
本文档介绍了如何使用 Google Kubernetes Engine (GKE) 上的 KubeRay 在 Ray 控制面板上查看 TPU 指标。在具有 Ray GKE 加载项的 GKE 集群中,Cloud Monitoring 中会提供 TPU 指标。
准备工作
在开始之前,请确保您已执行以下任务:
- 启用 Google Kubernetes Engine API。 启用 Google Kubernetes Engine API
- 如果您要使用 Google Cloud CLI 执行此任务,请安装并初始化 gcloud CLI。 如果您之前安装了 gcloud CLI,请运行
gcloud components update命令以获取最新版本。较早版本的 gcloud CLI 可能不支持运行本文档中的命令。
您有一个满足以下条件的 GKE 集群:
- 配置为使用 TPU 的节点池。
- 此集群上不得启用 Ray on GKE 插件。
- 使用 Ray 和 TPU 在 GKE 上运行的服务或训练工作负载。
如果您需要创建满足这些条件的集群,请选择一个示例 TPU 工作负载,例如在 GKE 上使用 JAX、Ray Train 和 TPU Trillium 训练 LLM 或通过 KubeRay,使用 GKE 上的 TPU 应用 LLM,然后按照设置步骤配置集群。
准备环境
在本教程中,您将使用 Cloud Shell,这是一个用于管理Google Cloud上托管资源的 Shell 环境。
Cloud Shell 预安装有 Google Cloud CLI 和 kubectl 命令行工具。gcloud CLI 为 Google Cloud提供了主要的命令行界面,kubectl 则为针对 Kubernetes 集群运行命令提供了主要的行界面。
启动 Cloud Shell:
前往 Google Cloud 控制台。
在控制台的右上角,点击激活 Cloud Shell 按钮:

控制台下方的框架内会打开一个 Cloud Shell 会话。您可以使用此 shell 运行 gcloud 和 kubectl 命令。
在运行命令之前,请在 Google Cloud CLI 中使用以下命令设置默认项目:
gcloud config set project PROJECT_ID
将 PROJECT_ID 替换为您的项目 ID。
在 Ray 信息中心内查看 TPU 指标
如需在 Ray 信息中心内查看 TPU 指标,请执行以下操作:
在 shell 中,通过安装 Kubernetes Prometheus Stack 在 Ray 信息中心内启用指标。
./install/prometheus/install.sh --auto-load-dashboard true kubectl get all -n prometheus-system输出类似于以下内容:
NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/prometheus-grafana 1/1 1 1 46s deployment.apps/prometheus-kube-prometheus-operator 1/1 1 1 46s deployment.apps/prometheus-kube-state-metrics 1/1 1 1 46s此安装使用 Helm 图表将自定义资源定义 (CRD)、Pod 监控器和服务监控器添加到集群中的 Ray Pod。
安装启用了指标抓取的 KubeRay 操作器 v1.5.0 或更高版本。如需在 Grafana 中查看 TPU 指标,并使用 KubeRay 中提供的默认信息中心,您必须安装 KubeRay v1.5.0 或更高版本。
helm repo add kuberay https://ray-project.github.io/kuberay-helm/ helm install kuberay-operator kuberay/kuberay-operator --version 1.5.0-rc.0 \ --set metrics.serviceMonitor.enabled=true \ --set metrics.serviceMonitor.selector.release=prometheus安装 KubeRay TPU 网络钩子。此 webhook 设置了一个环境变量
TPU_DEVICE_PLUGIN_HOST_IP,Ray 使用该变量从tpu-device-pluginDaemonSet 轮询 TPU 指标。helm install kuberay-tpu-webhook \ oci://us-docker.pkg.dev/ai-on-gke/kuberay-tpu-webhook-helm/kuberay-tpu-webhook \ --set tpuWebhook.image.tag=v1.2.6-gke.0如需准备工作负载以记录指标,请在 RayCluster 规范中设置以下端口和环境变量:
headGroupSpec: ... ports: ... - containerPort: 44217 name: as-metrics - containerPort: 44227 name: dash-metrics env: - name: RAY_GRAFANA_IFRAME_HOST value: http://127.0.0.1:3000 - name: RAY_GRAFANA_HOST value: http://prometheus-grafana.prometheus-system.svc:80 - name: RAY_PROMETHEUS_HOST value: http://prometheus-kube-prometheus-prometheus.prometheus-system.svc:9090使用 Ray 运行含 TPU 的工作负载。您可以使用示例 TPU 工作负载,例如在 GKE 上使用 JAX、Ray Train 和 TPU Trillium 训练 LLM 或通过 KubeRay,使用 GKE 上的 TPU 应用 LLM。
在 Ray 信息中心或 Grafana 中查看指标
如需连接到 RayCluster,请转发 Ray 头服务的端口:
kubectl port-forward service/RAY_CLUSTER_NAME-head-svc 8265:8265将
RAY_CLUSTER_NAME替换为您的集群名称。如果您的工作负载来自在 GKE 上使用 JAX、Ray Train 和 TPU Trillium 训练 LLM 教程,则此值为maxtext-tpu-cluster。如需查看 Ray 信息中心,请在本地机器上前往
http://localhost:8265/。对 Grafana 网页界面进行端口转发。您需要对 Grafana 进行端口转发,才能查看显示在嵌入 Ray 信息中心的 Grafana 信息中心内的 TPU 指标。
kubectl port-forward -n prometheus-system service/prometheus-grafana 3000:http-web在 Ray 信息中心内,打开 Metrics 标签页,然后找到 TPU Utilization by Node 标签页。当 TPU 运行时,Tensor 核心利用率、HBM 利用率、TPU 工作周期和内存用量等每个节点的指标会流式传输到信息中心。如需在 Grafana 中查看这些指标,请前往 Grafana 中的“查看”标签页。
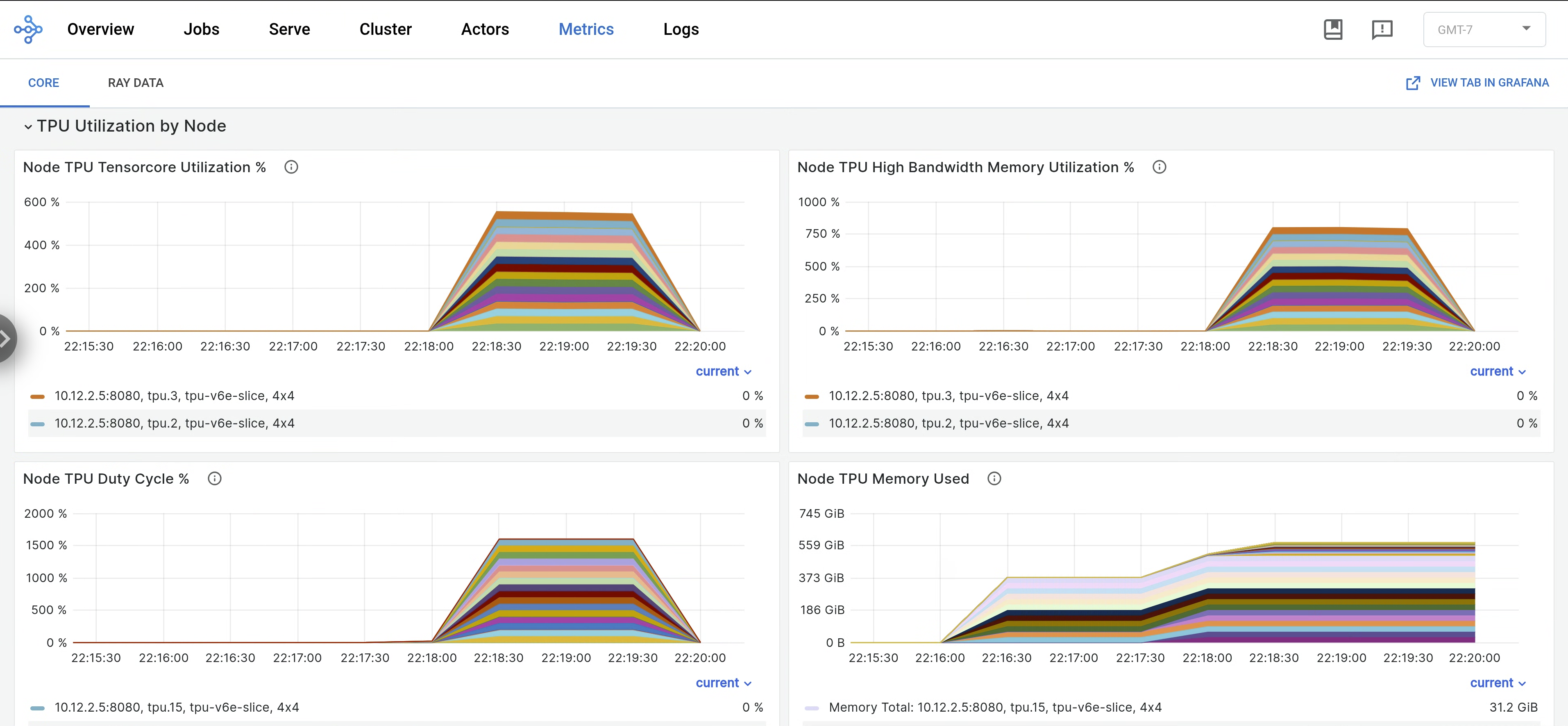
如需查看
libtpu日志,请前往 Ray 信息中心上的日志标签页,然后选择 TPU 节点。Libtpu 日志会写入/tpu_logs目录。
如需详细了解如何配置 TPU 日志记录,请参阅调试 TPU 虚拟机日志。