
Utilizzo
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
Gerarchia
aggregate_table |
Valore predefinito
Nessuno
Accetta
Un nome per la tabella aggregata, il sottoparametro query per definire la tabella e il sottoparametro materialization per definire la strategia di persistenza della tabella
Regole speciali
|
Definizione
Il parametro aggregate_table viene utilizzato per creare tabelle aggregate che riducono al minimo il numero di query necessarie per le tabelle di grandi dimensioni nel database.
Looker utilizza la logica di consapevolezza delle tabelle aggregate per trovare la tabella aggregata più piccola ed efficiente disponibile nel tuo database per eseguire una query mantenendo comunque la correttezza. Per una panoramica e strategie per la creazione di tabelle aggregate, consulta la pagina di documentazione Consapevolezza delle tabelle aggregate.
Per le tabelle molto grandi nel database, puoi creare tabelle aggregate più piccole di dati, raggruppati in base a varie combinazioni di attributi. Le tabelle aggregate fungono da tabelle di riepilogo che Looker può utilizzare per le query, se possibile, anziché la tabella di grandi dimensioni originale.
Una volta create le tabelle aggregate, puoi eseguire query nell'esplorazione per vedere quali tabelle aggregate utilizza Looker. Per ulteriori informazioni, consulta la sezione Determinare quale tabella aggregata viene utilizzata per una query nella pagina della documentazione Riconoscimento degli aggregati.
Per i motivi più comuni per cui le tabelle aggregate non vengono utilizzate, consulta la sezione Risoluzione dei problemi nella pagina della documentazione Riconoscimento degli aggregati.
Definizione di una tabella aggregata in LookML
Ogni parametro aggregate_table deve avere un nome univoco all'interno di un determinato explore.
Il parametro aggregate_table ha i sottoparametri query e materialization.
query
Il parametro query definisce la query per la tabella aggregata, incluse le dimensioni e le misure da utilizzare. Il parametro query include i seguenti parametri secondari:
| Nome parametro | Descrizione | Esempio |
|---|---|---|
dimensions |
Un elenco separato da virgole delle dimensioni dell'esplorazione da includere nella tabella aggregata. Il campo dimensions utilizza questo formato: dimensions: [dimension1, dimension2, ...]
Ogni dimensione di questo elenco deve essere definita come dimension nel file di vista per l'esplorazione della query. Se vuoi includere un campo definito come campo filter nella query di Esplora, puoi aggiungerlo all'elenco filters nella query della tabella aggregata.
|
dimensions: [orders.created_month, orders.country] |
measures |
Un elenco separato da virgole delle misure dell'esplorazione da includere nella tabella aggregata. Il campo measures utilizza questo formato: measures: [measure1, measure2, ...]
Per informazioni sui tipi di metrica supportati per la consapevolezza aggregata, consulta la sezione Fattori del tipo di metrica nella pagina di documentazione Consapevolezza aggregata.
|
measures: [orders.count] |
filters |
(Facoltativo) Aggiunge un filtro a un query. I filtri vengono aggiunti alla clausola WHERE dell'SQL che genera la tabella aggregata.
Il campo filters utilizza questo formato: filters: [field1: "value1", field2: "value2", ...]
Per informazioni su come i filtri possono impedire l'utilizzo della tabella aggregata, consulta la sezione Fattori di filtro nella pagina di documentazione Rilevamento dell'aggregazione. |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
(Facoltativo) Specifica i campi di ordinamento e la direzione di ordinamento (crescente o decrescente) per query.
Il campo sorts utilizza questo formato: sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
Imposta il fuso orario per query. Se non viene specificato un fuso orario, la tabella aggregata non esegue alcuna conversione del fuso orario e utilizza invece il fuso orario del database.
Per informazioni sull'impostazione del fuso orario in modo che la tabella aggregata venga utilizzata come origine query, consulta la sezione Fattori del fuso orario nella pagina della documentazione Riconoscimento degli aggregati.
L'IDE suggerisce automaticamente il valore del fuso orario quando digiti il parametro timezone nell'IDE. L'IDE mostra anche l'elenco dei valori dei fusi orari supportati nel riquadro Guida rapida. |
timezone: America/Los_Angeles |
materialization
Il parametro materialization specifica la strategia di persistenza per la tabella aggregata, nonché altre opzioni per la distribuzione, il partizionamento, gli indici e il clustering che potrebbero essere supportati dal dialetto SQL.
Per essere accessibile per la consapevolezza aggregata, la tabella aggregata deve essere persistente nel database. Il parametro materialization della tabella aggregata deve avere uno dei seguenti parametri secondari per specificare la strategia di persistenza:
datagroup_triggersql_trigger_valuepersist_for(non consigliato)
Inoltre, a seconda del dialetto SQL, potrebbero essere supportati i seguenti parametri secondari materialization per la tabella aggregata:
Per creare una tabella aggregata incrementale, utilizza i seguenti parametri secondari materialization:
datagroup_trigger
Utilizza il parametro datagroup_trigger per attivare la rigenerazione della tabella aggregata in base a un datagroup esistente definito nel file del modello:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
Utilizza il parametro sql_trigger_value per attivare la rigenerazione della tabella aggregata in base a un'istruzione SQL che fornisci. Se il risultato dell'istruzione SQL è diverso dal valore precedente, la tabella viene rigenerata. Questa istruzione sql_trigger_value attiverà la rigenerazione quando la data cambia:
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
Il parametro persist_for è supportato anche per le tabelle aggregate. Tuttavia, la strategia persist_for potrebbe non offrirti il rendimento migliore per l'awareness aggregata. Questo perché quando un utente esegue una query che si basa su una tabella persist_for, Looker controlla l'età della tabella rispetto all'impostazione persist_for. Se la tabella è precedente all'impostazione persist_for, viene rigenerata prima dell'esecuzione della query. Se l'età è inferiore all'impostazione persist_for, viene utilizzata la tabella esistente. Pertanto, a meno che un utente non esegua una query entro il periodo di tempo persist_for, la tabella aggregata deve essere ricreata prima di poter essere utilizzata per la consapevolezza aggregata.
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
A meno che tu non comprenda le limitazioni e non abbia un caso d'uso specifico per l'implementazione di persist_for, è meglio utilizzare datagroup_trigger o sql_trigger_value come strategia di persistenza per le tabelle aggregate.
cluster_keys
Il parametro cluster_keys ti consente di aggiungere una colonna in cluster alle tabelle partizionate su BigQuery o Snowflake. Il clustering ordina i dati in una partizione in base ai valori delle colonne in cluster e organizza le colonne in cluster in blocchi di archiviazione di dimensioni ottimali.
Per saperne di più, consulta la pagina della documentazione del parametro cluster_keys.
distribution
Il parametro distribution consente di specificare la colonna di una tabella aggregata a cui applicare una chiave di distribuzione. distribution funziona solo con i database Redshift e Aster. Per altri dialetti SQL (come MySQL e Postgres), utilizza invece indexes.
Per saperne di più, consulta la pagina della documentazione del parametro distribution.
distribution_style
Il parametro distribution_style ti consente di specificare come viene distribuita la query per una tabella aggregata tra i nodi di un database Redshift:
distribution_style: allindica che tutte le righe vengono copiate completamente in ogni nodo.distribution_style: evenspecifica una distribuzione uniforme, in modo che le righe vengano distribuite a nodi diversi in modo round robin.
Per saperne di più, consulta la pagina della documentazione del parametro distribution_style.
indexes
Il parametro indexes consente di applicare indici alle colonne di una tabella aggregata.
Per saperne di più, consulta la pagina della documentazione del parametro indexes.
partition_keys
Il parametro partition_keys definisce un array di colonne in base alle quali verrà partizionata la tabella aggregata. partition_keys supporta i dialetti del database che hanno la possibilità di partizionare le colonne. Quando viene eseguita una query filtrata in base a una colonna partizionata, il database analizza solo le partizioni che includono i dati filtrati, anziché l'intera tabella. partition_keys è supportato solo con i dialetti Presto e BigQuery.
Per saperne di più, consulta la pagina della documentazione del parametro partition_keys.
publish_as_db_view
Il parametro publish_as_db_view consente di contrassegnare una tabella aggregata per l'esecuzione di query al di fuori di Looker. Per le tabelle aggregate con publish_as_db_view impostato su yes, Looker crea una visualizzazione stabile del database per la tabella aggregata. La visualizzazione stabile del database viene creata sul database stesso, in modo che possa essere sottoposta a query al di fuori di Looker.
Per saperne di più, consulta la pagina della documentazione del parametro publish_as_db_view.
sortkeys
Il parametro sortkeys consente di specificare una o più colonne di una tabella aggregata a cui applicare una chiave di ordinamento regolare.
Per saperne di più, consulta la pagina della documentazione del parametro sortkeys.
increment_key
Puoi creare PDT incrementali nel tuo progetto se il tuo dialetto li supporta. Una PDT incrementale è una tabella derivata persistente (PDT) che Looker crea aggiungendo nuovi dati alla tabella, anziché ricostruirla interamente. Per ulteriori informazioni, consulta la pagina della documentazione relativa ai PDT incrementali.
Le tabelle aggregate sono un tipo di PDT e possono essere create in modo incrementale aggiungendo il parametro increment_key. Il parametro increment_key specifica l'incremento di tempo per cui devono essere eseguiti query sui dati aggiornati e aggiunti alla tabella aggregata.
Per saperne di più, consulta la pagina della documentazione del parametro increment_key.
increment_offset
