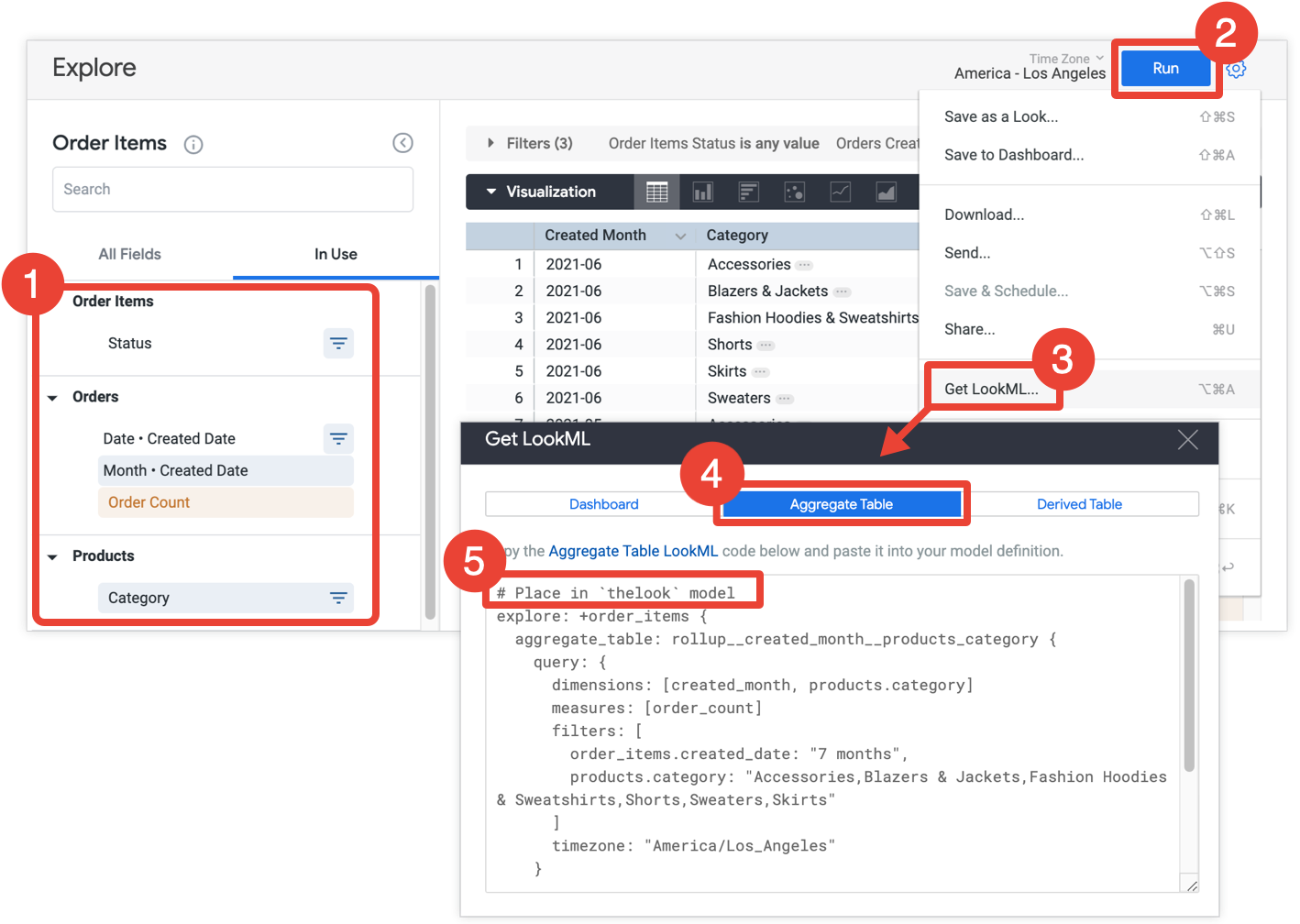
- Explore で、サマリー表に含めるすべてのフィールドとフィルタを選択します。
- [実行] をクリックして結果を取得します。
- Explore の歯車メニューから [LookML を取得] を選択します。このオプションは Looker デベロッパーのみが使用できます。
- [集計テーブル] タブをクリックします。
- Looker は、サマリー表を Explore に追加する Explore の絞り込みの LookML を提供します。LookML をコピーして、関連するモデルファイルに貼り付けます。関連するモデルファイルは、Explore の絞り込みの前のコメントに示されています。Explore がモデルファイルではなく、別の Explore ファイルで定義されている場合は、モデルファイルではなく Explore のファイルに絞り込みを追加できます。どちらの場所でも機能します。
集計テーブルの LookML を変更する必要がある場合は、このページの LookML で集計テーブルを定義するセクションで説明されているパラメータを使用します。サマリー表の名前を変更しても、元の Explore クエリへの適用性は変わりません。ただし、集約テーブルに対するその他の変更は、Looker が Explore クエリにサマリー表を使用する機能に影響する可能性があります。集約テーブルの自動認識で使用されるように集約テーブルを最適化するためのヒントについては、集約テーブルの自動認識のドキュメント ページの集約テーブルの設計をご覧ください。
ダッシュボードからの集計テーブルLookMLの取得
Looker デベロッパー向けの別のオプションとして、ダッシュボードのすべてのタイルのサマリー表 LookML を取得し、LookML を LookML プロジェクトにコピーする方法があります。
