
本文档介绍了如何创建和优化上下文集,以帮助在数据代理应用中实现高 QueryData 查询准确性。上下文工程智能体可通过自动创建和优化上下文集,帮助您构建、评估和改进上下文集。
如需了解上下文集和 QueryData,请参阅上下文集概览和 QueryData 概览。若要构建企业级数据应用,文本转 SQL 模型的准确率通常需要达到近乎 100% 的质量。错误的查询结果会影响应用的整体可用性和用户体验。若要获得可解释的、与业务相关的且准确率高的答案,需要进行上下文工程,即创建并迭代优化上下文以实现最佳准确率的过程。
通过提供以您的业务应用为目标的上下文的 QueryData,您可以提供系统解决细致入微的用户意图所需的精确业务规则。
上下文工程智能体
上下文工程智能体可自动执行此优化工作流。您可以与代理对话,处理临时任务,以优化上下文。以下列表提供了一些自然语言提示示例,您可以利用这些提示来指示代理,并附有代理响应方式的说明。您可以参考以下示例来构建和优化上下文:
- 失败分析的提示示例:“更新上下文,以便我们正确识别‘迪士尼世界航班’等查询中的机场。”代理会分析失败情况,推断出差距,并建议添加适当的上下文项,例如值搜索查询。
- 上下文建议的提示示例:“读取我的应用代码,并建议添加一些上下文。”智能体将解析代码,推断应用领域,并建议哪些上下文项可能相关。
- 批量处理的提示示例:“以下是 10 个问题和 SQL 查询示例。将它们转换为模板。”代理会批量处理您的输入内容并更新您的上下文集。
黄金数据集的重要性
如需优化上下文,您必须先创建一个与应用的自然语言输入相匹配的数据集。该代理可以帮助您构建此黄金数据集,其中包含用户问题及其预期数据库查询。黄金数据集可让您:
- 确定查询性能基准。
- 根据标准答案数据库查询验证更新。
- 衡量迭代过程中的准确率提高幅度。
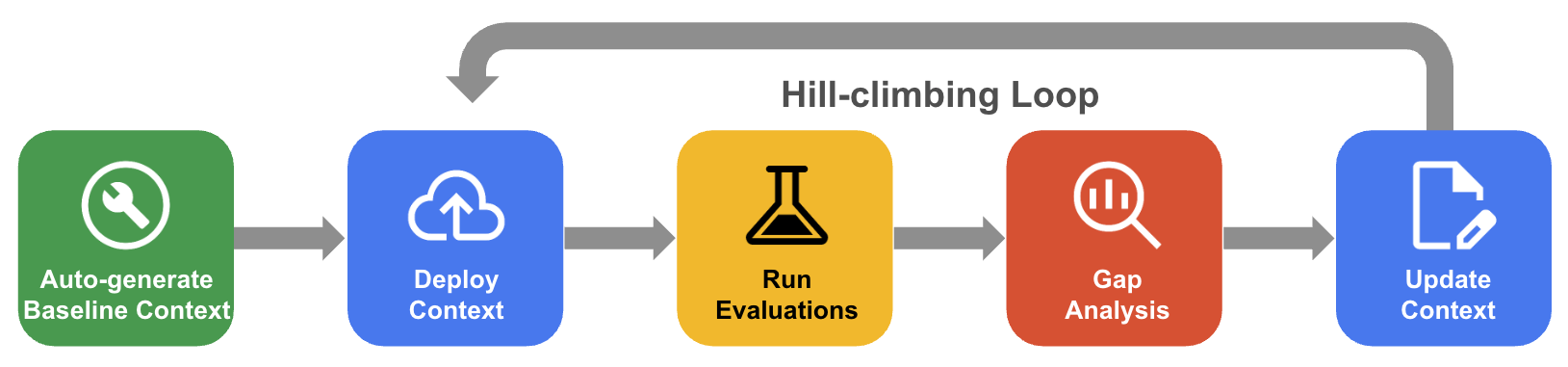
系统性的爬山过程
在系统性爬山算法中,智能体通过评估黄金数据集、差距分析和更新来迭代改进上下文集,从而将准确率提高到接近 100%。
- 自动生成基准上下文:创建一组从数据库架构和应用制品派生的初始上下文。
- 爬山优化工作流程:让智能体评估 QueryData 的准确率,对失败进行差距分析,并自动提出改进建议,以提高准确率。
下图显示了系统爬山工作流:
准备工作
在使用上下文工程代理之前,请完成以下前提条件。
启用必需服务
为项目启用以下服务:准备 Cloud SQL 实例
确保您有权访问现有 Cloud SQL 实例或创建新实例。 如需了解详情,请参阅为 Cloud SQL 创建实例。本教程要求您在 Cloud SQL 实例中拥有一个数据库。如需了解详情,请参阅在 Cloud SQL 实例上创建数据库
所需的角色和权限
- 向实例添加 IAM 用户或服务账号。如需了解详情,请参阅使用 IAM 数据库身份验证管理 Cloud SQL 用户。
- 在项目级层向 IAM 用户授予
cloudsql.studioUser、cloudsql.instanceUser和geminidataanalytics.queryDataUser角色。如需了解详情,请参阅为项目添加 IAM 政策绑定。 - 您还必须以具有超级用户权限(例如
postgres用户)的用户身份登录,向 IAM 用户或服务账号授予只读数据库权限。GRANT SELECT ON ALL TABLES IN SCHEMA public TO USER_NAME;
将 USER_NAME 替换为用户的电子邮件地址。您必须使用英文引号将电子邮件地址括起来,因为它包含特殊字符(@ 和 .)。
如需了解详情,请参阅向单个 IAM 用户或服务账号授予数据库权限。
向 Cloud SQL 实例授予 executesql 权限
如需向 Cloud SQL 实例授予 executesql 权限并启用 Cloud SQL Data API,请运行以下命令:
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
PROJECT_ID:您的 Google Cloud 项目的 ID。INSTANCE_ID:Cloud SQL 实例的 ID。
准备环境
您可以在任何本地开发环境或 IDE 中构建上下文集文件。 要准备环境,请完成以下步骤:
- 安装上下文工程代理
- 设置数据库连接
安装上下文工程代理
上下文工程代理运行 Model Context Protocol (MCP) 服务器,该服务器需要 uv 来管理底层 Python 软件包。
按照安装
uv中的说明安装uv。验证
uv是否已安装并可从命令行访问:uv --version
如需准备环境,请在所选的智能体框架(例如 Antigravity CLI、Claude Code 或 Gemini CLI)中安装上下文工程智能体。
根据您选择的智能体 Harness,按照相应的安装步骤操作:
Antigravity CLI
如需在 Antigravity CLI 中安装上下文工程代理,请按以下步骤操作:
- 安装 Antigravity CLI。请参阅 Antigravity CLI 使用入门。
- 安装上下文工程智能体插件,其中包含用于生成上下文的工作流。将 VERSION 替换为所需的已发布版本:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- 启动 Antigravity CLI:
agy
- 可选。更新插件:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
如需在 Claude Code 中安装上下文工程代理,请按以下步骤操作:
- 添加插件市场:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- 安装插件:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- 重新加载插件以启用更改:
/reload-plugins
- 可选。更新插件:
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI(已弃用)
如需在 Gemini CLI 中安装上下文工程代理,请按以下步骤操作:
- 安装 Gemini CLI。请参阅 Gemini CLI 使用入门。
- 安装扩展程序:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- 可选。更新扩展程序:
gemini extensions update mcp-db-context-enrichment
设置数据库连接
该代理需要数据库连接才能提取架构,并且能够验证生成的 SQL 上下文的语法。如需让代理与数据库互动,请配置身份验证凭据并定义数据库连接配置。
配置应用默认凭据
配置应用默认凭证 (ADC),以提供用户凭据,以便从上下文工程代理访问 Google Cloud 资源:
- Toolbox MCP 服务器:使用凭据连接到您的数据库、提取架构并运行 SQL 进行验证。
- Evalbench:使用凭据调用 QueryData 进行评估。
在终端中运行以下命令进行身份验证:
gcloud auth application-default login配置数据库连接文件
智能体需要数据库连接才能生成上下文,而 MCP Toolbox 支持此功能,并在配置文件中定义数据库连接。
配置文件用于指定数据库来源以及提取架构或执行 SQL 所需的工具。上下文工程代理预安装了代理技能,可帮助您生成配置。
启动代理环境。
让智能体帮助设置数据库连接,例如,提示“帮我设置数据库连接”。按照代理的说明在当前工作目录中创建配置文件,并将其命名为
autoctx/tools.yaml。如需应用新的
tools.yaml配置,请重新加载连接:- 在 Antigravity CLI 中,运行
/mcp并选择toolbox以重新启动。 - 在 Gemini CLI 中,运行
/mcp reload。 - 在 Claude Code 中,运行
/reload-plugins。
- 在 Antigravity CLI 中,运行
如需详细了解如何手动配置数据库配置文件,请参阅 MCP Toolbox 配置。
生成和优化上下文
上下文工程智能体提供了一组智能体技能和 MCP 工具,以增强编码智能体的上下文工程能力。您可以搭配使用这些工具来生成基准、衡量效果,并以迭代方式应用改进措施。不过,您可以从工作流程的任何阶段开始:
- 如果您已设置上下文,可以直接进行评估。
- 如果您有想要修正的失败查询,可以直接进行差距分析。
每项功能都描述了代理的操作、应用场景和调用命令。
示例提示展示了如何使用自然语言查询代理。如果智能体需要更多详细信息才能完成请求,它会提示您提供更多信息。
构建和扩充评估数据集
若要提升效果,您必须先衡量效果。如果没有包含用户问题及其预期 SQL 的黄金数据集,上下文工程就缺乏系统性验证。借助黄金数据集,每次更改都是可衡量的改进,您可以根据标准答案进行验证。
手动创建具有代表性的黄金数据集非常耗时,而且小型数据集可能会遗漏用户措辞的变化。智能体通过以下方式解决此问题:
- 正在根据您的数据库架构生成候选问题-SQL 对。
- 使用过滤条件变体、同义词和重新表述来扩充小型种子数据集。
(可选)您可以让代理针对数据库执行生成的 SQL。此验证可确认查询在添加到数据集之前是否能成功执行。
数据集是一个 JSON 文件,其中包含问题-SQL 对:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
获批的配对会填充到工作区中的 autoctx/golden.json 文件中,以便进行评估。您可以提供现有文件,也可以内嵌编写一些评估示例供代理扩展。
您可以使用以下示例提示来指示智能体:
- “根据我的架构生成评估数据集。”
- “这是一个初始问题和 SQL - 将其扩展为更广泛的数据集,并验证查询是否运行。”
生成基准上下文集
为避免从头开始创建上下文,您可以让代理从数据库架构和应用制品(例如业务规则、示例查询或 README 文件)中派生初始上下文集。虽然此基准上下文不是最终版本,但它提供了一个基于数据库模型的经过验证的起点。
您可以使用以下示例提示来指示智能体:
- “根据我的架构生成上下文集。”
- “使用这些架构和
requirements.md中的业务规则生成初始上下文。”
代理会提示您为实验命名,以便整理生成的制品,如果数据库架构较大,代理可能会要求您缩小范围。如需使用 Cloud SQL Studio 上传上下文,请在代理生成 JSON 文件后按照说明操作。
评估情境效果
建立上下文集和黄金数据集后,您可以让代理通过使用每个黄金问题查询数据代理的 QueryData API 来衡量上下文效果。代理会使用 Evalbench 将生成的 SQL 及其执行结果与预期答案进行比较,以处理比较事宜。
运行评估可提供以下信息:
- 定量指标,例如通过和未通过结果以及汇总得分,用于跟踪各个上下文迭代的进度。
- 内嵌对话摘要和详细的 CSV 报告,写入实验文件夹中的
eval_reports/目录。
如需开始评估,请提供黄金数据集路径和上下文集 ID。 如需了解如何查找上下文集 ID,请参阅查找代理上下文 ID。
您可以使用以下示例提示来指示智能体:
- “根据
golden.json评估我的上下文。” - “使用上次实验中的配置重新运行评估。”
如需重新运行之前生成的评估配置,而无需再次设置,请询问代理或直接调用 CLI:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
如需详细了解评估配置架构以及如何自定义评估运行,请参阅 Evalbench 文档。
执行差距分析并提出改进建议
如需解决查询失败问题,您必须确定其根本原因,例如列不正确、缺少表联接或模糊字词未解析。手动发现这些问题需要对评估报告进行广泛分析。
智能体可自动执行此分析和修正循环:
- 差距分析:代理读取评估结果和您的上下文,以对类似失败进行分组,并建议有针对性地添加上下文,例如模板、方面或值搜索。
- 建议的修正:代理会提出具体的修改建议,并可选择针对您的数据库测试 SQL 以验证解决方案。
- 基准保留:智能体将改进写入新 JSON 文件,并将其与基准上下文一起保存,从而保留原始文件。
您可以使用以下示例提示来指示智能体:
- “针对我的上次评估运行差距分析,并提出修复建议。”
- “针对
golden.json优化此上下文集。”
如需为下一次迭代做准备,请使用 Data Agents Studio 将改进后的上下文上传到目标上下文集,然后按照说明操作。
按需创作特定情境项
如果您已经知道所需的上下文,例如特定问题的模板、重复过滤器的 facet 或特定列的值搜索,则手动编写上下文 JSON 可能会导致参数名称、类型元数据或 fragment 语法出现序列化错误。智能体可处理 JSON 格式,让您专注于业务意图。
您还可以使用此功能进行临时更新,例如在需要支持新的查询模式或解决缺少架构详细信息的问题时。如需获取 JSON,请向智能体描述所需的上下文,而无需运行评估或设置实验。
当您接到一次性任务时,这也是合适的选择:利益相关者向您提供他们希望支持的新问题-SQL 对,或者您在代码审核期间发现缺少某个方面。您无需设置实验或运行评估即可修复此问题,只需描述您想要的内容,智能体就会生成 JSON。
您可以使用以下示例提示来指示智能体:
- “创建一个模板,用于回答‘加利福尼亚州有哪些机场?’这个问题,并使用 SQL 语句:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'。” - “为标记为‘红眼’的过滤条件
departure_time BETWEEN '00:00:00' AND '06:00:00'创建一个分面。” - “为
airports.iata创建值搜索。”
有关选择哪种上下文类型的理由
无论搜索的是模板、分面还是值,选择正确的上下文类型都有助于防止上下文膨胀和数据库查询回归。例如,使用模板而不是分面可能会导致规则重复,而在模板足以满足需求的情况下引入值搜索可能会增加查询延迟时间。如需查找正确的架构格式,请在创建上下文项之前,提示代理根据查询结构或数据库列推荐类型。智能体将说明其推理过程,帮助您了解上下文选项。
您可以使用以下示例提示来指示智能体:
- “我一直在多个查询中编写过滤条件
departure_time BETWEEN '00:00:00' AND '06:00:00'。“捕捉此场景的最佳方式是什么?” - "用户以自由文本形式描述航班状态,我想将这些描述与
flights.status相匹配。我应该设置哪种类型的价值搜索?” - “模板和功能块有何区别?我应该在何时使用它们?”
对上下文集应用批量操作
该代理支持批量更新,以便一致地管理大型上下文集。如果您需要同时更新多个上下文项,例如在数据库列重命名、代码值更改格式或模板引用已弃用的表时,代理可以跨每个受影响的项应用更改,而不会更改不相关的条目。
您可以使用以下示例提示来指示智能体:
- “读取
golden.txt并将所有配对项转换为模板。” - 在
context_set.json中,将引用“United”的任何商品的airline = 'UA'替换为airline = 'United Airlines'。请勿触碰无关物品。”
后续步骤
- 详细了解上下文集。
- 了解如何在 Cloud SQL Studio 中创建或删除上下文集。
- 了解如何测试上下文集。