
In dieser Anleitung wird beschrieben, wie Sie Large Language Models (LLMs) mit Tensor Processing Units (TPUs) in Google Kubernetes Engine (GKE) mit dem vLLM-Serving-Framework bereitstellen. In diesem Tutorial stellen Sie Llama 3.1 70b bereit, verwenden TPU Trillium und richten horizontales Pod-Autoscaling mit vLLM-Servermesswerten ein.
Dieses Dokument ist ein guter Ausgangspunkt, wenn Sie bei der Bereitstellung und Zugänglichmachung Ihrer KI/ML-Arbeitslasten die detaillierte Kontrolle, Skalierbarkeit, Robustheit, Übertragbarkeit und Kosteneffizienz von verwaltetem Kubernetes benötigen.
Hintergrund
Wenn Sie TPU Trillium in GKE verwenden, können Sie eine robuste, produktionsbereite Bereitstellungslösung mit allen Vorteilen von verwaltetem Kubernetes implementieren, darunter effiziente Skalierbarkeit und höhere Verfügbarkeit. In diesem Abschnitt werden die in diesem Leitfaden verwendeten Schlüsseltechnologien beschrieben.
TPU Trillium
TPUs sind von Google speziell entwickelte anwendungsspezifische integrierte Schaltkreise (Application-Specific Integrated Circuits, ASICs). TPUs werden verwendet, um das maschinelle Lernen und die KI-Modelle zu beschleunigen, die mit Frameworks wie TensorFlow, PyTorch und JAX erstellt wurden. In dieser Anleitung wird TPU Trillium verwendet, die sechste Generation der TPUs von Google.
Bevor Sie TPUs in GKE verwenden, sollten Sie den folgenden Lernpfad durcharbeiten:
vLLM
vLLM ist ein hoch optimiertes Open-Source-Framework für die Bereitstellung von LLMs. vLLM kann den Bereitstellungsdurchsatz auf TPUs über Funktionen wie die folgenden beschleunigen:
- Optimierte Transformer-Implementierung mit PagedAttention.
- Kontinuierliche Batchverarbeitung zur Verbesserung des allgemeinen Bereitstellungsdurchsatzes.
- Tensor-Parallelität und verteilte Bereitstellung auf mehreren TPUs.
Weitere Informationen finden Sie in der vLLM-Dokumentation.
Unterstützte Modelle und Funktionen
Bevor Sie LLMs mit vLLM auf TPUs bereitstellen, sollten Sie die Modellkompatibilität und die unterstützten Funktionen prüfen, um Bereitstellungsprobleme zu vermeiden. Die Bibliothek vllm-project/tpu-inference bietet das erforderliche Backend für die Ausführung von vLLM auf TPUs.
Eine vollständige Liste der unterstützten Modelle und Funktionen finden Sie in der offiziellen Dokumentation:
Cloud Storage FUSE
Cloud Storage FUSE bietet Zugriff von Ihrem GKE-Cluster auf Cloud Storage für Modellgewichte, die sich in Objektspeicher-Buckets befinden. In dieser Anleitung ist der erstellte Cloud Storage-Bucket anfangs leer. Wenn vLLM gestartet wird, lädt GKE das Modell von Hugging Face herunter und speichert die Gewichte im Cloud Storage-Bucket. Beim Neustart des Pods oder beim Hochskalieren der Bereitstellung werden bei nachfolgenden Modellladevorgängen zwischengespeicherte Daten aus dem Cloud Storage-Bucket heruntergeladen. Dabei werden parallele Downloads für eine optimale Leistung genutzt.
Weitere Informationen finden Sie in der Dokumentation zum CSI-Treiber für Cloud Storage FUSE.
Ziele
Diese Anleitung richtet sich an MLOps- oder DevOps-Entwickler oder Plattformadministratoren, die GKE-Orchestrierungsfunktionen zum Bereitstellen von LLMs verwenden möchten.
Diese Anleitung umfasst die folgenden Schritte:
- Erstellen Sie einen GKE-Cluster mit der empfohlenen TPU Trillium-Topologie anhand der Modelleigenschaften.
- Stellen Sie das vLLM-Framework in einem Knotenpool in Ihrem Cluster bereit.
- Verwenden Sie das vLLM-Framework, um Llama 3.1 70b über einen Load-Balancer bereitzustellen.
- Horizontales Pod-Autoscaling mit vLLM-Servermesswerten einrichten
- Modell bereitstellen
Hinweis
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the required API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Sie benötigen die folgenden Rollen für das Projekt:
roles/container.admin,roles/iam.serviceAccountAdmin,roles/iam.securityAdmin,roles/artifactregistry.writer,roles/container.clusterAdminRollen prüfen
-
Rufen Sie in der Google Cloud Console die Seite IAM auf.
IAM aufrufen - Wählen Sie das Projekt aus.
-
Suchen Sie in der Spalte Hauptkonto nach allen Zeilen, in denen Sie oder eine Gruppe, zu der Sie gehören, angegeben sind. Fragen Sie Ihren Administrator, zu welchen Gruppen Sie gehören.
- Prüfen Sie in allen Zeilen, in denen Sie angegeben oder enthalten sind, die Spalte Rolle, um zu sehen, ob die Liste der Rollen die erforderlichen Rollen enthält.
Rollen zuweisen
-
Rufen Sie in der Google Cloud Console die Seite IAM auf.
IAM aufrufen - Wählen Sie das Projekt aus.
- Klicken Sie auf Zugriffsrechte erteilen.
-
Geben Sie im Feld Neue Hauptkonten Ihre Nutzer-ID ein. Das ist in der Regel die E‑Mail-Adresse eines Google-Kontos.
- Klicken Sie auf Rolle auswählen und suchen Sie nach der Rolle.
- Klicken Sie auf Weitere Rolle hinzufügen, wenn Sie weitere Rollen zuweisen möchten.
- Klicken Sie auf Speichern.
-
- Erstellen Sie ein Hugging Face-Konto, falls Sie noch keines haben.
- Prüfen Sie, ob Ihr Projekt ein ausreichendes Kontingent für Cloud TPU in GKE hat.
Umgebung vorbereiten
In diesem Abschnitt stellen Sie die Ressourcen bereit, die Sie zum Bereitstellen von vLLM und des Modells benötigen.
Zugriff auf das Modell erhalten
Sie müssen die Einwilligungsvereinbarung unterzeichnen, um Llama 3.1 70b im Hugging Face-Repository verwenden zu können.
Zugriffstoken erstellen
Generieren Sie ein neues Hugging Face-Token, falls Sie noch keines haben:
- Klicken Sie auf Profil > Einstellungen > Zugriffstokens.
- Wählen Sie Neues Token aus.
- Geben Sie einen Namen Ihrer Wahl und eine Rolle von mindestens
Readan. - Wählen Sie Token generieren aus.
Cloud Shell starten
In dieser Anleitung verwenden Sie Cloud Shell zum Verwalten von Ressourcen, die inGoogle Cloudgehostet werden. Die Software, die Sie für diese Anleitung benötigen, ist in Cloud Shell vorinstalliert, einschließlich kubectl und der gcloud CLI.
So richten Sie Ihre Umgebung mit Cloud Shell ein:
Starten Sie in der Google Cloud Console eine Cloud Shell-Sitzung. Klicken Sie dazu in der Google Cloud Console auf
 Cloud Shell aktivieren. Dadurch wird im unteren Bereich der Google Cloud Console eine Sitzung gestartet.
