
이 문서에서는 Google Cloud 콘솔을 사용하여 로그 항목을 쿼리하고 보고 분석하는 방법을 설명합니다. 사용 가능한 인터페이스로는 로그 탐색기와 관측 가능성 분석이라는 두 가지 인터페이스가 있습니다. 두 인터페이스 중 무엇을 사용하던 로그를 쿼리, 확인, 분석할 수 있지만 두 인터페이스는 사용하는 쿼리 언어와 기능이 다릅니다.
로그 데이터의 문제 해결과 탐색 분석을 위해서는 로그 탐색기를 사용하세요.
로그 및 트레이스 데이터를 조인하거나 통계 및 트렌드를 생성하려면 모니터링 가능성 분석을 사용하세요.
Logging API 명령어를 실행하여 로그를 쿼리하고 쿼리를 저장할 수 있습니다. 또한 Google Cloud CLI를 사용하여 로그를 쿼리할 수도 있습니다.
로그 탐색기 사용
로그 탐색기는 서비스 및 애플리케이션의 문제를 해결하고 성능을 분석할 수 있도록 설계되었습니다. 예를 들어 히스토그램에 오류율이 표시됩니다. 오류가 급증하거나 흥미로운 사항이 표시되면 해당 로그 항목을 찾아 볼 수 있습니다. 로그 항목이 오류 그룹과 연결되어 있는 경우, 해당 로그 항목에는 오류 그룹에 대한 자세한 정보에 액세스할 수 있는 옵션 메뉴가 주석으로 추가되어 있습니다.
Cloud Logging API, Google Cloud CLI, 로그 탐색기에서 같은 쿼리 언어가 지원됩니다. 로그 탐색기를 사용할 때 쿼리 구성을 간소화하려면 메뉴를 사용하거나, 텍스트를 입력하거나, 경우에 따라 개별 로그 항목의 디스플레이에 포함된 옵션을 사용하여 쿼리를 빌드할 수 있습니다.
로그 탐색기에서는 특정 패턴이 포함된 로그 항목 수 계산과 같은 집계 작업을 지원하지 않습니다. 집계 작업을 수행하려면 로그 버킷에서 분석을 사용 설정한 후 관측 가능성 분석을 사용합니다.
로그 탐색기로 로그를 검색하고 보는 방법에 대한 자세한 내용은 로그 탐색기를 사용하여 로그 보기를 참고하세요.
관측 가능성 분석 살펴보기
모니터링 가능성 분석을 사용하면 로그 데이터를 그룹화하고 집계하는 쿼리를 실행하여 유용한 정보를 생성할 수 있습니다. 이러한 정보를 통해 문제 해결에 소요되는 시간을 줄일 수 있습니다. 쿼리 결과를 보려면 표, 차트 또는 둘 다를 사용합니다. 차트를 사용하면 로그 데이터의 패턴과 추세를 파악할 수 있습니다. 예를 들어 다음 스크린샷은 테이블과 차트로 표시된 쿼리 결과를 보여줍니다.
