
En este documento, se describe cómo crear y optimizar los conjuntos de contexto que ayudan a lograr una alta precisión en las consultas de QueryData en tus aplicaciones de agentes de datos. El agente de ingeniería de contexto te ayuda a crear, evaluar y mejorar conjuntos de contexto automatizando su creación y optimización.
Para obtener información sobre los conjuntos de contexto y QueryData, consulta Descripción general de los conjuntos de contexto y Descripción general de QueryData.Para compilar aplicaciones de datos de nivel empresarial, la exactitud del modelo de texto a SQL suele alcanzar una calidad cercana al 100%. Los resultados de búsqueda incorrectos afectan la usabilidad general de la aplicación y la experiencia del usuario. Para lograr respuestas explicables y pertinentes para la empresa con un alto nivel de precisión, se requiere ingeniería de contexto, que es el proceso de crear y optimizar de forma iterativa el contexto para lograr una precisión óptima.
Si proporcionas QueryData con el contexto segmentado para tu aplicación comercial, proporcionas las reglas comerciales precisas que el sistema necesita para resolver la intención matizada del usuario.
Agente de ingeniería de contexto
El agente de ingeniería de contexto automatiza este flujo de trabajo de optimización. Puedes conversar con el agente para que realice tareas ad hoc y optimice tu contexto. En la siguiente lista, se proporcionan ejemplos de instrucciones en lenguaje natural que puedes usar para darle instrucciones al agente, junto con una descripción de cómo responde el agente. Usa estos ejemplos para crear y optimizar tu contexto:
- Ejemplo de instrucción para el análisis de errores: "Actualiza el contexto para que identifiquemos correctamente el aeropuerto en búsquedas como 'vuelos a Disney World'". El agente analiza la falla, explica la brecha y recomienda agregar un elemento de contexto adecuado, como una búsqueda de valores.
- Ejemplo de instrucción para sugerir contexto: "Lee el código de mi app y sugiere algo de contexto para agregar". El agente analiza el código, razona sobre el dominio de tu aplicación y sugiere qué elementos de contexto serían relevantes.
- Ejemplo de instrucción para el procesamiento masivo: "Aquí hay 10 ejemplos de preguntas y consultas en SQL. Conviértelos en plantillas". El agente procesa tus entradas de forma masiva y actualiza tu conjunto de contexto.
Importancia del conjunto de datos de referencia
Para optimizar tu contexto, primero debes crear un conjunto de datos que coincida con las entradas en lenguaje natural de tu aplicación. El agente puede ayudarte a crear este conjunto de datos de referencia, que consta de preguntas de los usuarios y sus consultas de bases de datos esperadas. Un conjunto de datos de referencia te permite hacer lo siguiente:
- Establece una referencia para el rendimiento de las búsquedas.
- Validar las actualizaciones con las consultas de la base de datos de verdad fundamental
- Mide las mejoras en la precisión en cada iteración.
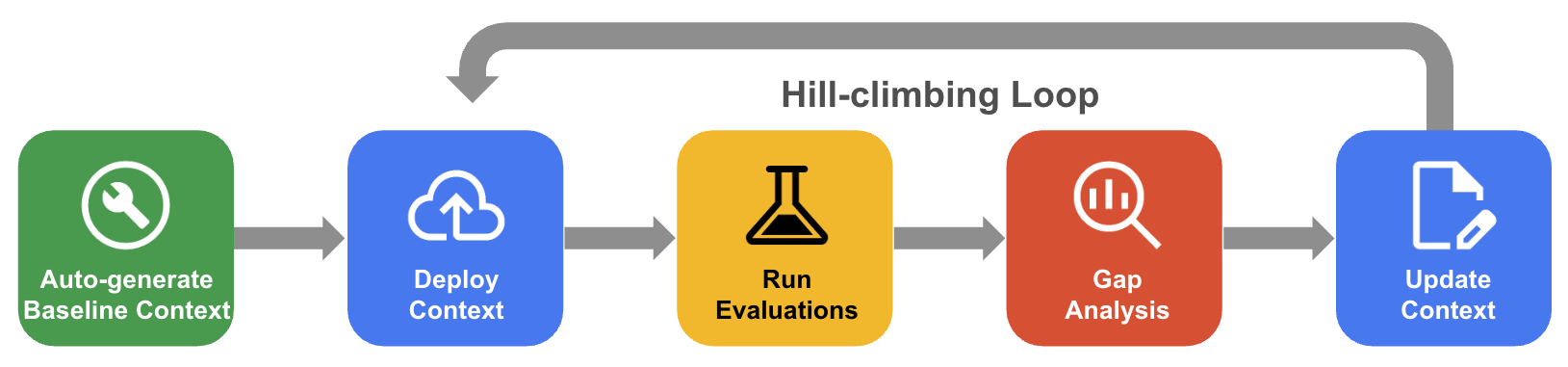
El proceso sistemático de ascenso de colinas
En el ascenso de colina sistemático, el agente mejora de forma iterativa un conjunto de contexto a través de la evaluación del conjunto de datos de referencia, el análisis de brechas y las actualizaciones para aumentar la precisión hasta casi el 100%.