集約テーブルを作成すると、特に大規模なデータセットに対してクエリを実行するタイルの場合、ダッシュボードのパフォーマンスを大幅に向上させることができます。
develop 権限がある場合は、ダッシュボードを開き、ダッシュボードのその他メニューから [LookML を取得] を選択して、[集計テーブル] タブを選択すると、ダッシュボードの集計テーブルを作成するための LookML を取得できます。
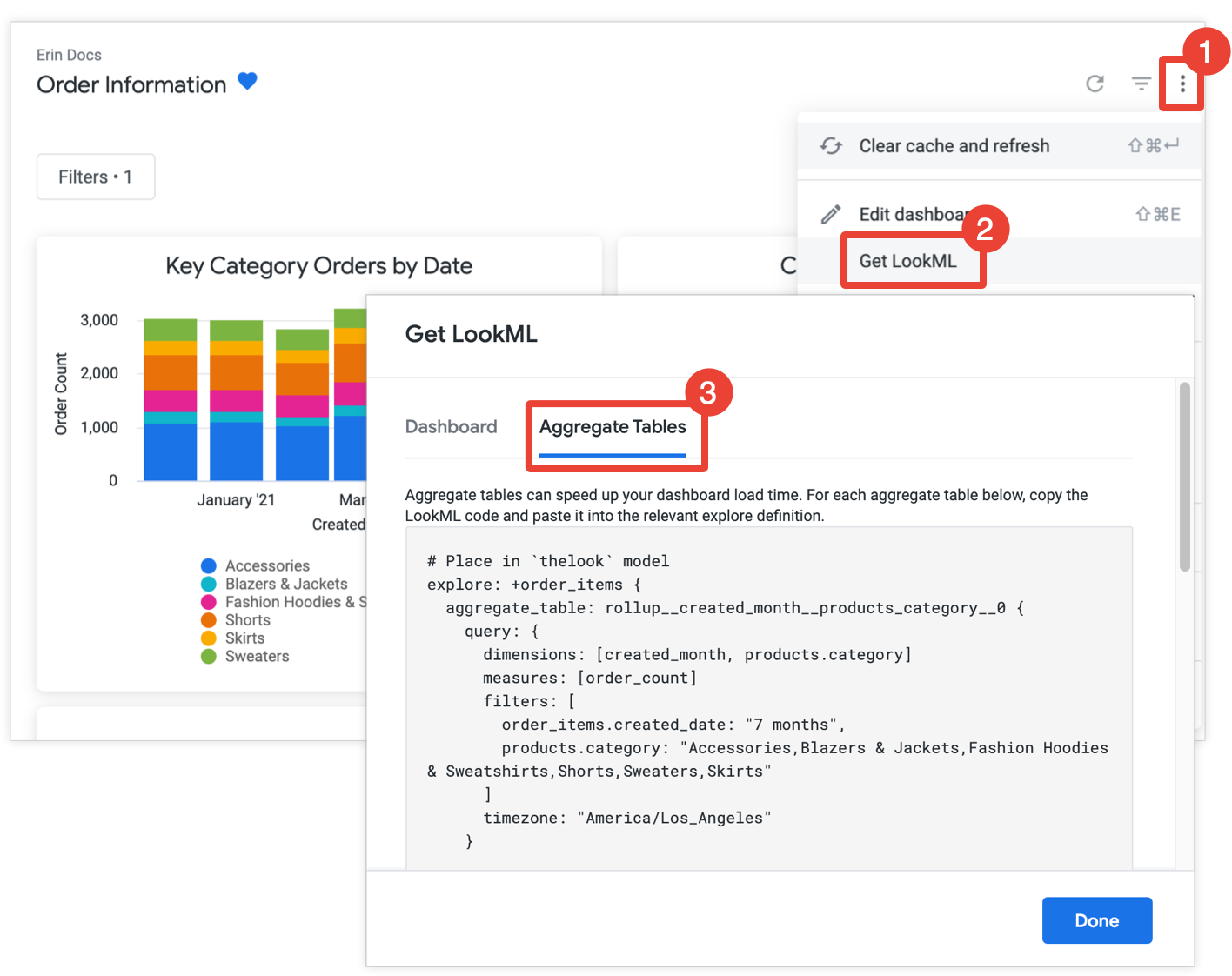
集計認識で最適化されていないタイルごとに、Looker は、サマリー表を Explore に追加する Explore の絞り込みの LookML を提供します。ダッシュボードに同じ Explore の複数のタイルが含まれている場合、Looker はすべての集計テーブルを 1 つの Explore の絞り込みに配置します。生成されるサマリー表の数を減らすため、Looker は生成されたサマリー表を複数のタイルで使用できるかどうかを判断し、使用できるタイルが少ない冗長なサマリー表を削除します。
各 Explore の絞り込みを、関連するモデルファイル(Explore の絞り込みの前のコメントで示されています)にコピーして貼り付けます。Explore がモデルファイルではなく別の Explore ファイルで定義されている場合は、モデルファイルではなく Explore ファイルに絞り込みを追加できます。どちらの場所でも構いません。
ダッシュボード フィルタがタイルに適用されると、Looker はフィルタのディメンションをタイルのサマリー表に追加し、サマリー表をタイルで使用できるようにします。これは、クエリのフィルタがサマリー表のディメンションとして使用できるフィールドを参照している場合にのみ、サマリー表をクエリに使用できるためです。詳細については、集約テーブルの自動認識のドキュメント ページをご覧ください。
