
El catálogo de entorno de ejecución de Lakehouse es un metastore unificado y sin servidores que simplifica la administración de los metastores de Hive autoalojados. Esta única capa de metadatos completamente administrada elimina la necesidad de almacenes de metadatos separados para las cargas de trabajo de código abierto. Te permite compartir datos sin problemas en Apache Spark, Apache Hive y BigQuery.
Optimizado para la compatibilidad con ExternalCatalog de Apache Spark, esta integración admite un subconjunto de la interfaz de Hive Metastore. Para ver si tus cargas de trabajo
dependen de funciones no compatibles, como transacciones, compactaciones o Kerberos,
revisa la comparación de funciones y las limitaciones.
Cómo se integra Hive con el catálogo de entorno de ejecución de Lakehouse
El extremo de Hive Metastore administra las tablas estándar de Apache Hive y Spark (con Hive SerDes o fuentes de datos de Spark) en lugar de las tablas de Apache Iceberg. Para simplificar la conexión de tus trabajos de Spark a este extremo, las imágenes de Managed Service para Apache Spark están preconfiguradas con las bibliotecas cliente y las dependencias necesarias.
En la siguiente secuencia, se describe cómo se conecta Spark al metastore:
- Apache Spark se conecta a catálogos de metadatos externos mediante la interfaz estándar
IMetastoreClientde Apache Hive. - El catálogo de entorno de ejecución de Lakehouse implementa un
IMetastoreClientpersonalizado para proporcionar un servicio de metastore completamente administrado para tus metadatos de Spark y Hive. - Los entornos de ejecución preconfigurados de Managed Service para Apache Spark usan automáticamente este cliente personalizado para enrutar las operaciones de metadatos directamente al metastore.
Después de la configuración, puedes consultar las tablas creadas por Spark directamente en BigQuery. Esta integración admite varios formatos de almacenamiento, como Parquet, ORC y Avro, junto con asignaciones de tipos de datos específicos entre Spark y BigQuery.
