

Il Throughput riservato (PT) è un abbonamento a costo fisso e durata fissa disponibile in diverse durate che riserva il throughput sulla piattaforma Gemini Enterprise Agent. Per riservare la velocità effettiva, devi specificare il modello e le posizioni disponibili in cui viene eseguito il modello.
Questa pagina spiega come funziona il Throughput riservato, come controllare gli addebiti in eccesso o bypassare il Throughput riservato e come monitorare l'utilizzo.
Quando utilizzare il throughput riservato
Se una delle seguenti considerazioni si applica al tuo caso d'uso, valuta la possibilità di utilizzare il Throughput riservato:
- I tuoi workload critici richiedono costantemente un throughput elevato. La misurazione del throughput dipende dal modello.
- Vuoi offrire un'esperienza coerente e prevedibile agli utenti delle tue applicazioni.
- Vuoi costi dell'AI generativa deterministici pagando un prezzo mensile o settimanale fisso con controllo dei costi aggiuntivi.
Il Throughput riservato è una delle diverse opzioni di consumo per Gemini Enterprise Agent Platform. Per scoprire tutte le opzioni di consumo, consulta Opzioni di consumo.
Come funziona il Throughput riservato
Questa sezione spiega come funziona il Throughput riservato utilizzando il controllo delle quote durante il periodo di applicazione delle quote.
Controllo della quota di throughput riservato
La quota massima di Throughput riservato è un multiplo del numero di unità della scala di AI generativa (GSU) acquistate e del throughput per GSU. Viene controllato ogni volta che fai una richiesta nel periodo di applicazione della quota, ovvero la frequenza con cui viene applicata la quota di Throughput riservato massimo.
Al momento della ricezione di una richiesta, le dimensioni effettive della risposta sono sconosciute. Poiché diamo la priorità alla velocità di risposta per le applicazioni in tempo reale, il Throughput riservato stima le dimensioni dei token di output. Se la stima iniziale supera la quota massima di Throughput riservato disponibile, la richiesta viene elaborata come pagamento a consumo. In caso contrario, viene elaborata come Throughput riservato. A questo scopo, viene confrontata la stima iniziale con la quota massima di Throughput riservato.
Quando viene generata la risposta e si conosce la dimensione effettiva del token di output, l'utilizzo e la quota effettivi vengono riconciliati aggiungendo la differenza tra la stima e l'utilizzo effettivo all'importo della quota di Throughput riservato disponibile.
Finestre di applicazione delle quote di throughput riservato
La piattaforma agentica Gemini Enterprise applica una finestra dinamica e impone la quota di Throughput riservato per i modelli Gemini. Ciò garantisce una stabilità ottimale per il traffico soggetto a picchi. Anziché una finestra fissa, Agent Platform applica la quota su una finestra flessibile che si regola automaticamente, a seconda del tipo di modello e del numero di GSU che hai eseguito il provisioning. Di conseguenza, in alcuni casi potresti riscontrare temporaneamente un traffico prioritario che supera la quota al secondo. Tuttavia, non devi superare la quota durante il periodo di tempo. Questi periodi si basano sull'ora dell'orologio interno di Agent Platform e sono indipendenti dal momento in cui vengono effettuate le richieste.
Come funziona la finestra di applicazione della quota
La finestra di applicazione determina di quanto puoi superare, o "burst", il limite al secondo prima che venga applicata la limitazione. Questa finestra viene applicata automaticamente. Tieni presente che questi periodi sono soggetti a modifiche per ottimizzare le prestazioni e l'affidabilità.
Allocazioni ridotte di GSU (3 GSU o meno): la finestra può variare da 40 a 120 secondi per consentire l'elaborazione di richieste individuali più grandi senza interruzioni.
Ad esempio, se acquisti 1 GSU di
gemini-2.5-flash, ottieni una media di 2690 token al secondo di throughput continuo. L'utilizzo totale in un periodo di 120 secondi non può superare i 322.800 token (2690 token al secondo * 120 secondi). Pertanto, se invii una richiesta che utilizza 70.000 token al secondo, ma l'utilizzo totale in 120 secondi rimane inferiore a 322.800 token, il burst di 70.000 token al secondo viene comunque conteggiato come Throughput riservato, poiché l'utilizzo medio non supera i 2690 token al secondo.Allocazioni GSU standard (di medie dimensioni) (più di 3 GSU): per implementazioni GSU di medie dimensioni (ad esempio, meno di 50 GSU), la finestra può variare da 5 a 30 secondi. Le soglie e le finestre contestuali di GSU variano in base al modello.
Ad esempio, se acquisti 25 GSU di
gemini-2.5-flash, ottieni una media di 67.250 token al secondo (2690 token al secondo * 25) di throughput continuo. L'utilizzo totale in un periodo di 30 secondi non può superare 2.017.500 token (67.250 token al secondo * 30 secondi). Pertanto, se invii una richiesta che utilizza 1.000.000 di token al secondo, ma l'utilizzo totale in 30 secondi rimane entro 2.017.500 token, il burst di 1.000.000 di token al secondo viene comunque conteggiato come Throughput riservato, poiché l'utilizzo medio non supera 67.250 token al secondo.Allocazioni di GSU ad alta precisione (su larga scala): per deployment di GSU su larga scala (ad esempio 50 GSU o più), la finestra può variare da 1 a 5 secondi per garantire che le richieste ad alta frequenza vengano elaborate con la massima accuratezza nell'infrastruttura.
Ad esempio, se acquisti 250 GSU di
gemini-2.5-flash, ottieni una media di 672.500 token al secondo (2690 token al secondo * 250) di throughput continuo. L'utilizzo totale in un periodo di 5 secondi non può superare 3.362.500 token (672.500 token al secondo * 5 secondi). Pertanto, se invii una richiesta che utilizza 5.000.000 di token al secondo, non verrà elaborata come Throughput riservato, perché l'utilizzo totale di 5.000.000 di token supera il limite di 3.362.500 token in un intervallo di 5 secondi. D'altra parte, una richiesta che utilizza 1.000.000 di token al secondo può essere elaborata come Throughput riservato se l'utilizzo medio nella finestra di 5 secondi non supera i 672.500 token al secondo.
Controllare gli addebiti per superamento o ignorare il throughput riservato
Utilizza l'API per controllare le eccedenze quando superi la velocità effettiva acquistata o per ignorare il Throughput riservato in base alla richiesta.
Leggi ogni opzione per determinare cosa devi fare per soddisfare il tuo caso d'uso.
Comportamento predefinito
Se una richiesta supera la quota di Throughput riservato rimanente, l'intera richiesta viene elaborata come richiesta on demand per impostazione predefinita e viene addebitata in base alla tariffa pagamento a consumo. Quando ciò si verifica, il traffico viene visualizzato come overflow nelle dashboard di monitoraggio. Per maggiori informazioni sul monitoraggio dell'utilizzo del throughput riservato, consulta Monitorare il throughput riservato.
Una volta attivato l'ordine di Throughput riservato, il comportamento predefinito viene eseguito automaticamente. Non devi modificare il codice per iniziare a utilizzare l'ordine purché lo utilizzi nella regione di provisioning.
Utilizza solo il throughput riservato
Se gestisci i costi evitando gli addebiti on demand, utilizza solo il Throughput riservato.
Le richieste che superano l'importo dell'ordine di Throughput riservato restituiscono un errore 429.
Quando invii richieste all'API, imposta l'intestazione HTTP X-Vertex-AI-LLM-Request-Type su dedicated.
Utilizzare solo il pagamento a consumo
Questa operazione è nota anche come utilizzo on demand. Le richieste ignorano l'ordine di Throughput riservato e vengono inviate direttamente al pagamento a consumo. Questo potrebbe essere utile per esperimenti o applicazioni in fase di sviluppo.
Quando invii richieste all'API, imposta l'intestazione HTTP X-Vertex-AI-LLM-Request-Type su shared.
