
Utilisation
explore: explore_name {
aggregate_table: table_name {
query: {
dimensions: [dimension1, dimension2, ... ]
measures: [measure1, measure2, ... ]
sorts: [field1: asc, field2: desc, ... ]
filters: [field1: "value1", field2: "value2", ... ]
timezone: timezone
}
materialization: {
...
}
}
...
}
|
Hiérarchie
aggregate_table |
Valeur par défaut
Aucun
Acceptation
Un nom pour la table agrégée, le sous-paramètre query pour définir la table et le sous-paramètre materialization pour définir la stratégie de persistance de la table
Règles spéciales
|
Définition
Le paramètre aggregate_table permet de créer des tables agrégées qui minimisent le nombre de requêtes nécessaires pour les grandes tables de votre base de données.
Looker utilise une logique de reconnaissance des agrégats pour trouver la table agrégée la plus petite et la plus efficace disponible dans votre base de données, afin d'exécuter une requête tout en restant le plus précis possible. (Pour obtenir une présentation et des stratégies de création de tables agrégées, consultez la page de documentation Connaissance des agrégats.)
Pour les très grandes tables de votre base de données, vous pouvez créer des tables agrégées moins volumineuses contenant des données regroupées selon diverses combinaisons d'attributs. Les tables agrégées servent de tables de cumul ou de synthèse. Looker peut les utiliser pour les requêtes, chaque fois que cela est possible, à la place de la grande table d'origine.
Une fois que vous avez créé vos tables agrégées, vous pouvez exécuter des requêtes dans l'exploration pour voir quelles tables agrégées Looker utilise. Pour en savoir plus, consultez la section Déterminer quelle table cumulée est utilisée pour une requête sur la page de documentation Connaissance des agrégats.
Consultez la section Dépannage de la page de documentation Connaissance des agrégats pour connaître les raisons courantes pour lesquelles les tables agrégées ne sont pas utilisées.
Définir une table agrégée dans LookML
Chaque paramètre aggregate_table doit avoir un nom unique dans un explore donné.
Le paramètre aggregate_table comporte les sous-paramètres query et materialization.
query
Le paramètre query définit la requête pour le tableau cumulé, y compris les dimensions et les mesures à utiliser. Le paramètre query inclut les sous-paramètres suivants :
| Nom du paramètre | Description | Exemple |
|---|---|---|
dimensions |
Liste des dimensions de l'exploration à inclure dans votre tableau cumulé, séparées par une virgule. Le champ dimensions utilise le format suivant :dimensions: [dimension1, dimension2, ...]
Chaque dimension de cette liste doit être définie comme dimension dans le fichier d'affichage de l'exploration de la requête. Si vous souhaitez inclure un champ défini comme champ filter dans la requête Explorer, vous pouvez l'ajouter à la liste filters dans la requête du tableau agrégé.
|
dimensions: [orders.created_month, orders.country] |
measures |
Liste des mesures de l'exploration à inclure dans votre tableau cumulé, séparées par une virgule. Le champ measures utilise le format suivant : measures: [measure1, measure2, ...]
Pour en savoir plus sur les types de mesures compatibles avec la reconnaissance des agrégats, consultez la section Facteurs de type de mesure sur la page de documentation Reconnaissance des agrégats.
|
measures: [orders.count] |
filters |
Ajoute éventuellement un filtre à un query. Les filtres sont ajoutés à la clause WHERE du code SQL qui génère le tableau cumulé.
Le champ filters utilise le format suivant : filters: [field1: "value1", field2: "value2", ...]
Pour savoir comment les filtres peuvent empêcher l'utilisation de votre tableau cumulé, consultez la section Facteurs de filtrage sur la page de documentation Conscience de l'agrégation. |
filters: [orders.country: "United States", orders.state: "California"]
|
sorts |
Spécifie éventuellement les champs de tri et le sens du tri (croissant ou décroissant) pour query.
