
En este documento se muestra cómo acelerar la carga de los pesos de modelos de IA grandes desde Cloud Storage mediante Run:ai Model Streamer con el servidor de inferencia vLLM en Google Kubernetes Engine (GKE).
La solución de este documento presupone que ya has cargado tu modelo de IA y sus pesos en formato safetensors en un segmento de Cloud Storage.
Si añades la marca --load-format=runai_streamer a tu despliegue de vLLM, puedes usar Run:ai Model Streamer para mejorar la eficiencia de descarga de modelos de tus cargas de trabajo de IA en GKE.
Este documento está dirigido a los siguientes usuarios:
- Ingenieros de aprendizaje automático (ML) que necesiten cargar modelos de IA grandes desde el almacenamiento de objetos en nodos de GPU o TPU lo más rápido posible.
- Administradores y operadores de plataformas que automatizan y optimizan la infraestructura de servicio de modelos en GKE.
- Arquitectos de la nube que evalúan herramientas especializadas de carga de datos para cargas de trabajo de IA y aprendizaje automático.
Para obtener más información sobre los roles habituales y las tareas de ejemplo que se mencionan en el contenido, consulta Roles y tareas habituales de los usuarios de GKE. Google Cloud
Información general
La solución descrita en este documento usa tres componentes principales (Run:ai Model Streamer, vLLM y el formato de archivo safetensors) para acelerar el proceso de carga de los pesos del modelo de Cloud Storage en los nodos de GPU.
Run:ai Model Streamer
Run:ai Model Streamer es un SDK de Python de código abierto que acelera la carga de modelos de IA grandes en GPUs. Transmite los pesos del modelo directamente desde el almacenamiento, como los segmentos de Cloud Storage, a la memoria de tu GPU. El streamer de modelos es especialmente adecuado para acceder a archivos safetensors ubicados en Cloud Storage.
safetensors
safetensors es un formato de archivo para almacenar tensores, las estructuras de datos principales de los modelos de IA, de una forma que mejora tanto la seguridad como la velocidad. safetensors se ha diseñado como alternativa al formato pickle de Python y permite que los tiempos de carga sean rápidos gracias a un enfoque de copia cero. De esta forma, los tensores se pueden acceder directamente desde la fuente sin necesidad de cargar primero todo el archivo en la memoria local.
vLLM
vLLM es una biblioteca de código abierto para la inferencia y el servicio de LLMs. Es un servidor de inferencia de alto rendimiento optimizado para cargar rápidamente modelos de IA de gran tamaño. En este documento, vLLM es el motor principal que ejecuta tu modelo de IA en GKE y gestiona las solicitudes de inferencia entrantes. La compatibilidad con la autenticación integrada de Model Streamer de Run:ai para Cloud Storage requiere la versión 0.11.1 de vLLM o una posterior.
Cómo acelera la carga de modelos Run:ai Model Streamer
Cuando inicias una aplicación de IA basada en LLMs para la inferencia, suele haber un retraso considerable antes de que el modelo esté listo para usarse. Este retraso, conocido como arranque en frío, se produce porque el archivo del modelo, que ocupa varios gigabytes, debe descargarse por completo desde una ubicación de almacenamiento, como un segmento de Cloud Storage, al disco local de tu máquina. El archivo se carga en la memoria de la GPU. Durante este periodo de carga, la GPU cara está inactiva, lo que resulta ineficiente y costoso.
En lugar de descargar el modelo y, después, cargarlo, el streamer de modelos transmite el modelo directamente desde Cloud Storage a la memoria de la GPU. El streamer usa un backend de alto rendimiento para leer varias partes del modelo, llamadas tensores, en paralelo. Leer tensores simultáneamente es significativamente más rápido que cargar el archivo de forma secuencial.
Información general sobre la arquitectura
Run:ai Model Streamer se integra con vLLM en GKE para acelerar la carga de modelos transmitiendo los pesos de los modelos directamente desde Cloud Storage a la memoria de la GPU, sin pasar por el disco local.