Esempio
Python
Installa
pip install --upgrade google-genai
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Go
Scopri come installare o aggiornare Go.
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Node.js
Installa
npm install @google/genai
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
Java
Scopri come installare o aggiornare Java.
Per saperne di più, consulta la documentazione di riferimento dell'SDK.
Imposta le variabili di ambiente per utilizzare l'SDK Gen AI con Vertex AI:
# Replace the `GOOGLE_CLOUD_PROJECT` and `GOOGLE_CLOUD_LOCATION` values # with appropriate values for your project. export GOOGLE_CLOUD_PROJECT=GOOGLE_CLOUD_PROJECT export GOOGLE_CLOUD_LOCATION=global export GOOGLE_GENAI_USE_VERTEXAI=True
REST
Dopo aver configurato l'ambiente, puoi utilizzare REST per testare un prompt di testo. L'esempio seguente invia una richiesta all'endpoint del modello del publisher.
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
-H "X-Vertex-AI-LLM-Request-Type: dedicated" \ # Options: dedicated, shared
$URL \
-d '{"contents": [{"role": "user", "parts": [{"text": "Hello."}]}]}'
Utilizzare il Throughput riservato con una chiave API
Se hai acquistato il Throughput riservato per un progetto, un modello Google e una regione specifici e vuoi utilizzarlo per inviare una richiesta con una chiave API, devi includere l'ID progetto, il modello, la località e la chiave API come parametri nella richiesta.
Per informazioni su come creare una chiave API Google Cloud associata a un service account, consulta Ottieni una chiave API Google Cloud . Per scoprire come inviare richieste all'API Gemini utilizzando una chiave API, consulta la guida rapida all'API Gemini in Gemini Enterprise Agent Platform.
Ad esempio, il seguente campione mostra come inviare una richiesta con una chiave API durante l'utilizzo del Throughput riservato:
REST
Dopo aver configurato l'ambiente, puoi utilizzare REST per testare un prompt di testo. L'esempio seguente invia una richiesta all'endpoint del modello del publisher.
curl \
-X POST \
-H "Content-Type: application/json" \
"https://aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/publishers/google/models/MODEL_ID:generateContent?key=YOUR_API_KEY" \
-d $'{
"contents": [
{
"role": "user",
"parts": [
{
"text": "Explain how AI works in a few words"
}
]
}
]
}'
Monitorare il throughput riservato
Puoi monitorare autonomamente l'utilizzo del Throughput riservato utilizzando un insieme di metriche misurate sul tipo di risorsa aiplatform.googleapis.com/PublisherModel.
Il monitoraggio del traffico di Throughput riservato è una funzionalità in anteprima pubblica.
Dimensioni
Puoi filtrare in base alle metriche utilizzando le seguenti dimensioni:
| Dimensione | Valori |
|---|---|
type |
inputoutput |
request_type |
|
Prefisso percorso
Il prefisso del percorso per una metrica è
aiplatform.googleapis.com/publisher/online_serving.
Ad esempio, il percorso completo della metrica /consumed_throughput è
aiplatform.googleapis.com/publisher/online_serving/consumed_throughput.
Metriche
Le seguenti metriche di Cloud Monitoring sono disponibili per la risorsa aiplatform.googleapis.com/PublisherModel per i modelli Gemini. Utilizza i tipi di richiesta dedicated per filtrare l'utilizzo del throughput riservato.
| Metrica | Nome visualizzato | Descrizione |
|---|---|---|
/dedicated_gsu_limit |
Limite (GSU) | Limite dedicato nelle GSU. Utilizza questa metrica per comprendere la quota massima di Throughput riservato in GSU. |
/tokens |
Token | Distribuzione del conteggio dei token di input e output. |
/token_count |
Conteggio token | Conteggio dei token di input e output accumulati. |
/consumed_token_throughput |
Throughput dei token | Utilizzo della velocità effettiva, che tiene conto del tasso di esaurimento dei token e incorpora la riconciliazione delle quote. Consulta Controllo della quota di Throughput riservato. Utilizza questa metrica per capire come è stata utilizzata la quota di Throughput riservato. |
/dedicated_token_limit |
Limite (token al secondo) | Limite dedicato in token al secondo. Utilizza questa metrica per comprendere la quota massima di Throughput riservato per i modelli basati su token. |
/characters |
Caratteri | Distribuzione del conteggio dei caratteri di input e output. |
/character_count |
Conteggio dei caratteri | Conteggio dei caratteri di input e output accumulati. |
/consumed_throughput |
Velocità effettiva dei caratteri | Utilizzo del throughput, che tiene conto del tasso di esaurimento in caratteri e incorpora la riconciliazione delle quote Controllo della quota di Throughput riservato. Utilizza questa metrica per capire come è stata utilizzata la quota di Throughput riservato. Per i modelli basati su token, questa metrica equivale al throughput consumato in token moltiplicato per 4. |
/dedicated_character_limit |
Limite (caratteri al secondo) | Limite dedicato in caratteri al secondo. Utilizza questa metrica per comprendere la quota massima di Throughput riservato per i modelli basati su caratteri. |
/model_invocation_count |
Conteggio chiamate del modello | Numero di chiamate del modello (richieste di previsione). |
/model_invocation_latencies |
Latenze di chiamata del modello | Latenze di chiamata del modello (latenze di previsione). |
/first_token_latencies |
Latenze del primo token | Durata dal momento in cui la richiesta viene ricevuta al momento in cui viene restituito il primo token. |
I modelli Anthropic hanno anche un filtro per il throughput riservato, ma solo per tokens e
token_count.
Dashboard
Le dashboard di monitoraggio predefinite per il Throughput riservato forniscono metriche che ti consentono di comprendere meglio l'utilizzo e l'utilizzo del Throughput riservato. Per accedere alle dashboard:
Nella console Google Cloud , vai alla pagina Throughput riservato.
Per visualizzare l'utilizzo del throughput riservato di ciascun modello negli ordini, seleziona la scheda Riepilogo utilizzo.
Nella tabella Utilizzo del throughput riservato per modello, puoi visualizzare quanto segue per l'intervallo di tempo selezionato:
Numero totale di GSU che avevi.
Utilizzo del throughput di picco in termini di GSU.
L'utilizzo medio di GSU.
Il numero di volte in cui hai raggiunto il limite di Throughput riservato.
Seleziona un modello dalla tabella Utilizzo del throughput riservato per modello per visualizzare altre metriche specifiche per il modello selezionato.
Come interpretare le dashboard di monitoraggio
Il throughput riservato controlla la quota disponibile in tempo reale a livello di millisecondo per le richieste man mano che vengono effettuate, ma confronta questi dati con un periodo di applicazione della quota mobile, in base all'ora dell'orologio interno della piattaforma dell'agente. Questo confronto è indipendente dal momento in cui vengono effettuate le richieste. Le dashboard di monitoraggio riportano le metriche di utilizzo dopo la riconciliazione della quota. Tuttavia, queste metriche vengono aggregate per fornire le medie per i periodi di allineamento della dashboard, in base all'intervallo di tempo selezionato. La granularità più bassa supportata dalle dashboard di monitoraggio è a livello di minuti. Inoltre, l'ora dell'orologio per le dashboard di monitoraggio è diversa da quella di Agent Platform.
Queste differenze di tempistiche potrebbero occasionalmente comportare discrepanze tra i dati nei dashboard di monitoraggio e il rendimento in tempo reale. Questi possono derivare da uno dei seguenti motivi:
La quota viene applicata in tempo reale, ma i grafici di monitoraggio aggregano i dati in periodi di allineamento della dashboard medi di 1 minuto o superiori, a seconda dell'intervallo di tempo specificato nelle dashboard di monitoraggio.
Agent Platform e le dashboard di monitoraggio vengono eseguite su orologi di sistema diversi.