Le champ sorts utilise le format suivant : sorts: [field1: asc|desc, field2: asc|desc, ...]
|
[orders.country: asc, orders.state: desc] |
timezone |
Définit le fuseau horaire pour query. Si aucun fuseau horaire n'est spécifié, le tableau cumulé n'effectue aucune conversion de fuseau horaire et utilise le fuseau horaire de la base de données.
Pour savoir comment définir le fuseau horaire afin que votre tableau cumulé soit utilisé comme source de requête, consultez la section Facteurs liés au fuseau horaire sur la page de documentation Connaissance des agrégats.
L'IDE suggère automatiquement la valeur du fuseau horaire lorsque vous saisissez le paramètre timezone dans l'IDE. L'IDE affiche également la liste des valeurs de fuseau horaire acceptées dans le panneau "Aide rapide". |
timezone: America/Los_Angeles |
materialization
Le paramètre materialization spécifie la stratégie de persistance de votre tableau cumulé, ainsi que d'autres options de distribution, de partitionnement, d'index et de clustering qui peuvent être prises en charge par votre dialecte SQL.
Pour être accessible à la fonctionnalité de reconnaissance d'agrégats, votre table agrégée doit être conservée dans votre base de données. Le paramètre materialization de votre tableau cumulé doit comporter l'un des sous-paramètres suivants pour spécifier la stratégie de persistance :
datagroup_triggersql_trigger_valuepersist_for(non recommandé)
De plus, les sous-paramètres materialization suivants peuvent être acceptés pour votre tableau cumulé, en fonction de votre dialecte SQL :
Pour créer une table agrégée incrémentielle, utilisez les sous-paramètres materialization suivants :
datagroup_trigger
Utilisez le paramètre datagroup_trigger pour déclencher la régénération du tableau cumulé en fonction d'un datagroup existant défini dans le fichier de modèle :
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: order_datagroup
}
query: {
...
}
}
...
}
sql_trigger_value
Utilisez le paramètre sql_trigger_value pour déclencher la régénération du tableau cumulé en fonction d'une instruction SQL que vous fournissez. Si le résultat de l'instruction SQL est différent de la valeur précédente, la table est régénérée. Cette instruction sql_trigger_value déclenchera la régénération lorsque la date changera :
explore: event {
aggregate_table: monthly_orders {
materialization: {
sql_trigger_value: SELECT CURDATE() ;;
}
query: {
...
}
}
...
}
persist_for
Le paramètre persist_for est également compatible avec les tables agrégées. Toutefois, la stratégie persist_for n'est pas forcément la plus performante pour la reconnaissance des agrégats. En effet, lorsqu'un utilisateur exécute une requête qui s'appuie sur une table persist_for, Looker vérifie l'ancienneté de la table par rapport au paramètre persist_for. Si la table est plus ancienne que le paramètre persist_for, elle est régénérée avant l'exécution de la requête. Si l'ancienneté est inférieure au paramètre persist_for, la table existante est utilisée. Par conséquent, à moins qu'un utilisateur n'exécute une requête dans le délai persist_for, la table agrégée doit être reconstruite avant de pouvoir être utilisée pour la reconnaissance des agrégats.
explore: event {
aggregate_table: monthly_orders {
materialization: {
persist_for: "90 minutes"
}
query: {
...
}
}
...
}
À moins que vous ne compreniez les limites et que vous ayez un cas d'utilisation spécifique pour l'implémentation persist_for, il est préférable d'utiliser datagroup_trigger ou sql_trigger_value comme stratégie de persistance pour les tableaux agrégés.
cluster_keys
Le paramètre cluster_keys vous permet d'ajouter une colonne groupée aux tables partitionnées sur BigQuery ou Snowflake. Le clustering trie les données d'une partition en fonction des valeurs des colonnes en cluster et organise ces colonnes dans des blocs de stockage de taille optimale.
Pour en savoir plus, consultez la page de documentation sur le paramètre cluster_keys.
distribution
Le paramètre distribution vous permet de spécifier la colonne d'un tableau cumulé sur laquelle appliquer une clé de distribution. distribution ne fonctionne qu'avec les bases de données Redshift et Aster. Pour les autres dialectes SQL (tels que MySQL et Postgres), utilisez plutôt indexes.
Pour en savoir plus, consultez la page de documentation sur le paramètre distribution.
distribution_style
Le paramètre distribution_style vous permet de spécifier la façon dont la requête pour un tableau cumulé est distribuée sur les nœuds d'une base de données Redshift :
distribution_style: allindique que toutes les lignes sont entièrement copiées sur chaque nœud.distribution_style: evenspécifie une distribution uniforme, de sorte que les lignes sont distribuées à différents nœuds de manière séquentielle.
Pour en savoir plus, consultez la page de documentation sur le paramètre distribution_style.
indexes
Le paramètre indexes vous permet d'appliquer des index aux colonnes d'un tableau cumulé.
Pour en savoir plus, consultez la page de documentation sur le paramètre indexes.
partition_keys
Le paramètre partition_keys définit un tableau de colonnes selon lesquelles la table cumulée sera partitionnée. partition_keys est compatible avec les dialectes de base de données qui permettent de partitionner des colonnes. Lorsqu'une requête est exécutée et filtrée sur une colonne partitionnée, la base de données n'analyse que les partitions qui incluent les données filtrées, au lieu d'analyser l'intégralité de la table. partition_keys n'est compatible qu'avec les dialectes Presto et BigQuery.
Pour en savoir plus, consultez la page de documentation sur le paramètre partition_keys.
publish_as_db_view
Le paramètre publish_as_db_view vous permet de signaler une table agrégée pour l'interroger en dehors de Looker. Pour les tables agrégées dont le paramètre publish_as_db_view est défini sur yes, Looker crée une vue de base de données stable sur la base de données pour la table agrégée. La vue de base de données stable est créée sur la base de données elle-même, afin qu'elle puisse être interrogée en dehors de Looker.
Pour en savoir plus, consultez la page de documentation sur le paramètre publish_as_db_view.
sortkeys
Le paramètre sortkeys vous permet de spécifier une ou plusieurs colonnes d'un tableau cumulé sur lesquelles appliquer une clé de tri régulière.
Pour en savoir plus, consultez la page de documentation sur le paramètre sortkeys.
increment_key
Vous pouvez créer des tables PDT incrémentielles dans votre projet si votre dialecte les prend en charge. Une augmentation de table PDT est une table dérivée persistante (PDT) créée par Looker en ajoutant des données à jour à la table, au lieu de régénérer la totalité de la table. Pour en savoir plus, consultez la page de documentation sur les PDT incrémentales.
Les tables agrégées sont un type de PDT. Vous pouvez les créer de manière incrémentale en ajoutant le paramètre increment_key. Le paramètre increment_key indique l'incrément de temps pour lequel de nouvelles données devraient être interrogées et ajoutées au tableau cumulé.
Pour en savoir plus, consultez la page de documentation sur le paramètre increment_key.
increment_offset
Le paramètre increment_offset définit le nombre de périodes précédentes (selon la granularité de la clé d'incrémentation) qui seront régénérées lors de l'ajout de données au tableau cumulé. Le paramètre increment_offset est facultatif pour les PDT incrémentielles et les tables agrégées.
Pour en savoir plus, consultez la page de documentation sur le paramètre increment_offset.
