

프로비저닝된 처리량 (PT)은 Gemini Enterprise Agent Platform의 처리량을 예약하는 고정 비용, 고정 기간 구독이며 여러 기간으로 제공됩니다. 처리량을 예약하려면 모델과 모델이 실행되는 사용 가능한 위치를 지정해야 합니다.
이 페이지에서는 프로비저닝된 처리량의 작동 방식, 초과 사용량을 제어하거나 프로비저닝된 처리량을 우회하는 방법, 사용량을 모니터링하는 방법을 설명합니다.
프로비저닝된 처리량을 사용하는 경우
다음 고려사항 중 하나라도 사용 사례에 적용되는 경우 프로비저닝된 처리량을 사용하는 것이 좋습니다.
- 중요 워크로드에 지속적으로 높은 처리량이 필요합니다. 처리량 측정은 모델에 따라 다릅니다.
- 애플리케이션 사용자에게 일관되고 예측 가능한 환경을 제공하려고 합니다.
- 고정된 월별 또는 주별 요금을 지불하고 초과 사용을 관리하면서 확정적인 생성형 AI 비용을 지출하고 싶습니다.
프로비저닝된 처리량은 Gemini Enterprise Agent Platform의 여러 소비 옵션 중 하나입니다. 모든 소비 옵션에 대해 알아보려면 소비 옵션을 참고하세요.
프로비저닝된 처리량의 작동 방식
이 섹션에서는 할당량 적용 기간 동안 할당량 확인을 사용하여 프로비저닝된 처리량이 작동하는 방식을 설명합니다.
프로비저닝된 처리량 할당량 확인
프로비저닝된 처리량 최대 할당량은 구매한 생성형 AI 확장 단위 (GSU) 수와 GSU당 처리량의 배수입니다. 최대 프로비저닝된 처리량 할당량이 적용되는 빈도인 할당량 적용 기간 내에 요청할 때마다 확인됩니다.
요청이 수신될 때 실제 응답 크기는 알 수 없습니다. 실시간 애플리케이션의 응답 속도가 우선되므로 프로비저닝된 처리량은 출력 토큰 크기를 예상합니다. 초기 예상치가 사용 가능한 프로비저닝된 처리량 최대 할당량을 초과하면 요청이 사용한 만큼만 지불로 처리됩니다. 그렇지 않으면 프로비저닝된 처리량으로 처리됩니다. 초기 예상치를 프로비저닝된 처리량 최대 할당량과 비교하여 결정합니다.
응답이 생성되고 실제 출력 토큰 크기가 알려지면 예상치와 실제 사용량의 차이를 사용 가능한 프로비저닝된 처리량 할당량에 더하여 실제 사용량과 할당량을 조정합니다.
프로비저닝된 처리량 할당량 적용 기간
Gemini Enterprise 에이전트 플랫폼은 Gemini 모델에 프로비저닝된 처리량 할당량을 적용하는 동시에 동적 윈도우를 적용합니다. 이를 통해 급증하기 쉬운 트래픽에 최적의 안정성을 제공합니다. 고정된 기간 대신 에이전트 플랫폼은 모델 유형과 프로비저닝한 GSU 수에 따라 자동으로 조정되는 유연한 기간에 할당량을 적용합니다. 따라서 경우에 따라 일시적으로 초당 할당량을 초과하는 우선순위 지정 트래픽이 발생할 수 있습니다. 하지만 기간 동안 할당량을 초과해서는 안 됩니다. 이 기간은 Agent Platform 내부 시간을 기반으로 하며 요청 시점과는 무관합니다.
할당량 시행 기간 작동 방식
강제 적용 기간은 제한되기 전에 초당 한도를 초과할 수 있는 양을 결정합니다. 이 창은 자동으로 적용됩니다. 이러한 기간은 성능과 안정성을 최적화하기 위해 변경될 수 있습니다.
소규모 GSU 할당 (GSU 3개 이하): 창은 중단 없이 더 큰 개별 요청을 처리할 수 있도록 40~120초 범위일 수 있습니다.