Cloud Shell aktivieren. Dadurch wird im unteren Bereich der Google Cloud Console eine Sitzung gestartet.Legen Sie die Standardumgebungsvariablen fest:
gcloud config set project PROJECT_ID && \ gcloud config set billing/quota_project PROJECT_ID && \ export PROJECT_ID=$(gcloud config get project) && \ export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)") && \ export CLUSTER_NAME=CLUSTER_NAME && \ export CONTROL_PLANE_LOCATION=CONTROL_PLANE_LOCATION && \ export ZONE=ZONE && \ export HF_TOKEN=HUGGING_FACE_TOKEN && \ export CLUSTER_VERSION=CLUSTER_VERSION && \ export GSBUCKET=GSBUCKET && \ export KSA_NAME=KSA_NAME && \ export NAMESPACE=NAMESPACEErsetzen Sie die folgenden Werte:
- PROJECT_ID : Ihre Google Cloud Projekt-ID.
- CLUSTER_NAME : der Name Ihres GKE-Cluster.
- CONTROL_PLANE_LOCATION: die Compute Engine-Region der Steuerungsebene des Clusters. Geben Sie eine Region an, die TPU Trillium (v6e) unterstützt.
- ZONE : Eine Zone, die TPU Trillium (v6e) unterstützt.
- CLUSTER_VERSION : Eine GKE-Version, die TPU Trillium (v6e) unterstützt. Weitere Informationen finden Sie unter TPU-Verfügbarkeit in GKE prüfen.
- GSBUCKET : Der Name des Cloud Storage-Bucket, der für Cloud Storage FUSE verwendet werden soll.
- KSA_NAME : Der Name des Kubernetes-Dienstkontos, das für den Zugriff auf Cloud Storage-Buckets verwendet wird. Für Cloud Storage FUSE ist Bucket-Zugriff erforderlich.
- NAMESPACE : der Kubernetes-Namespace, in dem Sie die vLLM-Assets bereitstellen möchten.
GKE-Cluster erstellen
Sie können LLMs auf TPUs in einem GKE-Cluster im Autopilot- oder Standardmodus bereitstellen. Für eine vollständig verwaltete Kubernetes-Umgebung empfehlen wir die Verwendung eines Autopilot-Clusters. Informationen zum Auswählen des GKE-Betriebsmodus, der für Ihre Arbeitslasten am besten geeignet ist, finden Sie unter GKE-Betriebsmodus auswählen.
Autopilot
Erstellen Sie einen GKE Autopilot-Cluster:
gcloud container clusters create-auto ${CLUSTER_NAME} \ --cluster-version=${CLUSTER_VERSION} \ --location=${CONTROL_PLANE_LOCATION}
Standard
GKE-Standardcluster erstellen:
gcloud container clusters create ${CLUSTER_NAME} \ --project=${PROJECT_ID} \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --cluster-version=${CLUSTER_VERSION} \ --workload-pool=${PROJECT_ID}.svc.id.goog \ --addons GcsFuseCsiDriver
Mit diesem Befehl wird ein GKE-Standardcluster erstellt und die Workload Identity-Föderation sowie der CSI-Treiber für Cloud Storage FUSE werden aktiviert. Wenn Sie einen vorhandenen Cluster verwenden, muss der CSI-Treiber für Cloud Storage FUSE aktiviert sein.
So erstellen Sie einen TPU-Slice-Knotenpool:
gcloud container node-pools create tpunodepool \ --location=${CONTROL_PLANE_LOCATION} \ --node-locations=${ZONE} \ --num-nodes=1 \ --machine-type=ct6e-standard-8t \ --cluster=${CLUSTER_NAME} \ --enable-autoscaling --total-min-nodes=1 --total-max-nodes=2GKE erstellt die folgenden Ressourcen für das LLM:
- Ein GKE Standard-Cluster, der die Workload Identity-Föderation für GKE verwendet und in dem der CSI-Treiber für Cloud Storage FUSE aktiviert ist.
- Ein TPU-Trillium-Knotenpool mit dem Maschinentyp
ct6e-standard-8t. Dieser Knotenpool hat einen Knoten, acht TPU-Chips und aktiviertes Autoscaling.
kubectl für die Kommunikation mit Ihrem Cluster konfigurieren
Führen Sie den folgenden Befehl aus, um kubectl für die Kommunikation mit Ihrem Cluster zu konfigurieren:
gcloud container clusters get-credentials ${CLUSTER_NAME} --location=${CONTROL_PLANE_LOCATION}
Kubernetes-Secret für Hugging Face-Anmeldedaten erstellen
Namespace erstellen Wenn Sie den Namespace
defaultverwenden, können Sie diesen Schritt überspringen:kubectl create namespace ${NAMESPACE}Erstellen Sie ein Kubernetes-Secret, das das Hugging Face-Token enthält, indem Sie den folgenden Befehl ausführen:
kubectl create secret generic hf-secret \ --from-literal=hf_api_token=${HF_TOKEN} \ --namespace ${NAMESPACE}
Cloud Storage-Bucket erstellen
Führen Sie in Cloud Shell den folgenden Befehl aus:
gcloud storage buckets create gs://${GSBUCKET} \
--uniform-bucket-level-access
Dadurch wird ein Cloud Storage-Bucket zum Speichern der Modelldateien erstellt, die Sie von Hugging Face herunterladen.
Kubernetes-Dienstkonto für den Zugriff auf den Bucket einrichten
Erstellen Sie das Kubernetes-Dienstkonto:
kubectl create serviceaccount ${KSA_NAME} --namespace ${NAMESPACE}Gewähren Sie dem Kubernetes-Dienstkonto Lese-/Schreibzugriff, um auf den Cloud Storage-Bucket zuzugreifen:
gcloud storage buckets add-iam-policy-binding gs://${GSBUCKET} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"Alternativ können Sie Lese-/Schreibzugriff auf alle Cloud Storage-Buckets im Projekt gewähren:
gcloud projects add-iam-policy-binding ${PROJECT_ID} \ --member "principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/${NAMESPACE}/sa/${KSA_NAME}" \ --role "roles/storage.objectUser"GKE erstellt die folgenden Ressourcen für das LLM:
- Ein Cloud Storage-Bucket zum Speichern des heruntergeladenen Modells und des Kompilierungscache. Ein Cloud Storage FUSE-CSI-Treiber liest den Inhalt des Buckets.
- Volumes mit aktiviertem Datei-Caching und die Funktion paralleler Download von Cloud Storage FUSE.
Best Practice: Verwenden Sie einen Dateicache, der von
tmpfsoderHyperdisk / Persistent Diskunterstützt wird, je nach erwarteter Größe des Modellinhalts, z. B. Gewichtsdateien. In dieser Anleitung verwenden Sie einen durch RAM unterstützten Cloud Storage FUSE-Dateicache.
vLLM-Modellserver bereitstellen
In dieser Anleitung wird eine Kubernetes-Bereitstellung verwendet, um den vLLM-Modellserver bereitzustellen. Ein Deployment ist ein Kubernetes-API-Objekt, mit dem Sie mehrere Replikate von Pods ausführen können, die auf die Knoten in einem Cluster verteilt sind.
Sehen Sie sich das folgende Deployment-Manifest an, das als
vllm-llama3-70b.yamlgespeichert ist und ein einzelnes Replikat verwendet:Wenn Sie das Deployment auf mehrere Replikate hochskalieren, führen die gleichzeitigen Schreibvorgänge in
VLLM_XLA_CACHE_PATHzum FehlerRuntimeError: filesystem error: cannot create directories. Sie haben zwei Möglichkeiten, diesen Fehler zu vermeiden:Entfernen Sie den XLA-Cache-Speicherort, indem Sie den folgenden Block aus dem Deployment-YAML entfernen. Das bedeutet, dass alle Replikate den Cache neu kompilieren.
- name: VLLM_XLA_CACHE_PATH value: "/data"Skalieren Sie die Bereitstellung auf
1und warten Sie, bis das erste Replikat bereit ist und in den XLA-Cache geschrieben wird. Skalieren Sie dann auf zusätzliche Replikate. So können die verbleibenden Replikate den Cache lesen, ohne zu versuchen, ihn zu schreiben.