Extraire le code LookML d'un tableau cumulé à partir d'une exploration
Pour gagner du temps, les développeurs Looker peuvent utiliser une exploration pour créer un tableau cumulé, puis copier le code LookML dans le projet LookML :
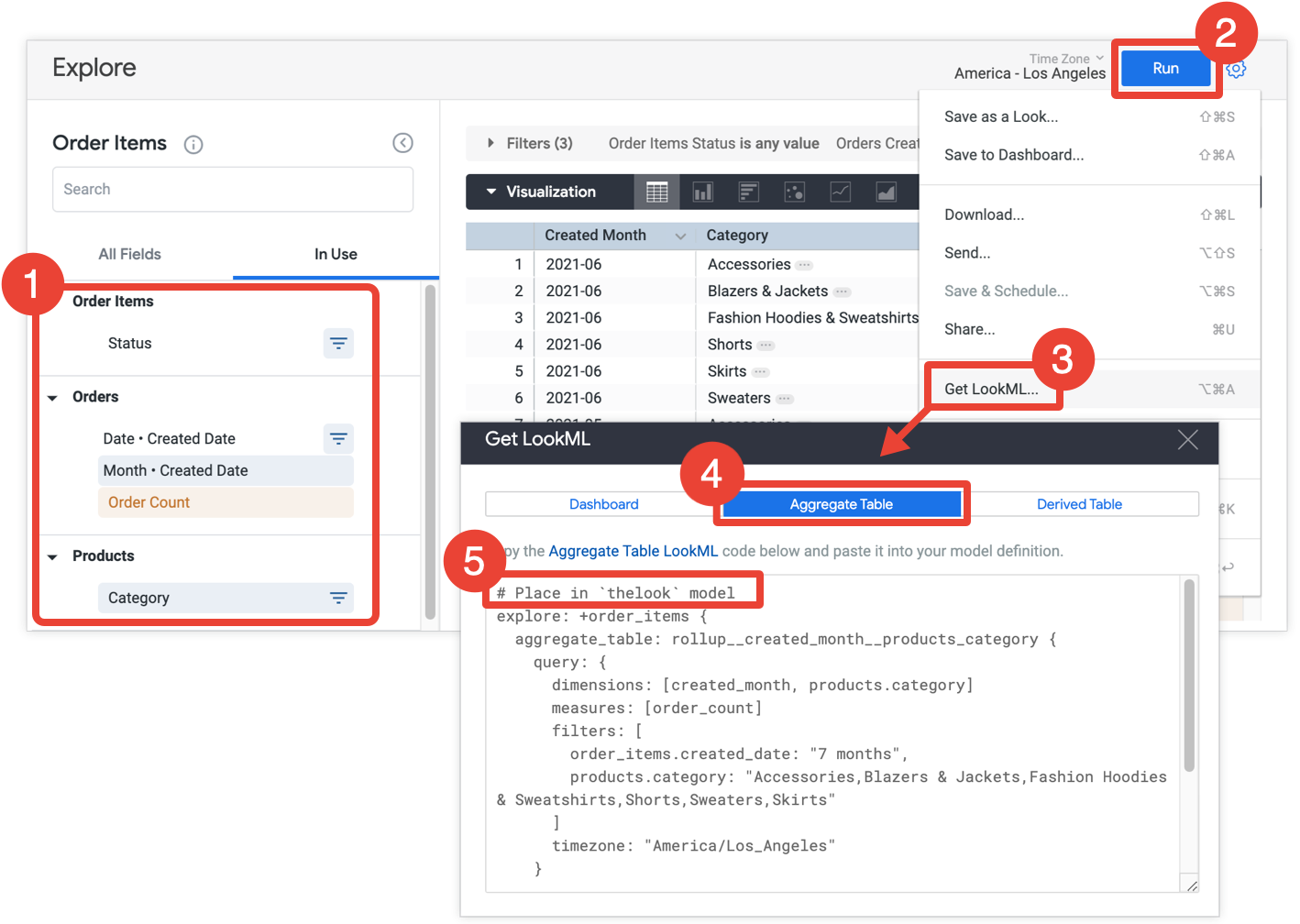
- Dans votre exploration, sélectionnez tous les champs et filtres que vous souhaitez inclure dans votre tableau cumulé.