예를 들어
gemini-2.5-flashGSU 1개를 구매하면 초당 평균 2,690개의 토큰의 연속 처리량을 얻을 수 있습니다. 120초 동안의 총 사용량은 322,800토큰 (초당 2,690토큰 * 120초)을 초과할 수 없습니다. 따라서 초당 70,000개의 토큰을 사용하는 요청을 전송하지만 120초 동안의 총 사용량이 322,800개 미만이면 평균 사용량이 초당 2,690개를 초과하지 않으므로 초당 70,000개의 토큰 버스트는 여전히 프로비저닝된 처리량으로 간주됩니다.표준 (중간 크기) GSU 할당 (GSU 3개 초과): 중간 크기 GSU 배포 (예: GSU 50개 미만)의 경우 창은 5초에서 30초까지 다양할 수 있습니다. GSU 임계값과 컨텍스트 윈도우는 모델에 따라 다릅니다.
예를 들어
gemini-2.5-flashGSU 25개를 구매하면 초당 평균 67,250개 토큰 (초당 2,690개 토큰 * 25)의 연속 처리량을 얻게 됩니다. 30초 동안의 총 사용량이 2,017,500토큰 (초당 67,250토큰 * 30초)을 초과할 수 없습니다. 따라서 초당 1,000,000개의 토큰을 사용하는 요청을 보내지만 30초 동안의 총 사용량이 2,017,500개의 토큰 이내로 유지되면 평균 사용량이 초당 67,250개의 토큰을 초과하지 않으므로 초당 1,000,000개의 토큰 버스트는 프로비저닝된 처리량으로 간주됩니다.고정밀도 (대규모) GSU 할당: 대규모 GSU 배포 (예: 50개 이상의 GSU)의 경우 고빈도 요청이 인프라 전반에서 최대 정확도로 처리되도록 1~5초 범위일 수 있습니다.
예를 들어
gemini-2.5-flashGSU 250개를 구매하면 초당 평균 672,500개 (초당 토큰 2,690개 * 250)의 연속 처리량이 제공됩니다. 5초 동안의 총 사용량이 3,362,500토큰 (초당 672,500토큰 * 5초)을 초과할 수 없습니다. 따라서 초당 5,000,000개의 토큰을 사용하는 요청을 보내면 5초 동안의 총 사용량이 3,362,500개 토큰 한도를 초과하므로 프로비저닝된 처리량으로 처리되지 않습니다. 반면 초당 1,000,000개의 토큰을 사용하는 요청은 5초 기간의 평균 사용량이 초당 672,500개의 토큰을 초과하지 않는 경우 프로비저닝된 처리량으로 처리될 수 있습니다.
초과 사용량 제어 또는 프로비저닝된 처리량 우회
API를 사용하여 구매한 처리량을 초과할 때 초과분을 제어하거나 요청별로 프로비저닝된 처리량을 우회할 수 있습니다.
각 옵션을 읽고 사용 사례에 맞게 무엇을 해야 하는지 결정하세요.
기본 동작
요청이 남은 프로비저닝된 처리량 할당량을 초과하면 기본적으로 전체 요청이 주문형 요청으로 처리되고 사용한 만큼만 지불하는 요금으로 청구됩니다. 이 경우 트래픽이 모니터링 대시보드에 스필오버로 표시됩니다. 프로비저닝된 처리량 사용량 모니터링에 대한 자세한 내용은 프로비저닝된 처리량 모니터링을 참고하세요.
프로비저닝된 처리량 주문이 활성화되면 기본 동작이 자동으로 실행됩니다. 프로비저닝된 리전에서 주문을 소비하는 한 주문을 소비하기 위해 코드를 변경할 필요는 없습니다.
프로비저닝된 처리량만 사용
주문형 요금을 피해 비용을 관리하는 경우 프로비저닝된 처리량만 사용하세요.
프로비저닝된 처리량 주문 금액을 초과하는 요청은 429 오류를 반환합니다.
API에 요청을 보낼 때 X-Vertex-AI-LLM-Request-Type HTTP 헤더를 dedicated로 설정합니다.
