
本文档介绍如何通过在 Google Kubernetes Engine (GKE) 上将 Run:ai Model Streamer 与 vLLM 推理服务器搭配使用,加速从 Cloud Storage 加载大型 AI 模型权重的过程。
本文档中的解决方案假设您已将 AI 模型和权重以 safetensors 格式加载到 Cloud Storage 存储桶中。
通过向 vLLM 部署添加 --load-format=runai_streamer 标志,您可以使用 Run:ai Model Streamer 提高 GKE 上 AI 工作负载的模型下载效率。
本文档适用于以下用户:
- 需要尽快将大型 AI 模型从对象存储空间加载到 GPU/TPU 节点中的机器学习 (ML) 工程师。
- 在 GKE 上自动化和优化模型部署基础设施的平台管理员和运维人员。
- 评估 AI/机器学习工作负载专用数据加载工具的云架构师。
如需详细了解我们在 Google Cloud 内容中提及的常见角色和示例任务,请参阅常见的 GKE 用户角色和任务。
概览
本文档中介绍的解决方案使用三个核心组件(Run:ai Model Streamer、vLLM 和 safetensors 文件格式)来加快将模型权重从 Cloud Storage 加载到 GPU 节点的过程。
Run:ai Model Streamer
Run:ai Model Streamer 是一种开源 Python SDK,可加快将大型 AI 模型加载到 GPU 上的速度。它直接从存储空间(例如 Cloud Storage 存储桶)将模型权重流式传输到 GPU 的内存。模型流式传输器特别适合用于访问位于 Cloud Storage 中的 safetensors 文件。
safetensors
safetensors 是一种文件格式,用于以可同时提升安全性和速度的方式存储张量(AI 模型中的核心数据结构)。safetensors 旨在替代 Python 的 pickle 格式,并通过零复制方法实现快速加载。这种方法可让张量直接从来源进行访问,而无需先将整个文件加载到本地内存中。
vLLM
vLLM 是一个用于 LLM 推理和部署的开源库。它是一款高性能推理服务器,经过优化,可快速加载大型 AI 模型。在本文档中,vLLM 是在 GKE 上运行 AI 模型并处理传入推理请求的核心引擎。Run:ai Model Streamer 对 Cloud Storage 的内置身份验证支持需要 vLLM 0.11.1 版或更高版本。
Run:ai Model Streamer 如何加速模型加载
当您启动基于 LLM 的 AI 应用进行推理时,通常需要延迟很长时间模型才可以使用。这种延迟称为冷启动,之所以会发生,是因为必须将整个数 GB 的模型文件从存储位置(例如 Cloud Storage 存储桶)下载到机器的本地磁盘。然后,该文件会加载到 GPU 的内存中。在此加载期间,昂贵的 GPU 处于闲置状态,这既低效又浪费成本。
模型流式传输器会直接将模型从 Cloud Storage 流式传输到 GPU 的内存,而不是先下载再加载的过程。流式传输器使用高性能后端并行读取模型的多个部分(称为张量)。并发读取张量的速度比按顺序加载文件的速度快得多。
架构概览
Run:ai Model Streamer 与 GKE 上的 vLLM 集成,通过将模型权重直接从 Cloud Storage 流式传输到 GPU 内存(绕过本地磁盘)来加快模型加载速度。
下图展示了此架构:
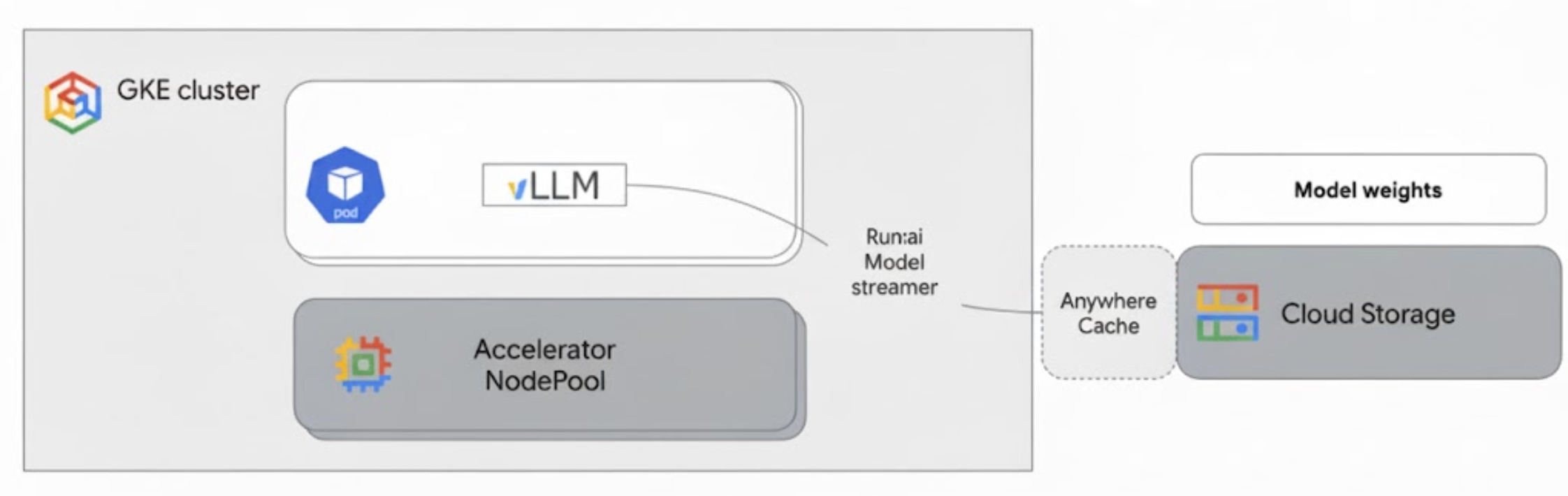
此架构包括以下组件和工作流:
- Cloud Storage 存储桶:以
safetensors格式存储 AI 模型权重。 - 具有 GPU 的 GKE Pod:运行 vLLM 推理服务器。
- vLLM 推理服务器:配置了
--load-format=runai_streamer标志,该标志可启用模型流式传输器功能。 - Run:ai Model Streamer:vLLM 启动后,模型流式传输器会从 Cloud Storage 存储桶中指定的
gs://路径读取模型权重。它不会将文件下载到磁盘,而是将张量数据直接流式传输到 GKE Pod 的 GPU 内存中,以便 vLLM 立即用于推理。 - Cloud Storage Anywhere Cache(可选):如果启用,Anywhere Cache 会在 GKE 节点所在的可用区中缓存存储桶数据,从而进一步加快流式传输器的数据访问速度。
优势
- 缩短了冷启动时间:模型流式传输器可显著缩短模型启动所需的时间。与传统方法相比,它加载模型权重的速度最多可快 6 倍。如需了解详情,请参阅 Run:ai Model Streamer 基准
- 提高了 GPU 利用率:通过最大限度地缩短模型加载延迟时间,GPU 可以将更多时间用于实际的推理任务,从而提高整体效率和处理能力。
- 简化了工作流:本文档中介绍的解决方案与 GKE 集成,使 vLLM 或 SGLang 等推理服务器能够直接访问 Cloud Storage 存储桶中的模型。
准备工作
请务必满足以下前提条件。
选择或创建一个项目并启用 API
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Verify that billing is enabled for your Google Cloud project.
Enable the Kubernetes Engine, Cloud Storage, Compute Engine, IAM APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
设置 Cloud Shell
本文档使用 Google Cloud CLI 和 kubectl 命令来创建和管理此解决方案所需的资源。您可以通过点击 Google Cloud 控制台顶部的激活 Cloud Shell,在 Cloud Shell 中运行这些命令。
In the Google Cloud console, activate Cloud Shell.
或者,您也可以在本地 shell 环境中安装并初始化 gcloud CLI 来运行这些命令。如果您想使用本地 shell 终端,请运行 gcloud auth login 命令以向 Google Cloud进行身份验证。
授予 IAM 角色
确保您的 Google Cloud 账号拥有项目的以下 IAM 角色,以便您可以创建 GKE 集群并管理 Cloud Storage:
roles/container.adminroles/storage.admin
如需授予这些角色,请运行以下命令:
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/container.admin"
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="user:$(gcloud config get-value account)" \
--role="roles/storage.admin"
将 PROJECT_ID 替换为您的项目 ID。
准备环境
本部分将引导您设置 GKE 集群并配置权限,以便访问 Cloud Storage 中的模型。
创建具有 GPU 的 GKE 集群
Run:ai Model Streamer 可与 GKE Autopilot 和 Standard 集群搭配使用。选择最符合您的需求的集群模式。
为项目和集群名称设置变量:
export PROJECT_ID=PROJECT_ID export CLUSTER_NAME=CLUSTER_NAME替换以下内容:
PROJECT_ID:您的 Google Cloud 项目 ID。 您可以通过运行gcloud config get-value project命令来查找项目 ID。CLUSTER_NAME:您的集群的名称。 例如run-ai-test。
创建 Autopilot 集群或 Standard 集群:
Autopilot
请按照以下步骤创建 GKE Autopilot 集群:
为集群设置区域:
export REGION=REGION将
REGION替换为您要在其中创建集群的区域。为获得最佳性能,请使用与 Cloud Storage 存储桶相同的区域。创建集群:
gcloud container clusters create-auto $CLUSTER_NAME \ --project=$PROJECT_ID \ --location=$REGION
Autopilot 集群会根据工作负载要求自动预配节点。在后面的步骤中部署 vLLM 服务器时,Autopilot 会根据需要预配 GPU 节点。如需了解详情,请参阅节点池自动创建简介。
Standard
请按照以下步骤创建 GKE Standard 集群:
为集群设置可用区:
export ZONE=ZONE将
ZONE替换为您要在其中创建集群的可用区。为获得最佳性能,请使用 Cloud Storage 存储桶所在区域中的可用区。创建集群:
gcloud container clusters create $CLUSTER_NAME \ --project=$PROJECT_ID \ --zone=$ZONE \ --workload-pool=$PROJECT_ID.svc.id.goog \ --num-nodes=1创建一个具有 G2 机器(NVIDIA L4 GPU)的节点池:
gcloud container node-pools create g2-gpu-pool \ --cluster=$CLUSTER_NAME \ --zone=$ZONE \ --machine-type=g2-standard-16 \ --num-nodes=1 \ --accelerator=type=nvidia-l4
配置 Workload Identity Federation for GKE
配置 Workload Identity Federation for GKE,以允许 GKE 工作负载安全地访问 Cloud Storage 存储桶中的模型。
为您的 Kubernetes 服务账号和命名空间设置变量:
export KSA_NAME=KSA_NAME export NAMESPACE=NAMESPACE替换以下内容:
NAMESPACE:您希望工作负载在其中运行的命名空间。请务必使用同一命名空间来创建本文档中的所有资源。KSA_NAME:Pod 可用于向 Google Cloud API 进行身份验证的 Kubernetes 服务账号的名称。
创建 Kubernetes 命名空间:
kubectl create namespace $NAMESPACE创建 Kubernetes 服务账号 (KSA):
kubectl create serviceaccount $KSA_NAME \ --namespace=$NAMESPACE为您的 KSA 授予必要的权限:
设置环境变量:
export BUCKET_NAME=BUCKET_NAME export PROJECT_ID=PROJECT_ID export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID \ --format 'get(projectNumber)')替换以下内容:
BUCKET_NAME:包含safetensors文件的 Cloud Storage 存储桶的名称。PROJECT_ID:您的 Google Cloud 项目 ID。
PROJECT_NUMBER、PROJECT_ID、NAMESPACE和KSA_NAME将用于在后续步骤中构建项目的 Workload Identity Federation for GKE 主账号标识符。向您的 KSA 授予
roles/storage.bucketViewer角色,以查看 Cloud Storage 存储桶中的对象:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.bucketViewer"向您的 KSA 授予
roles/storage.objectUser角色,以读取、写入和删除 Cloud Storage 存储桶中的对象:gcloud storage buckets add-iam-policy-binding gs://$BUCKET_NAME \ --member="principal://iam.googleapis.com/projects/$PROJECT_NUMBER/locations/global/workloadIdentityPools/$PROJECT_ID.svc.id.goog/subject/ns/$NAMESPACE/sa/$KSA_NAME" \ --role="roles/storage.objectUser"
您现在已设置一个具有 GPU 的 GKE 集群,并配置了 Workload Identity Federation for GKE,从而向 Kubernetes 服务账号授予了访问 Cloud Storage 中的 AI 模型所需的权限。在集群和权限就绪后,您就可以部署 vLLM 推理服务器了,该服务器将使用此服务账号通过 Run:ai Model Streamer 流式传输模型权重。
使用 Run:ai Model Streamer 部署 vLLM
部署一个运行兼容 vLLM OpenAI 服务器的 Pod,并配置了 --load-format=runai_streamer 标志以使用 Run:ai Model Streamer。vLLM 版本必须为 0.11.1 或更高版本。
以下示例清单展示了 vLLM 配置,其中启用了模型流式传输器,以使用单个 NVIDIA L4 GPU 来处理小型模型(例如 gemma-2-9b-it)。
- 如果您使用的是需要多个 GPU 的大型模型,请将
--tensor-parallel-size值增加到所需的 GPU 数量。 --model-loader-extra-config={"distributed":true}标志可实现模型权重的分布式加载,建议使用此设置来提升从对象存储空间加载模型的性能。
将以下清单保存为
vllm-deployment.yaml。该清单旨在实现 Autopilot 集群和 Standard 集群的灵活性。apiVersion: apps/v1 kind: Deployment metadata: name: vllm-streamer-deployment namespace: NAMESPACE spec: replicas: 1 selector: matchLabels: app: vllm-streamer template: metadata: labels: app: vllm-streamer spec: serviceAccountName: KSA_NAME containers: - name: vllm-container image: vllm/vllm-openai:v0.11.1 command: - python3 - -m - vllm.entrypoints.openai.api_server args: - --model=gs://BUCKET_NAME/PATH_TO_MODEL - --load-format=runai_streamer - --model-loader-extra-config={"distributed":true} - --host=0.0.0.0 - --port=8000 - --disable-log-requests - --tensor-parallel-size=1 ports: - containerPort: 8000 name: api # startupProbe allows for longer startup times for large models startupProbe: httpGet: path: /health port: 8000 failureThreshold: 60 # 60 * 10s = 10 minutes timeout periodSeconds: 10 initialDelaySeconds: 30 readinessProbe: httpGet: path: /health port: 8000 failureThreshold: 3 periodSeconds: 10 resources: limits: nvidia.com/gpu: "1" requests: nvidia.com/gpu: "1" volumeMounts: - mountPath: /dev/shm name: dshm nodeSelector: cloud.google.com/gke-accelerator: nvidia-l4 volumes: - emptyDir: medium: Memory name: dshm替换以下内容:
NAMESPACE:您的 Kubernetes 命名空间。KSA_NAME:您的 Kubernetes 服务账号名称。BUCKET_NAME:您的 Cloud Storage 存储桶名称。PATH_TO_MODEL:该存储桶中的模型目录的路径,例如models/my-llama。
应用该清单以创建 Deployment:
kubectl create -f vllm-deployment.yaml
您可以使用 GKE 推理快速入门工具生成更多 vLLM 清单。
验证 Deployment
检查 Deployment 的状态:
kubectl get deployments -n NAMESPACE获取 Pod 名称:
kubectl get pods -n NAMESPACE | grep vllm-streamer记下以
vllm-streamer-deployment开头的 Pod 的名称。如需检查模型流式传输器是否下载了模型和权重,请查看 Pod 日志:
kubectl logs -f POD_NAME -n NAMESPACE将
POD_NAME替换为上一步中 Pod 的名称。成功的流式传输日志如下所示:[RunAI Streamer] Overall time to stream 15.0 GiB of all files: 13.4s, 1.1 GiB/s
可选:使用 Anywhere Cache 提升性能
Cloud Storage Anywhere Cache 可通过将数据缓存到更靠近 GKE 节点的位置,进一步加快模型加载速度。在同一可用区中扩容多个节点时,缓存尤其有用。
您可以为特定 Google Cloud 可用区中的特定 Cloud Storage 存储桶启用 Anywhere Cache。为提高性能,缓存所在的可用区必须与 GKE 推理 Pod 在其中运行的可用区一致。您采取的方法取决于 Pod 是否在可预测的可用区中运行。
对于 GKE Standard 可用区级集群,如果您知道 Pod 将在哪个可用区中运行,请为该特定可用区启用 Anywhere Cache。
对于 Pod 可跨多个可用区进行调度的区域级 GKE 集群(Autopilot 和 Standard),您有以下选项:
- 在所有可用区中启用缓存:在集群所在区域内的每个可用区中启用 Anywhere Cache。这样可确保无论 GKE 在什么位置调度 Pod,缓存都可用。请注意,您需要为启用缓存的每个可用区支付费用。如需了解详情,请参阅 Anywhere Cache 价格。
- 将 Pod 放置在特定可用区中:在工作负载清单中使用
nodeSelector或nodeAffinity规则,以将 Pod 仅限于单个可用区。然后,您就可以仅在该可用区中启用 Anywhere Cache。如果您的工作负载可以容忍仅限于单个可用区,则此方法更经济实惠。
如需为 GKE 集群所在的可用区启用 Anywhere Cache,请运行以下命令:
# Enable the cache
gcloud storage buckets anywhere-caches create gs://$BUCKET_NAME $ZONE
# Check the status of the cache
gcloud storage buckets anywhere-caches describe $BUCKET_NAME/$ZONE
清理
为避免因本文档中使用的资源导致您的 Google Cloud 账号产生费用,请删除包含这些资源的项目,或者保留该项目但删除各个资源。
如需删除各个资源,请按照以下步骤操作:
删除 GKE 集群。 此操作会移除所有节点和工作负载。
gcloud container clusters delete CLUSTER_NAME --location=ZONE_OR_REGION替换以下内容:
CLUSTER_NAME:您的集群的名称。ZONE_OR_REGION:集群所在的可用区或区域。
如果您已启用 Anywhere Cache,请将其停用,以免持续产生费用。如需了解详情,请参阅停用缓存。
后续步骤
- 了解如何将 Hugging Face 模型加载到 Cloud Storage 中(实验性)
- 了解如何使用 GPU 在 GKE 上部署 LLM。
- 详细了解 GKE 中提供的 GPU。
- 阅读 GKE 存储概览。
- 了解如何配置工作负载身份联合。