
In diesem Dokument erfahren Sie, wie Sie das Laden der großen KI-Modellgewichtungen aus Cloud Storage beschleunigen können. Dazu verwenden Sie Run:ai Model Streamer mit dem vLLM-Inferenzserver in Google Kubernetes Engine (GKE).
Die Lösung in diesem Dokument setzt voraus, dass Sie Ihr KI-Modell und die Gewichtungen im safetensors Format bereits in einen Cloud Storage-Bucket geladen haben.
Wenn Sie Ihrer vLLM-Bereitstellung das Flag --load-format=runai_streamer hinzufügen, können Sie den Run:ai Model Streamer verwenden, um die Effizienz des Modell-Downloads für Ihre KI-Arbeitslasten in GKE zu verbessern.
Dieses Dokument richtet sich an die folgenden Nutzer:
- Machine-Learning-Ingenieure (ML), die große KI-Modelle so schnell wie möglich aus dem Objektspeicher in GPU-/TPU-Knoten laden müssen.
- Plattformadministratoren und ‑operatoren, die die Infrastruktur für die Modellbereitstellung in GKE automatisieren und optimieren.
- Cloud-Architekten, die spezielle Tools zum Laden von Daten für KI-/ML-Arbeitslasten evaluieren.
Weitere Informationen zu gängigen Rollen und Beispielaufgaben, auf die in diesem Inhalt verwiesen wird, finden Sie unter Häufig verwendete GKE-Nutzerrollen und -Aufgaben. Google Cloud
Übersicht
Die in diesem Dokument beschriebene Lösung verwendet drei Kernkomponenten – Run:ai Model Streamer, vLLM und das safetensors-Dateiformat –, um das Laden von Modellgewichtungen aus Cloud Storage auf GPU- oder TPU-Knoten zu beschleunigen.
Run:ai Model Streamer
Run:ai Model Streamer
ist ein Open-Source-Python-SDK, mit dem das Laden großer KI-Modelle auf
Beschleuniger beschleunigt wird. Es streamt Modellgewichtungen direkt aus dem Speicher, z. B. Cloud Storage-Buckets, in den GPU- oder TPU-Speicher. Der Modell-Streamer eignet sich besonders für den Zugriff auf safetensors-Dateien in Cloud Storage.
safetensors
safetensors ist ein Dateiformat zum Speichern von Tensoren, den wichtigsten Datenstrukturen in KI-Modellen, auf eine Weise, die sowohl die Sicherheit als auch die Geschwindigkeit erhöht. safetensors wurde als Alternative zum Pickle-Format von Python entwickelt und ermöglicht durch einen Zero-Copy-Ansatz schnelle Ladezeiten. Mit diesem Ansatz können die Tensoren direkt von der Quelle aus aufgerufen werden, ohne dass die gesamte Datei zuerst in den lokalen Speicher geladen werden muss.
vLLM
vLLM ist eine Open-Source-Bibliothek für LLM-Inferenz und ‑Bereitstellung. Es ist ein leistungsstarker Inferenzserver, der für das schnelle Laden großer KI-Modelle optimiert ist. In diesem Dokument ist vLLM die Kern-Engine, die Ihr KI-Modell in GKE ausführt und eingehende Inferenzanfragen verarbeitet. Die integrierte Authentifizierungsunterstützung von Run:ai Model Streamer für Cloud Storage erfordert vLLM-Version 0.11.1 oder höher für GPUs und 0.18.0 oder höher für TPUs.
So beschleunigt Run:ai Model Streamer das Laden von Modellen
Wenn Sie eine LLM-basierte KI-Anwendung für die Inferenz starten, tritt oft eine erhebliche Verzögerung auf, bevor das Modell verwendet werden kann. Diese Verzögerung, auch Kaltstart genannt, tritt auf, weil die gesamte mehrere Gigabyte große Modelldatei von einem Speicherort wie einem Cloud Storage-Bucket auf die lokale Festplatte Ihres Computers heruntergeladen werden muss. Die Datei wird dann in den Speicher Ihres Beschleunigers geladen. Während dieser Ladezeit ist der teure Beschleuniger im Leerlauf, was ineffizient und kostspielig ist.
Anstelle des Prozesses „Herunterladen und dann laden“ streamt der Modell-Streamer das Modell direkt aus Cloud Storage in den GPU- oder TPU-Speicher. Der Streamer verwendet ein leistungsstarkes Back-End, um mehrere Teile des Modells, sogenannte Tensoren, parallel zu lesen. Das gleichzeitige Lesen von Tensoren ist deutlich schneller als das sequenzielle Laden der Datei.
Architektur
Der Run:ai Model Streamer lässt sich in vLLM in GKE einbinden, um das Laden von Modellen zu beschleunigen. Dazu werden Modellgewichtungen direkt aus Cloud Storage in den Beschleunigerspeicher gestreamt, wobei die lokale Festplatte umgangen wird.
Das folgende Diagramm zeigt diese Architektur:
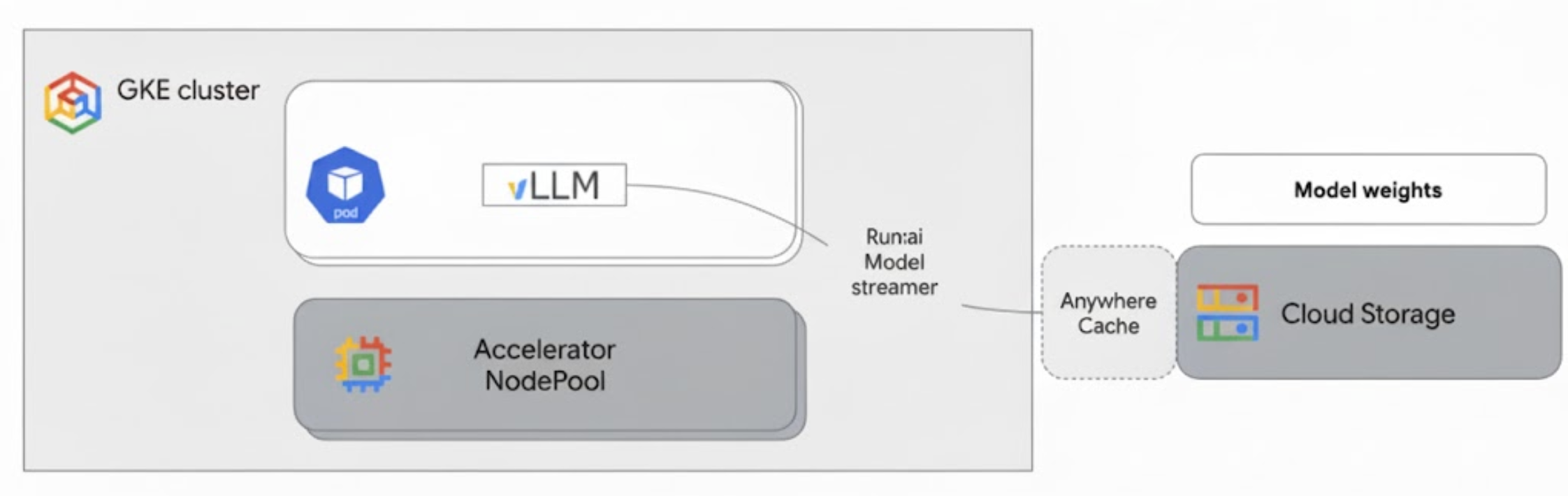
Diese Architektur umfasst die folgenden Komponenten und den folgenden Workflow:
- Cloud Storage-Bucket: Speichert die KI-Modellgewichtungen im
safetensors-Format. - GKE-Pod mit GPUs oder TPUs: Führt den vLLM-Inferenzserver aus.
- vLLM-Inferenzserver: Mit dem
--load-format=runai_streamerFlag konfiguriert, das die Modell-Streamer-Funktion aktiviert. - Run:ai Model Streamer: Wenn vLLM gestartet wird, liest der Modell-Streamer Modellgewichtungen aus dem angegebenen
gs://Pfad im Cloud Storage-Bucket. Anstatt Dateien auf die Festplatte herunterzuladen, werden Tensordaten direkt in den Beschleunigerspeicher des GKE-Pods gestreamt, wo sie sofort für die Inferenz mit vLLM verfügbar sind. - Cloud Storage Rapid Cache (optional): Wenn diese Option aktiviert ist, werden Bucket-Daten im Rapid Cache in derselben Zone wie die GKE-Knoten gespeichert, wodurch der Datenzugriff für den Streamer weiter beschleunigt wird.
Vorteile
- Kürzere Kaltstartzeiten:Der Modell-Streamer verkürzt die Zeit, die zum Starten von Modellen benötigt wird, erheblich. Er lädt die Modellgewichtungen im Vergleich zu herkömmlichen Methoden bis zu sechsmal schneller. Weitere Informationen finden Sie unter Run:ai Model Streamer-Benchmarks.
- Bessere Nutzung des Beschleunigers:Durch die Minimierung von Verzögerungen beim Laden von Modellen können Beschleuniger wie GPUs und TPUs mehr Zeit für tatsächliche Inferenzaufgaben aufwenden, was die Gesamteffizienz und Verarbeitungskapazität erhöht.
- Optimierter Workflow:Die in diesem Dokument beschriebene Lösung lässt sich in GKE einbinden, sodass Inferenzserver wie vLLM oder SGLang direkt auf Modelle in Cloud Storage-Buckets zugreifen können.
Hinweis
Prüfen Sie, ob alle Voraussetzungen erfüllt sind.
Projekt auswählen oder erstellen und APIs aktivieren
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Cloud Shell einrichten
In diesem Dokument werden die Google Cloud CLI und kubectl-Befehle verwendet, um die für diese Lösung erforderlichen Ressourcen zu erstellen und zu verwalten. Sie können diese
Befehle in der Cloud Shell ausführen. Klicken Sie dazu oben in
der Google Cloud Console auf Cloud Shell aktivieren.
Aktivieren Sie Cloud Shell in der Google Cloud Console.
Alternativ können Sie die gcloud CLI in Ihrer lokalen Shell-Umgebung installieren und initialisieren, um die Befehle auszuführen. Wenn Sie ein lokales Shell-Terminal verwenden möchten, führen Sie den gcloud auth login Befehl aus, um sich bei zu authentifizieren Google Cloud.
IAM-Rollen zuweisen
Achten Sie darauf, dass Ihr Google Cloud -Konto die folgenden IAM-Rollen für Ihr Projekt hat, damit Sie einen GKE-Cluster erstellen und Cloud Storage verwalten können:
roles/container.adminroles/storage.admin
Führen Sie die folgenden Befehle aus, um diese Rollen zuzuweisen:
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/container.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/storage.admin"
Ersetzen Sie PROJECT_ID durch Ihre Projekt-ID.
Umgebung vorbereiten
In diesem Abschnitt erfahren Sie, wie Sie Ihren GKE-Cluster einrichten und Berechtigungen für den Zugriff auf Ihr Modell in Cloud Storage konfigurieren.
GKE-Cluster erstellen
Der Run:ai Model Streamer kann sowohl mit GKE Autopilot- als auch mit GKE Standard-Clustern verwendet werden. Wählen Sie den Clustermodus aus, der Ihren Anforderungen am besten entspricht.
Legen Sie Variablen für Ihr Projekt und den Clusternamen fest:
export PROJECT_ID=PROJECT_ID export CLUSTER_NAME=CLUSTER_NAMEErsetzen Sie Folgendes:
PROJECT_ID: Ihre Google Cloud Projekt-ID. Sie können Ihre Projekt-ID mit dem Befehlgcloud config get-value projectabrufen.CLUSTER_NAME: Der Name Ihres Clusters. Beispiel:run-ai-test.
Erstellen Sie entweder einen Autopilot- oder einen Standard-Cluster:
Autopilot
So erstellen Sie einen GKE Autopilot-Cluster:
Legen Sie die Region für Ihren Cluster fest:
export REGION=REGIONErsetzen Sie
REGIONdurch die Region, in der Sie den Cluster erstellen möchten. Für eine optimale Leistung sollten Sie dieselbe Region wie für Ihren Cloud Storage-Bucket verwenden.Erstellen Sie den Cluster:
gcloud container clusters create-auto $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$REGION
Autopilot-Cluster stellen Knoten automatisch basierend auf den Anforderungen der Arbeitslasten bereit. Wenn Sie den vLLM-Server in einem späteren Schritt bereitstellen, stellt Autopilot bei Bedarf die GPU- oder TPU-Knoten bereit. Weitere Informationen finden Sie unter Automatische Erstellung von Knotenpools.