- Cliquez sur Exécuter pour obtenir les résultats.
- Sélectionnez Obtenir le LookML dans le menu en forme de roue dentée de l'exploration. Cette option n'est disponible que pour les développeurs Looker.
- Cliquez sur l'onglet Tableau agrégé.
- Looker fournit le code LookML pour un affinement d'exploration qui ajoutera le tableau cumulé à l'exploration. Copiez le code LookML et collez-le dans le fichier de modèle associé, indiqué dans le commentaire qui précède l'affinage de l'exploration. Si l'exploration est définie dans un fichier d'exploration distinct et non dans un fichier de modèle, vous pouvez ajouter l'affinage au fichier de l'exploration au lieu du fichier de modèle. Les deux emplacements conviennent.
Si vous devez modifier le code LookML du tableau cumulé, vous pouvez le faire à l'aide des paramètres décrits dans la section Définir un tableau cumulé dans LookML de cette page. Vous pouvez renommer le tableau cumulé sans modifier son applicabilité à la requête Explorer d'origine. Toutefois, toute autre modification apportée au tableau cumulé peut empêcher Looker de l'utiliser pour la requête d'exploration. Consultez la section Concevoir des tables agrégées de la page de documentation Reconnaissance d'agrégats pour obtenir des conseils sur l'optimisation de vos tables agrégées afin de vous assurer qu'elles sont utilisées pour la reconnaissance d'agrégats.
Extraire le code LookML d'une table agrégée à partir d'un tableau de bord
Une autre option pour les développeurs Looker consiste à obtenir le code LookML du tableau cumulé pour toutes les vignettes d'un tableau de bord, puis à copier le code LookML dans le projet LookML.
La création de tables agrégées peut améliorer considérablement les performances d'un tableau de bord, en particulier pour les tuiles qui interrogent d'énormes ensembles de données.
Si vous disposez de l'autorisation develop, vous pouvez obtenir le code LookML pour créer des tables agrégées pour un tableau de bord. Pour cela, ouvrez le tableau de bord, sélectionnez Obtenir le code LookML dans le menu à trois points du tableau de bord, puis choisissez l'onglet Tables agrégées :
