
O catálogo de ambientes de execução do Lakehouse é um metastore unificado e sem servidor que simplifica o gerenciamento de metastores do Hive auto-hospedados. Essa camada de metadados única e totalmente gerenciada elimina a necessidade de lojas de metadados separadas para cargas de trabalho de código aberto. Ela permite que você compartilhe dados perfeitamente entre o Apache Spark, o Apache Hive e o BigQuery.
Otimizada para a compatibilidade do ExternalCatalog do Apache Spark, essa integração oferece suporte a um subconjunto da interface do metastore do Hive. Para saber se suas cargas de trabalho
dependem de recursos sem suporte, como transações, compactações ou Kerberos,
revise a comparação de recursos e as limitações.
Como o Hive se integra ao catálogo de ambientes de execução do Lakehouse
O endpoint do metastore do Hive gerencia tabelas padrão do Apache Hive e do Spark (usando o Hive SerDes ou fontes de dados do Spark) em vez de tabelas do Apache Iceberg. Para simplificar a conexão dos jobs do Spark a esse endpoint, as imagens do Serviço Gerenciado para Apache Spark são pré-configuradas com as bibliotecas e dependências de cliente necessárias.
A sequência a seguir descreve como o Spark se conecta ao metastore:
- O Apache Spark se conecta a catálogos de metadados externos usando a interface
IMetastoreClientpadrão do Apache Hive. - O catálogo de ambientes de execução do Lakehouse implementa um
IMetastoreClientpersonalizado para fornecer um serviço de metastore totalmente gerenciado para os metadados do Spark e do Hive. - Os ambientes de execução do Serviço Gerenciado para Apache Spark pré-configurados usam automaticamente esse cliente personalizado para encaminhar operações de metadados diretamente para o metastore.
Após a configuração, é possível consultar as tabelas criadas pelo Spark diretamente no BigQuery. Essa integração oferece suporte a vários formatos de armazenamento, como Parquet, ORC e Avro, além de mapeamentos de tipo de dados específicos entre o Spark e o BigQuery.