Nell'arco di un secondo, se un burst di traffico supera la quota di Throughput riservato in base alla finestra di applicazione, l'intera richiesta viene elaborata come traffico di overflow. Tuttavia, l'utilizzo complessivo del Throughput riservato potrebbe sembrare basso quando i dati di monitoraggio per quel secondo vengono calcolati in media nel periodo di allineamento di 1 minuto, perché l'utilizzo medio nell'intero periodo di allineamento potrebbe non superare il 100%. Se visualizzi traffico di overflow, ciò conferma che la quota di Throughput riservato è stata utilizzata completamente durante il periodo di applicazione della quota in cui sono state effettuate queste richieste specifiche. Indipendentemente dall'utilizzo medio mostrato nelle dashboard di monitoraggio.
Esempio di potenziale discrepanza nei dati di monitoraggio
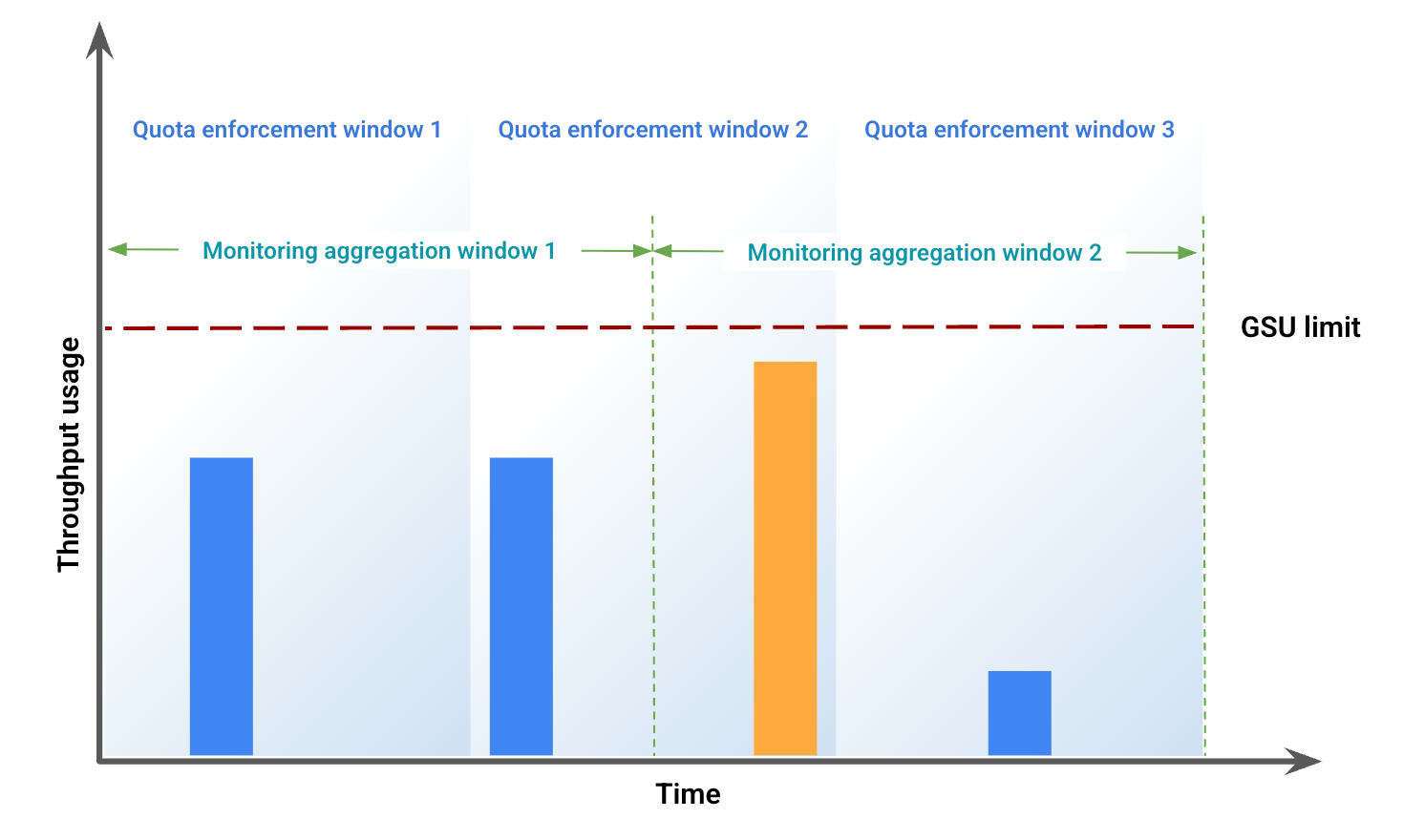
Questo esempio illustra alcune delle discrepanze derivanti dal disallineamento della finestra. La Figura 1 mostra l'utilizzo del throughput in un periodo di tempo specifico. In questa figura:
Le barre blu rappresentano il traffico ammesso come Throughput riservato.
