
本文档提供了有关在 Google Kubernetes Engine (GKE) 上运行批处理推理工作负载的最佳实践。批量推理是指使用机器学习模型对大型数据集生成预测的过程,它优先考虑高吞吐量和成本效益,而不是立即做出低延迟响应。
本指南将批处理推理与请求批处理(或动态批处理)区分开来,后者是一种服务器端技术,用于在 vLLM 或 SGLang 等引擎中对并发的实时请求进行分组,以优化加速器效率。您可以将请求批处理应用于批量推理工作负载。
本指南中的最佳实践涵盖两种常见的批处理推理模式:
- 异步推理:在数据生成后不久便以块为单位处理数据。这种方法的典型延迟时间为数秒到数分钟,可在对新数据的需求与同时处理多个项目的效率之间取得平衡。异步推理有时也称为近实时推理。
- 批量推理:按预定的时间间隔(例如每晚或每周)处理大量累积的数据。延迟时间通常为数小时到数天,因为这些作业通常安排在非高峰时段运行,以最大限度地提高资源可用性。
这些建议是基于在 GKE 上进行推理的最佳实践概览中所述的基础知识构建的专业优化层。在针对批处理工作负载进行优化之前,请确保您已遵循有关模型选择、量化和加速器选择的核心最佳实践。
为批次推理处理选择架构模式
选择正确的架构模式对于部署批处理推理工作负载至关重要,因为这会影响延迟时间、吞吐量和费用之间的权衡。为保持效率,请确保推理吞吐量在非高峰时段超过传入查询的速率,以防止队列无限增长。
使用异步推理处理突发工作
异步推理非常适合需要频繁增量更新的应用场景,例如:
- 每隔几分钟根据最近的互动情况更新用户推荐资料。
- 以 1 分钟为间隔处理社交媒体提及内容,以实现实时监控。
- 从高频金融数据流中检测影响市场的信号。
- 对收到的客户反馈或新闻 Feed 执行情感分析。
如果您的工作负载可以容忍几秒到几分钟的延迟,请选择此模式。
实现异步推理时,请考虑以下特征:
- 延迟时间:从发出请求到收到第一个令牌的时间可能从数十秒到数分钟不等。
- 数据源:您通常会处理大小从兆字节到千兆字节不等的数据集,例如 Pub/Sub 中的消息或 Cloud Storage 中在短时间窗口内累积的文件。
- 计算模式:您的基础架构应支持可处理频繁突发工作负载的持续服务。
- 费用优化:此模式可在低延迟实时推理和高吞吐量批处理之间实现平衡。
针对大型数据集使用批量推理
批量推理非常适合大规模的临时性作业,这些作业可以容忍数小时或数天的延迟,例如:
- 根据前一天的金融交易生成每晚的风险评估报告。
- 为整个目录创建商品嵌入,以支持下游搜索和推荐系统。
- 为大量图片数据集添加标签,以便进行模型训练或归档分类。
如果您要处理大量数据,并且可以容忍从数小时到数天的延迟,请选择此模式。
实现批次推理时,请考虑以下特征:
- 延迟时间:工作负载启动延迟时间通常从几分钟到几天不等,因为作业通常在非高峰时段安排。
- 数据源:您处理的数据集大小从 GB 到 PB 不等,通常存储在 Cloud Storage 或 BigQuery 表中。
- 计算模式:您使用临时性、突发性作业,这些作业会先初始化,然后处理数据,最后终止。
- 费用优化:这种模式非常适合采用按用量计费模式。由于批处理作业的完成时间窗口较为灵活,我们建议使用 Spot 虚拟机来降低费用。
针对吞吐量和成本效益进行优化
批量推理工作负载非常适合可能涉及中断的节省成本的基础设施。
使用 Spot 虚拟机降低计算费用
针对批处理作业使用 Spot 虚拟机 的折扣。 由于批处理推理工作负载通常可以容忍延迟和中断,因此非常适合采用抢占式容量的低价。
确保您的批次推理代码实现检查点,以处理潜在的抢占事件。如果 Spot 虚拟机被抢占,您可以创建一个新节点,并从上次处理的批次恢复工作负载,而不是从头开始。
调整工作负载批次大小和请求批次大小
为避免资源争用和作业超时,请确保发送到引擎的商品数量(工作负载批次)至少与服务器可处理的并发请求数(请求批次)一样多,以避免加速器利用不足。
调整工作负载批次大小
工作负载批次大小是指在单个工作单元中发送到推理引擎的商品总数。您可以在客户端提交逻辑或 Kubernetes 作业配置中通过对数据进行分片或将多个项分组到单个请求中来配置此设置。
如需确定最佳工作负载批次大小,请使用以下边界:
- 计算最小批次大小:确保工作负载批次大小至少与请求批次大小一样大。例如,如果向可同时处理 256 个项目的服务器发送 1 个项目,则会导致资源严重利用不足。如需查找最小大小,请检查推理服务器配置,例如 vLLM 中的
max_num_seqs实参。您可以配置客户端逻辑,将多个商品分组到单个请求中;也可以对数据进行分片,使每个作业接收到的数据量至少达到或超过请求批次大小。 - 计算最大批次大小:确保工作负载批次大小允许 Pod 在达到 Kubernetes 作业中定义的
activeDeadlineSeconds超时之前完成。 估计处理一个请求批次所需的时间,并设置工作负载大小,以便 Pod 在截止期限内顺利完成。例如,如果您的activeDeadlineSeconds为 3,600 秒,而启动开销为 600 秒,请确保最长执行时间允许 Pod 在 3,000 秒内完成。
如果工作负载批次大小过小,作业会浪费时间在 Pod 启动开销(下载权重、配置、初始化加速器)上;如果过大,则作业可能会因 activeDeadlineSeconds 超时而被 GKE 终止,从而导致作业失败并丢失进度。
调整请求批次大小
请求批次大小是指推理服务器在加速器上同时处理的并发请求数量。您可以通过调整推理服务器配置中的服务器专用标志(例如,vLLM 的 --max-num-seqs 标志)来优化此参数。
您的目标是最大限度地提高 GPU 利用率,同时避免触发内存不足 (OOM) 错误。如果请求批次大小未校准,您的系统将无法充分利用加速器,或者导致模型服务器崩溃。对于 vLLM,您可以使用 vLLM auto_tune 脚本等工具,为您的特定硬件找到 max_num_seqs 和 max_num_batched_tokens 设置的最佳值。如需了解详情,请参阅 GKE 推理最佳实践概览指南中的优化推理服务器的配置。
为异步推理实现异步组件
对于异步推理,我们建议使用消息传送缓冲区将提取层与推理层分离。
以下架构图展示了一个异步推理平台的示例。此架构可保护推理服务器免受流量高峰的影响,管理工作积压,并确保加速器得到充分利用。
该图显示了从 Pub/Sub 到订阅方、推理网关和推理服务器的流程,结果会持久保存在 AlloyDB 中,而失败的消息会发送到死信主题。
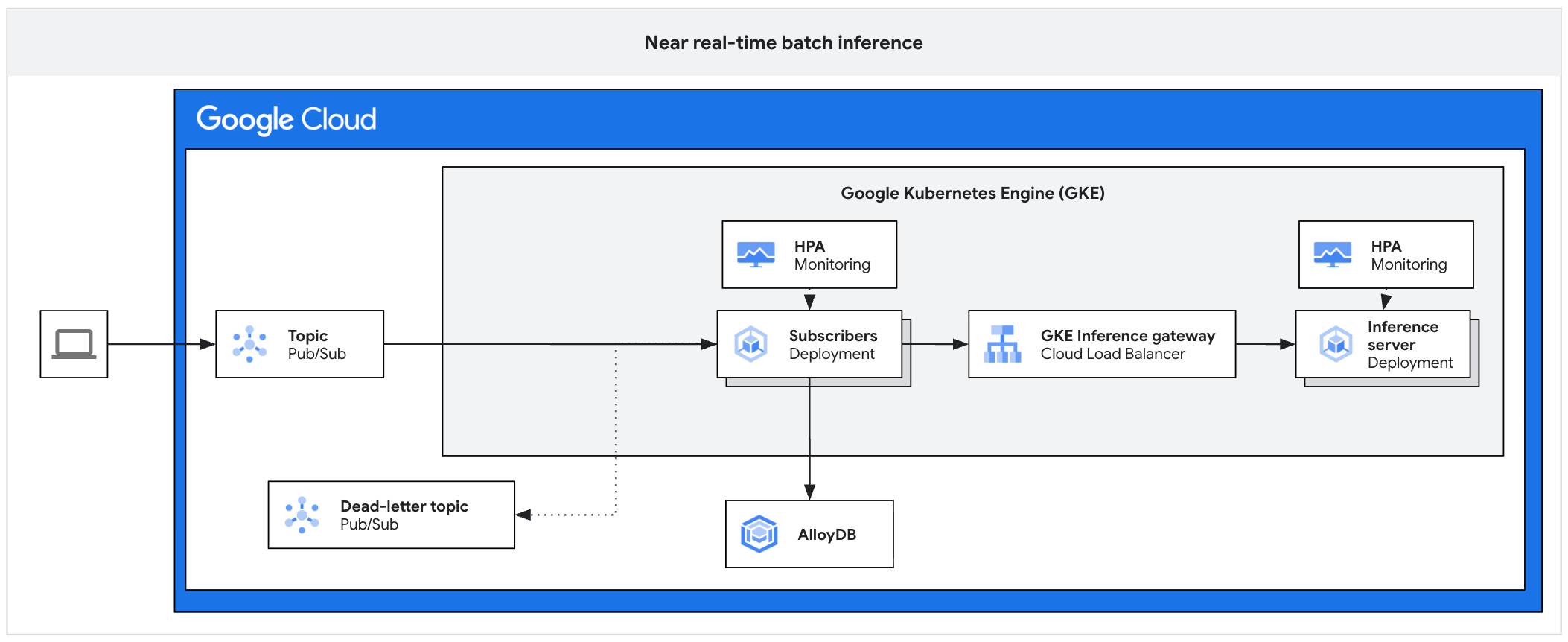
该架构包含以下组件:
- Pub/Sub 主题:充当传入客户端消息的持久缓冲区,保留期限为 7 到 31 天。
- 订阅者:一种组件,用于读取消息批次、向推理服务器发送请求并确认处理。
- 订阅者 HPA:根据
num_undelivered_messages指标(未确认的消息数量)扩缩订阅者部署。 - 存储:使用数据库(例如 AlloyDB)或对象存储(例如 Cloud Storage)持久保存推理结果。
- 推理网关:向订阅者公开推理工作负载。
- 推理服务器:处理批处理的推理请求(例如,vLLM)。
- 服务器 HPA:根据引擎专用指标(例如
vllm:num_requests_waiting)扩缩推理引擎。 - 死信主题:捕获在经过设定次数的指数退避算法重试后处理失败的消息。
如需了解详情,请参阅 GitHub 上的参考实现。
缓冲和聚合请求
如需管理请求的流程,请执行以下操作:
- 将 Pub/Sub 用作持久缓冲区:实现 Pub/Sub 以持久存储推理请求。此设置充当 FIFO 缓冲区,用于保存请求,直到消费者有能力处理这些请求为止,从而防止服务器在突发流量期间过载。
- 使用拉取订阅和客户端流控制:配置 Pull 订阅模型。这样,订阅方应用就可以仅在有能力处理消息时明确请求消息,从而让您能够完全控制使用率。
- 汇总消息以填满服务器批次大小:避免将一条 Pub/Sub 消息作为一条推理请求发送。订阅者应将多条消息捆绑到单个批量请求中,该请求应与推理服务器的最佳批次大小保持一致(例如,与 vLLM 中的
max_num_seqs设置相匹配)。这种方法有助于确保加速器完全饱和,并最大限度提高吞吐量。具体来说,请将订阅者的max_messages拉取设置配置为max_num_seqs的倍数,以确保每个模型前向传递都完全饱和。
自动扩缩订阅者和服务器
有效的批处理推理需要以不同方式伸缩订阅者(受 CPU 限制)和推理服务器(受 GPU 或 TPU 限制)。
根据工作积压情况扩缩订阅者:根据 Pub/Sub 中的
num_undelivered_messages指标为订阅者部署配置 HorizontalPodAutoscaler (HPA)。如需了解详情,请参阅根据指标优化 Pod 自动扩缩。 使用以下等式计算要使用的副本数:\[ desiredReplicas = \frac{num\_undelivered\_messages}{target\_latency\_seconds \times throughput\_per\_replica} \]
遵守基础设施配额:通过在 HPA 中配置
maxReplicas设置,明确限制订阅者的最大副本数。请勿将订阅者数量扩展到超出推理服务器的 GPU 或 TPU 配额所能支持的范围。过度预配订阅者会将瓶颈转移到推理服务器,从而在不提高吞吐量的情况下增加资源争用。根据引擎指标扩缩推理服务器:根据推理引擎直接导出的指标(不仅限于 CPU/内存)扩缩推理服务器部署。例如,使用 vLLM 的
vllm:num_requests_waiting设置,该设置可直接衡量模型服务器级别的处理积压。如需了解详情,请参阅自动扩缩 Pod。
处理错误和超时
如需处理错误和超时,请执行以下操作:
- 主动延长确认时限:配置订阅者以主动延长正在处理的消息的 Pub/Sub 确认 (ack) 时限,从而防止重新传送循环和重复处理。之所以需要这种方法,是因为推理任务通常比默认的超时窗口长。一般来说,应将延期时间设置为长于最糟糕情况下的批次推理时间。
- 使用死信主题隔离故障:启用死信主题可自动隔离无法成功传送的格式错误的消息。此方法可防止“毒丸”消息阻塞队列并停止整个流水线。
- 实现退避策略:如果推理服务器返回
429(请求过多)或503(服务不可用)错误,订阅方必须捕获这些错误并实现指数退避算法,暂时暂停从 Pub/Sub 中消费消息,直到服务器恢复正常。
大规模编排批处理作业
在处理海量数据集时,请遵循以下最佳实践,以最大限度地提高吞吐量、确保成本效益、实现全面的可追溯性以进行审核,并应用高级配额管理和作业优先级划分。
使用 JobSet 进行多节点分布式推理
我们建议您使用 Kubernetes JobSet 资源来编排需要多个节点协同工作的分布式推理工作负载,例如在 TPU Pod 或多节点 GPU 集群上运行的大型模型。标准 Kubernetes 作业无法保证所有必需的 Pod 同时启动,这可能会导致分布式工作负载出现死锁。
JobSet 是一种 Kubernetes 原生 API,可将一组作业作为一个单元进行管理,并为批量推理提供以下优势:
- 群组调度:有助于确保在启动工作负载之前所有必需的资源(例如 TPU 切片或 GPU 节点)都可用,从而防止出现死锁。
- 独占放置:有助于确保单个 JobSet 独占对网络拓扑(例如 TPU 切片)的访问权限,从而最大限度地提高互连性能。
- 故障恢复:如果工作器发生故障,您可以根据自己的配置重启特定的复制作业或整个作业集。
使用索引作业进行数据分片
使用 JobSet 时,请配置 ReplicatedJob 以使用 completionMode:
Indexed 设置。此设置会自动将 JOB_COMPLETION_INDEX 环境变量注入每个 Pod。推理代码可以使用此索引来确定性地选择要处理的唯一数据分片。
例如,如果您有一个包含 10 万张图片的 Cloud Storage 存储桶,并部署了一个并行度为 10 的 JobSet,那么每个 Pod 在启动时都会读取其索引 (0-9)。然后,Pod 0 可以计算出它应该处理图片 0-9,999,而 Pod 1 处理图片 10,000-19,999。这种方法可减少对单独的任务队列服务的需求。
针对服务器饱和度使用边车模式
为了最大限度地提高加速器利用率,请使用边车模式配置包含两个容器的 JobSet Pod:
- 推理服务器:完全专注于 GPU 或 TPU 计算的优化服务器(例如 vLLM)。
- 客户端驱动程序:一种逻辑容器,可异步向本地主机上的服务器发送大量请求。
这种解耦有助于确保 GPU 或 TPU 始终处于忙碌状态,在等待网络 I/O 或数据预处理时绝不会处于空闲状态。如果不采用这种方法,按顺序加载数据的模型可能会导致加速器等待 I/O 操作完成,从而导致利用率不足。例如,客户端驱动程序可以预提取数据并持续向推理服务器发送异步请求,而不是等待数据处理完毕,这有助于确保加速器的请求队列保持饱和状态。
核对清单摘要
| 类别 | 最佳做法 |
|---|---|
| 架构模式 | |
| 费用和吞吐量 |
|
| 消息传递和伸缩 |
|
| 编排 |
|