- Generar automáticamente el contexto de referencia: Crea un conjunto de contexto inicial derivado del esquema de tu base de datos y los artefactos de la aplicación.
- Flujo de trabajo de optimización de ascenso de colina: Permite que el agente evalúe la exactitud de tus datos de búsqueda, realice un análisis de brechas en los errores y proponga automáticamente mejoras para aumentar la exactitud.
En el siguiente diagrama, se muestra el flujo de trabajo sistemático de ascenso de colina:
Antes de comenzar
Completa los siguientes requisitos previos antes de usar el agente de ingeniería de contexto.
Habilita los servicios obligatorios
Habilita los siguientes servicios para tu proyecto:Prepara una instancia de Cloud SQL
- Asegúrate de tener acceso a una instancia de Cloud SQL existente o crea una nueva. Para obtener más información, consulta Crea instancias para Cloud SQL.
- Asegúrate de crear una base de datos en tu instancia en la que crearás las tablas. Para obtener más información, consulta Crea una base de datos en la instancia de Cloud SQL.
Roles y permisos requeridos
- Agrega un usuario o una cuenta de servicio de IAM a nivel de la instancia. Para obtener más información, consulta Agrega una vinculación de política de IAM a un usuario, una cuenta de servicio o un grupo.
- Otorga los roles
cloudsql.studioUser,cloudsql.instanceUserygeminidataanalytics.queryDataUseral usuario o la cuenta de servicio de IAM a nivel del proyecto. Para obtener más información, consulta Cómo agregar una vinculación de política de IAM para un proyecto. - Debes tener un usuario con privilegios para otorgar privilegios de base de datos al usuario o la cuenta de servicio de IAM.
GRANT SELECT PRIVILEGES ON * TO "IAM_USERNAME";.
Para obtener más información, consulta Otorga privilegios de base de datos a un usuario o una cuenta de servicio de IAM individuales.
Otorga permiso de executesql a la instancia de Cloud SQL
Para otorgar el permiso executesql a la instancia de Cloud SQL y habilitar la API de Cloud SQL Data, ejecuta el siguiente comando:
gcloud config set project PROJECT_ID gcloud components update gcloud beta sql instances patch INSTANCE_ID --data-api-access=ALLOW_DATA_API
PROJECT_ID: Es el ID de tu proyecto de Google Cloud .INSTANCE_ID: Es el ID de tu instancia de Cloud SQL.
Prepara la base de datos para las búsquedas de valores
Para usar las búsquedas de valores semánticos y trigramas, debes configurar tu instancia de Cloud SQL para MySQL de modo que admita embeddings de vectores y la indexación de n-gramas.
Para permitir que la instancia de Cloud SQL para MySQL realice búsquedas de valores semánticos, habilita las siguientes marcas.
Habilita la marca
cloudsql_vector.gcloud sql instances patch INSTANCE_NAME --database-flags=cloudsql_vector=onHabilita la marca
enable-google-ml-integrationpara permitir que la instancia de Cloud SQL para MySQL se integre en Vertex AI.gcloud sql instances patch INSTANCE_NAME --enable-google-ml-integrationCrea una columna de vectores para almacenar los embeddings de ciudades
ALTER TABLE `airports` ADD COLUMN `city_embedding` VECTOR(768);Genera y almacena embeddings de vectores para los nombres de las ciudades
UPDATE `airports` SET `city_embedding` = mysql.ml_embedding('text-embedding-005', `city`) WHERE `city` IS NOT NULL;
Para permitir que la instancia de Cloud SQL para MySQL realice búsquedas de valores de trigramas, sigue estos pasos:
Habilita la marca
ngram_token_size.gcloud sql instances patch INSTANCE_NAME --database-flags=ngram_token_size=3Crea un índice FULLTEXT para la coincidencia de trigramas en el nombre del aeropuerto:
CREATE FULLTEXT INDEX `idx_ngram_airports_name` ON `airports`(`name`) WITH PARSER ngram;
Prepara el entorno
Puedes compilar archivos de conjunto de contexto desde cualquier entorno de desarrollo local o IDE. Para preparar tu entorno, completa los siguientes pasos:
- Instala el agente de ingeniería de contexto
- Configura la conexión de la base de datos
Instala el agente de ingeniería de contexto
El agente de ingeniería de contexto ejecuta el servidor del Protocolo de contexto del modelo (MCP) que requiere uv para administrar los paquetes de Python subyacentes.
Instala
uvsiguiendo las instrucciones que se indican en Instalauv.Verifica que
uvesté instalado y que se pueda acceder a él desde la línea de comandos:uv --version
Para preparar tu entorno, instala el agente de ingeniería de contexto en el arnés de agente seleccionado, como la CLI de Antigravity, Claude Code o Gemini CLI.
Según el arnés del agente que hayas seleccionado, sigue los pasos de instalación correspondientes:
CLI de Antigravity
Para instalar el agente de ingeniería de contexto en la CLI de Antigravity, sigue estos pasos:
- Instala la CLI de Antigravity. Consulta Comienza a usar la CLI de Antigravity.
- Instala el complemento del agente de ingeniería de contexto, que incluye flujos de trabajo para la generación de contexto. Reemplaza VERSION por la versión lanzada requerida:
agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/VERSION
- Inicia la CLI de Antigravity:
agy
- Es opcional. Actualiza el complemento:
agy plugin uninstall google-cloud-db-context-engineering agy plugin install https://github.com/GoogleCloudPlatform/db-context-enrichment/tree/NEW_VERSION
Claude Code
Para instalar el agente de ingeniería de contexto en Claude Code, sigue estos pasos:
- Agrega el mercado de complementos:
/plugin marketplace add https://github.com/GoogleCloudPlatform/db-context-enrichment.git
- Instala el complemento:
/plugin install db-context-engineering@db-context-enrichment-marketplace
- Vuelve a cargar los complementos para activar los cambios:
/reload-plugins
- Es opcional. Actualiza el complemento:
/plugin update db-context-engineering@db-context-enrichment-marketplace
Gemini CLI (obsoleto)
Para instalar el agente de ingeniería de contexto en la CLI de Gemini, sigue estos pasos:
- Instala Gemini CLI. Consulta Comienza a usar Gemini CLI.
- Instala la extensión:
gemini extensions install https://github.com/GoogleCloudPlatform/db-context-enrichment
- Es opcional. Actualiza la extensión:
gemini extensions update mcp-db-context-enrichment
Configura la conexión de la base de datos
El agente requiere una conexión a la base de datos para recuperar esquemas y la capacidad de validar la sintaxis del contexto de SQL generado. Para permitir que el agente interactúe con tu base de datos, configura las credenciales de autenticación y define la configuración de conexión de la base de datos.