Cómo se integra el catálogo de Hive con los Google Cloud servicios
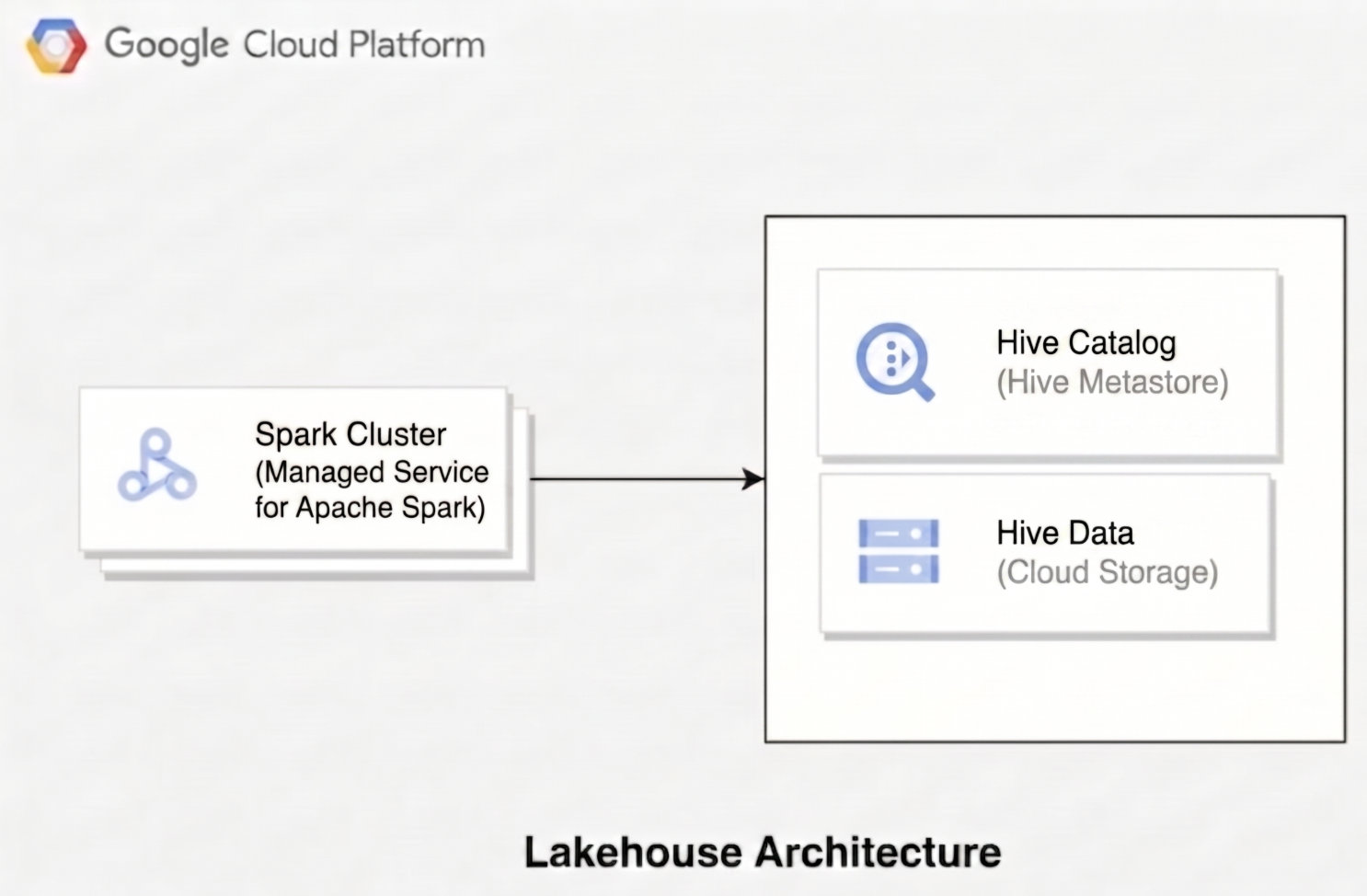
Para comprender cómo Lakehouse para Apache Iceberg administra tus datos, consulta cómo se integra la arquitectura del catálogo de Hive con los servicios Google Cloud . En lugar de mantener metastores autoalojados, tus cargas de trabajo de código abierto se conectan al catálogo de entorno de ejecución de Lakehouse para administrar las definiciones de bases de datos y tablas de Hive, mientras almacenan los archivos de datos subyacentes directamente en los directorios del almacén de Cloud Storage.
En el siguiente diagrama, se ilustra cómo los motores de procesamiento, como Managed Service para Apache Spark, usan el catálogo de entorno de ejecución de Lakehouse para administrar los metadatos de la tabla mientras leen y escriben archivos de datos subyacentes directamente en Hive.
Comparación de funciones con Hive Metastore
En la siguiente tabla, se comparan las entidades y las operaciones en Hive Metastore y Lakehouse.
| Entidad u operación | Hive Metastore | Catálogo de entorno de ejecución de Lakehouse |
|---|---|---|
| Catálogo | ✅ | ✅ |
| Base de datos (crear, borrar, actualizar) | ✅ | ✅ |
| Tabla (crear, borrar, actualizar) | ✅ | ✅ |
| Partición (agregar, quitar, actualizar) | ✅ | ✅ |
| Privilegios de tabla | ✅ | ✅ (a través de Identity and Access Management [IAM]) |
| Privilegios de partición | ✅ | ✅ (a través de IAM) |
| Funciones definidas por el usuario | ✅ | No compatible |
| Agrupación en buckets / sesgo de columnas | ✅ | No compatible |
| Estadísticas de columnas de tablas y particiones | ✅ | No compatible |
| Restricciones clave | ✅ | No compatible |
| Tokens de delegación (Kerberos) | ✅ | No compatible |
| Privilegios de columna | ✅ | No compatible |
| Funciones | ✅ | No compatible |
| Planes de recursos del administrador de cargas de trabajo | ✅ | No compatible |
| Transacciones y compactaciones | ✅ | No compatible |