En el siguiente diagrama se muestra esta arquitectura:
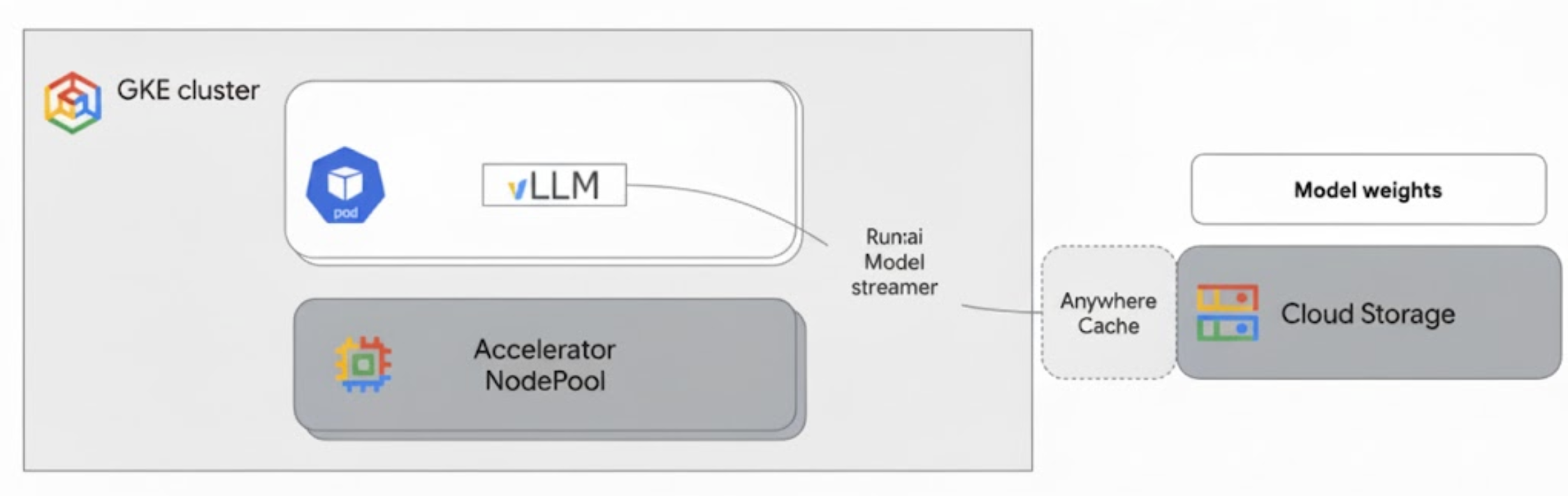
Esta arquitectura incluye los siguientes componentes y flujo de trabajo:
- Segmento de Cloud Storage: almacena los pesos del modelo de IA en formato
safetensors. - Pod de GKE con GPU: ejecuta el servidor de inferencia de vLLM.
- Servidor de inferencia de vLLM: configurado con la marca
--load-format=runai_streamer, que habilita la función de transmisión de modelos. - Run:ai Model Streamer: cuando se inicia vLLM, el streamer de modelos lee los pesos del modelo de la ruta
gs://especificada en el segmento de Cloud Storage. En lugar de descargar archivos en el disco, transmite datos de tensor directamente a la memoria de la GPU del pod de GKE, donde vLLM puede acceder a ellos inmediatamente para realizar inferencias. - Caché en cualquier lugar de Cloud Storage (opcional): si está habilitada, Caché en cualquier lugar almacena en caché los datos del segmento en la misma zona que los nodos de GKE, lo que acelera aún más el acceso a los datos para el streamer.
Ventajas
- Tiempos de arranque en frío reducidos: el streamer de modelos reduce significativamente el tiempo que tardan los modelos en iniciarse. Carga los pesos del modelo hasta seis veces más rápido que los métodos convencionales. Para obtener más información, consulta las comparativas de Run:ai Model Streamer.
- Utilización mejorada de la GPU: al minimizar los retrasos en la carga de modelos, las GPUs pueden dedicar más tiempo a las tareas de inferencia reales, lo que aumenta la eficiencia general y la capacidad de procesamiento.
- Flujo de trabajo optimizado: la solución descrita en este documento se integra con GKE, lo que permite que los servidores de inferencia, como vLLM o SGLang, accedan directamente a los modelos de los contenedores de Cloud Storage.
Antes de empezar
Asegúrate de completar los siguientes requisitos previos.
Seleccionar o crear un proyecto y habilitar las APIs
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Configurar Cloud Shell
En este documento se usan la CLI de Google Cloud y los comandos kubectl para crear y gestionar los recursos necesarios para esta solución. Para ejecutar estos comandos en Cloud Shell, haz clic en Activar Cloud Shell en la parte superior de la consola Google Cloud .
In the Google Cloud console, activate Cloud Shell.
También puedes instalar e inicializar la CLI de gcloud en tu entorno de shell local para ejecutar los comandos. Si quieres usar un terminal shell local, ejecuta el comando gcloud auth login para autenticarte con Google Cloud.
Otorgar roles de gestión de identidades y accesos
Asegúrate de que tu Google Cloud cuenta tenga los siguientes roles de gestión de identidades y accesos en tu proyecto para poder crear un clúster de GKE y gestionar Cloud Storage:
roles/container.adminroles/storage.admin
Para asignar estos roles, ejecuta los siguientes comandos:
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/container.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/storage.admin"
Sustituye PROJECT_ID por el ID del proyecto.
Prepara tu entorno
En esta sección se explica cómo configurar el clúster de GKE y los permisos para acceder al modelo en Cloud Storage.
Crear un clúster de GKE con GPUs
Run:ai Model Streamer se puede usar con clústeres de Autopilot y Standard de GKE. Elige el modo de clúster que mejor se adapte a tus necesidades.
Define las variables del nombre del proyecto y del clúster:
export PROJECT_ID=PROJECT_ID export CLUSTER_NAME=CLUSTER_NAMEHaz los cambios siguientes:
PROJECT_ID: tu ID de proyecto Google Cloud . Para encontrar el ID de tu proyecto, ejecuta el comandogcloud config get-value project.CLUSTER_NAME: el nombre del clúster. Por ejemplo,run-ai-test.
Crea un clúster de Autopilot o Standard:
Autopilot
Para crear un clúster de GKE Autopilot, sigue estos pasos:
Define la región de tu clúster:
export REGION=REGIONSustituye
REGIONpor la región en la que quieras crear el clúster. Para obtener un rendimiento óptimo, usa la misma región que tu segmento de Cloud Storage.Crea el clúster:
gcloud container clusters create-auto $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$REGION
Los clústeres Autopilot aprovisionan nodos automáticamente en función de los requisitos de las cargas de trabajo. Cuando despliegues el servidor vLLM en un paso posterior, Autopilot aprovisionará los nodos de GPU si es necesario. Para obtener más información, consulta Información sobre la creación automática de grupos de nodos.
Estándar
Sigue estos pasos para crear un clúster estándar de GKE:
Define la zona de tu clúster:
export ZONE=ZONESustituye
ZONEpor la zona en la que quieras crear el clúster. Para obtener un rendimiento óptimo, utiliza una zona de la misma región que tu segmento de Cloud Storage.Crea el clúster:
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --zone=$ZONE \ --workload-pool=$PROJECT_ID.svc.id.goog \ --num-nodes=1Crea un pool de nodos con una máquina G2 (GPU NVIDIA L4):
gcloud container node-pools create g2-gpu-pool \ --cluster=$CLUSTER_NAME \ --zone=$ZONE \ --machine-type=g2-standard-16 \ --num-nodes=1 \ --accelerator=type=nvidia-l4
Configurar Workload Identity Federation para GKE
Configura Workload Identity Federation para GKE para permitir que tus cargas de trabajo de GKE accedan de forma segura al modelo de tu segmento de Cloud Storage.