Wenden Sie das Manifest mit dem folgenden Befehl an:
kubectl apply -f vllm-llama3-70b.yaml -n ${NAMESPACE}So rufen Sie die Logs des laufenden Modellservers auf:
kubectl logs -f -l app=vllm-tpu -n ${NAMESPACE}Die Ausgabe sollte in etwa so aussehen:
INFO: Started server process [1] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
Modell bereitstellen
Führen Sie den folgenden Befehl aus, um die externe IP-Adresse des VLLM-Dienstes abzurufen:
export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE})Mit dem Modell über
curlinteragieren:curl http://$vllm_service:8000/v1/completions \ -H "Content-Type: application/json" \ -d '{ "model": "meta-llama/Llama-3.1-70B", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0 }'Die Ausgabe sollte in etwa so aussehen:
{"id":"cmpl-6b4bb29482494ab88408d537da1e608f","object":"text_completion","created":1727822657,"model":"meta-llama/Llama-3-8B","choices":[{"index":0,"text":" top holiday destination featuring scenic beauty and","logprobs":null,"finish_reason":"length","stop_reason":null,"prompt_logprobs":null}],"usage":{"prompt_tokens":5,"total_tokens":12,"completion_tokens":7}}
Benutzerdefiniertes Autoscaling einrichten
In diesem Abschnitt richten Sie das horizontale Pod-Autoscaling mit benutzerdefinierten Prometheus-Messwerten ein. Sie verwenden die Google Cloud Managed Service for Prometheus-Messwerte vom vLLM-Server.
Weitere Informationen finden Sie unter Google Cloud Managed Service for Prometheus. Diese Option sollte im GKE-Cluster standardmäßig aktiviert sein.
Richten Sie den Stackdriver-Adapter für benutzerdefinierte Messwerte in Ihrem Cluster ein:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yamlFügen Sie dem Dienstkonto, das vom Stackdriver-Adapter für benutzerdefinierte Messwerte verwendet wird, die Rolle „Monitoring-Betrachter“ hinzu:
gcloud projects add-iam-policy-binding projects/${PROJECT_ID} \ --role roles/monitoring.viewer \ --member=principal://iam.googleapis.com/projects/${PROJECT_NUMBER}/locations/global/workloadIdentityPools/${PROJECT_ID}.svc.id.goog/subject/ns/custom-metrics/sa/custom-metrics-stackdriver-adapterSpeichern Sie das folgende Manifest als
vllm_pod_monitor.yaml:Wenden Sie es auf den Cluster an:
kubectl apply -f vllm_pod_monitor.yaml -n ${NAMESPACE}
Last auf dem vLLM-Endpunkt erzeugen
Erstellen Sie Last für den vLLM-Server, um zu testen, wie GKE mit einem benutzerdefinierten vLLM-Messwert skaliert.
Führen Sie ein Bash-Skript (
load.sh) aus, umNparallele Anfragen an den vLLM-Endpunkt zu senden:#!/bin/bash N=PARALLEL_PROCESSES export vllm_service=$(kubectl get service vllm-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n ${NAMESPACE}) for i in $(seq 1 $N); do while true; do curl http://$vllm_service:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "meta-llama/Llama-3.1-70B", "prompt": "Write a story about san francisco", "max_tokens": 1000, "temperature": 0}' done & # Run in the background done waitErsetzen Sie PARALLEL_PROCESSES durch die Anzahl der parallelen Prozesse, die Sie ausführen möchten.
Führen Sie das Bash-Skript aus:
chmod +x load.sh nohup ./load.sh &
Prüfen, ob Google Cloud Managed Service for Prometheus die Messwerte aufnimmt
Nachdem Google Cloud Managed Service for Prometheus die Messwerte erfasst hat und Sie den vLLM-Endpunkt belasten, können Sie die Messwerte in Cloud Monitoring ansehen.
Wechseln Sie in der Google Cloud Console zur Seite Metrics Explorer.
Klicken Sie auf < > PromQL.
Geben Sie die folgende Abfrage ein, um Traffic-Messwerte zu beobachten:
vllm:num_requests_waiting{cluster='CLUSTER_NAME'}
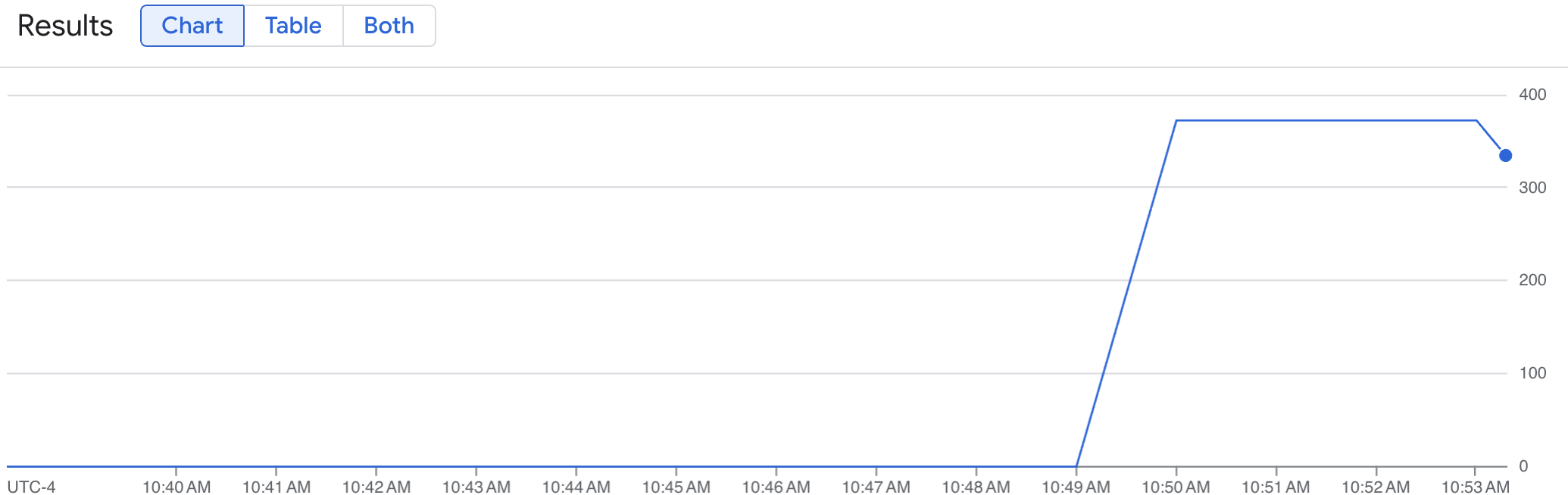
Ein Liniendiagramm zeigt den vLLM-Messwert (num_requests_waiting) im Zeitverlauf. Der vLLM-Messwert wird von 0 (vor dem Laden) auf einen Wert (nach dem Laden) skaliert. Dieses Diagramm bestätigt, dass Ihre vLLM-Messwerte in Google Cloud Managed Service for Prometheus aufgenommen werden. Das folgende Beispiel zeigt einen Startwert für die Vorablast von 0, der innerhalb einer Minute einen maximalen Wert nach dem Laden von fast 400 erreicht.
Konfiguration für horizontales Pod-Autoscaling bereitstellen
Bei der Entscheidung, auf welchen Messwert das Autoscaling erfolgen soll, empfehlen wir die folgenden Messwerte für vLLM TPU:
num_requests_waiting: Diese Messgröße bezieht sich auf die Anzahl der Anfragen, die in der Warteschlange des Modellservers warten. Diese Zahl beginnt spürbar zu steigen, wenn der KV-Cache voll ist.gpu_cache_usage_perc: Dieser Messwert bezieht sich auf die KV-Cache-Nutzung, die direkt mit der Anzahl der Anfragen korreliert, die für einen bestimmten Inferenzzyklus auf dem Modellserver verarbeitet werden. Dieser Messwert funktioniert auf GPUs und TPUs gleich, ist aber an das GPU-Benennungsschema gebunden.