사용한 만큼만 지불 사용
이를 주문형 사용이라고도 합니다. 요청이 프로비저닝된 처리량 주문을 우회하고 사용한 만큼만 지불로 직접 전송됩니다. 이는 개발 중인 실험이나 애플리케이션에 유용할 수 있습니다.
API에 요청을 보낼 때 X-Vertex-AI-LLM-Request-Type HTTP 헤더를 shared로 설정합니다.
예
Python
설치
pip install --upgrade google-genai
자세한 내용은 SDK 참고 문서를 참고하세요.
Vertex AI에서 생성형 AI SDK를 사용하도록 환경 변수를 설정합니다.
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Go를 설치하거나 업데이트하는 방법을 알아보세요.
자세한 내용은 SDK 참고 문서를 참고하세요.
Vertex AI에서 생성형 AI SDK를 사용하도록 환경 변수를 설정합니다.
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
설치
npm install @google/genai
자세한 내용은 SDK 참고 문서를 참고하세요.
Vertex AI에서 생성형 AI SDK를 사용하도록 환경 변수를 설정합니다.
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Java를 설치하거나 업데이트하는 방법을 알아보세요.
자세한 내용은 SDK 참고 문서를 참고하세요.
Vertex AI에서 생성형 AI SDK를 사용하도록 환경 변수를 설정합니다.
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
환경을 설정하면 REST를 사용하여 텍스트 프롬프트를 테스트할 수 있습니다. 다음 샘플은 요청을 게시자 모델 엔드포인트에 전송합니다.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
API 키로 프로비저닝된 처리량 사용
특정 프로젝트, Google 모델, 리전에 프로비저닝된 처리량을 구매했으며 이를 사용하여 API 키로 요청을 보내려면 요청에 프로젝트 ID, 모델, 위치, API 키를 파라미터로 포함해야 합니다.
서비스 계정에 바인딩된 Google Cloud API 키를 만드는 방법은 Google Cloud API 키 가져오기를 참고하세요. API 키를 사용하여 Gemini API에 요청을 전송하는 방법을 알아보려면 Gemini Enterprise Agent Platform의 Gemini API API 빠른 시작을 참고하세요.
예를 들어 다음 샘플은 프로비저닝된 처리량을 사용하는 동안 API 키로 요청을 제출하는 방법을 보여줍니다.
REST
환경을 설정하면 REST를 사용하여 텍스트 프롬프트를 테스트할 수 있습니다. 다음 샘플은 요청을 게시자 모델 엔드포인트에 전송합니다.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
프로비저닝된 처리량 모니터링
aiplatform.googleapis.com/PublisherModel 리소스 유형에서 측정된 측정항목 집합을 사용하여 프로비저닝된 처리량 사용량을 직접 모니터링할 수 있습니다.
프로비저닝된 처리량 트래픽 모니터링은 공개 프리뷰 기능입니다.
측정기준
다음 측정기준을 사용하여 측정항목을 필터링할 수 있습니다.
| 측정기준 | 값 |
|---|---|
type |
inputoutput |
request_type |
|
경로 프리픽스
측정항목의 경로 접두사는 aiplatform.googleapis.com/publisher/online_serving입니다.
예를 들어 /consumed_throughput 측정항목의 전체 경로는 aiplatform.googleapis.com/publisher/online_serving/consumed_throughput입니다.
측정항목
Gemini 모델의 aiplatform.googleapis.com/PublisherModel 리소스에서 다음 Cloud Monitoring 측정항목을 사용할 수 있습니다. dedicated 요청 유형을 사용하여 프로비저닝된 처리량 사용량을 필터링합니다.
| 측정항목 | 표시 이름 | 설명 |
|---|---|---|
/dedicated_gsu_limit |
한도(GSU) | GSU의 전용 한도입니다. 이 측정항목을 사용하여 GSU의 프로비저닝된 처리량 최대 할당량을 파악합니다. |
/tokens |
토큰 | 입력 및 출력 토큰 수 분포입니다. |
/token_count |
토큰 수 | 누적된 입력 및 출력 토큰 수입니다. |
/consumed_token_throughput |
토큰 처리량 | 토큰의 소진율을 고려하고 할당량 조정을 통합하는 처리량 사용량입니다. 프로비저닝된 처리량 할당량 확인을 참고하세요. 이 측정항목을 사용하여 프로비저닝된 처리량 할당량이 사용된 방식을 파악합니다. |
/dedicated_token_limit |
한도(초당 토큰 수) | 초당 토큰 전용 한도입니다. 이 측정항목을 사용하여 토큰 기반 모델의 프로비저닝된 처리량 최대 할당량을 파악합니다. |
/characters |
문자 | 입력 및 출력 문자 수 분포입니다. |
/character_count |
문자 수 | 누적된 입력 및 출력 문자 수입니다. |
/consumed_throughput |
문자 처리량 | 처리량 사용량: 소진율을 문자 수로 고려하고 할당량 조정 프로비저닝된 처리량 할당량 확인을 통합합니다. 이 측정항목을 사용하여 프로비저닝된 처리량 할당량이 사용된 방식을 파악합니다. 토큰 기반 모델의 경우 이 측정항목은 토큰에서 소비된 처리량에 4를 곱한 값과 같습니다. |
/dedicated_character_limit |
한도(초당 문자 수) | 초당 문자 수 전용 제한입니다. 이 측정항목을 사용하여 문자 기반 모델의 프로비저닝된 처리량 최대 할당량을 파악합니다. |
/model_invocation_count |
모델 호출 수 | 모델 호출 수(예측 요청)입니다. |
/model_invocation_latencies |
모델 호출 지연 시간 | 모델 호출 지연 시간(예측 지연 시간)입니다. |
/first_token_latencies |
첫 번째 토큰 지연 시간 | 요청이 수신된 시점부터 첫 번째 토큰이 반환될 때까지의 기간입니다. |
Anthropic 모델에는 프로비저닝된 처리량 필터도 있지만 tokens 및 token_count에만 해당합니다.
대시보드
프로비저닝된 처리량의 기본 모니터링 대시보드는 사용량과 프로비저닝된 처리량 사용률을 더 잘 파악할 수 있는 측정항목을 제공합니다. 대시보드에 액세스하려면 다음을 수행하세요.
Google Cloud 콘솔에서 프로비저닝된 처리량 페이지로 이동합니다.
주문 전반에서 각 모델의 프로비저닝된 처리량 사용률을 확인하려면 사용률 요약 탭을 선택합니다.
모델별 프로비저닝된 처리량 사용률 표에서 선택한 기간에 대해 다음을 확인할 수 있습니다.
보유한 총 GSU 수입니다.
GSU 측면에서의 최대 처리량 사용량입니다.
평균 GSU 사용률입니다.
프로비저닝된 처리량 한도에 도달한 횟수입니다.
모델별 프로비저닝된 처리량 사용률 표에서 모델을 선택하여 선택한 모델과 관련된 추가 측정항목을 확인합니다.
모니터링 대시보드를 해석하는 방법
프로비저닝된 처리량은 요청이 이루어질 때 밀리초 수준에서 실시간으로 사용 가능한 할당량을 확인하지만, 이 데이터를 에이전트 플랫폼 내부 시계 시간을 기반으로 하는 롤링 할당량 시행 기간과 비교합니다. 이 비교는 요청이 이루어진 시간과 무관합니다. 모니터링 대시보드는 할당량 조정이 이루어진 후 사용량 측정항목을 보고합니다. 하지만 이러한 측정항목은 선택한 기간을 기준으로 대시보드 정렬 기간의 평균을 제공하기 위해 집계됩니다. 모니터링 대시보드에서 지원하는 가장 낮은 세분성은 분 수준입니다. 또한 모니터링 대시보드의 시계 시간은 에이전트 플랫폼의 시계 시간과 다릅니다.
이러한 타이밍 차이로 인해 모니터링 대시보드의 데이터와 실시간 실적 간에 불일치가 발생할 수 있습니다. 다음과 같은 이유로 인해 발생할 수 있습니다.
할당량은 실시간으로 적용되지만 모니터링 차트는 모니터링 대시보드에 지정된 기간에 따라 데이터를 1분 이상의 평균 대시보드 정렬 기간으로 집계합니다.
에이전트 플랫폼과 모니터링 대시보드가 서로 다른 시스템 시계에서 실행됩니다.
1초 동안 트래픽 급증이 강제 적용 기간에 따라 프로비저닝된 처리량 할당량을 초과하면 전체 요청이 스필오버 트래픽으로 처리됩니다. 하지만 해당 초의 모니터링 데이터가 1분 정렬 기간 내에서 평균화되면 전체 프로비저닝된 처리량 사용률이 낮게 표시될 수 있습니다. 전체 정렬 기간의 평균 사용률이 100%를 초과하지 않을 수 있기 때문입니다. 스필오버 트래픽이 표시되면 해당 특정 요청이 이루어진 할당량 시행 기간 동안 프로비저닝된 처리량 할당량이 완전히 사용되었음을 확인할 수 있습니다. 이는 모니터링 대시보드에 표시되는 평균 사용률과 관계없이 적용됩니다.
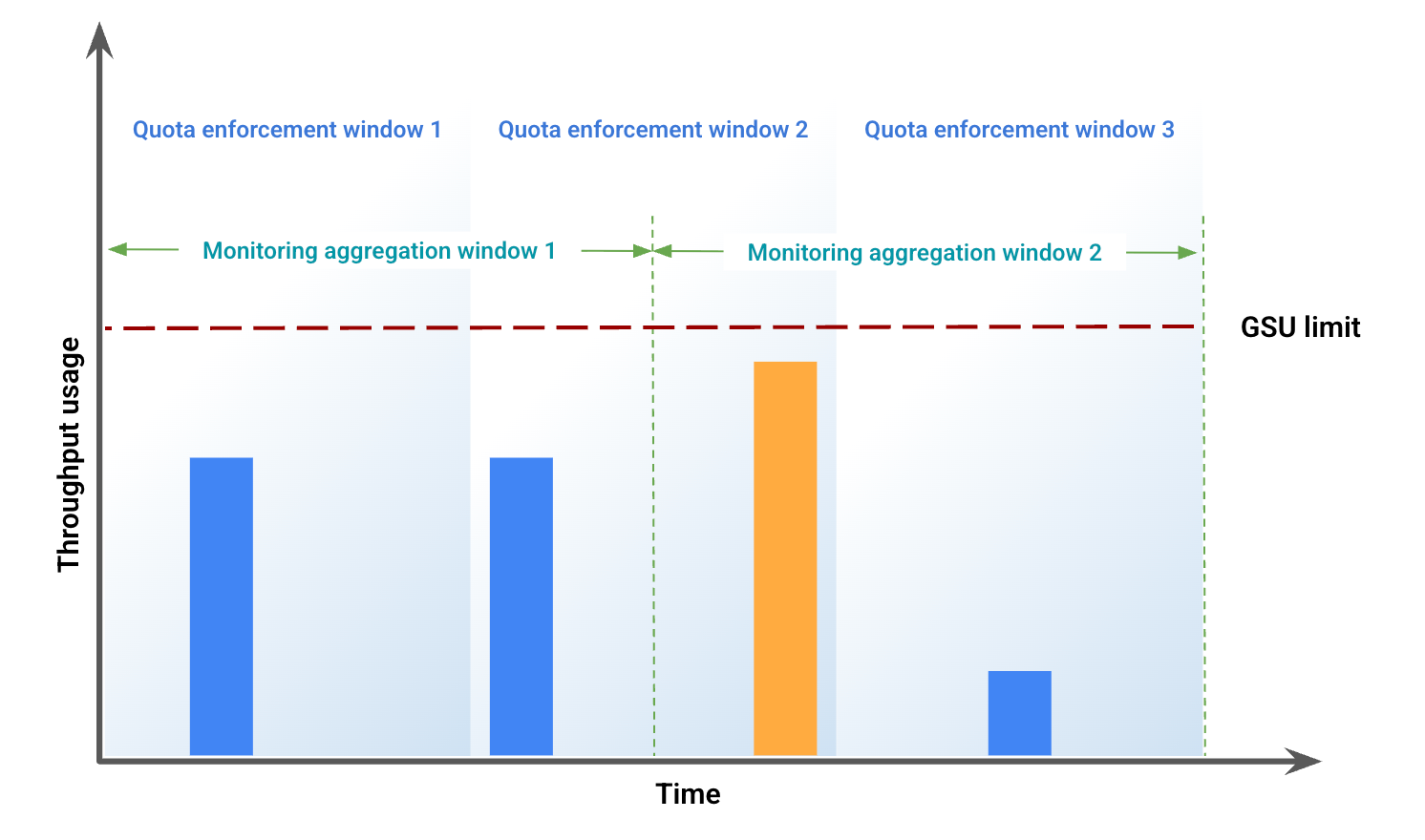
모니터링 데이터의 잠재적 불일치 예
이 예에서는 창 정렬 불량으로 인해 발생하는 불일치를 보여줍니다. 그림 1은 특정 기간 동안의 처리량 사용량을 나타냅니다. 이 그림에서
파란색 막대는 프로비저닝된 처리량으로 허용된 트래픽을 나타냅니다.
주황색 막대는 GSU 한도를 초과하는 사용량을 유발하고 스필오버로 처리되는 트래픽을 나타냅니다.
처리량 사용량을 기반으로 그림 2는 윈도우 불일치로 인해 발생할 수 있는 시각적 불일치를 나타냅니다. 이 그림에서
파란색 선은 프로비저닝된 처리량 트래픽을 나타냅니다.
주황색 선은 스필오버 트래픽을 나타냅니다.
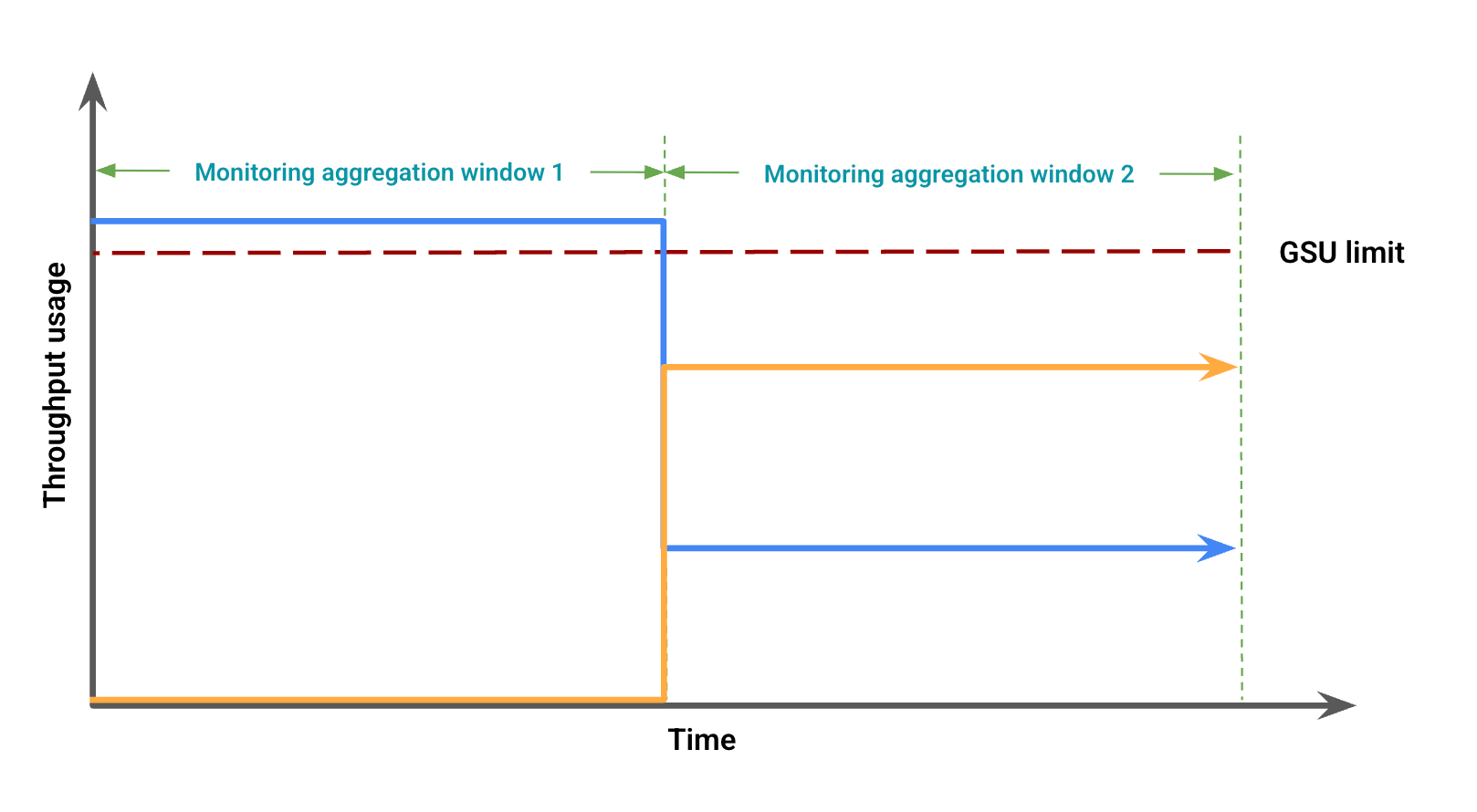
이 경우 모니터링 집계 기간에 오버플로가 없는 프로비저닝된 처리량 사용량이 모니터링 데이터에 표시될 수 있으며, 동시에 다른 모니터링 집계 기간에 오버플로가 발생하면서 GSU 한도 미만의 프로비저닝된 처리량 사용량이 관찰될 수 있습니다.
모니터링 대시보드 문제 해결
다음 단계를 실행하여 대시보드에서 예기치 않은 오버플로 또는 429 오류를 해결할 수 있습니다.
확대: 대시보드 기간을 12시간 이하로 설정하여 가장 세부적인 정렬 기간인 1분을 제공합니다. 시간 범위가 넓으면 스로틀링을 유발하는 급증을 완화하고 정렬 기간 평균을 늘릴 수 있습니다.
총 트래픽 확인: 모델별 대시보드에는 전용 트래픽과 오버플로 트래픽이 두 개의 별도 선으로 표시되므로 프로비저닝된 처리량 할당량이 완전히 사용되지 않고 조기에 오버플로된다는 잘못된 결론을 내릴 수 있습니다. 트래픽이 사용 가능한 할당량을 초과하면 전체 요청이 스필오버로 처리됩니다. 유용한 시각화를 추가하려면 측정항목 탐색기를 사용하여 대시보드에 쿼리를 추가하고 특정 모델 및 리전의 토큰 처리량을 포함하세요. 전체 트래픽 유형 (전용, 스필오버, 공유)의 총 트래픽을 보려면 추가 집계나 필터를 포함하지 마세요.
Genmedia 모델 모니터링
Veo 3 모델에서는 프로비저닝된 처리량 모니터링을 사용할 수 없습니다.
알림
알림을 사용 설정한 후 트래픽 사용량을 관리하는 데 도움이 되는 기본 알림을 설정합니다.
알림 사용
대시보드에서 알림을 사용 설정하려면 다음 단계를 따르세요.
Google Cloud 콘솔에서 프로비저닝된 처리량 페이지로 이동합니다.
주문 전반에서 각 모델의 프로비저닝된 처리량 사용률을 확인하려면 사용률 요약 탭을 선택합니다.
추천 알림을 선택하면 다음 알림이 표시됩니다.
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
트래픽을 관리하는 데 도움이 되는 알림을 확인합니다.
알림 세부정보 더 보기
알림에 대한 자세한 내용을 보려면 다음 단계를 따르세요.
통합 페이지로 이동합니다.
필터 필드에 vertex를 입력하고 Enter 키를 누릅니다. Google Gemini Enterprise Agent Platform이 표시됩니다.
자세한 내용을 보려면 세부정보 보기를 클릭하세요. Google Gemini Enterprise Agent Platform 세부정보 창이 표시됩니다.
알림 탭을 선택한 다음 알림 정책 템플릿을 선택합니다.