Como o catálogo do Hive se integra aos Google Cloud serviços
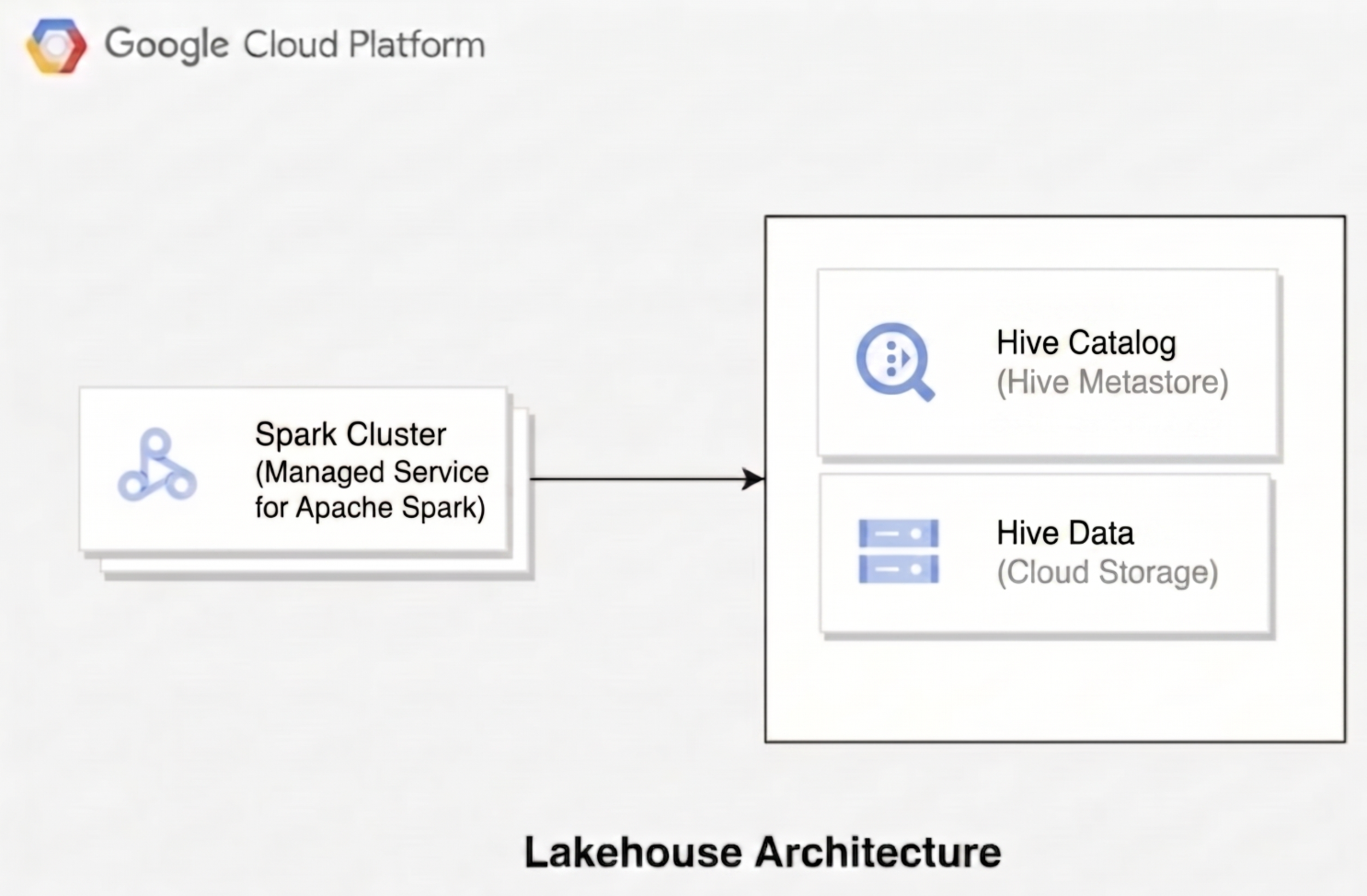
Para entender como o Lakehouse para Apache Iceberg gerencia seus dados, consulte como a arquitetura do catálogo do Hive se integra aos Google Cloud serviços. Em vez de manter metastores auto-hospedados, suas cargas de trabalho de código aberto se conectam ao catálogo de ambientes de execução do Lakehouse para gerenciar definições de banco de dados e tabelas do Hive, enquanto armazenam os arquivos de dados subjacentes diretamente nos diretórios do data warehouse do Cloud Storage.
O diagrama a seguir ilustra como mecanismos de computação, como o Serviço Gerenciado para Apache Spark, usam o catálogo de ambientes de execução do Lakehouse para gerenciar metadados de tabelas ao ler e gravar arquivos de dados subjacentes diretamente no Hive.
Comparação de recursos com o metastore do Hive
A tabela a seguir compara entidades e operações no metastore do Hive e no Lakehouse.
| Entidade ou operação | Metastore do Hive | Catálogo de ambientes de execução do Lakehouse |
|---|---|---|
| Catálogo | ✅ | ✅ |
| Banco de dados (criar, excluir, atualizar) | ✅ | ✅ |
| Tabela (criar, excluir, atualizar) | ✅ | ✅ |
| Partição (adicionar, remover, atualizar) | ✅ | ✅ |
| Privilégios da tabela | ✅ | ✅ (pelo Identity and Access Management, IAM) |
| Privilégios de partição | ✅ | ✅ (pelo IAM) |
| Funções definidas pelo usuário | ✅ | Indisponível |
| Colunas de bucket / inclinação | ✅ | Indisponível |
| Estatísticas de colunas de tabela e partição | ✅ | Indisponível |
| Principais limitações | ✅ | Indisponível |
| Tokens de delegação (Kerberos) | ✅ | Indisponível |
| Privilégios de coluna | ✅ | Indisponível |
| Papéis | ✅ | Indisponível |
| Planos de recursos do gerenciador de cargas de trabalho | ✅ | Indisponível |
| Transações e compactações | ✅ | Indisponível |