Wir empfehlen die Verwendung von num_requests_waiting, wenn Sie den Durchsatz und die Kosten optimieren möchten und Ihre Latenzziele mit dem maximalen Durchsatz Ihres Modellservers erreicht werden können.
Wir empfehlen die Verwendung von gpu_cache_usage_perc für latenzempfindliche Arbeitslasten, bei denen die warteschlangenbasierte Skalierung nicht schnell genug ist, um Ihre Anforderungen zu erfüllen.
Weitere Informationen finden Sie unter Best Practices für das Autoscaling von Inferenzen für LLM-Arbeitslasten (Large Language Model) mit TPUs.
Wenn Sie ein averageValue-Ziel für Ihre HPA-Konfiguration auswählen, müssen Sie es experimentell ermitteln. Im Blogpost Save on GPUs: Smarter autoscaling for your GKE inferencing workloads (GPUs sparen: Intelligenteres Autoscaling für Ihre GKE-Inferenzarbeitslasten) finden Sie weitere Ideen zur Optimierung dieses Teils. Der in diesem Blogpost verwendete profile-generator funktioniert auch für vLLM TPU.
In der folgenden Anleitung stellen Sie Ihre HPA-Konfiguration mit dem Messwert num_requests_waiting bereit. Zu Demonstrationszwecken legen Sie den Messwert auf einen niedrigen Wert fest, damit die HPA-Konfiguration Ihre vLLM-Replikate auf zwei skaliert. So stellen Sie die Konfiguration des horizontalen Pod-Autoscalings mit num_requests_waiting bereit:
Speichern Sie das folgende Manifest als
vllm-hpa.yaml:Die vLLM-Messwerte in Google Cloud Managed Service for Prometheus folgen dem Format
vllm:metric_name.Best Practice: Verwenden Sie
num_requests_waitingzum Skalieren des Durchsatzes. Verwenden Siegpu_cache_usage_percfür latenzempfindliche TPU-Anwendungsfälle.Stellen Sie die Konfiguration für das horizontale Pod-Autoscaling bereit:
kubectl apply -f vllm-hpa.yaml -n ${NAMESPACE}GKE plant die Bereitstellung eines weiteren Pods, wodurch der Autoscaler für Knotenpools einen zweiten Knoten hinzufügt, bevor die zweite vLLM-Replica bereitgestellt wird.
Beobachten Sie den Fortschritt des Pod-Autoscalings:
kubectl get hpa --watch -n ${NAMESPACE}Die Ausgabe sieht etwa so aus:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE vllm-hpa Deployment/vllm-tpu <unknown>/10 1 2 0 6s vllm-hpa Deployment/vllm-tpu 34972m/10 1 2 1 16s vllm-hpa Deployment/vllm-tpu 25112m/10 1 2 2 31s vllm-hpa Deployment/vllm-tpu 35301m/10 1 2 2 46s vllm-hpa Deployment/vllm-tpu 25098m/10 1 2 2 62s vllm-hpa Deployment/vllm-tpu 35348m/10 1 2 2 77sWarten Sie 10 Minuten und wiederholen Sie die Schritte im Abschnitt Prüfen, ob Google Cloud Managed Service for Prometheus die Messwerte aufnimmt. Google Cloud Managed Service for Prometheus erfasst jetzt die Messwerte von beiden vLLM-Endpunkten.
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Bereitgestellte Ressourcen löschen
Mit den folgenden Befehlen vermeiden Sie, dass Ihrem Google Cloud -Konto die in dieser Anleitung erstellten Ressourcen in Rechnung gestellt werden:
ps -ef | grep load.sh | awk '{print $2}' | xargs -n1 kill -9
gcloud container clusters delete ${CLUSTER_NAME} \
--location=${CONTROL_PLANE_LOCATION}
Nächste Schritte
- Mehr über TPUs in GKE erfahren
- Weitere Informationen zu den verfügbaren Messwerten zum Einrichten des horizontalen Pod-Autoscalers
- Sehen Sie sich das GitHub-Repository und die Dokumentation zu vLLM an.