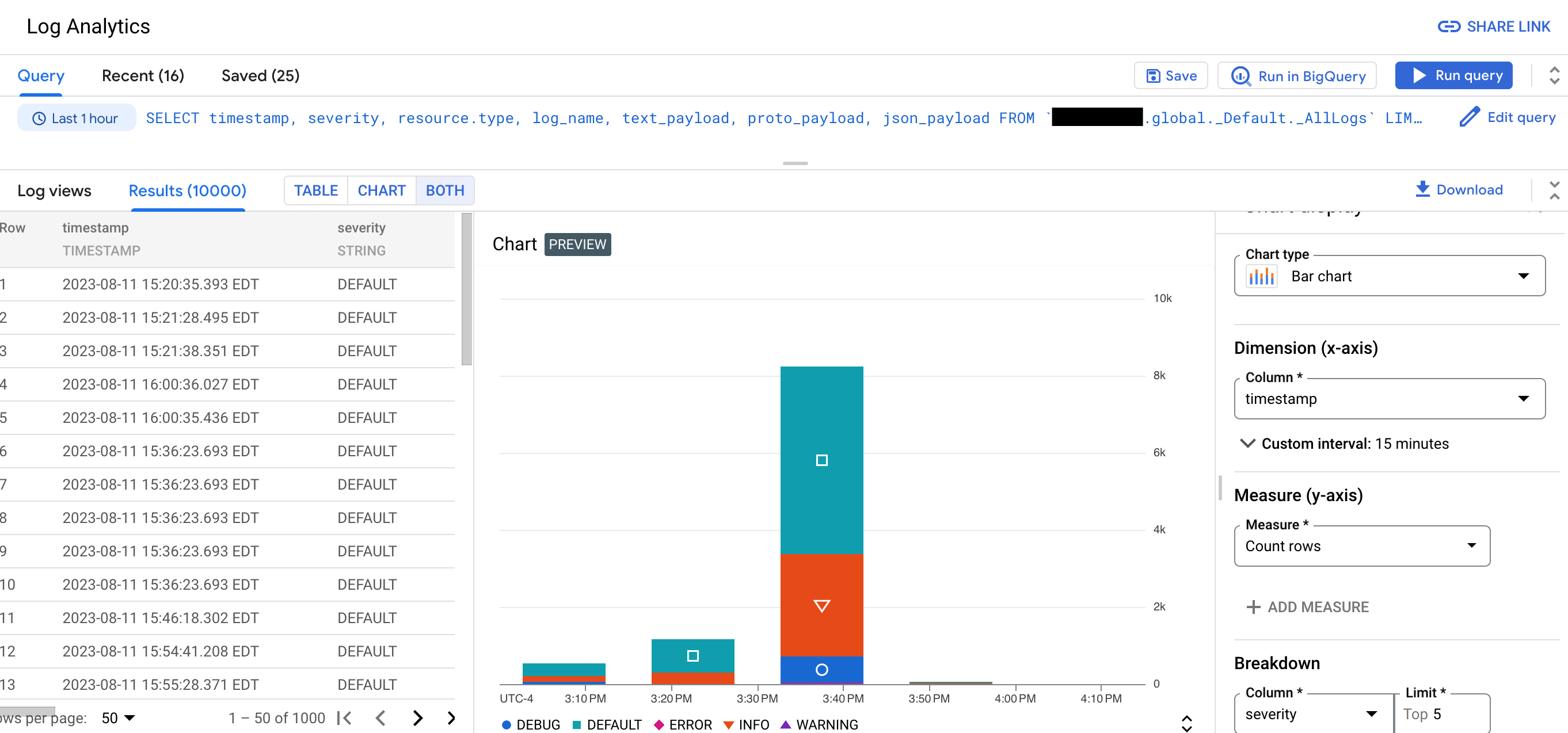
모니터링 가능성 분석은 다음을 지원합니다.
로그 데이터 그룹화 및 집계
예를 들어 시간별로 로그 항목을 그룹화한 다음 각 그룹에 대해 특정 URL에 발급된 HTTP 요청의 평균 지연 시간을 계산하는 SQL 쿼리를 실행할 수 있습니다.
파이프 구문을 사용하는 SQL 쿼리
-
로그 뷰에는 시스템 정의 스키마가 있습니다. 분석 뷰의 스키마를 정의합니다.
로그 및 추적 데이터의 조인
trace 데이터 쿼리에 관한 자세한 내용은 trace 쿼리 및 분석을 참고하세요.
또한 Cloud Logging을 사용하면 데이터를 BigQuery로 내보내지 않고도 BigQuery에서 로그 데이터를 쿼리할 수 있습니다. 관측 가능성 분석을 사용하도록 로그 버킷을 업그레이드한 후 연결된 BigQuery 데이터 세트를 만듭니다. BigQuery 서비스를 사용하여 연결된 BigQuery 데이터 세트를 쿼리할 수 있습니다.
로그 버킷을 업그레이드해도 로그 탐색기 사용에는 영향을 미치지 않습니다. 로그 탐색기에서는 로그 데이터가 로그 버킷에 저장되어 있어야 합니다.
제한사항
모니터링 가능성 분석을 사용하도록 기존 로그 버킷을 업그레이드하려면 다음 제한사항이 적용됩니다.
- 로그 버킷은 Google Cloud 프로젝트 수준에서 생성되었습니다.
- 로그 버킷이
_Required버킷이 아니면 잠금 해제됩니다. - 버킷에 대기 중인 업데이트가 없습니다.
버킷이 업그레이드되기 전에 작성된 로그 항목은 즉시 사용할 수 없습니다. 하지만 백필 작업이 완료되면 이러한 로그 항목을 분석할 수 있습니다. 백필 프로세스는 며칠이 걸릴 수 있습니다.
로그 버킷에 필드 수준 액세스 제어가 구성된 경우 관측 가능성 분석 페이지를 사용하여 로그 뷰를 쿼리할 수 없습니다. 하지만 로그 탐색기 페이지를 통해 쿼리를 실행하고 연결된 BigQuery 데이터 세트를 쿼리할 수 있습니다. BigQuery는 필드 수준 액세스 제어를 따르지 않으므로 연결된 BigQuery 데이터 세트를 쿼리하면 로그 항목의 모든 필드를 쿼리할 수 있습니다.
중복 로그 항목은 쿼리가 실행되기 전에 삭제되지 않습니다. 이 동작은 로그 이름, 타임스탬프, 삽입 ID 필드를 비교하여 중복 항목을 삭제하는 로그 탐색기를 사용하여 로그 항목을 쿼리할 때와 다릅니다. 자세한 내용은 문제 해결: 모니터링 가능성 분석 결과에 중복된 로그 항목이 있음을 참고하세요.
조인 제한
뷰를 결합하려면 다음 제한사항이 적용됩니다.
-
뷰의 위치가 다음 중 하나를 충족합니다.
- 모든 뷰의 위치가 동일합니다.
- 모든 조회수는
global또는us위치에서 발생합니다.
-
스토리지 리소스가 고객 관리 암호화 키 (CMEK)를 사용하는 경우 다음 중 하나가 참입니다.
- CMEK를 사용하는 스토리지 리소스는 동일한 Cloud KMS 키를 사용합니다.
- CMEK를 사용하는 스토리지 리소스에는 공통 상위 항목이 있으며, 이 상위 항목은 스토리지 리소스와 동일한 위치에 있는 기본 Cloud KMS 키를 지정합니다.
하나 이상의 스토리지 리소스가 CMEK를 사용하는 경우 시스템은 공통 Cloud KMS 키 또는 상위 항목의 기본 Cloud KMS 키를 사용하여 조인에서 생성된 임시 데이터를 암호화합니다.
예를 들어 동일한 위치에 있는 두 개의 뷰가 있다고 가정해 보겠습니다. 그런 다음 다음 중 하나라도 해당하는 경우 이러한 뷰를 조인할 수 있습니다.
- 스토리지 리소스가 CMEK를 사용하지 않습니다.
- 한 스토리지 리소스는 CMEK를 사용하고 다른 스토리지 리소스는 CMEK를 사용하지 않습니다.
- 두 스토리지 리소스 모두 CMEK를 사용하고 동일한 Cloud KMS 키를 사용합니다.
두 스토리지 리소스 모두 CMEK를 사용하지만 서로 다른 키를 사용합니다. 하지만 리소스는 스토리지 리소스와 동일한 위치에 있는 기본 Cloud KMS 키를 지정하는 상위 항목을 공유합니다.
예를 들어 로그 버킷과 관측 가능성 버킷의 리소스 계층 구조에 동일한 조직이 포함된다고 가정해 보겠습니다. 조직에 대해 스토리지 위치의 기본 Cloud KMS 키가 동일한 Cloud Logging의 기본 리소스 설정과 관측 가능성 버킷을 구성한 경우 이러한 버킷의 뷰를 조인할 수 있습니다.
가격 책정
가격 책정 정보는 Google Cloud Observability 가격 책정 페이지를 참고하세요. 로그 데이터를 다른 Google Cloud 서비스로 라우팅하는 경우 다음 문서를 참고하세요.
관측 가능성 분석을 사용하도록 버킷을 업그레이드한 후 연결된 BigQuery 데이터 세트를 만들면 BigQuery 수집 또는 스토리지 비용이 발생하지 않습니다. 로그 버킷에 연결된 BigQuery 데이터 세트를 만들 때 로그 데이터를 BigQuery로 수집하지 않습니다. 대신 연결된 BigQuery 데이터 세트를 통해 로그 버킷에 저장된 로그 데이터에 대한 읽기 액세스 권한을 얻을 수 있습니다.
BigQuery 분석 요금은 BigQuery Studio 페이지, BigQuery API, BigQuery 명령줄 도구 사용을 포함하여 BigQuery 연결 BigQuery 데이터 세트에서 SQL 쿼리를 실행할 때 적용됩니다.
블로그
모니터링 가능성 분석에 대한 자세한 내용은 다음 블로그 게시물을 참고하세요.
- 관측 가능성 분석 개요는 Cloud Logging의 관측 가능성 분석이 정식 버전으로 출시되었습니다를 참고하세요.
- 모니터링 가능성 분석 쿼리로 생성된 차트를 만들고 커스텀 대시보드에 이러한 차트를 저장하는 방법을 알아보려면 공개 미리보기 버전의 Cloud Logging에서 모니터링 가능성 분석 차트 및 대시보드 발표를 참고하세요.
- 모니터링 가능성 분석을 사용하여 감사 로그를 분석하는 방법을 알아보려면 모니터링 가능성 분석을 사용하여 감사 로그에서 보안 통계 확보를 참고하세요.
- 로그를 BigQuery로 라우팅하고 이 솔루션과 관측 가능성 분석 사용의 차이를 알고 싶으면 BigQuery Export 사용자를 위한 관측 가능성 분석으로 전환을 참고하세요.
다음 단계
- 로그 버킷을 만들고 모니터링 가능성 분석을 사용하도록 업그레이드
- 모니터링 가능성 분석을 사용하도록 기존 버킷 업그레이드
로그 쿼리 및 보기:
샘플 쿼리: