
本文档介绍了如何创建和优化上下文集,以帮助在数据代理应用中实现高 QueryData 查询准确率。上下文工程代理可帮助您构建、评估和改进上下文集,方法是自动创建和优化上下文集。
如需了解上下文集和 QueryData,请参阅上下文集概览和QueryData 概览。如需构建企业级数据应用,文本到 SQL 模型的准确率通常需要接近 100%。不正确的查询结果会影响应用的整体可用性和用户体验。如需获得可解释的、与业务相关的答案并保持高准确率,需要进行上下文工程,即创建上下文并以迭代方式优化上下文以实现最佳准确率的过程。
通过为 QueryData 提供针对业务应用的上下文,您可以提供系统解决细微用户意图所需的精确 业务规则。
上下文工程代理
上下文工程代理可自动执行此优化工作流。您可以与代理对话,以处理临时任务来优化上下文。以下列表提供了一些自然语言提示示例,您可以使用这些提示来指示代理,以及代理的响应方式说明。使用这些示例来帮助构建和优化上下文:
- 失败分析的提示示例:"更新上下文,以便我们 正确识别机场,以用于‘迪士尼世界航班’等查询。"代理会分析失败情况,推断出差距,并建议添加适当的上下文项,例如值搜索查询。
- 上下文建议的提示示例:“阅读我的应用代码并建议 添加一些上下文。”代理会解析代码,推断出应用的网域,并建议哪些上下文项是相关的。
- 批量处理的提示示例: "以下是 10 个问题 和 SQL 查询示例。将它们转换为模板。”代理会批量处理您的输入并更新上下文集。
黄金数据集的重要性
如需优化上下文,您必须先创建一个与应用的自然语言输入匹配的数据集。代理可以帮助您构建此黄金数据集,该数据集由用户问题及其预期数据库查询组成。借助黄金数据集,您可以:
- 建立查询性能基准。
- 根据真实数据库查询验证更新。
- 衡量各个迭代的准确率提升情况。
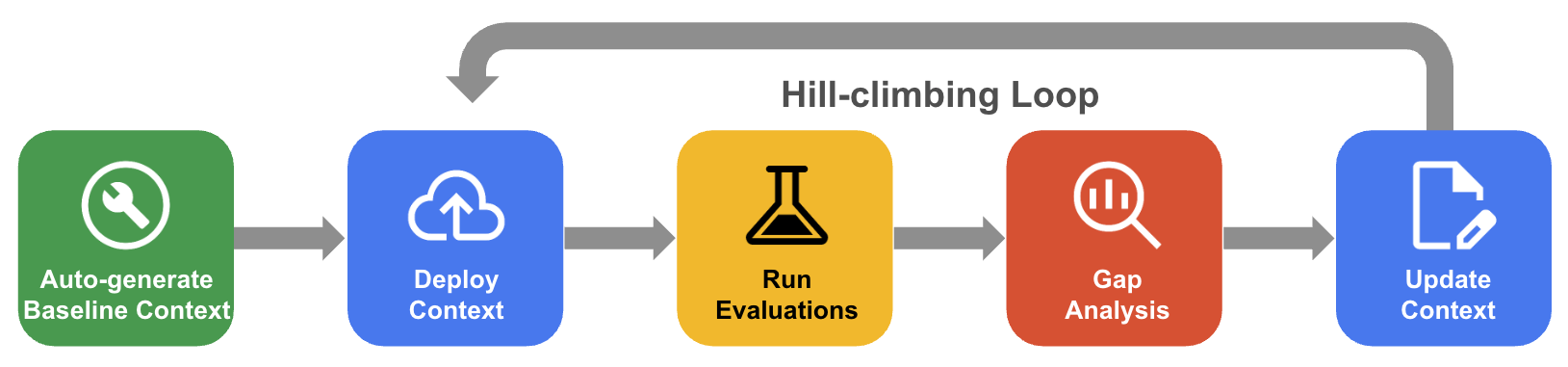
系统性的爬山过程
在系统性的爬山过程中,代理会通过评估黄金数据集、差距分析和更新来迭代改进上下文集,以使准确率接近 100%。
- 自动生成基准上下文:创建从数据库架构和应用工件派生的起始上下文集。
- 爬山优化工作流:让代理评估您的 QueryData 准确率,对失败情况执行差距分析,并自动提出 改进建议以提高准确率。
下图显示了系统性的爬山工作流:
准备工作
在使用上下文工程代理之前,请完成以下前提条件。
启用必需服务
为您的项目启用以下服务:准备 Cloud SQL 实例
- 确保您有权访问现有 Cloud SQL 实例或创建一个新实例。 如需了解详情,请参阅为 Cloud SQL创建实例。
- 确保在实例中创建数据库,您将在其中创建表。如需了解详情,请参阅在 Cloud SQL 实例上创建数据库。
所需的角色和权限
- 在实例级添加 IAM 用户或服务帐号。如需了解详情,请参阅向用户、服务帐号或群组添加 IAM 政策绑定。
- 在项目级向 IAM 用户或服务帐号授予
cloudsql.studioUser、cloudsql.instanceUser和geminidataanalytics.queryDataUser角色。如需了解详情,请参阅添加 项目的 IAM 政策绑定。 - 您必须让具有特权的用户向
IAM 用户或服务账号授予数据库权限。
GRANT SELECT PRIVILEGES ON * TO "IAM_USERNAME";。
如需了解 详情,请参阅向 单个 IAM 用户或服务账号授予数据库权限。
向 Cloud SQL 实例授予 executesql 权限
如需向 Cloud SQL 实例授予 executesql 权限并启用 Cloud SQL Data API,请运行以下命令:
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
PROJECT_ID:您的 Google Cloud 项目的 ID。INSTANCE_ID:Cloud SQL 实例的 ID。
为值搜索准备数据库
如需使用语义和三元语法值搜索,您必须将 Cloud SQL for MySQL 实例配置为支持向量嵌入和 N 元语法索引。
如需让 Cloud SQL for MySQL 实例执行语义值搜索,请启用以下标志。
启用
cloudsql_vector标志。gcloud sql instances patch INSTANCE_NAME --database-flags=cloudsql_vector=on启用
enable-google-ml-integration标志,以让 Cloud SQL for MySQL 实例与 Vertex AI 集成。gcloud sql instances patch INSTANCE_NAME --enable-google-ml-integration创建向量列以存储城市嵌入
ALTER TABLE `airports` ADD COLUMN `city_embedding` VECTOR(768);为城市名称生成和存储向量嵌入
UPDATE `airports` SET `city_embedding` = mysql.ml_embedding('text-embedding-005', `city`) WHERE `city` IS NOT NULL;
如需让 Cloud SQL for MySQL 实例执行三元值搜索,请按以下步骤操作:
启用
ngram_token_size标志。gcloud sql instances patch INSTANCE_NAME --database-flags=ngram_token_size=3为机场名称上的三元匹配创建 FULLTEXT 索引:
CREATE FULLTEXT INDEX `idx_ngram_airports_name` ON `airports`(`name`) WITH PARSER ngram;
准备环境
您可以从任何本地开发环境或 IDE 构建上下文集文件。 如需准备环境,请完成以下步骤:
- 安装上下文工程代理
- 设置数据库连接
安装上下文工程代理
上下文工程代理运行 Model Context Protocol (MCP) 服务器,该服务器需要 uv 来管理底层 Python 软件包。
按照 安装
uv中的说明安装uv。验证
uv是否已安装且可从命令行访问:uv --version
如需准备环境,请在您选择的智能体 Harness(例如 Antigravity CLI、Claude Code 或 Gemini CLI)中安装上下文工程智能体。
根据您选择的智能体 Harness,按照相应的安装步骤操作:
Antigravity CLI
如需在 Antigravity CLI 中安装上下文工程代理,请按以下步骤操作:
- 安装 Antigravity CLI。请参阅 Antigravity CLI 使用入门。
- 安装上下文工程代理插件,其中包括用于生成上下文的工作流。将 VERSION 替换为所需的 已发布版本:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- 启动 Antigravity CLI:
agy
- 可选。更新插件:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
如需在 Claude Code 中安装上下文工程代理,请按以下步骤操作:
- 添加插件市场:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- 安装插件:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- 重新加载插件以启用更改:
/reload-plugins
- 可选。更新插件:
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI(已废弃)
如需在 Gemini CLI 中安装上下文工程代理,请按以下步骤操作:
- 安装 Gemini CLI。请参阅 Gemini CLI 使用入门。
- 安装扩展程序:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- 可选。更新扩展程序:
gemini extensions update mcp-db-context-enrichment
设置数据库连接
代理需要数据库连接来提取架构,并且能够验证生成的 SQL 上下文的语法。如需让代理与数据库互动,请配置身份验证凭据并定义数据库连接配置。
配置应用默认凭据
配置 应用默认凭证 (ADC),以提供用户凭据,供 Google Cloud 上下文工程代理访问资源:
- Toolbox MCP 服务器:使用凭据连接到数据库、提取架构并运行 SQL 进行验证。
- Evalbench:使用凭据调用 QueryData 进行评估。
在终端中运行以下命令进行身份验证:
gcloud auth application-default login配置数据库连接文件
代理需要数据库连接才能生成上下文, MCP Toolbox 支持并 在配置文件中定义该连接。
配置文件指定了数据库来源以及提取架构或执行 SQL 所需的工具。上下文工程代理预安装了代理技能,可帮助您生成配置。
启动代理环境。
让代理帮助设置数据库连接,例如提示“help me set up the database connection”。 按照代理的说明在当前工作目录中创建配置文件,文件名为
autoctx/tools.yaml。如需应用新的
tools.yaml配置,请重新加载连接:- 在 Antigravity CLI 中,运行
/mcp并选择toolbox以重启。 - 在 Gemini CLI 中,运行
/mcp reload。 - 在 Claude Code 中,运行
/reload-plugins。
- 在 Antigravity CLI 中,运行
如需详细了解如何手动配置数据库配置文件, 请参阅 MCP Toolbox 配置。
生成和优化上下文
上下文工程代理提供了一组代理技能和 MCP 工具,以增强编码代理的上下文工程能力。您可以搭配使用这些工具来生成基准、衡量效果并以迭代方式应用改进。不过,您可以从工作流的任何阶段开始:
- 如果您已有上下文集,可以直接进行评估。
- 如果您有想要修复的失败查询,可以直接进行差距分析。
每项功能都介绍了代理的操作、用例和调用命令。
示例提示展示了如何使用自然语言查询代理。如果代理需要更多详细信息才能完成请求,它会提示您进行澄清。
构建和扩充评估数据集
如需提高性能,您必须先精准衡量。如果没有黄金数据集(由用户问题及其预期 SQL 组成),上下文工程就缺乏系统性的验证。借助黄金数据集,每次更改都是可衡量的改进,您可以根据标准答案进行验证。
手动创建具有代表性的黄金数据集非常耗时,而小型数据集可能会遗漏用户措辞的变化。代理通过以下方式解决此问题:
- 根据数据库架构生成候选问题-SQL 对。
- 使用过滤条件变体、同义词和改述来扩充小型种子数据集。
(可选)您可以让代理针对数据库执行生成的 SQL。此验证可确保查询在添加到数据集之前成功执行。
数据集是一个包含问题-SQL 对的 JSON 文件:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
获批准的对会填充到工作区中的 autoctx/golden.json 文件中,以便进行评估。您可以提供现有文件,也可以内联编写一些评估示例供代理扩充。
您可以使用以下示例提示来指示代理:
- “根据我的架构生成评估数据集。”
- “这是一个种子问题和 SQL - 将其扩充为更广泛的数据集并验证 查询是否运行。”
生成基准上下文集
为避免从头开始创建上下文,您可以让代理从数据库架构和应用工件(例如业务规则、示例查询或 README 文件)派生初始上下文集。虽然此基准上下文不是最终的,但它提供了一个基于数据库模型且经过验证的起点。
您可以使用以下示例提示来指示代理:
- “根据我的架构生成上下文集。”
- “使用这些架构和
中的业务规则生成初始上下文。”
requirements.md
代理会提示您为实验命名,以便整理生成的工件,如果数据库架构很大,可能会要求您缩小范围。如需使用 Cloud SQL Studio 上传上下文,请在代理生成 JSON 文件后按照 说明操作。
评估上下文效果
建立上下文集和黄金数据集后,您可以让代理通过使用每个黄金问题查询数据代理的 QueryData API 来衡量上下文性能。代理会使用 Evalbench将生成的 SQL 及其执行结果与预期答案进行比较,以处理 比较。
运行评估可提供以下信息:
- 定量指标,例如通过和失败结果以及汇总得分,用于跟踪各个上下文迭代的进度。
- 内联对话摘要和详细的 CSV 报告,这些报告会写入实验文件夹中的
eval_reports/目录。
如需开始评估,请提供黄金数据集路径和上下文集 ID。 如需了解如何查找上下文集 ID,请参阅查找代理上下文 ID。
您可以使用以下示例提示来指示代理:
- “根据
golden.json评估我的上下文。” - “使用上次实验中的配置重新运行评估。”
如需重新运行之前生成的评估配置而不重新设置,请让代理执行此操作或直接调用 CLI:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
如需详细了解评估配置架构以及如何自定义 评估运行,请参阅 Evalbench 文档。
执行差距分析并提出改进建议
如需解决查询失败问题,您必须找出其根本原因,例如列不正确、缺少表联接或未解决的模糊字词。手动找出这些问题需要对评估报告进行广泛分析。
代理会自动执行此分析和更正循环:
- 差距分析:代理会读取评估结果和上下文集,以将类似的失败情况分组,并建议添加有针对性的上下文,例如模板、分面或值搜索。
- 建议的修复:代理会提出具体的修改建议,并可以选择针对数据库测试 SQL 以验证解决方案。
- 基准保留:代理会将改进写入新 JSON 文件,并保留原始文件。
您可以使用以下示例提示来指示代理:
- “对上次评估运行差距分析并提出修复建议。”
- “根据
golden.json优化此上下文集。”
如需为下一次迭代做准备,请使用 Data Agents Studio 将改进后的上下文上传到目标 上下文集,然后按照 说明操作。
按需编写特定上下文项
如果您已经知道所需的上下文,例如特定问题的模板、重复过滤条件的分面或特定列的值搜索,手动编写上下文 JSON 可能会在参数名称、类型元数据或片段语法中引入序列化错误。代理会处理 JSON 格式,让您专注于业务意图。
您还可以将此功能用于临时更新,例如当您需要支持新的查询模式或解决架构详细信息缺失问题时。如需获取 JSON,请向代理描述所需的上下文,而无需运行评估或设置实验。
当您接到一次性任务时,这也是正确的选择:利益相关者向您提供他们希望支持的新问题-SQL 对,或者您在代码审核期间发现缺少分面。您无需设置实验或运行评估即可修复此问题 - 只需描述您想要的内容,代理就会生成 JSON。
您可以使用以下示例提示来指示代理:
- “为以下内容创建模板:‘加利福尼亚州有哪些机场?’,SQL 为
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'。” - “为过滤条件
departure_time BETWEEN '00:00:00' AND '06:00:00'创建一个名为‘red eye’的分面。” - “为
airports.iata创建值搜索。”
推断出要选择的上下文类型
无论选择的是模板、分面还是值搜索,选择正确的上下文类型都有助于防止上下文膨胀和数据库查询回归。例如,使用模板而不是分面可能会导致规则重复,而在模板足够的情况下引入值搜索可能会增加查询延迟时间。如需查找正确的架构格式,请在创建上下文项之前,提示代理根据查询结构或数据库列推荐类型。代理会解释其推理过程,以帮助您了解上下文选项。
您可以使用以下示例提示来指示代理:
- “我一直在许多查询中编写过滤条件
departure_time BETWEEN '00:00:00' AND '06:00:00'。捕获此过滤条件的最佳方式是什么?" - “用户以自由文本形式描述航班状态,我想将它们与
flights.status匹配。我应该设置哪种类型的值搜索?" - “模板和分面之间有什么区别?我应该在何时 使用每种类型?”
在上下文集中应用批量操作
代理支持批量更新,以便一致地管理大型上下文集。如果您需要同时更新多个上下文项(例如,当数据库列重命名、代码值更改格式或模板引用已废弃的表时),代理可以在不更改无关条目的情况下,对每个受影响的项应用更改。
您可以使用以下示例提示来指示代理:
- “读取
golden.txt并将所有对转换为模板。” - “在
context_set.json中,将引用‘United’的任何项的airline = 'UA'替换为airline = 'United Airlines'。不要更改无关项。”
后续步骤
- 详细了解上下文集。
- 了解如何在 Cloud SQL Studio 中创建或删除上下文集。
- 了解如何测试上下文集。