
このページでは、GKE Inference Gateway の段階的なロールアウト オペレーションの方法について説明します。このロールアウトでは、新しいバージョンの推論インフラストラクチャを段階的にデプロイします。このゲートウェイを使用すると、安全で管理された方法で推論インフラストラクチャを更新できます。サービスの停止を最小限に抑えて、ノード、ベースモデル、LoRA アダプタを更新できます。このページでは、信頼性に優れたデプロイにするために、トラフィック分割とロールバックに関するガイダンスも提供します。
このページは、GKE Inference Gateway のロールアウト オペレーションを担当する、GKE の ID とアカウントの管理者およびデベロッパーを対象としています。
次のユースケースがサポートされています。
ノードの更新をロールアウトする
ノードの更新により、ノードのハードウェアやアクセラレータの新しい構成へ推論ワークロードを安全に移行できます。このプロセスは、モデルサービスを中断せずに、管理された方法で実施できます。ハードウェアのアップグレード、ドライバの更新、セキュリティ問題の解決が進行中でも、ノードの更新を使用すればサービスの停止を最小限にできます。
新しい
InferencePoolを作成する: ノードやハードウェアの更新済み仕様で構成したInferencePoolをデプロイします。HTTPRouteを使用してトラフィックを分割する: 既存と新しいInferencePoolリソースの間でトラフィックが分配されるようにHTTPRouteを構成します。backendRefsのweightフィールドを使用して、新しいノードに分配するトラフィックの割合を管理します。一貫性のある
InferenceObjectiveを維持する: 既存のInferenceObjective構成を保持して、両方のノード構成でモデルの動作が同一になるようにします。元のリソースを保持する: 必要に応じてロールバックできるように、ロールアウト中は元の
InferencePoolとノードをアクティブな状態に保持します。
たとえば、名前を llm-new として新しい InferencePool を作成できます。既存の llmInferencePool と同じモデル構成で、このプールを構成します。クラスタにある新しいノードセットに、このプールをデプロイします。HTTPRoute オブジェクトを使用して、元の llm と新しい llm-new InferencePool の間でトラフィックを分割します。この手法を使用すると、モデルノードを段階的に更新できます。
GKE Inference Gateway によってノードの更新がロールアウトされる様子を次の図に示します。
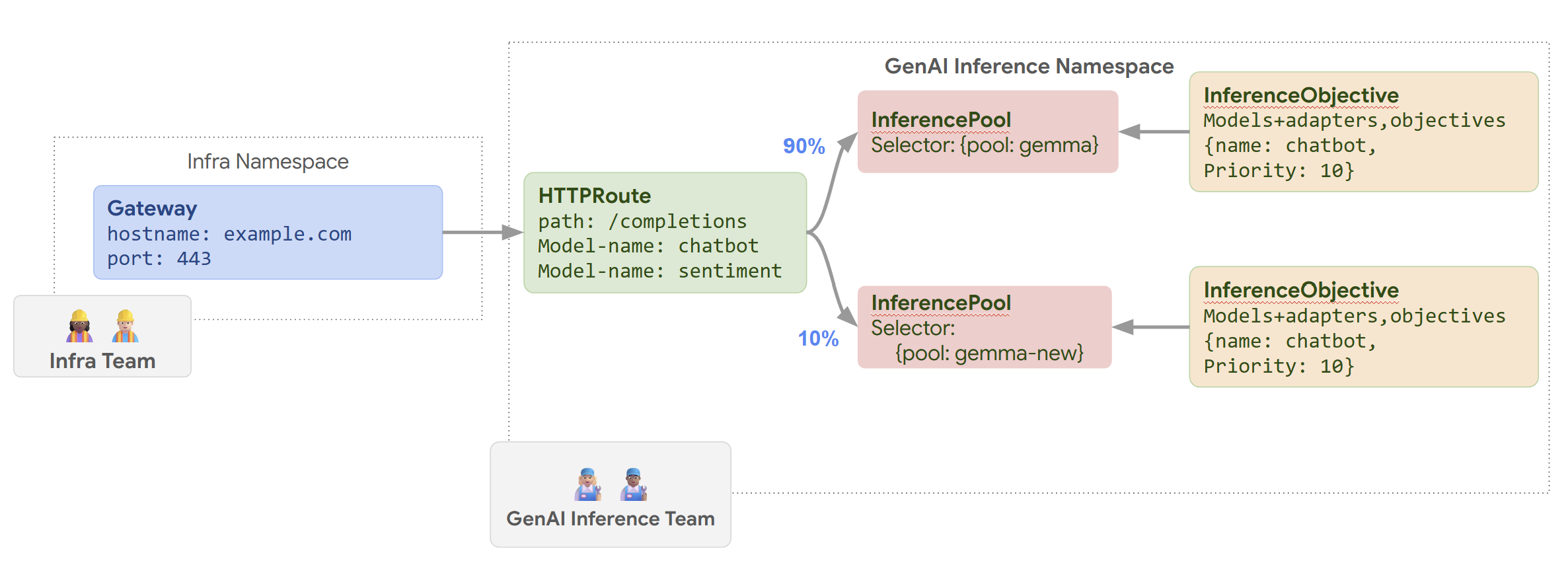
ノードの更新をロールアウトする手順は次のとおりです。
次のサンプル マニフェストを
routes-to-llm.yamlとして保存します。apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-new group: inference.networking.k8s.io kind: InferencePool weight: 10マニフェストをクラスタに適用します。
kubectl apply -f routes-to-llm.yaml
元の llm InferencePool がトラフィックの大部分を受け取り、llm-new InferencePool は残りのトラフィックを受け取ります。llm-new InferencePool に対するトラフィックの重み付けを段階的に大きくして、ノードの更新のロールアウトを完了します。
ベースモデルをロールアウトする
ベースモデルの更新を、既存の LoRA アダプタとの互換性を維持しながら、新しいベース LLM へ段階的にロールアウトします。ベースモデルの更新のロールアウトを使用すると、改善したモデル アーキテクチャへのアップグレードやモデル固有の問題への対処が可能になります。
ベースモデルの更新をロールアウトするには:
- 新しいインフラストラクチャをデプロイする: 選択した新しいベースモデルで構成した新しいノードと新しい
InferencePoolを作成します。 - トラフィック分配を構成する:
HTTPRouteを使用して、古いベースモデルを使用している既存のInferencePoolと新しいベースモデルを使用する新しいInferencePoolの間でトラフィックを分割します。backendRefs weightフィールドは、各プールに割り当てられるトラフィックの割合を制御します。 InferenceObjectiveの完全性を維持する:InferenceObjectiveの構成は現状のままで変更しません。これにより、両方のバージョンのベースモデルに同じ LoRA アダプタが一貫して適用されます。- ロールバック機能を保持する: ロールアウト中は元のノードと
InferencePoolを保持し、必要に応じて実施するロールバックを容易にします。
名前を llm-pool-version-2 として新しい InferencePool を作成します。このプールは、新しいノードセットに新しいバージョンのベースモデルをデプロイします。ここに示す例のように HTTPRoute を構成すると、元の llm-pool と llm-pool-version-2 の間でトラフィックを段階的に分割できます。これにより、クラスタの中でベースモデルの更新を制御できます。
ベースモデルの更新をロールアウトする手順は次のとおりです。
次のサンプル マニフェストを
routes-to-llm.yamlとして保存します。apiVersion: gateway.networking.k8s.io/v1 kind: HTTPRoute metadata: name: routes-to-llm spec: parentRefs: - name: my-inference-gateway group: inference.networking.k8s.io kind: InferenceGateway rules: backendRefs: - name: llm-pool group: inference.networking.k8s.io kind: InferencePool weight: 90 - name: llm-pool-version-2 group: inference.networking.k8s.io kind: InferencePool weight: 10マニフェストをクラスタに適用します。
kubectl apply -f routes-to-llm.yaml
元の llm-pool InferencePool がトラフィックの大部分を受け取り、llm-pool-version-2 InferencePool は残りのトラフィックを受け取ります。llm-pool-version-2 InferencePool に対するトラフィックの重み付けを段階的に大きくして、ベースモデルの更新のロールアウトを完了します。