Define variables para tu cuenta de servicio y espacio de nombres de Kubernetes:
export KSA_NAME=KSA_NAME export NAMESPACE=NAMESPACEHaz los cambios siguientes:
NAMESPACE: el espacio de nombres en el que quieres que se ejecuten tus cargas de trabajo. Asegúrate de usar el mismo espacio de nombres para crear todos los recursos de este documento.KSA_NAME: el nombre de la cuenta de servicio de Kubernetes que puede usar tu pod para autenticarse en las APIs. Google Cloud
Crea un espacio de nombres de Kubernetes:
kubectl create namespace $NAMESPACECrea una cuenta de servicio de Kubernetes (KSA):
kubectl create serviceaccount $KSA_NAME \ --namespace=$NAMESPACEConcede a tu KSA los permisos necesarios:
Define las variables de entorno:
export BUCKET_NAME=BUCKET_NAME export PROJECT_ID=PROJECT_ID export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID \ --format 'get(projectNumber)')Haz los cambios siguientes:
BUCKET_NAME: el nombre del segmento de Cloud Storage que contiene los archivossafetensors.PROJECT_ID: tu ID de proyecto Google Cloud .
Los valores
PROJECT_NUMBER,PROJECT_ID,NAMESPACEyKSA_NAMEse usarán para crear el identificador principal de Workload Identity Federation for GKE de tu proyecto en los pasos siguientes.Asigna el rol
roles/storage.bucketViewera tu KSA para ver los objetos de tu segmento de Cloud Storage:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.bucketViewer"Concede el rol
roles/storage.objectUsera tu KSA para leer, escribir y eliminar objetos de tu segmento de Cloud Storage:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.objectUser"
Ahora has configurado un clúster de GKE con GPUs y la federación de identidades de carga de trabajo para GKE, lo que concede a una cuenta de servicio de Kubernetes los permisos necesarios para acceder a tu modelo de IA en Cloud Storage. Una vez que tengas el clúster y los permisos, podrás desplegar el servidor de inferencia de vLLM, que usará esta cuenta de servicio para transmitir los pesos del modelo con Run:ai Model Streamer.
Desplegar vLLM con Run:ai Model Streamer
Despliega un pod que ejecute el servidor compatible con OpenAI de vLLM y que esté configurado con la marca --load-format=runai_streamer para usar Run:ai Model Streamer. La versión de vLLM debe ser la 0.11.1 o una posterior.
El siguiente manifiesto de ejemplo muestra una configuración de vLLM con el streamer de modelos habilitado para un modelo de tamaño pequeño, como gemma-2-9b-it, que usa una sola GPU NVIDIA L4.
- Si usas un modelo grande que requiere varias GPUs, aumenta el valor de
--tensor-parallel-sizeal número de GPUs necesario. - La marca
--model-loader-extra-config={"distributed":true}permite la carga distribuida de los pesos del modelo y es un ajuste recomendado para mejorar el rendimiento de la carga del modelo desde el almacenamiento de objetos.
Para obtener más información, consulta Paralelismo de tensores y Parámetros ajustables.
Guarda el siguiente archivo de manifiesto como
vllm-deployment.yaml. El manifiesto se ha diseñado para ofrecer flexibilidad tanto en los clústeres Autopilot como en los Estándar.apiVersion: apps/v1 kind: Deployment metadata: name: vllm-streamer-deployment namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: vllm-streamer template: metadata: labels: app: vllm-streamer spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-openai:v0.11.1 command: - python3 - -m - vllm.entrypoints.openai.api_server args: - --model=gs://BUCKET_NAME/PATH_TO_MODEL - --load-format=runai_streamer - --model-loader-extra-config={"distributed":true} - --host=0.0.0.0 - --port=8000 - --disable-log-requests - --tensor-parallel-size=1 ports: - containerPort: 8000 name: api # startupProbe allows for longer startup times for large models startupProbe: httpGet: path: /health port: 8000 failureThreshold: 60 # 60 * 10s = 10 minutes timeout periodSeconds: 10 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health port: 8000 failureThreshold: 3 periodSeconds: 10 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" volumeMounts: - mountPath: /dev/shm name: dshm nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 volumes: - emptyDir: medium: Memory name: dshmHaz los cambios siguientes:
NAMESPACE: tu espacio de nombres de Kubernetes.KSA_NAME: el nombre de tu cuenta de servicio de Kubernetes.BUCKET_NAME: el nombre de tu segmento de Cloud Storage.PATH_TO_MODEL: la ruta al directorio del modelo en el contenedor. Por ejemplo,models/my-llama.
Aplica el manifiesto para crear la implementación:
kubectl create -f vllm-deployment.yaml
Puedes generar más manifiestos de vLLM con la herramienta Guía de inicio rápido de inferencia de GKE.
Verificar la implementación
Comprueba el estado del despliegue:
kubectl get deployments -n NAMESPACEObtén el nombre del pod:
kubectl get pods -n NAMESPACE | grep vllm-streamerAnota el nombre del pod que empieza por
vllm-streamer-deployment.Para comprobar si el streamer de modelos descarga el modelo y los pesos, consulta los registros de Pod:
kubectl logs -f POD_NAME -n NAMESPACESustituye
POD_NAMEpor el nombre del pod del paso anterior. Los registros de streaming correctos tienen un aspecto similar al siguiente:[RunAI Streamer] Overall time to stream 15.0 GiB of all files: 13.4s, 1.1 GiB/s
Opcional: Mejora el rendimiento con Anywhere Cache
Cloud Storage Anywhere Cache puede acelerar aún más la carga de modelos almacenando en caché los datos más cerca de tus nodos de GKE. El almacenamiento en caché es especialmente útil cuando se escalan varios nodos en la misma zona.
Habilita Anywhere Cache para un segmento de Cloud Storage específico en una zona Google Cloud concreta. Para mejorar el rendimiento, la zona de la caché debe coincidir con la zona en la que se ejecutan tus pods de inferencia de GKE. Tu enfoque dependerá de si tus pods se ejecutan en zonas predecibles.
En los clústeres zonales estándar de GKE, donde sabes en qué zona se ejecutarán tus pods, habilita Anywhere Cache para esa zona específica.
En los clústeres regionales de GKE (tanto Autopilot como Standard), en los que los pods se pueden programar en varias zonas, tienes las siguientes opciones:
- Habilitar el almacenamiento en caché en todas las zonas: habilita Anywhere Cache en todas las zonas de la región del clúster. De esta forma, se garantiza que haya una caché disponible independientemente de dónde programe GKE tus pods. Ten en cuenta que se te cobrará por cada zona en la que esté habilitada la caché. Para obtener más información, consulta los precios de Anywhere Cache.
- Colocar pods en una zona específica: usa una regla
nodeSelectoronodeAffinityen el manifiesto de tu carga de trabajo para restringir tus pods a una sola zona. Después, puedes habilitar Anywhere Cache solo en esa zona. Este enfoque es más rentable si tu carga de trabajo tolera estar restringida a una sola zona.
Para habilitar Anywhere Cache en la zona en la que se encuentra tu clúster de GKE, ejecuta los siguientes comandos:
# Enable the cache
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE
# Check the status of the cache
gcloud storage buckets anywhere-caches describe $BUCKET_NAME/$ZONE
Limpieza
Para evitar que se apliquen cargos en tu cuenta de Google Cloud por los recursos utilizados en este documento, elimina el proyecto que contiene los recursos o conserva el proyecto y elimina los recursos.
Para eliminar los recursos concretos, sigue estos pasos:
Elimina el clúster de GKE. Esta acción elimina todos los nodos y las cargas de trabajo.
gcloud container clusters delete CLUSTER_NAME --location=ZONE_OR_REGIONHaz los cambios siguientes:
CLUSTER_NAME: el nombre de tu clúster.ZONE_OR_REGION: la zona o región de tu clúster.
Inhabilita Anywhere Cache, si lo has habilitado, para evitar costes continuos. Para obtener más información, consulta Inhabilitar una caché.
Siguientes pasos
- Consulta cómo cargar modelos de Hugging Face en Cloud Storage (experimental).
- Consulta cómo servir LLMs en GKE con GPUs.
- Consulta más información sobre las GPUs disponibles en GKE.
- Consulta la información general sobre el almacenamiento de GKE.
- Consulta información sobre cómo configurar la federación de identidades de cargas de trabajo.