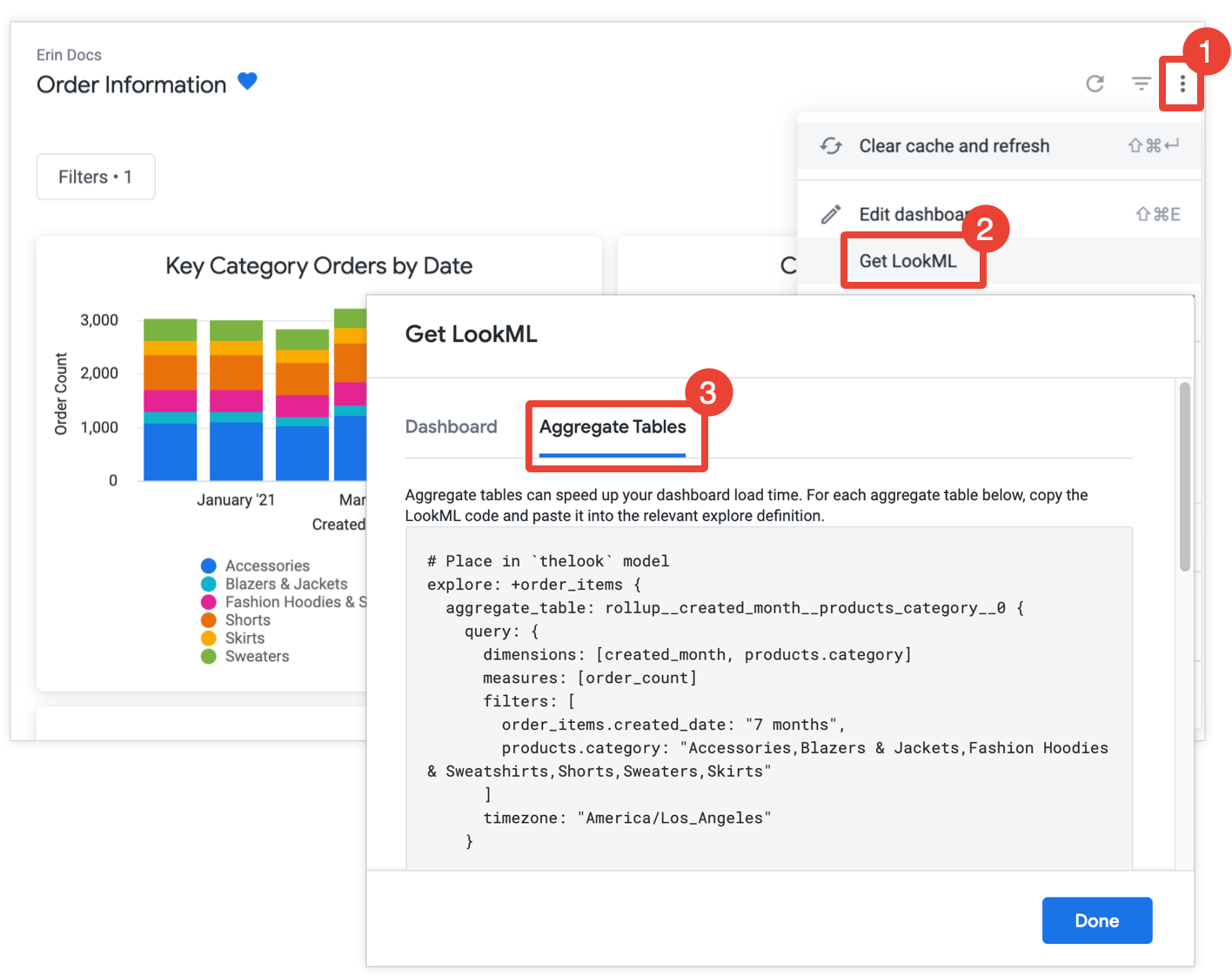
Pour chaque vignette qui n'est pas encore optimisée avec la reconnaissance des agrégats, Looker fournit le code LookML pour un affinage d'exploration qui ajoutera le tableau cumulé à l'exploration. Si le tableau de bord inclut plusieurs vignettes provenant de la même exploration, Looker place toutes les tables agrégées dans un seul affinement d'exploration. Pour réduire le nombre de tableaux cumulés générés, Looker détermine si un tableau cumulé généré peut être utilisé pour plusieurs vignettes. Si c'est le cas, il supprime tous les tableaux cumulés redondants qui peuvent être utilisés pour moins de vignettes.
Copiez et collez chaque affinement d'exploration dans le fichier de modèle associé, indiqué dans le commentaire précédant l'affinement d'exploration. Si l'exploration est définie dans un fichier d'exploration distinct et non dans un fichier de modèle, vous pouvez ajouter l'affinage au fichier d'exploration au lieu du fichier de modèle. Les deux emplacements conviennent.
Si un filtre de tableau de bord est appliqué à une vignette, Looker ajoute la dimension du filtre à la table cumulée de la vignette afin que la table cumulée puisse être utilisée pour la vignette. En effet, les tableaux cumulés ne peuvent être utilisés pour une requête que si les filtres de la requête font référence à des champs disponibles en tant que dimensions dans le tableau cumulé. Pour en savoir plus, consultez la page de documentation Conscience globale.
Si vous devez modifier le code LookML du tableau cumulé, vous pouvez le faire à l'aide des paramètres décrits dans la section Définir un tableau cumulé dans LookML de cette page. Vous pouvez renommer le tableau cumulé sans modifier son applicabilité à la vignette de tableau de bord d'origine. Toutefois, toute autre modification apportée au tableau cumulé peut empêcher Looker de l'utiliser pour le tableau de bord. Consultez la section Concevoir des tables agrégées de la page de documentation Reconnaissance d'agrégats pour obtenir des conseils sur l'optimisation de vos tables agrégées afin de vous assurer qu'elles sont utilisées pour la reconnaissance d'agrégats.
Exemple
L'exemple suivant crée un tableau cumulé monthly_orders pour l'exploration event. La table agrégée crée un décompte mensuel des commandes. Looker utilisera la table agrégée pour les requêtes sur le nombre de commandes qui peuvent tirer parti de la granularité mensuelle, comme les requêtes sur le nombre de commandes annuelles, trimestrielles et mensuelles.
Le tableau cumulé est configuré avec persistance à l'aide de datagroup orders_datagroup. Il est également défini avec publish_as_db_view: yes, ce qui signifie que Looker créera une vue de base de données stable pour le tableau cumulé.
La définition du tableau cumulé se présente comme suit :
explore: event {
aggregate_table: monthly_orders {
materialization: {
datagroup_trigger: orders_datagroup
publish_as_db_view: yes
}
query: {
dimensions: [orders.created_month]
measures: [orders.count]
filters: [orders.created_date: "1 year", orders.status: "fulfilled"]
timezone: America/Los_Angeles
}
}
}
Éléments à prendre en compte
Consultez la section Concevoir des tables agrégées de la page de documentation Connaissance des agrégats pour obtenir des conseils sur la création stratégique de vos tables agrégées :
- Facteurs de période
- Facteurs de fuseau horaire
- Facteurs de filtrage
- Facteurs de champ
- Facteurs de type de mesure
Prise en charge des dialectes pour la reconnaissance d'agrégats
La possibilité d'utiliser la fonction Aggregate Awareness dépend du dialecte de base de données de votre connexion Looker. Dans la dernière version de Looker, les dialectes suivants sont compatibles avec Aggregate Awareness :
| Dialecte | Compatibilité |
|---|---|
| Actian Avalanche | |
| Amazon Athena | |
| Amazon Aurora MySQL | |
| Amazon Redshift | |
| Amazon Redshift 2.1+ | |
| Amazon Redshift Serverless 2.1+ | |
| Apache Druid | |
| Apache Druid 0.13+ | |
| Apache Druid 0.18+ | |
| Apache Hive 2.3+ | |
| Apache Hive 3.1.2+ | |
| Apache Spark 3+ | |
| ClickHouse | |
| Cloudera Impala 3.1+ | |
| Cloudera Impala 3.1+ with Native Driver | |
| Cloudera Impala with Native Driver | |
| DataVirtuality | |
| Databricks | |
| Denodo 7 | |
| Denodo 8 & 9 | |
| Dremio | |
| Dremio 11+ | |
| Exasol | |
| Google BigQuery Legacy SQL | |
| Google BigQuery Standard SQL | |
| Google Cloud PostgreSQL | |
| Google Cloud SQL | |
| Google Spanner | |
| Greenplum | |
| HyperSQL | |
| IBM Netezza | |
| MariaDB | |
| Microsoft Azure PostgreSQL | |
| Microsoft Azure SQL Database | |
| Microsoft Azure Synapse Analytics | |
| Microsoft SQL Server 2008+ | |
| Microsoft SQL Server 2012+ | |
| Microsoft SQL Server 2016 | |
| Microsoft SQL Server 2017+ | |
| MongoBI | |
| MySQL | |
| MySQL 8.0.12+ | |
| Oracle | |
| Oracle ADWC | |
| PostgreSQL 9.5+ | |
| PostgreSQL pre-9.5 | |
| PrestoDB | |
| PrestoSQL | |
| SAP HANA | |
| SAP HANA 2+ | |
| SingleStore | |
| SingleStore 7+ | |
| Snowflake | |
| Teradata | |
| Trino | |
| Vector | |
| Vertica |