La barra arancione rappresenta il traffico che spinge l'utilizzo oltre il limite di GSU e viene elaborato come overflow.
In base all'utilizzo del throughput, la figura 2 mostra possibili discrepanze visive dovute al disallineamento delle finestre. In questa figura:
La linea blu rappresenta il traffico di throughput riservato.
La linea arancione rappresenta il traffico di overflow.
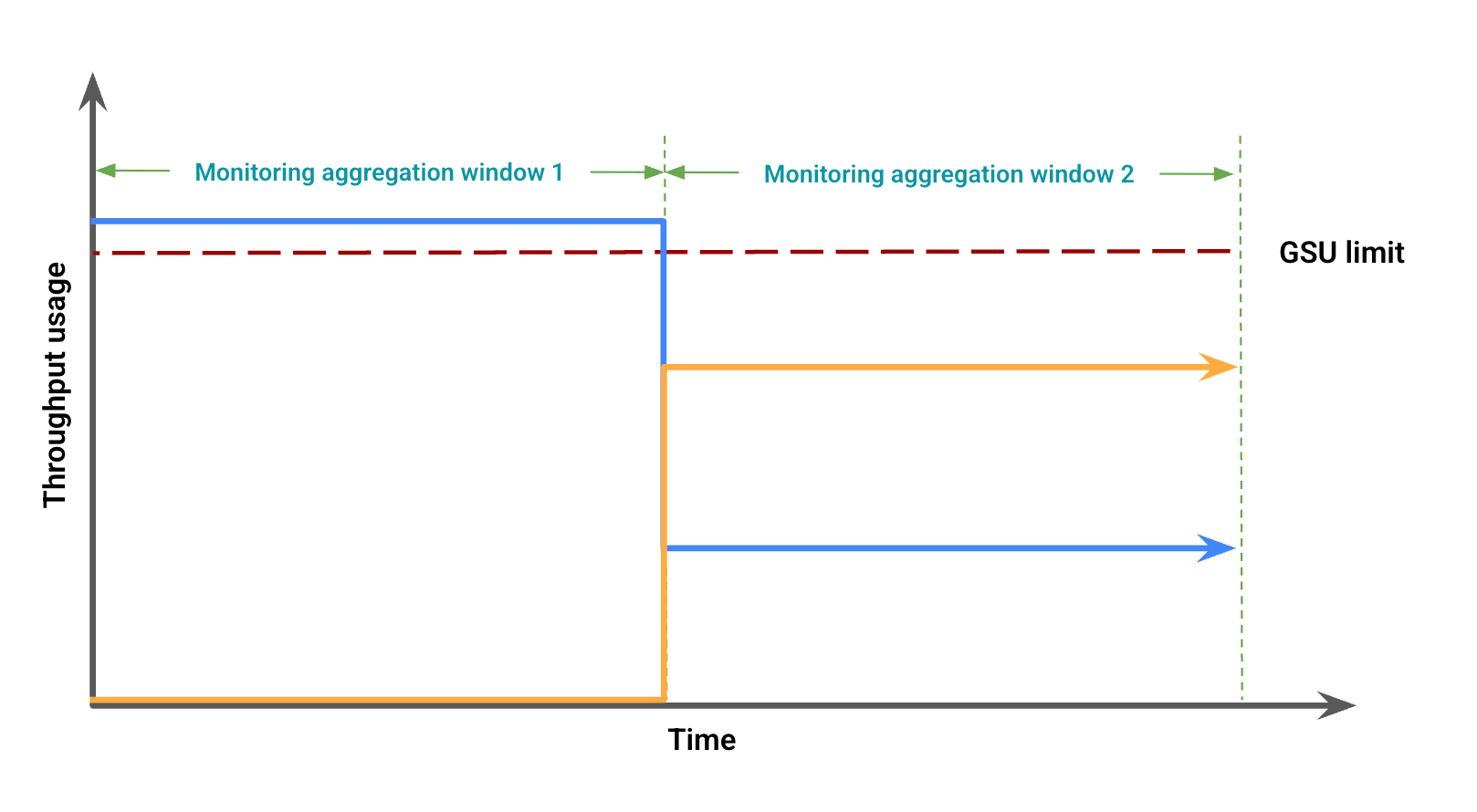
In questo caso, i dati di monitoraggio potrebbero mostrare l'utilizzo del Throughput riservato senza overflow per un periodo di aggregazione del monitoraggio, mentre contemporaneamente si osserva l'utilizzo del Throughput riservato al di sotto del limite GSU in concomitanza con un overflow in un altro periodo di aggregazione del monitoraggio.
Risolvere i problemi relativi alle dashboard di monitoraggio
Per risolvere i problemi relativi a overflow imprevisti nei dashboard o agli errori 429, segui questi passaggi:
Aumenta: imposta l'intervallo di tempo del dashboard su 12 ore o meno per fornire il periodo di allineamento più granulare di 1 minuto. Intervalli di tempo ampi attenuano i picchi che causano la limitazione e aumentano le medie del periodo di allineamento.
Controlla il traffico totale: i dashboard specifici del modello mostrano il traffico dedicato e di overflow come due linee separate, il che potrebbe portare alla conclusione errata che la quota di Throughput riservato non viene utilizzata completamente e si verifica un overflow prematuro. Se il tuo traffico supera la quota disponibile, l'intera richiesta viene elaborata come spillover. Per un'altra visualizzazione utile, aggiungi una query alla dashboard utilizzando Metrics Explorer e includi il throughput dei token per il modello e la regione specifici. Non includere aggregazioni o filtri aggiuntivi per visualizzare il traffico totale in tutti i tipi di traffico (dedicato, spillover e condiviso).
Monitorare i modelli Genmedia
Il monitoraggio del throughput riservato non è disponibile sui modelli Veo 3.
Avvisi
Dopo aver attivato gli avvisi, imposta quelli predefiniti per gestire l'utilizzo del traffico.
Attiva avvisi
Per attivare gli avvisi nella dashboard:
Nella console Google Cloud , vai alla pagina Throughput riservato.
Per visualizzare l'utilizzo del throughput riservato di ciascun modello negli ordini, seleziona la scheda Riepilogo utilizzo.
Seleziona Avvisi consigliati e verranno visualizzati i seguenti avvisi:
Provisioned Throughput Usage Reached LimitProvisioned Throughput Utilization Exceeded 80%Provisioned Throughput Utilization Exceeded 90%
Controlla gli avvisi che ti aiutano a gestire il traffico.
Visualizzare ulteriori dettagli dell'avviso
Per visualizzare ulteriori informazioni sugli avvisi:
Vai alla pagina Integrazioni.
Inserisci vertex nel campo Filtro e premi Invio. Viene visualizzata la pagina Google Gemini Enterprise Agent Platform.
Per visualizzare ulteriori informazioni, fai clic su Visualizza dettagli. Viene visualizzato il riquadro Google Gemini Enterprise Agent Platform details.
Seleziona la scheda Avvisi, quindi seleziona un modello di criterio di avviso.