集計テーブルの LookML を変更する必要がある場合は、このページの LookML で集計テーブルを定義するセクションで説明されているパラメータを使用します。サマリー表の名前は、元のダッシュボード タイルへの適用性を変更することなく変更できますが、サマリー表に対する他の変更は、Looker がダッシュボードにサマリー表を使用する機能に影響する可能性があります。集約テーブルの自動認識で使用されるように集約テーブルを最適化するためのヒントについては、集約テーブルの自動認識のドキュメント ページの集約テーブルの設計をご覧ください。
例
次の例では、event Explore の monthly_orders サマリー表を作成します。サマリー表は、注文数の月次カウントを作成します。Looker は、年次、四半期、月次の注文数などの月単位の粒度を利用できる注文数クエリに、このサマリー表を使用します。
サマリー表は、データグループ orders_datagroup を使用して永続化するように設定されています。また、サマリー表は publish_as_db_view: yes で定義されています。これは、Looker がサマリー表の安定したデータベース ビューをデータベースに作成することを意味します。
サマリー表の定義は次のようになります。
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
注意点
集約テーブルを戦略的に作成するためのヒントについては、集約テーブルの自動認識のドキュメント ページの集約テーブルの設計セクションをご覧ください。
集計テーブルの自動認識向けの言語サポート
集計認識を使用できるかどうかは、Looker 接続で使用されているデータベース言語によって異なります。Looker の最新リリースでは、次の言語が集約テーブルの自動認識をサポートしています。
| 方言 | サポート対象 |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |