

本頁面將介紹 Gemini Enterprise 的「搜尋並回答」和「後續追問」功能,並說明如何透過方法呼叫實作這些功能。
「搜尋並取得答案」和「後續問題」功能採用回答方法。此外,回答方法還提供一些重要的附加功能,例如處理複雜查詢的能力。
回答方法的特色
「回答」方法的主要功能如下:
能夠生成複雜查詢的答案。舉例來說,答案方法可將複合查詢 (如下所示) 分解為多個較小的查詢,以傳回更準確的結果,進而提供更優質的答案:
- 「2024 年 Google Cloud 和 Google Ads 的營收分別是多少?」
- 「Google 成立後幾年達到 10 億美元營收?」
在多輪對話中,透過在每一輪呼叫答案方法,結合搜尋和答案生成功能。
可與搜尋方法配對,以減少搜尋延遲。您可以分別呼叫搜尋方法和回答方法,並在不同時間點,於不同的 iframe 中算繪搜尋結果和答案。也就是說,您可以在幾毫秒內向使用者顯示搜尋結果 (10 個藍色連結)。您不必等待系統生成答案,即可顯示搜尋結果。
答案和後續追問功能可分為查詢、搜尋和回答三個階段:
何時使用「回答」,何時使用「搜尋」
Gemini Enterprise 有兩種查詢應用程式的方法。兩者功能不同,但有部分重疊。
在下列情況下,請使用 answer 方法:
您希望 AI 生成搜尋結果的答案 (或摘要)。
您想要多輪搜尋,也就是搜尋時保留脈絡,以便提出後續問題。
在下列情況下,請使用 search 方法:
您只需要搜尋結果,不需要生成的答案。
您希望系統傳回超過十個搜尋結果 (「藍色連結」)。
具備下列任一條件:
- 您自己的嵌入
- 同義詞或重新導向控制項
- facet
- 使用者國家/地區代碼
在下列情況下,請同時使用回答和搜尋方法:
您想傳回超過十筆搜尋結果,且想取得生成的答案。
您有延遲問題,且希望在系統傳回生成的答案前,先傳回並顯示搜尋結果。
查詢階段功能
「回答」和「後續問題」功能支援自然語言查詢處理。
本節將說明並展示查詢重述和分類的各種選項。
重新措辭查詢
查詢重述功能預設為開啟。這項功能會自動選擇最佳方式重新措辭查詢,以改善搜尋結果。這項功能也能處理不需要重新措辭的查詢。
將複雜查詢拆解為多項查詢,並執行同步子查詢。
舉例來說,複雜的查詢會拆解成四個較小且簡單的查詢。
使用者輸入內容 從複雜查詢建立的子查詢 Andie Ram 和 Arnaud Clément 有哪些共同的工作和興趣? - Andie Ram 職業
- Arnaud Clément 職業
- Andie Ram 興趣
- Arnaud Clément hobby
彙整多輪查詢,讓後續問題瞭解背景資訊並保留狀態。
舉例來說,根據使用者在每個回合的使用者輸入內容合成的查詢可能如下所示:
使用者輸入內容 查詢已合成 第 1 輪:學校適用的筆記型電腦 學校適用的筆記型電腦 第 2 輪:不是 Mac 學校適用的筆電 (非 Mac) 第 3 輪:更大的螢幕,而且我還需要無線鍵盤和滑鼠 學校適用的筆電,螢幕要大一點,不要 Mac,要有無線鍵盤和滑鼠 第 4 步:為其製作背包 學校用的筆電,螢幕要大一點,不要 Mac,要有無線鍵盤和滑鼠,還要能裝進背包 簡化長查詢,提升擷取效果。
例如:將冗長的查詢縮短為簡單的查詢。
使用者輸入內容 簡化查詢 我們網站上的「加入購物車」按鈕無法正常運作,我想找出原因。使用者點選按鈕時,商品似乎不會加入購物車,且會收到錯誤訊息。我檢查了程式碼,看起來正確無誤,因此不確定問題出在哪裡。可以幫我排解這個問題嗎? 網站上的「加入購物車」按鈕無法運作。 執行多步驟推論
多步驟推論是以 ReAct (推論 + 行動) 範例為基礎,可讓 LLM 使用自然語言推論解決複雜工作。預設步驟上限為五個。
例如:
使用者輸入內容 生成答案的兩個步驟 Google 成立幾年後,營收達到 10 億美元? 步驟 1:
[想法]:我需要知道 Google 的成立時間,才能查詢自那時起的營收。
[Act] Search: When was Google founded?[Observe Search Results]: "1998"
步驟 2:
[Thought]:現在我需要搜尋 Google 自 1998 年以來的年營收,並找出首次超過 10 億美元的時間。
[Act] Search: Google revenue since 1998
[Observe Search Results] Google revenue in 1998, Google revenue in 1999…..
[Answer]: Google 於 1998 年成立 [2],並在 2003 年達到超過 10 億美元的收益 [1],
查詢分類
查詢分類選項可識別惡意查詢和非尋求答案的查詢。查詢分類選項預設為關閉。
如要進一步瞭解對抗性查詢和非尋找答案的查詢,請參閱「忽略對抗性查詢」和「忽略非尋找摘要的查詢」。
搜尋階段功能
搜尋時,回答方法與搜尋方法有相同的選項。例如:
套用篩選器,將搜尋範圍限定在特定文件。詳情請參閱「篩選自訂搜尋的結構化或非結構化資料」。
指定升幅條件,以升級或降級搜尋傳回的文件。詳情請參閱「提升搜尋結果排名」。
回答階段功能
在回答階段,如果系統根據搜尋結果生成答案,您可以啟用與搜尋方法相同的特徵。例如:
取得引文,指出答案中每個句子的來源。詳情請參閱「加入引文」。
使用提示前言自訂答案,例如語氣、風格和詳細程度。詳情請參閱「指定自訂前言」。
選擇要用來生成答案的模型。 詳情請參閱「答案生成模型版本和生命週期」。
選擇是否要忽略已分類為對抗性或非尋求答案的查詢。
如要進一步瞭解惡意查詢和非尋求答案的查詢,請參閱「忽略惡意查詢」和「忽略非尋求摘要的查詢」。非尋求答案的查詢也稱為非尋求摘要的查詢。
搜尋方法不支援的其他答案階段功能包括:
取得每項主張 (生成答案中的句子) 的支援分數。支援分數是介於 0 到 1 之間的浮點值,表示資料儲存庫中的資料對主張的支持程度。詳情請參閱「傳回基礎支援分數」。
取得答案的匯總支援分數。支援分數代表答案以資料儲存庫中的資料為依據的程度。詳情請參閱「傳回基礎支援分數」。
只傳回有根據的答案。您可以選擇只傳回符合特定支援分數門檻的答案。詳情請參閱「只顯示有根據的答案」。
在查詢中加入個人化資訊,讓系統為個別使用者提供客製化回覆。詳情請參閱「個人化回覆」。
如要取得包含圖表或圖片的多模態回覆 (不只是文字),請使用下列選項:
取得的答案會包含圖表,繪製答案中包含的資料。詳情請參閱「產生答案圖表」。
從資料儲存庫擷取圖片。如果資料儲存庫包含圖片,回答方法可以在答案中傳回圖片。如果要求提供引文,也可以在參照中傳回資料儲存庫中的圖片。詳情請參閱「從資料儲存區擷取現有圖片」。
搜尋和回答 (基本)
下列指令顯示如何呼叫 answer 方法,並傳回生成的答案和搜尋結果清單,以及來源連結。
這項指令只會顯示必要輸入內容。選項保留預設值。
REST
如要搜尋並取得附有生成答案的結果,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"} }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。例如「比較 BigQuery 和 Spanner 資料庫?」
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
查詢階段指令
本節說明如何為 answer 方法呼叫的查詢階段指定選項。
搜尋並回答 (已停用重述功能)
下列指令顯示如何呼叫 answer 方法,並傳回生成的答案和搜尋結果清單。由於重新措辭選項已停用,因此答案可能與先前的答案不同。
REST
如要搜尋並取得生成式答案,但不套用查詢重述,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "queryUnderstandingSpec": { "queryRephraserSpec": { "disable": true } } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。例如「比較 BigQuery 和 Spanner 資料庫?」
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
搜尋並回答 (指定最多步驟)
下列指令顯示如何呼叫 answer 方法,並傳回生成的答案和搜尋結果清單。由於重述步驟的數量增加,因此答案與先前的答案不同。
REST
如要搜尋並取得生成式答案,最多可重新措辭五次,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "queryUnderstandingSpec": { "queryRephraserSpec": { "maxRephraseSteps": MAX_REPHRASE } } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。例如「比較 BigQuery 和 Spanner 資料庫?」MAX_REPHRASE:重新措辭步驟的數量上限。最大值為5。 如未設定或設為小於1的值,則預設值為1。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
透過查詢分類搜尋及回答
下列指令說明如何呼叫 answer 方法,查詢查詢內容是否為惡意、非尋求答案,或兩者皆非。
回應會包含查詢的分類類型,但答案本身不受分類影響。 如要根據查詢類型變更回答行為,可以在回答階段執行這項操作。請參閱「忽略惡意查詢」和「忽略非摘要查詢」。
REST
如要判斷查詢是否為對抗性或非尋求答案,請執行下列操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "queryUnderstandingSpec": { "queryClassificationSpec": { "types": ["QUERY_CLASSIFICATION_TYPE"] } } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。例如「hello」。QUERY_CLASSIFICATION_TYPE:您要識別的查詢類型:ADVERSARIAL_QUERY、NON_ANSWER_SEEKING_QUERY或兩者。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
搜尋階段指令:搜尋並根據搜尋結果回答問題
本節說明如何為 answer 方法呼叫的搜尋階段部分指定選項,例如設定傳回的文件數上限、提升和篩選,以及在提供自己的搜尋結果時如何取得答案。
下列指令說明如何呼叫 answer 方法,以及如何指定搜尋結果的回傳方式。(搜尋結果與答案無關)。
REST
如要設定各種選項,決定要傳回哪些搜尋結果及傳回方式,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "searchSpec": { "searchParams": { "maxReturnResults": MAX_RETURN_RESULTS, "filter": "FILTER", "boostSpec": BOOST_SPEC, "orderBy": "ORDER_BY", "searchResultMode": SEARCH_RESULT_MODE } } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。例如:「比較 BigQuery 和 Spanner 資料庫?」MAX_RETURN_RESULTS:要傳回的搜尋結果數量。預設值為 10。FILTER:篩選器會指定要查詢的文件。如果文件的中繼資料符合篩選條件規格,系統就會查詢該文件。如要瞭解詳情 (包括篩選器語法),請參閱「篩選結構化或非結構化資料的自訂搜尋」。BOOST_SPEC:提升規格可讓您在搜尋結果中提升特定文件,這可能會影響答案。如要進一步瞭解如何指定加成,包括語法,請參閱「加成搜尋結果」。ORDER_BY:傳回文件的順序。文件可依 Document 物件中的欄位排序。orderBy運算式須區分大小寫。 如果無法辨識這個欄位,系統會傳回INVALID_ARGUMENT。SEARCH_RESULT_MODE:指定搜尋結果模式:DOCUMENTS或CHUNKS。詳情請參閱「剖析及分塊處理文件」和「ContentSearchSpec」。這個欄位僅適用於 API 的 v1alpha 版。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
回答階段指令
本節說明如何自訂 answer 方法呼叫。您可以視需要結合下列選項。
忽略對抗查詢和非尋求答案的查詢
下列指令說明如何呼叫 answer 方法,避免回答對抗性查詢和非尋求答案的查詢。
REST
如要略過對抗性或非尋求答案的查詢,請執行下列操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "answerGenerationSpec": { "ignoreAdversarialQuery": true, "ignoreNonAnswerSeekingQuery": true } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
只顯示相關答案
Gemini Enterprise 可以評估結果與查詢的相關程度。如果系統判定沒有足夠相關的結果,您可以選擇傳回備用答案「We do not have a summary for your query.」,而不是從不相關或相關性極低的結果生成答案。
下列指令說明在呼叫 answer 方法時,如何針對不相關的結果傳回備用答案。
REST
如要傳回備用答案 (找不到相關結果時),請執行下列操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "answerGenerationSpec": { "ignoreLowRelevantContent": true } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
傳回基礎支援分數
下列指令顯示如何傳回答案和聲明的根據支援分數。
REST
如要傳回每項主張 (答案中的句子) 的支援分數,以及答案的匯總支援分數,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "groundingSpec": { "includeGroundingSupports": true, } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。
只顯示有根據的答案
下列指令說明如何只傳回在語料庫 (資料儲存庫中的資訊) 中有根據的答案。系統會篩除依據不足的答案。
您可以選擇基礎支援分數的低或高層級門檻。然後,只有在答案達到或超過該層級時,才會傳回答案。您可以實驗這兩個篩選器門檻,以及不設門檻,判斷哪種篩選器等級最有可能為使用者提供最佳結果。
REST
如要只在答案達到支援分數門檻時傳回答案,請執行下列操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "groundingSpec": { "filteringLevel": "FILTER_LEVEL" } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。FILTER_LEVEL:用於根據基礎支援分數篩選答案的列舉。選項包括:FILTERING_LEVEL_LOW和FILTERING_LEVEL_HIGH。如果未加入filteringLevel,系統就不會對答案套用任何支援分數篩選條件。
指定答案模型
下列指令顯示如何變更用於生成答案的模型版本。
如要瞭解支援的模型,請參閱「答案生成模型版本和生命週期」。
REST
如要使用預設模型以外的模型生成答案,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "answerGenerationSpec": { "modelSpec": { "modelVersion": "MODEL_VERSION", } } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。MODEL_VERSION:用於生成答案的模型版本。詳情請參閱「答案生成模型版本和生命週期」。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
指定自訂前置碼
以下指令顯示如何為生成的答案設定前言。前言包含自然語言指示,可自訂答案。你可以要求自訂長度、詳細程度、輸出內容風格 (例如「簡單」)、輸出語言、答案重點和格式 (例如表格、項目符號和 XML)。舉例來說,前言可能是「用十歲小孩能理解的方式說明」。
前言可能會對生成的答案品質造成顯著影響。如要瞭解前言的撰寫內容和前言範例,請參閱「關於自訂前言」。
REST
如要使用預設模型以外的模型生成答案,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "answerGenerationSpec": { "promptSpec": { "preamble": "PREAMBLE", } } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。PREAMBLE:以自然語言提供指示,自訂回覆內容。例如,嘗試show the answer format in an ordered list或give a very detailed answer。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
只包含書目/引用資料
以下指令顯示如何要求在答案中加入引文。
REST
如要使用預設模型以外的模型生成答案,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "answerGenerationSpec": { "includeCitations": INCLUDE_CITATIONS } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。INCLUDE_CITATIONS:指定是否要在答案中加入引文的中繼資料。預設值為false。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
設定答案語言代碼
以下指令說明如何設定答案的語言代碼。
REST
如要使用預設模型以外的模型生成答案,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "answerGenerationSpec": { "answerLanguageCode": "ANSWER_LANGUAGE_CODE" } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。ANSWER_LANGUAGE_CODE:答案的語言代碼。請使用 BCP47:語言辨識標記中定義的語言標記。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
個人化答案
如果有使用者的特定資訊 (例如個人資料中的資料),您可以在 endUserMetadata 物件中指定該資訊,以便為使用者提供個人化的查詢結果。
舉例來說,如果使用者正在搜尋升級手機的相關資訊,系統會根據個人資料中的資訊 (例如目前的手機型號和行動方案),產生個人化回覆。
如要新增查詢者的個人資訊,並生成考量個人資訊的答案,請按照下列步驟操作:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "endUserSpec": { "endUserMetadata": [ { "chunkInfo": { "content": "PERSONALIZED_INFO", "documentMetadata": { "title": "INFO_DESCRIPTION"} } } ] } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。PERSONALIZATION_INFO:這個字串包含查詢使用者的專屬資訊。例如:This customer has a Pixel 6 Pro purchased over a period of 24-months starting 2023-01-15. This customer is on the Business Plus International plan. No payment is due at this time.這個字串的長度上限為 8,000 個字元。INFO_DESCRIPTION:簡要說明個人化資訊的字串,例如「模型會使用這項說明和個人化資訊,針對查詢生成自訂答案」。Customer profile data, including model, plan, and billing status.
為答案生成圖表
answer 方法可以生成圖表,並將其做為查詢回覆的一部分傳回。
你可以明確要求回覆內容包含圖表,例如「Plot the year-on-year growth rate of small business payments over years with available data」(根據現有資料繪製小型企業付款的年增率)。如果系統判定資料充足,就會傳回圖表。通常會傳回一些答案文字和圖表。
此外,如果資料足以建立圖表,即使查詢未明確要求圖表,答案方法仍可傳回圖表。舉例來說,「在 2010 年至 2020 年這十年期間,更多人取得乾淨飲用水與人類發展指數 (HDI) 分數提升之間有何關聯?」
每個答案只會生成一張圖表。不過,圖表可能是複合圖表,內含其他較小的圖表。複合圖表範例:
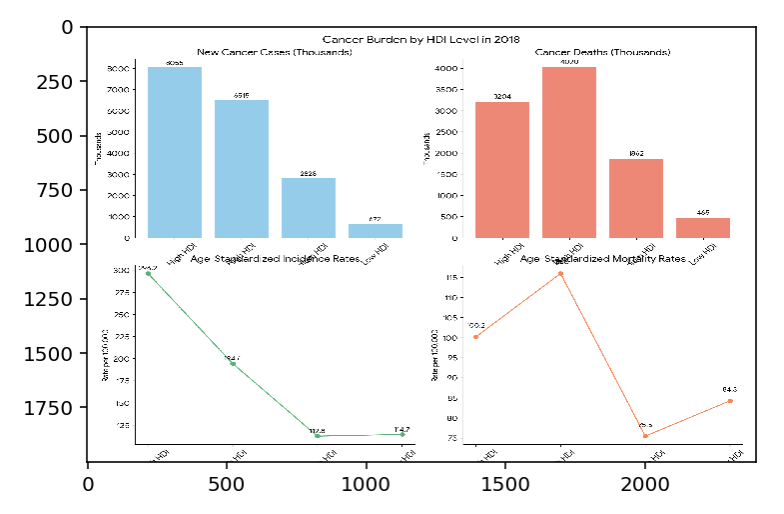
限制
查詢內容必須以英文輸入。
常見的失敗情況
系統不一定會在回覆中附上圖片。如果資料不足,系統就無法產生數據。
其他失敗情況包括程式碼執行失敗和逾時。如果發生上述任一情況,請改用其他字詞,然後再搜尋一次。
事前準備
執行要求生成圖表的查詢前,請先完成下列事項:
請確認您使用的是 Gemini 2.0 以上版本模型。如要瞭解模型,請參閱「答案生成模型版本和生命週期」。
程序
REST
呼叫 answer 方法,傳回的答案可包含根據資料儲存庫資料生成的圖表,如下所示:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1beta/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "answerGenerationSpec": { "model_spec": { "model_version": "MODEL_VERSION" }, "multimodalSpec": { "imageSource": "IMAGE_SOURCE" } } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:以英文輸入的任意文字字串,內含問題或搜尋查詢。MODEL_VERSION:模型版本stable或其他支援的模型,請參閱「答案生成模型版本和生命週期」。IMAGE_SOURCE:列舉要求,讓答案包含產生的圖表 (FIGURE_GENERATION_ONLY),或讓答案包含產生的圖表或資料儲存庫中的現有圖片 (ALL_AVAILABLE_SOURCES)。
從資料儲存庫擷取現有圖片
您可以選擇讓資料儲存庫中的圖片與答案一起回傳,並在引文參考資料中顯示。資料儲存庫必須為非結構化資料儲存庫,且已開啟版面配置剖析器。
如果 imageSource 為 CORPUS_IMAGE_ONLY 或 ALL_AVAILABLE_SOURCES,則 answer 方法可視情況從資料儲存庫擷取圖片。不過,開啟這項功能並不代表系統一律會傳回圖片。
每個答案最多可附上一張圖片。引文可以包含多張圖片。
限制
使用的應用程式必須連線至非結構化資料儲存庫。圖片無法從網站或結構化資料儲存庫傳回。
查詢內容必須以英文輸入。
透過版面配置剖析器進行的圖片註解必須套用至資料儲存庫。如要瞭解版面配置剖析器,請參閱「剖析及分塊處理文件」。
程序
REST
如要傳回答案,並在答案中加入資料儲存庫的圖片,請依下列方式呼叫 answer 方法:
執行下列 curl 指令:
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1beta/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "answerGenerationSpec": { "model_spec": { "model_version": "MODEL_VERSION" }, includeCitations: true, "multimodalSpec": { "imageSource": "IMAGE_SOURCE" } } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:要查詢的應用程式 ID。QUERY:以英文輸入的任意文字字串,內含問題或搜尋查詢。MODEL_VERSION:模型版本stable或其他支援的模型,請參閱「答案生成模型版本和生命週期」。IMAGE_SOURCE:列舉,要求答案包含資料儲存庫中的圖片 (CORPUS_IMAGE_ONLY),或答案可包含資料儲存庫中的圖片或產生的圖表 (ALL_AVAILABLE_SOURCES)。
後續問題的指令
後續問題是多輪查詢,在後續工作階段中,第一次查詢後,後續的「回合」會將先前的互動納入考量。後續問題的回答方法也會建議相關問題,使用者可以選擇這些問題,不必自行輸入後續問題。
前幾節所述的所有回答和後續追問功能,例如引文、篩選器、安全搜尋、忽略特定類型的查詢,以及使用前言自訂回答,都可以與後續追問功能一併使用。
後續追蹤工作階段範例
以下是包含後續追蹤的會話範例。假設你想瞭解在墨西哥度假的相關資訊:
回合 1:
你:墨西哥一年中哪個季節最適合度假?
回答並追問:墨西哥的最佳旅遊時間是乾季,也就是 11 月到 4 月。
第 2 回合:
你:匯率是多少?
回答後續問題:1 美元約等於 17.65 墨西哥披索。
第 3 輪:
你:12 月的平均溫度是多少?
回答並追問:平均溫度為 70-78°F。坎昆的平均溫度約為 25°C。
如果沒有後續查詢,系統就無法回答「匯率是多少?」這個問題,因為一般搜尋無法得知您想查詢墨西哥的匯率。同樣地,如果沒有後續對話,系統就無法取得提供墨西哥氣溫所需的背景資訊。
相關問題範例
當你詢問「墨西哥一年中什麼時候最適合度假?」時,除了回答你的問題,回答和後續追問還會建議你可能想問的其他問題,例如「墨西哥哪個月的度假費用最便宜?」和「墨西哥的旅遊旺季是哪幾個月?」。
啟用相關問題功能後,系統會在回應中以字串形式傳回問題。
關於工作階段
如要瞭解 Gemini Enterprise 的後續問題功能,必須先瞭解工作階段。
工作階段包含使用者提供的文字查詢,以及 Gemini Enterprise 提供的回覆。
這些查詢和回應組合有時也稱為「回合」。在上述範例中,第二輪對話包含「匯率是多少?」和「1 美元約等於 17.65 墨西哥披索」。
工作階段會與應用程式一併儲存。 在應用程式中,工作階段會以 session 資源表示。
除了查詢和回應訊息外,工作階段資源還包含:
專屬名稱 (工作階段 ID)。
狀態 (進行中或已完成)。
使用者虛擬 ID,也就是追蹤使用者的訪客 ID。可透過程式輔助方式指派。
開始時間和結束時間。
一輪對話,也就是查詢和答案的配對。
儲存工作階段資訊並取得回覆
您可以使用指令列產生搜尋回覆和答案,並將這些內容連同每個查詢儲存在工作階段中。
REST
如要使用指令列建立工作階段,並根據使用者的輸入內容生成回覆,請按照下列步驟操作:
指定要儲存工作階段的應用程式:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/sessions" \ -d '{ "userPseudoId": "USER_PSEUDO_ID" }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。USER_PSEUDO_ID:這是用來追蹤搜尋訪客的專屬 ID。舉例來說,您可以透過 HTTP Cookie 實作這項功能,在單一裝置上區分訪客。
指令與結果範例
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" "https://discoveryengine.googleapis.com/v1/projects/my-project-123/locations/global/collections/default_collection/engines/my-app/sessions" -d '{ "userPseudoId": "test_user" }'
{ "name": "projects/123456/locations/global/collections/default_collection/engines/my-app/sessions/16002628354770206943", "state": "IN_PROGRESS", "userPseudoId": "test_user", "startTime": "2024-09-13T18:47:10.465311Z", "endTime": "2024-09-13T18:47:10.465311Z" }記下工作階段 ID,也就是 JSON 回應中
name:欄位結尾的數字。在範例結果中,ID 為5386462384953257772。 下一個步驟會用到這個 ID。生成答案並新增至應用程式中的工作階段:
curl -X POST \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/servingConfigs/default_search:answer" \ -d '{ "query": { "text": "QUERY"}, "session": "projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/sessions/SESSION_ID", "searchSpec":{ "searchParams": {"filter": "FILTER"} } }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。QUERY:包含問題或搜尋查詢的任意文字字串。SESSION_ID:您在步驟 1 中建立的工作階段 ID。這些是name:欄位結尾的數字,如步驟 2 所示。在一個工作階段中,每次輪流對話時都使用相同的工作階段 ID。FILTER:文字欄位,可使用篩選運算式篩選搜尋結果。預設值為空字串。建構篩選條件的方式取決於您是否擁有內含中繼資料的非結構化資料、結構化資料或網站資料。詳情請參閱「篩選結構化或非結構化資料的自訂搜尋」。
指令與結果範例
curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" "https://discoveryengine.googleapis.com/v1/projects/my-project-123/locations/global/collections/default_collection/engines/my-app/servingConfigs/default_search:answer" -d '{ "query": { "text": "Compare bigquery with spanner database?"}, "session": "projects/123456/locations/global/collections/default_collection/engines/my-app/sessions/16002628354770206943", }'
{ "answer": { "name": "projects/123456/locations/global/collections/default_collection/engines/my-app/sessions/16002628354770206943/answers/4861507376861383072", "state": "SUCCEEDED", "answerText": "BigQuery and Spanner are both powerful tools that can be used together to handle transactional and analytical workloads. Spanner is a fully managed relational database optimized for transactional workloads, while BigQuery is a serverless data warehouse designed for business agility. Spanner provides seamless replication across regions in Google Cloud and processes over 1 billion requests per second at peak. BigQuery analyzes over 110 terabytes of data per second. Users can leverage federated queries to read data from Spanner and write to a native BigQuery table. \n", "steps": [ { "state": "SUCCEEDED", "description": "Rephrase the query and search.", "actions": [ { "searchAction": { "query": "Compare bigquery with spanner database?" }, "observation": { "searchResults": [ { "document": "projects/123456/locations/global/collections/default_collection/dataStores/my-data-store/branches/0/documents/ecc0e7547253f4ca3ff3328ce89995af", "uri": "https://cloud.google.com/blog/topics/developers-practitioners/how-spanner-and-bigquery-work-together-handle-transactional-and-analytical-workloads", "title": "How Spanner and BigQuery work together to handle transactional and analytical workloads | Google Cloud Blog", "snippetInfo": [ { "snippet": "Using Cloud \u003cb\u003eSpanner\u003c/b\u003e and \u003cb\u003eBigQuery\u003c/b\u003e also allows customers to build their \u003cb\u003edata\u003c/b\u003e clouds using Google Cloud, a unified, open approach to \u003cb\u003edata\u003c/b\u003e-driven transformation ...", "snippetStatus": "SUCCESS" } ] }, { "document": "projects/123456/locations/global/collections/default_collection/dataStores/my-data-store/branches/0/documents/d7e238f73608a860e00b752ef80e2941", "uri": "https://cloud.google.com/blog/products/databases/cloud-spanner-gets-stronger-with-bigquery-federated-queries", "title": "Cloud Spanner gets stronger with BigQuery-federated queries | Google Cloud Blog", "snippetInfo": [ { "snippet": "As enterprises compete for market share, their need for real-time insights has given rise to increased demand for transactional \u003cb\u003edatabases\u003c/b\u003e to support \u003cb\u003edata\u003c/b\u003e ...", "snippetStatus": "SUCCESS" } ] }, { "document": "projects/123456/locations/global/collections/default_collection/dataStores/my-data-store/branches/0/documents/e10a5a3c267dc61579e7c00fefe656eb", "uri": "https://cloud.google.com/blog/topics/developers-practitioners/replicating-cloud-spanner-bigquery-scale", "title": "Replicating from Cloud Spanner to BigQuery at scale | Google Cloud Blog", "snippetInfo": [ { "snippet": "... \u003cb\u003eSpanner data\u003c/b\u003e into \u003cb\u003eBigQuery\u003c/b\u003e for analytics. In this post, you will learn how to efficiently use this feature to replicate large tables with high throughput ...", "snippetStatus": "SUCCESS" } ] }, ... { "document": "projects/123456/locations/global/collections/default_collection/dataStores/my-data-store/branches/0/documents/8100ad36e1cac149eb9fc180a41d8f25", "uri": "https://cloud.google.com/blog/products/gcp/from-nosql-to-new-sql-how-spanner-became-a-global-mission-critical-database", "title": "How Spanner became a global, mission-critical database | Google Cloud Blog", "snippetInfo": [ { "snippet": "... SQL \u003cb\u003evs\u003c/b\u003e. NoSQL dichotomy may no longer be relevant." The \u003cb\u003eSpanner\u003c/b\u003e SQL query processor, while recognizable as a standard implementation, has unique ...", "snippetStatus": "SUCCESS" } ] } ] } } ] } ] }, "session": { "name": "projects/123456/locations/global/collections/default_collection/engines/my-app/sessions/16002628354770206943", "state": "IN_PROGRESS", "userPseudoId": "test_user", "turns": [ { "query": { "queryId": "projects/123456/locations/global/questions/741830", "text": "Compare bigquery with spanner database?" }, "answer": "projects/123456/locations/global/collections/default_collection/engines/my-app/sessions/16002628354770206943/answers/4861507376861383072" } ], "startTime": "2024-09-13T18:47:10.465311Z", "endTime": "2024-09-13T18:47:10.465311Z" }, "answerQueryToken": "NMwKDAjFkpK3BhDU24uZAhIkNjZlNDIyZWYtMDAwMC0yMjVmLWIxMmQtZjQwMzA0M2FkYmNj" }針對工作階段中的每個新查詢重複步驟 3。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
從資料儲存庫取得工作階段
以下指令說明如何呼叫 get 方法,並從資料儲存庫取得工作階段。
REST
如要從資料儲存庫取得工作階段,請執行下列操作:
執行下列 curl 指令:
curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/sessions/SESSION_ID"
更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。SESSION_ID:要取得的工作階段 ID。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
從應用程式中刪除訓練記錄
以下指令示範如何呼叫 delete 方法,並從資料儲存庫刪除工作階段。
根據預設,系統會自動刪除超過 60 天的會期。 不過,如要刪除特定工作階段 (例如含有敏感內容),請使用這個 API 呼叫。
REST
如要從應用程式中刪除工作階段,請按照下列步驟操作:
執行下列 curl 指令:
curl -X DELETE -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/sessions/SESSION_ID"
更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。SESSION_ID:要刪除的工作階段 ID。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
更新工作階段
您可能會因為各種原因而想更新工作階段。舉例來說,您可以執行下列任一操作:
- 將目標時段標示為完成
- 將一個工作階段的訊息合併到另一個工作階段
- 變更使用者的虛擬 ID
以下指令顯示如何呼叫 patch 方法,並更新資料儲存庫中的工作階段。
REST
如要從應用程式更新工作階段,請按照下列步驟操作:
執行下列 curl 指令:
curl -X PATCH \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/sessions/SESSION_ID?updateMask=state" \ -d '{ "state": "NEW_STATE" }'更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。SESSION_ID:要更新的會期 ID。NEW_STATE:狀態的新值,例如IN_PROGRESS。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
列出所有工作階段
下列指令顯示如何呼叫 list 方法,並列出資料儲存庫中的工作階段。
REST
如要列出應用程式的會期,請按照下列步驟操作:
執行下列 curl 指令:
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/sessions"
更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
列出使用者的工作階段
下列指令顯示如何呼叫 list 方法,列出與使用者或訪客相關聯的工作階段。
REST
如要列出與使用者或訪客相關聯的工作階段,請按照下列步驟操作:
執行下列 curl 指令:
curl -X GET \ -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/sessions?filter=userPseudoId=USER_PSEUDO_ID"
更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。USER_PSEUDO_ID:要列出工作階段的使用者虛擬 ID。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
列出使用者和狀態的工作階段
以下指令說明如何呼叫 list 方法,列出特定使用者處於指定狀態的會話。
REST
如要列出與特定使用者或訪客相關聯的開啟或關閉工作階段,請執行下列操作:
執行下列 curl 指令:
curl -X GET -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://discoveryengine.googleapis.com/v1/projects/PROJECT_ID/locations/global/collections/default_collection/engines/APP_ID/sessions?filter=userPseudoId=USER_PSEUDO_ID%20AND%20state=STATE"
更改下列內容:
PROJECT_ID:專案 ID。APP_ID:應用程式 ID。USER_PSEUDO_ID:要列出工作階段的使用者虛擬 ID。STATE:工作階段狀態:STATE_UNSPECIFIED(已關閉或不明) 或IN_PROGRESS(已開啟)。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Gemini Enterprise 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Gemini Enterprise Python API 參考文件。
如要向 Gemini Enterprise 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。