
The Lakehouse runtime catalog is a serverless, unified metastore that simplifies managing self-hosted Hive metastores. This single, fully managed metadata layer eliminates the need for separate metadata stores for open-source workloads. It lets you seamlessly share data across Apache Spark, Apache Hive, and BigQuery.
Optimized for Apache Spark ExternalCatalog compatibility, this integration
supports a subset of the Hive Metastore interface. To see if your workloads
depend on unsupported features like transactions, compactions, or Kerberos,
review the feature comparison and limitations.
How Hive integrates with the Lakehouse runtime catalog
The Hive metastore endpoint manages standard Apache Hive and Spark tables (using Hive SerDes or Spark data sources) rather than Apache Iceberg tables. To simplify connecting your Spark jobs to this endpoint, Managed Service for Apache Spark images are preconfigured with the necessary client libraries and dependencies.
The following sequence describes how Spark connects to the metastore:
- Apache Spark connects to external metadata catalogs by using the standard
Apache Hive
IMetastoreClientinterface. - The Lakehouse runtime catalog implements a custom
IMetastoreClientto provide a fully managed metastore service for your Spark and Hive metadata. - Preconfigured Managed Service for Apache Spark runtimes automatically use this custom client to route metadata operations directly to the metastore.
After setup, you can query your Spark-created tables directly in BigQuery. This integration supports various storage formats—such as Parquet, ORC, and Avro—along with specific data type mappings between Spark and BigQuery.
How the Hive catalog integrates with Google Cloud services
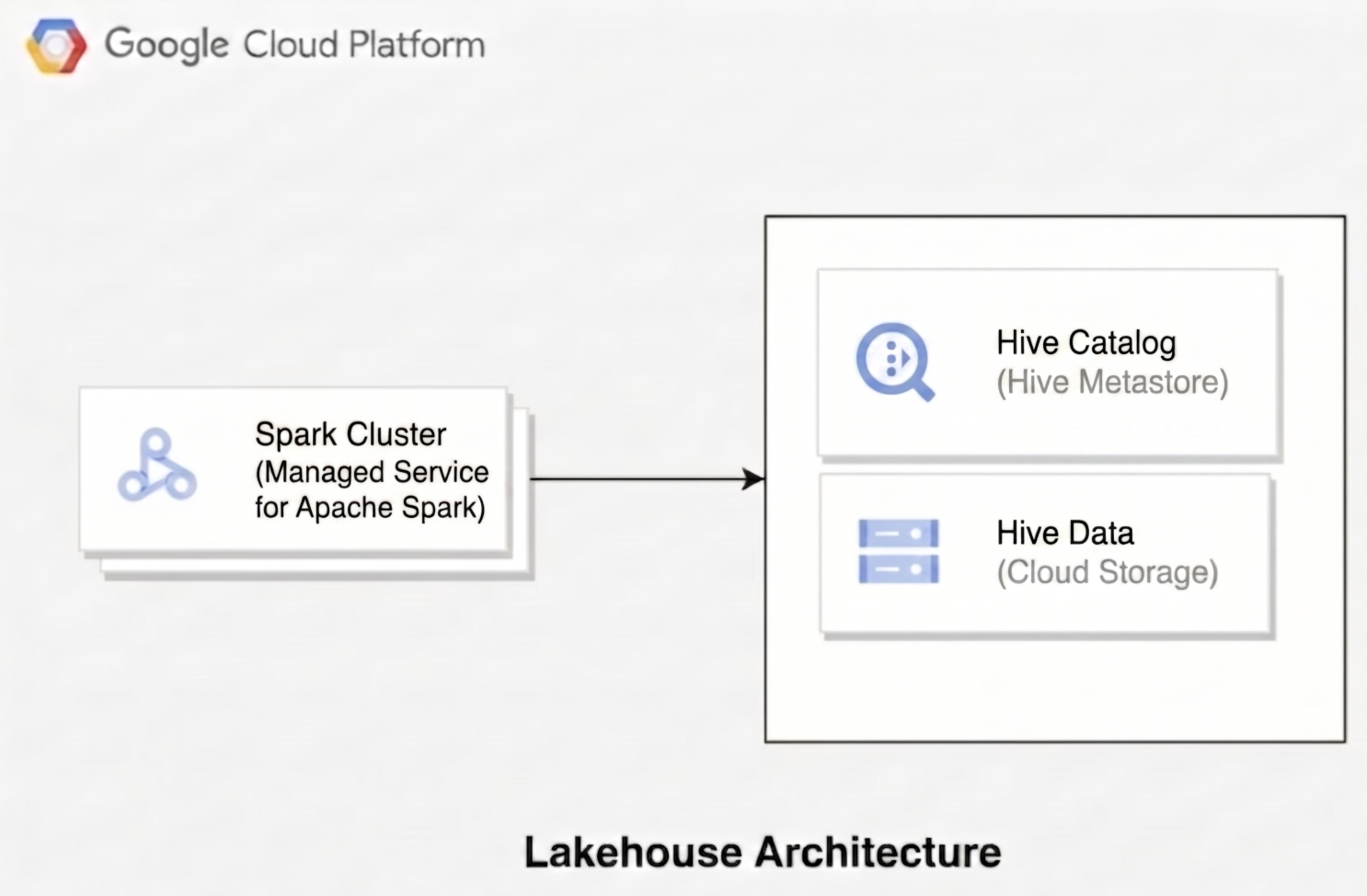
To understand how Lakehouse for Apache Iceberg manages your data, see how the Hive catalog architecture integrates with Google Cloud services. Rather than maintaining self-hosted metastores, your open-source workloads connect to the Lakehouse runtime catalog to manage Hive database and table definitions, while storing the underlying data files directly in Cloud Storage warehouse directories.
The following diagram illustrates how compute engines like Managed Service for Apache Spark use the Lakehouse runtime catalog to manage table metadata while reading and writing underlying data files directly in Hive.
Feature comparison with Hive Metastore
The following table compares entities and operations in Hive Metastore and Lakehouse.
| Entity or operation | Hive Metastore | Lakehouse runtime catalog |
|---|---|---|
| Catalog | ✅ | ✅ |
| Database (create, delete, update) | ✅ | ✅ |
| Table (create, delete, update) | ✅ | ✅ |
| Partition (add, drop, update) | ✅ | ✅ |
| Table privileges | ✅ | ✅ (through Identity and Access Management (IAM)) |
| Partition privileges | ✅ | ✅ (through IAM) |
| User-defined functions | ✅ | Not supported |
| Bucketing / Skewing columns | ✅ | Not supported |
| Table and partition column stats | ✅ | Not supported |
| Key constraints | ✅ | Not supported |
| Delegation tokens (Kerberos) | ✅ | Not supported |
| Column privileges | ✅ | Not supported |
| Roles | ✅ | Not supported |
| Workload manager resource plans | ✅ | Not supported |
| Transactions and compactions | ✅ | Not supported |