Il parametro increment_offset definisce il numero di periodi di tempo precedenti (con la granularità della chiave di incremento) che verranno ricreati quando i dati vengono aggiunti alla tabella aggregata. Il parametro increment_offset è facoltativo per le PDT incrementali e le tabelle aggregate.
Per saperne di più, consulta la pagina della documentazione del parametro increment_offset.
Recupero del codice LookML della tabella aggregata da un'esplorazione
Come scorciatoia, gli sviluppatori Looker possono utilizzare una query di esplorazione per creare una tabella aggregata e poi copiare il codice LookML nel progetto LookML:
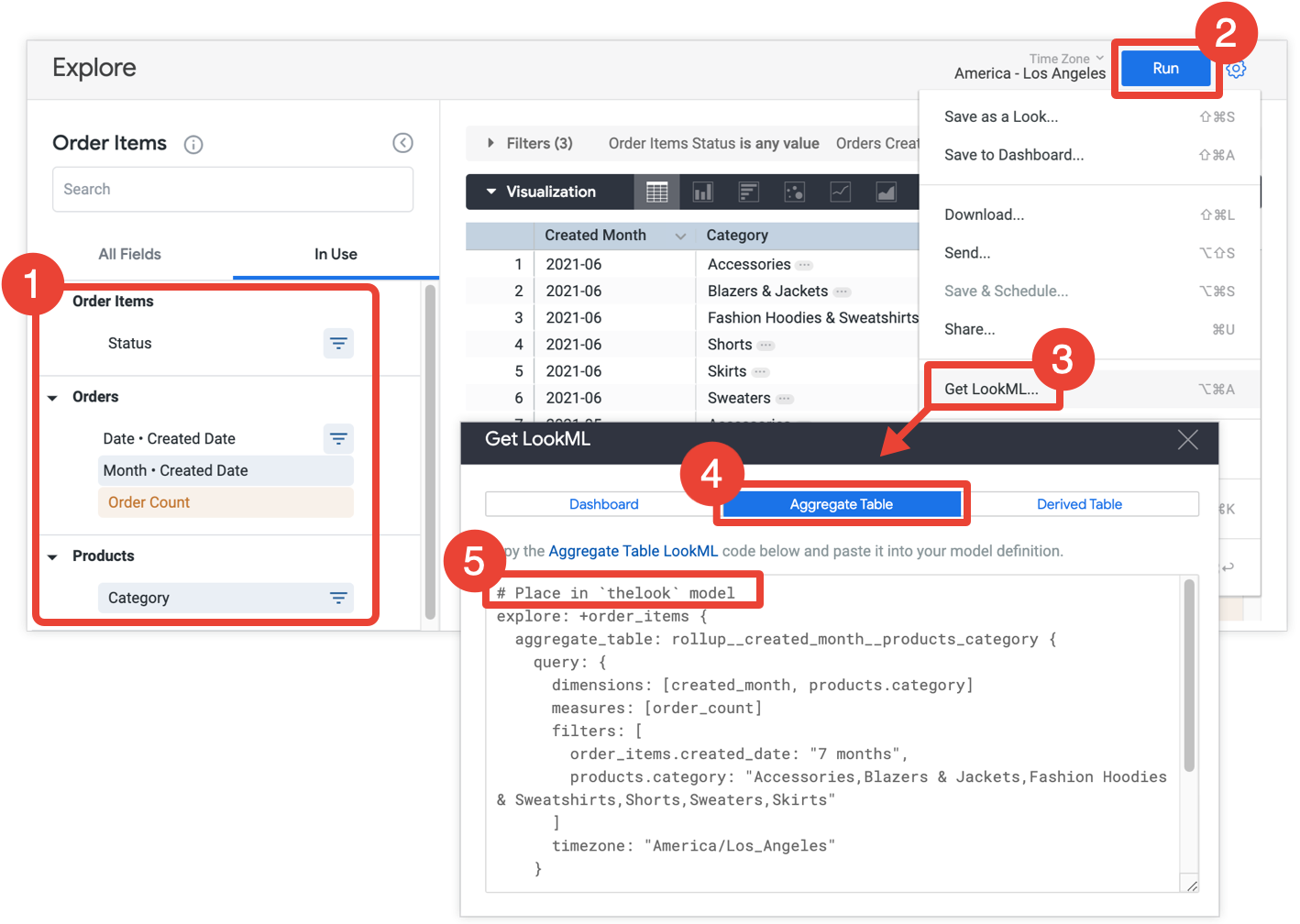
- In Esplora, seleziona tutti i campi e i filtri da includere nella tabella aggregata.
- Fai clic su Esegui per ottenere i risultati.
- Seleziona Ottieni LookML dal menu a forma di ingranaggio dell'esplorazione. Questa opzione è disponibile solo per gli sviluppatori di Looker.
- Fai clic sulla scheda Tabella aggregata.
- Looker fornisce il codice LookML per un perfezionamento di un'esplorazione che aggiungerà la tabella aggregata all'esplorazione. Copia il codice LookML e incollalo nel file del modello associato, indicato nel commento che precede il perfezionamento dell'esplorazione. Se l'esplorazione è definita in un file Explore separato e non in un file del modello, puoi aggiungere il perfezionamento al file Explore anziché al file del modello. Entrambe le posizioni funzionano.
Se devi modificare il codice LookML della tabella aggregata, puoi farlo con i parametri descritti nella sezione Definizione di una tabella aggregata in LookML di questa pagina. Puoi rinominare la tabella aggregata senza modificarne l'applicabilità alla query di esplorazione originale. Tuttavia, qualsiasi altra modifica alla tabella aggregata potrebbe influire sulla capacità di Looker di utilizzare la tabella aggregata per la query di esplorazione. Consulta la sezione Progettazione di tabelle aggregate della pagina della documentazione Riconoscimento degli aggregati per suggerimenti sull'ottimizzazione delle tabelle aggregate per assicurarti che vengano utilizzate per il riconoscimento degli aggregati.