Standard
So erstellen Sie einen GKE Standard-Cluster:
Legen Sie die Zone für Ihren Cluster fest:
export ZONE=ZONEErsetzen Sie
ZONEdurch die Zone, in der Sie den Cluster erstellen möchten. Für eine optimale Leistung sollten Sie eine Zone in derselben Region wie für Ihren Cloud Storage-Bucket verwenden.Erstellen Sie den Cluster:
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --zone=$ZONE \ --workload-pool=$PROJECT_ID.svc.id.goog \ --num-nodes=1
Knotenpool erstellen
Wenn Sie einen Standard-Cluster erstellt haben, müssen Sie einen Knotenpool mit GPUs oder TPUs erstellen. Autopilot-Cluster stellen Knoten automatisch basierend auf den Anforderungen der Arbeitslasten bereit. Erstellen Sie einen Knotenpool basierend auf dem Beschleuniger, den Sie verwenden möchten:
* {GPU}
Create a node pool with one G2 machine (NVIDIA L4 GPU):
```sh
gcloud container node-pools create g2-gpu-pool \
--cluster=$CLUSTER_NAME \
--zone=$ZONE \
--machine-type=g2-standard-16 \
--num-nodes=1 \
--accelerator=type=nvidia-l4
```
* {TPU}
Create a node pool with TPU v7x nodes:
```sh
gcloud container node-pools create tpu7x-pool \
--cluster=$CLUSTER_NAME \
--zone=$ZONE \
--machine-type=tpu7x-standard-4t \
--num-nodes=1
```
Workload Identity Federation for GKE konfigurieren
Konfigurieren Sie Workload Identity Federation for GKE, damit Ihre GKE-Arbeitslasten sicher auf das Modell in Ihrem Cloud Storage-Bucket zugreifen können.
Legen Sie Variablen für Ihr Kubernetes-Dienstkonto und den Namespace fest:
export KSA_NAME=KSA_NAME export NAMESPACE=NAMESPACEErsetzen Sie Folgendes:
NAMESPACE: Der Namespace, in dem Ihre Arbeitslasten ausgeführt werden sollen. Verwenden Sie denselben Namespace, um alle Ressourcen in diesem Dokument zu erstellen.KSA_NAME: Der Name des Kubernetes-Dienstkontos, das Ihr Pod zur Authentifizierung bei Google Cloud APIs verwenden kann.
Erstellen Sie einen Kubernetes-Namespace:
kubectl create namespace $NAMESPACEErstellen Sie ein Kubernetes-Dienstkonto (Kubernetes service account, KSA):
kubectl create serviceaccount $KSA_NAME \ --namespace=$NAMESPACEGewähren Sie Ihrem KSA die erforderlichen Berechtigungen:
Legen Sie die Umgebungsvariablen fest:
export BUCKET_NAME=BUCKET_NAME export PROJECT_ID=PROJECT_ID export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID \ --format 'get(projectNumber)')Ersetzen Sie Folgendes:
BUCKET_NAME: Der Name Ihres Cloud Storage-Bucket, der Ihresafetensors-Dateien enthält.PROJECT_ID: Ihre Google Cloud Projekt-ID.
Die Variablen
PROJECT_NUMBER,PROJECT_ID,NAMESPACEundKSA_NAMEwerden in den folgenden Schritten verwendet, um die Workload Identity Federation for GKE-Prinzipal-ID für Ihr Projekt zu erstellen.Weisen Sie Ihrem KSA die Rolle
roles/storage.bucketViewerzu, um Objekte in Ihrem Cloud Storage-Bucket anzusehen:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.bucketViewer"Weisen Sie Ihrem KSA die Rolle
roles/storage.objectUserzu, um Objekte in Ihrem Cloud Storage-Bucket zu lesen, zu schreiben und zu löschen:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.objectUser"
Sie haben jetzt einen GKE-Cluster mit GPUs oder TPUs eingerichtet und Workload Identity Federation for GKE konfiguriert. Dadurch wurde einem Kubernetes-Dienstkonto die erforderlichen Berechtigungen für den Zugriff auf Ihr KI-Modell in Cloud Storage gewährt. Nachdem der Cluster und die Berechtigungen eingerichtet sind, können Sie den vLLM-Inferenzserver bereitstellen, der dieses Dienstkonto verwendet, um Modellgewichtungen mit dem Run:ai Model Streamer zu streamen.
vLLM mit dem Run:ai Model Streamer bereitstellen
Stellen Sie einen Pod bereit, auf dem der vLLM OpenAI-kompatible Server ausgeführt wird und der mit dem Flag --load-format=runai_streamer konfiguriert ist, um den Run:ai Model Streamer zu verwenden. Die vLLM-Version muss 0.11.1 oder höher für GPUs und 0.18.0 oder höher für TPUs sein.
Die folgenden Beispielmanifeste zeigen, wie Sie vLLM mit aktiviertem Modell-Streamer für ein kleines Modell wie gemma-2-9b-it konfigurieren.
Das --model-loader-extra-config={"distributed":true} Flag aktiviert
das verteilte Laden von Modellgewichtungen und ist eine empfohlene Einstellung zur
Verbesserung der Leistung beim Laden von Modellen aus dem Objektspeicher.
Weitere Informationen finden Sie unter Tensor-Parallelität und Abstimmbare Parameter.
Wählen Sie das Beispielmanifest basierend auf dem Beschleuniger aus, den Sie verwenden möchten:
GPU
Das folgende Beispielmanifest verwendet eine einzelne NVIDIA L4-GPU. Wenn Sie ein großes Modell verwenden, für das mehrere GPUs erforderlich sind, erhöhen Sie den Wert von
--tensor-parallel-sizeauf die erforderliche Anzahl von GPUs.Speichern Sie das folgende Manifest als
vllm-deployment.yaml. Das Manifest ist so konzipiert, dass es sowohl für Autopilot- als auch für Standard-Cluster flexibel eingesetzt werden kann.apiVersion: apps/v1 kind: Deployment metadata: name: vllm-streamer-deployment namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: vllm-streamer template: metadata: labels: app: vllm-streamer spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-openai:v0.11.1 command: - python3 - -m - vllm.entrypoints.openai.api_server args: - --model=gs://BUCKET_NAME/PATH_TO_MODEL - --load-format=runai_streamer - --model-loader-extra-config={"distributed":true} - --host=0.0.0.0 - --port=8000 - --disable-log-requests - --tensor-parallel-size=1 ports: - containerPort: 8000 name: api # startupProbe allows for longer startup times for large models startupProbe: httpGet: path: /health port: 8000 failureThreshold: 60 # 60 * 10s = 10 minutes timeout periodSeconds: 10 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health port: 8000 failureThreshold: 3 periodSeconds: 10 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" volumeMounts: - mountPath: /dev/shm name: dshm nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 volumes: - emptyDir: medium: Memory name: dshmErsetzen Sie Folgendes:
NAMESPACE: Ihr Kubernetes-Namespace.KSA_NAME: Der Name Ihres Kubernetes-Dienstkontos.BUCKET_NAME: Name Ihres Cloud Storage-Bucket.PATH_TO_MODEL: Der Pfad zu Ihrem Modellverzeichnis im Bucket, z. B.models/my-llama.
TPU
Das folgende Beispielmanifest verwendet TPU v7x-Knoten.
Speichern Sie das folgende Manifest als
vllm-deployment.yaml.apiVersion: apps/v1 kind: Deployment metadata: name: tpu-vllm namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: tpu-vllm template: metadata: labels: app: tpu-vllm spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-tpu:v0.18.0 resources: limits: google.com/tpu: "4" command: ["sh", "-c"] args: - >- python3 -m vllm.entrypoints.openai.api_server --model=gs://BUCKET_NAME/PATH_TO_MODEL --load-format=runai_streamer --tensor-parallel-size=8 --port=8000 ports: - containerPort: 8000 env: - name: VLLM_XLA_CACHE_PATH value: "gs://BUCKET_NAME/PATH_TO_CACHE" nodeSelector: cloud.google.com/gke-tpu-accelerator: tpu7x cloud.google.com/gke-tpu-topology: 2x2x1Ersetzen Sie Folgendes:
NAMESPACE: Ihr Kubernetes-Namespace.KSA_NAME: Der Name Ihres Kubernetes-Dienstkontos.BUCKET_NAME: Name Ihres Cloud Storage-Bucket.PATH_TO_MODEL: Der Pfad zu Ihrem Modellverzeichnis im Bucket, z. B.models/my-llama.PATH_TO_CACHE: Der Pfad zu Ihrem XLA-Kompilierungscache-Verzeichnis im Bucket, z. B.models/xla-cache.
Wenden Sie das Manifest an, um die Bereitstellung zu erstellen:
kubectl create -f vllm-deployment.yaml
Mit dem GKE-Tool für die Kurzanleitung zur Inferenz können Sie weitere vLLM-Manifeste generieren.
Deployment prüfen
Prüfen Sie den Status der Bereitstellung:
kubectl get deployments -n NAMESPACERufen Sie den Namen des Pods ab:
kubectl get pods -n NAMESPACE | grep vllm-streamerNotieren Sie sich den Namen des Pods, der mit
vllm-streamer-deploymentbeginnt.Prüfen Sie in den Pod-Logs, ob der Modell-Streamer das Modell und die Gewichtungen herunterlädt:
kubectl logs -f POD_NAME -n NAMESPACEErsetzen Sie
POD_NAMEdurch den Namen des Pods aus dem vorherigen Schritt. Erfolgreiche Streaming-Logs sehen so aus:[RunAI Streamer] Overall time to stream 15.0 GiB of all files: 13.4s, 1.1 GiB/s
Optional: Leistung mit Rapid Cache steigern
Cloud Storage Rapid Cache kann das Laden von Modellen weiter beschleunigen, indem Daten näher an Ihren GKE-Knoten zwischengespeichert werden. Das Caching ist besonders vorteilhaft, wenn Sie mehrere Knoten in derselben Zone skalieren.
Sie aktivieren Rapid Cache für einen bestimmten Cloud Storage-Bucket in einer bestimmten Google Cloud Zone. Um die Leistung zu verbessern, muss die Zone des Cache mit der Zone übereinstimmen, in der Ihre GKE-Inferenz-Pods ausgeführt werden. Ihr Ansatz hängt davon ab, ob Ihre Pods in vorhersehbaren Zonen ausgeführt werden.
Bei zonalen GKE Standard-Clustern, bei denen Sie wissen, in welcher Zone Ihre Pods ausgeführt werden, aktivieren Sie Rapid Cache für diese Zone.
Bei regionalen GKE-Clustern (sowohl Autopilot- als auch Standard-Cluster), bei denen Pods in mehreren Zonen geplant werden können, haben Sie folgende Möglichkeiten:
- Caching in allen Zonen aktivieren: Aktivieren Sie Rapid Cache in jeder Zone in der Region des Clusters. So ist unabhängig davon, wo GKE Ihre Pods plant, ein Cache verfügbar. Beachten Sie, dass für jede Zone, in der das Caching aktiviert ist, Kosten anfallen. Weitere Informationen finden Sie unter Rapid Cache-Preise.
- Pods in einer bestimmten Zone platzieren: Verwenden Sie in Ihrem Arbeitslastmanifest eine
nodeSelectorodernodeAffinity-Regel, um Ihre Pods auf eine einzelne Zone zu beschränken. Anschließend können Sie Rapid Cache nur in dieser Zone aktivieren. Dies ist ein kostengünstigerer Ansatz, wenn Ihre Arbeitslast die Beschränkung auf eine einzelne Zone zulässt.
Führen Sie die folgenden Befehle aus, um Rapid Cache für die Zone zu aktivieren, in der sich Ihr GKE-Cluster befindet:
# Enable the cache
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE
# Check the status of the cache
gcloud storage buckets anywhere-caches describe $BUCKET_NAME/$ZONE
Bereinigen
Damit Ihrem Google Cloud -Konto die in diesem Dokument verwendeten Ressourcen nicht in Rechnung gestellt werden, können Sie entweder das Projekt löschen, das die Ressourcen enthält, oder das Projekt beibehalten und die einzelnen Ressourcen löschen.
So löschen Sie die einzelnen Ressourcen:
Löschen Sie den GKE-Cluster. Durch diese Aktion werden alle Knoten und Arbeitslasten entfernt.
gcloud container clusters delete CLUSTER_NAME --location=ZONE_OR_REGIONErsetzen Sie Folgendes:
CLUSTER_NAME: Der Name Ihres Clusters.ZONE_OR_REGION: Die Zone oder Region Ihres Clusters.
Deaktivieren Sie Rapid Cache, falls Sie es aktiviert haben, um laufende Kosten zu vermeiden. Weitere Informationen finden Sie unter Cache deaktivieren.
Nächste Schritte
- Informationen zum Laden von Hugging Face-Modellen in Cloud Storage (experimentell)
- Informationen zum Bereitstellen eines LLM mit mehreren GPUs in GKE.
- Weitere Informationen zu GPUs, die in GKE verfügbar sind.
- Weitere Informationen zu TPUs, die in GKE verfügbar sind.
- Übersicht zu GKE-Speicher lesen
- Informationen zum Konfigurieren der Identitätsföderation von Arbeitslasten.