Configura las credenciales predeterminadas de la aplicación
Configura las credenciales predeterminadas de la aplicación (ADC) para proporcionar credenciales de usuario para acceder a los recursos de Google Cloud desde el agente de ingeniería de contexto:
- Servidor de MCP de Toolbox: Usa credenciales para conectarse a tu base de datos, recuperar esquemas y ejecutar SQL para la validación.
- Evalbench: Usa credenciales para invocar QueryData para la evaluación.
Ejecuta los siguientes comandos en tu terminal para autenticarte:
gcloud auth application-default loginConfigura el archivo de conexión de la base de datos
El agente requiere una conexión a la base de datos para la generación de contexto, que MCP Toolbox admite y define dentro de un archivo de configuración.
El archivo de configuración especifica la fuente de tu base de datos y las herramientas necesarias para recuperar esquemas o ejecutar SQL. El agente de ingeniería de contexto incluye Habilidades de agente preinstaladas para ayudarte a generar la configuración.
Inicia el entorno del agente.
Pídele al agente que te ayude a configurar la conexión de la base de datos. Por ejemplo, puedes indicarle "Ayúdame a configurar la conexión de la base de datos". Sigue las instrucciones del agente para crear el archivo de configuración en tu directorio de trabajo actual como
autoctx/tools.yaml.Para aplicar la nueva configuración de
tools.yaml, vuelve a cargar la conexión:- En la CLI de Antigravity, ejecuta
/mcpy seleccionatoolboxpara reiniciar. - En Gemini CLI, ejecuta
/mcp reload. - En Claude Code, ejecuta
/reload-plugins.
- En la CLI de Antigravity, ejecuta
Para obtener más información sobre cómo configurar manualmente el archivo de configuración de la base de datos, consulta Configuración de MCP Toolbox.
Genera y optimiza el contexto
El agente de ingeniería de contexto proporciona un conjunto de habilidades del agente y herramientas de MCP para mejorar la capacidad de ingeniería de contexto de tu agente de programación. Puedes usar estas herramientas en conjunto para generar un valor de referencia, medir la efectividad y aplicar mejoras de forma iterativa. Sin embargo, puedes comenzar en cualquier etapa del flujo de trabajo:
- Si ya tienes un conjunto de contexto, puedes proceder directamente a la evaluación.
- Si tienes consultas que fallan y quieres corregirlas, puedes pasar directamente al análisis de brechas.
Cada capacidad describe las acciones, los casos de uso y los comandos de invocación del agente.
En los ejemplos de instrucciones, se muestra cómo puedes hacerle preguntas al agente en lenguaje natural. Si el agente requiere detalles adicionales para completar una solicitud, te pedirá que le brindes más información.
Compilar y expandir conjuntos de datos de evaluación
Para mejorar el rendimiento, primero debes medirlo. La ingeniería de contexto sin un conjunto de datos de referencia, que consiste en preguntas de los usuarios junto con su SQL esperado, carece de verificación sistemática. Con un conjunto de datos de referencia, cada cambio es una mejora medible que puedes validar en función de la verdad fundamental.
Crear manualmente un conjunto de datos de referencia representativo lleva mucho tiempo, y los conjuntos de datos pequeños pueden no incluir variaciones en la redacción de los usuarios. El agente resuelve este problema de la siguiente manera:
- Generar pares de preguntas y SQL candidatos según el esquema de tu base de datos
- Expande un pequeño conjunto de datos iniciales con variaciones de filtros, sinónimos y reformulaciones.
De manera opcional, puedes permitir que el agente ejecute el código SQL generado en tu base de datos. Esta verificación confirma que las consultas se ejecutan correctamente antes de que las agregues al conjunto de datos.
El conjunto de datos es un archivo JSON que contiene pares de preguntas y SQL:
[
{
"id": "example_001",
"nlq": "What is the total revenue for the top 5 products?",
"golden_sql": "SELECT product_id, sum(net_revenue) FROM sales GROUP BY product_id ORDER BY sum(net_revenue) DESC LIMIT 5;"
}
]
Los pares aprobados completan el archivo autoctx/golden.json en tu espacio de trabajo, donde están listos para la evaluación. Puedes proporcionar un archivo existente o escribir algunos ejemplos de evaluación intercalados para que el agente los expanda.
Puedes usar los siguientes ejemplos de instrucciones para indicarle al agente qué debe hacer:
- "Genera un conjunto de datos de evaluación a partir de mi esquema".
- "Aquí tienes una pregunta inicial y una consulta en SQL. Amplíala para que abarque un conjunto de datos más amplio y verifica que las consultas se ejecuten correctamente".
Genera un conjunto de información contextual de referencia
Para evitar crear contexto desde cero, puedes permitir que el agente derive un conjunto de contexto inicial a partir del esquema de tu base de datos y los artefactos de la aplicación, como reglas de negocio, consultas de muestra o archivos README. Si bien este contexto de referencia no es definitivo, proporciona un punto de partida validado basado en tu modelo de base de datos.
Puedes usar los siguientes ejemplos de instrucciones para indicarle al agente qué debe hacer:
- "Genera un conjunto de contexto a partir de mi esquema".
- "Genera el contexto inicial con estos esquemas y las reglas de negocio en
requirements.md".
El agente te pedirá que le pongas un nombre al experimento, lo que organizará los artefactos generados, y podría pedirte que acotes el alcance si el esquema de tu base de datos es grande. Para subir el contexto con Cloud SQL Studio, sigue las instrucciones después de que el agente genere el archivo JSON.
Evalúa la eficacia del contexto
Después de establecer un conjunto de contexto y un conjunto de datos de referencia, puedes permitir que el agente mida el rendimiento del contexto consultando la API de QueryData de tu agente de datos con cada pregunta de referencia. El agente compara el código SQL generado y sus resultados de ejecución con la respuesta esperada usando Evalbench para controlar la comparación.
Ejecutar una evaluación proporciona lo siguiente:
- Métricas cuantitativas, como los resultados de aprobación y rechazo, y las puntuaciones agregadas, para hacer un seguimiento del progreso en las iteraciones del contexto
- Un resumen de la conversación intercalado y los informes detallados en formato CSV escritos en el directorio
eval_reports/de la carpeta del experimento.
Para iniciar una evaluación, proporciona la ruta del conjunto de datos de referencia y el ID del conjunto de contexto. Para obtener información sobre cómo encontrar el ID del conjunto de contexto, consulta Cómo encontrar el ID del contexto del agente.
Puedes usar los siguientes ejemplos de instrucciones para indicarle al agente qué debe hacer:
- "Evalúa mi contexto en relación con
golden.json". - "Vuelve a ejecutar la evaluación con la configuración de mi último experimento".
Para volver a ejecutar una configuración de evaluación generada anteriormente sin volver a configurarla, pregúntale al agente o invoca la CLI directamente:
uvx google-evalbench --run_config=autoctx/experiments/my-experiment/eval_configs/run_config.json
Para obtener detalles sobre el esquema de configuración de la evaluación y cómo personalizar las ejecuciones de evaluación, consulta la documentación de Evalbench.
Realizar análisis de brechas y proponer mejoras
Para resolver los errores de las consultas, debes identificar sus causas raíz, como columnas incorrectas, uniones de tablas faltantes o términos aproximados no resueltos. Identificar estos problemas de forma manual requiere un análisis exhaustivo de los informes de evaluación.
El agente automatiza este bucle de análisis y corrección:
- Análisis de brechas: El agente lee los resultados de la evaluación y tu conjunto de contexto para agrupar fallas similares y recomendar adiciones de contexto específicas, como plantillas, facetas o búsquedas de valores.
- Correcciones propuestas: El agente propone ediciones concretas y, de manera opcional, prueba el código SQL en tu base de datos para verificar la resolución.
- Conservación del modelo de referencia: El agente escribe las mejoras en un nuevo archivo JSON junto con tu contexto de referencia, lo que conserva los archivos originales.
Puedes usar los siguientes ejemplos de instrucciones para indicarle al agente qué debe hacer:
- "Realiza un análisis de brechas en mi última evaluación y propón correcciones".
- "Optimiza este conjunto de contexto en función de
golden.json".
Para prepararte para la próxima iteración, sube el contexto mejorado al conjunto de contexto objetivo con Data Agents Studio. Para ello, sigue las instrucciones.
Elementos contextuales específicos del autor a pedido
Si ya conoces el contexto requerido, como una plantilla para una pregunta específica, una faceta para un filtro repetido o una búsqueda de valores para una columna en particular, escribir el JSON de contexto de forma manual puede generar errores de serialización en los nombres de los parámetros, los metadatos de tipo o la sintaxis de fragmentos. El agente controla el formato JSON para que te enfoques en la intención de tu empresa.
También puedes usar esta función para realizar actualizaciones ad hoc, por ejemplo, cuando necesites admitir un nuevo patrón de búsqueda o abordar un detalle faltante del esquema. Para obtener el JSON, describe el contexto requerido al agente sin ejecutar una evaluación ni configurar un experimento.
Esta también es la capacidad adecuada para usar cuando te asignan una tarea única: un interesado te da un nuevo par de preguntas y SQL que quiere que se admita, o bien detectas una faceta faltante durante una revisión de código. No es necesario que configures un experimento ni que ejecutes una evaluación para corregirlo. Describe lo que deseas y el agente producirá el JSON.
Puedes usar los siguientes ejemplos de instrucciones para indicarle al agente qué debe hacer:
- "Crea una plantilla para '¿Qué aeropuertos hay en California?' con SQL:
SELECT name FROM airports WHERE country = 'United States' AND state = 'CA'". - "Crea una faceta para el filtro
departure_time BETWEEN '00:00:00' AND '06:00:00'etiquetado como "ojos rojos"". - "Crea una búsqueda de valores para
airports.iata".
Razona sobre qué tipo de contexto seleccionar
Seleccionar el tipo de contexto correcto, independientemente de si se trata de una búsqueda de plantillas, facetas o valores, ayuda a evitar la sobrecarga de contexto y las regresiones de consultas de bases de datos. Por ejemplo, usar una plantilla en lugar de una faceta puede generar reglas duplicadas, mientras que las búsquedas de valores introducidas en los casos en que una plantilla es suficiente pueden aumentar la latencia de las búsquedas. Para encontrar el formato de esquema correcto, pídele al agente que recomiende un tipo según la estructura de la búsqueda o las columnas de la base de datos antes de crear elementos de contexto. El agente explica su razonamiento para ayudarte a comprender las opciones de contexto.
Puedes usar los siguientes ejemplos de instrucciones para indicarle al agente qué debe hacer:
- "Escribo el filtro
departure_time BETWEEN '00:00:00' AND '06:00:00'en muchas búsquedas. ¿Cuál es la mejor manera de capturar esto?" - "Los usuarios describen el estado del vuelo en texto libre y quiero correlacionarlos con
flights.status. ¿Qué tipo de búsqueda de valores debería configurar?" - "¿Cuál es la diferencia entre una plantilla y una faceta, y cuándo debo usar cada una?"
Aplica operaciones masivas en un conjunto de contexto
El agente admite actualizaciones masivas para administrar grandes conjuntos de contexto de manera coherente. Si necesitas actualizar varios elementos de contexto de forma simultánea, por ejemplo, cuando se cambia el nombre de una columna de la base de datos, un valor de código cambia de formato o las plantillas hacen referencia a una tabla obsoleta, el agente puede aplicar el cambio en cada elemento afectado sin alterar las entradas no relacionadas.
Puedes usar los siguientes ejemplos de instrucciones para indicarle al agente qué debe hacer:
- "Lee
golden.txty convierte todos los pares en plantillas". - "En
context_set.json, reemplazaairline = 'UA'porairline = 'United Airlines'para cualquier elemento que haga referencia a "United". No toques los elementos que no estén relacionados".
¿Qué sigue?
- Obtén más información sobre los conjuntos de contexto.
- Obtén más información para crear o borrar un conjunto de contexto en Cloud SQL Studio.
- Obtén más información para probar un conjunto de contexto.