Recupero del codice LookML della tabella aggregata da una dashboard
Un'altra opzione per gli sviluppatori Looker è recuperare il LookML della tabella aggregata per tutti i riquadri di una dashboard e poi copiarlo nel progetto LookML.
La creazione di tabelle aggregate può migliorare drasticamente le prestazioni di una dashboard, soprattutto per i riquadri che eseguono query su set di dati di grandi dimensioni.
Se disponi dell'autorizzazione develop, puoi ottenere il codice LookML per creare tabelle aggregate per una dashboard aprendo la dashboard, selezionando Recupera LookML dal menu con tre puntini della dashboard e scegliendo la scheda Tabelle aggregate:
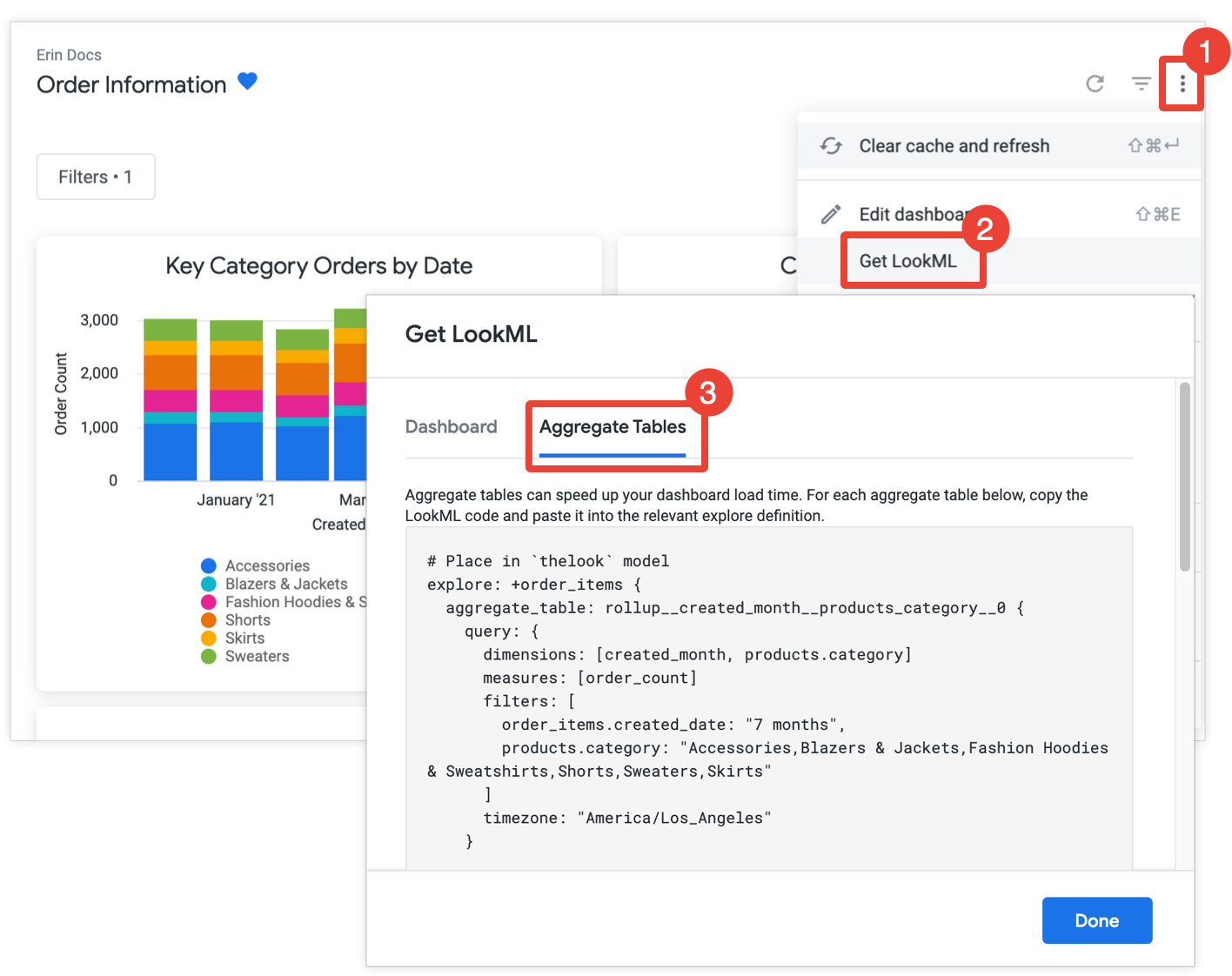
Per ogni riquadro non ancora ottimizzato con il riconoscimento degli aggregati, Looker fornisce il codice LookML per un affinamento di esplorazione che aggiungerà la tabella aggregata all'esplorazione. Se la dashboard include più riquadri della stessa esplorazione, Looker inserisce tutte le tabelle aggregate in un unico perfezionamento dell'esplorazione. Per ridurre il numero di tabelle aggregate generate, Looker determina se una tabella aggregata generata può essere utilizzata per più di un riquadro e, in caso affermativo, elimina le tabelle aggregate ridondanti che possono essere utilizzate per meno riquadri.
Copia e incolla ogni perfezionamento di Explore nel file del modello associato, indicato nel commento che precede il perfezionamento di Explore. Se l'Explore è definito in un file Explore separato e non in un file del modello, puoi aggiungere il perfezionamento al file Explore anziché al file del modello. Entrambe le posizioni funzionano.
Se un filtro della dashboard viene applicato a un riquadro, Looker aggiungerà la dimensione del filtro alla tabella aggregata del riquadro in modo che possa essere utilizzata per il riquadro. Questo perché le tabelle aggregate possono essere utilizzate per una query solo se i filtri della query fanno riferimento a campi disponibili come dimensioni nella tabella aggregata. Per informazioni, consulta la pagina della documentazione relativa alla consapevolezza aggregata.
Se devi modificare il codice LookML della tabella aggregata, puoi farlo con i parametri descritti nella sezione Definizione di una tabella aggregata in LookML di questa pagina. Puoi rinominare la tabella aggregata senza modificarne l'applicabilità al riquadro della dashboard originale, ma qualsiasi altra modifica alla tabella aggregata potrebbe influire sulla capacità di Looker di utilizzarla per la dashboard. Consulta la sezione Progettazione di tabelle aggregate della pagina della documentazione Riconoscimento degli aggregati per suggerimenti sull'ottimizzazione delle tabelle aggregate per assicurarti che vengano utilizzate per il riconoscimento degli aggregati.
Esempio
L'esempio seguente crea una tabella aggregata monthly_orders per l'esplorazione event. La tabella aggregata crea un conteggio mensile degli ordini. Looker utilizzerà la tabella aggregata per le query sul conteggio degli ordini che possono sfruttare la granularità mensile, ad esempio le query per i conteggi degli ordini annuali, trimestrali e mensili.
La tabella aggregata è configurata con la persistenza utilizzando datagroup orders_datagroup. Inoltre, la tabella aggregata è definita con publish_as_db_view: yes, il che significa che Looker creerà una visualizzazione stabile del database per la tabella aggregata.
La definizione della tabella aggregata è simile alla seguente:
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
Aspetti da considerare
Per suggerimenti sulla creazione strategica delle tabelle aggregate, consulta la sezione Progettazione di tabelle aggregate della pagina della documentazione Riconoscimento degli aggregati:
- Fattori del periodo di tempo
- Fattori del fuso orario
- Fattori di filtro
- Fattori di campo
- Fattori del tipo di misurazione
Supporto dei dialetti per il riconoscimento degli aggregati
La possibilità di utilizzare la consapevolezza degli aggregati dipende dal dialetto del database utilizzato dalla connessione Looker. Nell'ultima release di Looker, i seguenti dialetti supportano la consapevolezza degli aggregati:
| Dialetto | Supportata? |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |