
Ce document explique comment interroger, afficher et analyser les entrées de journal à l'aide de la console Google Cloud . Deux interfaces sont disponibles : l'explorateur de journaux et l'analyse de l'observabilité. Vous pouvez interroger, afficher et analyser les journaux avec les deux interfaces. Toutefois, elles utilisent des langages de requête différents et ont des capacités différentes :
Pour résoudre les problèmes et explorer les données de journaux, utilisez l'explorateur de journaux.
Pour joindre vos données de journaux et de trace, ou pour générer des insights et des tendances, utilisez l'analyse de l'observabilité.
Vous pouvez interroger vos journaux et enregistrer vos requêtes en exécutant des commandes de l'API Logging. Vous pouvez également interroger vos journaux à l'aide de la Google Cloud CLI.
Utiliser l'Explorateur de journaux
L'explorateur de journaux est conçu pour vous aider à résoudre les problèmes et à analyser les performances de vos services et applications. Par exemple, un histogramme affiche le taux d'erreurs. Si vous constatez un pic d'erreurs ou un événement intéressant, vous pouvez localiser et afficher les entrées de journal correspondantes. Lorsqu'une entrée de journal est associée à un groupe d'erreurs, elle est annotée avec un menu d'options qui vous permet d'accéder à plus d'informations sur le groupe d'erreurs.
Le même langage de requête est compatible avec l'API Cloud Logging, Google Cloud CLI et l'explorateur de journaux. Pour simplifier la création de requêtes lorsque vous utilisez l'explorateur de journaux, vous pouvez créer des requêtes à l'aide de menus, en saisissant du texte et, dans certains cas, en utilisant les options incluses dans l'affichage d'une entrée de journal individuelle.
L'explorateur de journaux ne prend pas en charge les opérations d'agrégation, comme le décompte du nombre d'entrées de journal contenant un modèle spécifique. Pour effectuer des opérations d'agrégation, activez l'analyse sur le bucket de journaux, puis utilisez Observability Analytics.
Pour en savoir plus sur la recherche et l'affichage des journaux avec l'explorateur de journaux, consultez Afficher les journaux à l'aide de l'explorateur de journaux.
Explorer Observability Analytics
L'Analyse de l'observabilité vous permet de générer des insights en exécutant des requêtes qui regroupent et agrègent vos données de journaux. Ces informations peuvent vous aider à réduire le temps que vous passez à résoudre les problèmes. Pour afficher les résultats de votre requête, utilisez un tableau, un graphique ou les deux. Les graphiques peuvent vous aider à identifier des schémas et des tendances dans les données de vos journaux. Par exemple, la capture d'écran suivante montre un résultat de requête affiché sous forme de tableau et de graphique :
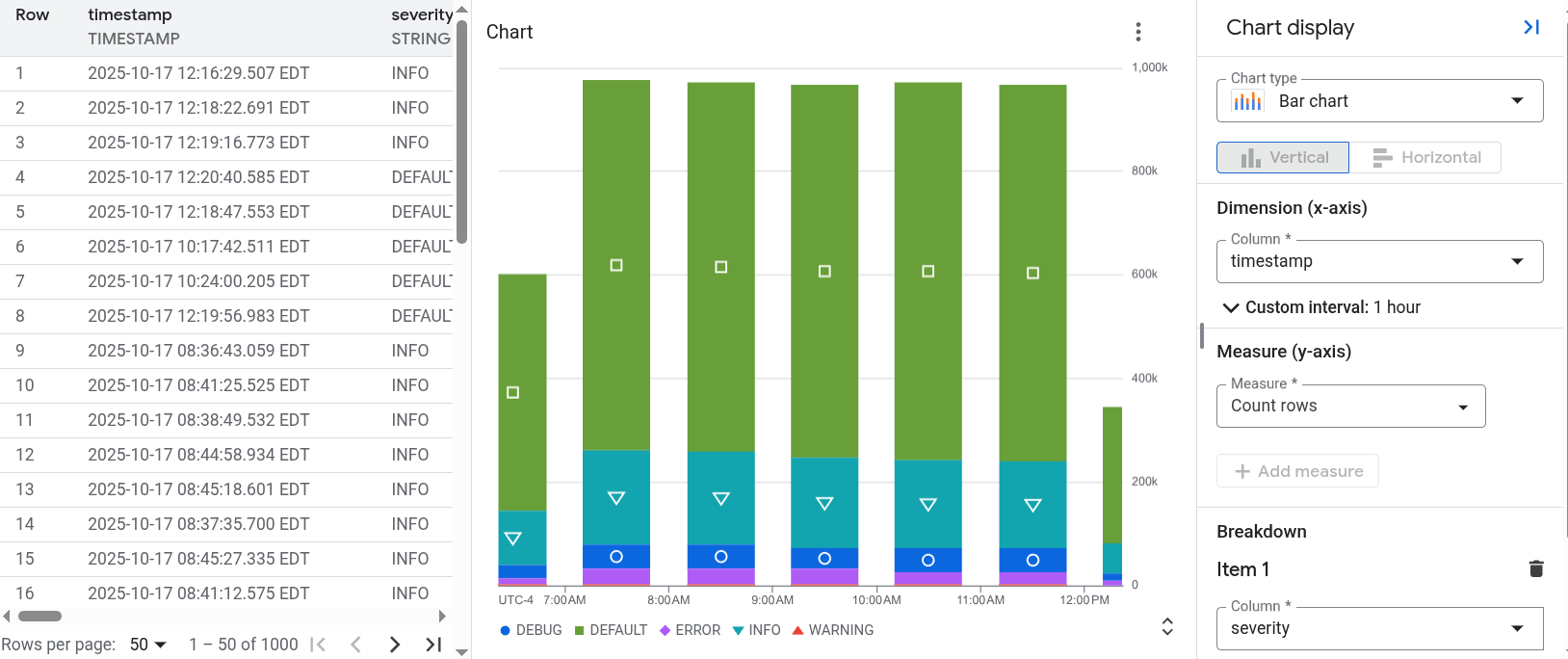
Observability Analytics est compatible avec les éléments suivants :
Regrouper et agréger les données de journaux
Par exemple, vous pouvez exécuter une requête SQL qui regroupe les entrées de journal par heure, puis calcule pour chaque groupe la latence moyenne des requêtes HTTP émises vers une URL spécifique.
Requêtes SQL utilisant la syntaxe pipe.
Requêtes sur les vues de journaux et les vues d'analyse.
Les vues de journaux ont un schéma défini par le système. Vous définissez le schéma des vues Analytics.
Jointures des données de journaux et de trace.
Pour savoir comment interroger vos données de trace, consultez Interroger et analyser des traces.
Cloud Logging vous permet également d'interroger vos données de journaux à partir de BigQuery, sans avoir à les y exporter. Après avoir mis à niveau votre bucket de journaux pour utiliser Observability Analytics, créez un ensemble de données BigQuery associé. Vous pouvez interroger l'ensemble de données BigQuery associé à l'aide des services BigQuery.
La mise à niveau d'un bucket de journaux n'a aucune incidence sur votre utilisation de l'explorateur de journaux. L'explorateur de journaux exige uniquement que vos données de journaux soient stockées dans un bucket de journaux.
Restrictions
Pour mettre à niveau un bucket de journaux existant afin qu'il utilise Observability Analytics, les restrictions suivantes s'appliquent :
- Le bucket de journaux a été créé au niveau du projet Google Cloud .
- Le bucket de journaux est déverrouillé, sauf s'il s'agit du bucket
_Required. - Aucune mise à jour n'est en attente pour le bucket.
Les entrées de journal écrites avant la mise à niveau d'un bucket ne sont pas immédiatement disponibles. Toutefois, une fois l'opération de remplissage terminée, vous pouvez analyser ces entrées de journal. Le processus de remplissage peut prendre plusieurs jours.
Vous ne pouvez pas utiliser la page Analyse de l'observabilité pour interroger les vues de journaux lorsque des contrôles d'accès au niveau du champ sont configurés pour le bucket de journaux. Toutefois, vous pouvez exécuter des requêtes sur la page Explorateur de journaux et interroger un ensemble de données BigQuery associé. Étant donné que BigQuery ne respecte pas les contrôles d'accès au niveau des champs, si vous interrogez un ensemble de données BigQuery associé, vous pouvez interroger tous les champs des entrées de journaux.
Les entrées de journaux en double ne sont pas supprimées avant l'exécution d'une requête. Ce comportement est différent de celui qui se produit lorsque vous interrogez des entrées de journal à l'aide de l'explorateur de journaux, qui supprime les entrées en double en comparant les champs "Nom du journal", "Code temporel" et "ID d'insertion". Pour en savoir plus, consultez Résoudre les problèmes : des entrées de journaux en double figurent dans mes résultats Observability Analytics.
Restrictions concernant les jointures
Pour joindre des vues, les restrictions suivantes s'appliquent :
-
Les emplacements des vues satisfont l'une des conditions suivantes :
- Toutes les vues ont le même emplacement.
- Toutes les vues se trouvent dans l'emplacement
globalouus.
-
Lorsque les ressources de stockage utilisent des clés de chiffrement gérées par le client (CMEK), l'une des conditions suivantes doit être remplie :
- Les ressources de stockage qui utilisent CMEK utilisent la même clé Cloud KMS.
- Les ressources de stockage qui utilisent CMEK ont un ancêtre commun, et cet ancêtre spécifie une clé Cloud KMS par défaut qui se trouve au même emplacement que les ressources de stockage.
Lorsqu'une ou plusieurs ressources de stockage utilisent le CMEK, le système chiffre les données temporaires générées par la jointure avec la clé Cloud KMS commune ou la clé Cloud KMS par défaut de l'ancêtre.
Par exemple, supposons que vous ayez deux vues qui se trouvent au même emplacement. Vous pouvez ensuite joindre ces vues si l'une des conditions suivantes est remplie :
- Les ressources de stockage n'utilisent pas CMEK.
- Une ressource de stockage utilise CMEK, mais pas l'autre.
- Les deux ressources de stockage utilisent le chiffrement CMEK et la même clé Cloud KMS.
Les deux ressources de stockage utilisent CMEK, mais avec des clés différentes. Toutefois, les ressources partagent un ancêtre qui spécifie une clé Cloud KMS par défaut se trouvant au même emplacement que les ressources de stockage.
Par exemple, supposons que la hiérarchie des ressources pour un bucket de journaux et un bucket d'observabilité inclue la même organisation. Vous pouvez joindre des vues sur ces buckets lorsque, pour cette organisation, vous avez configuré les paramètres de ressources par défaut pour Cloud Logging et pour les buckets d'observabilité avec la même clé Cloud KMS par défaut pour l'emplacement de stockage.
Tarifs
Pour en savoir plus sur les tarifs, consultez la page Tarifs de Google Cloud Observability. Si vous acheminez les données de journaux vers d'autres services Google Cloud , consultez les documents suivants :
Il n'y a pas de frais d'ingestion ni de stockage BigQuery lorsque vous mettez à niveau un bucket pour utiliser l'analyse de l'observabilité, puis que vous créez un ensemble de données BigQuery associé. Lorsque vous créez un ensemble de données BigQuery associé pour un bucket de journaux, vous n'ingérez pas vos données de journaux dans BigQuery. Vous bénéficiez plutôt d'un accès en lecture aux données de journaux stockées dans votre bucket de journaux via l'ensemble de données BigQuery associé.
Des frais d'analyse BigQuery s'appliquent lorsque vous exécutez des requêtes SQL sur des ensembles de données BigQuery associés à BigQuery. Cela inclut l'utilisation de la page BigQuery Studio, de l'API BigQuery et de l'outil de ligne de commande BigQuery.
Blogs
Pour en savoir plus sur Observability Analytics, consultez les articles de blog suivants :
- Pour obtenir une présentation d'Observability Analytics, consultez Observability Analytics dans Cloud Logging est désormais en disponibilité générale.
- Pour savoir comment créer des graphiques générés par des requêtes d'analyse de l'observabilité et les enregistrer dans des tableaux de bord personnalisés, consultez Annonce des graphiques et tableaux de bord d'analyse de l'observabilité dans Cloud Logging en version Preview publique.
- Pour savoir comment analyser les journaux d'audit à l'aide de l'Analyse de l'observabilité, consultez Obtenir des insights sur la sécurité provenant de journaux d'audit grâce à l'Analyse de l'observabilité.
- Si vous routez des journaux vers BigQuery et que vous souhaitez comprendre la différence entre cette solution et l'utilisation d'Observability Analytics, consultez Passer à Observability Analytics pour les utilisateurs de l'exportation BigQuery.
Étapes suivantes
- Créer un bucket de journaux et le mettre à niveau pour utiliser Observability Analytics
- Mettre à niveau un bucket existant pour utiliser Observability Analytics
Interrogez et affichez les journaux :
Exemples de requêtes :