
Entender las lecturas y escrituras a gran escala
Lea este documento para tomar decisiones fundamentadas sobre la arquitectura de sus aplicaciones y conseguir que tengan un alto rendimiento y fiabilidad. En este documento se tratan temas avanzados de Firestore. Si acabas de empezar a usar Firestore, consulta la guía de inicio rápido.
Para asegurarte de que tus aplicaciones sigan funcionando correctamente a medida que aumentan el tamaño y el tráfico de tu base de datos, es útil conocer los mecanismos de lectura y escritura en el backend de Firestore. También debes comprender la interacción de tus lecturas y escrituras con la capa de almacenamiento y las restricciones subyacentes que pueden afectar al rendimiento.
Consulta las siguientes secciones para conocer las prácticas recomendadas antes de diseñar tu aplicación.
Conocer los componentes de alto nivel
En el siguiente diagrama se muestran los componentes de alto nivel que intervienen en una solicitud a la API de Firestore.

SDKs, bibliotecas de cliente y controladores
Firestore admite SDKs, bibliotecas de cliente y controladores para diferentes plataformas.
Google Front End (GFE)
Se trata de un servicio de infraestructura común a todos los Google Cloud servicios. GFE acepta las solicitudes entrantes y las reenvía al servicio de Google correspondiente (en este caso, el servicio de Firestore).
Servicio de Firestore
El servicio Firestore realiza comprobaciones en la solicitud de la API, que incluyen la autenticación, la autorización y las comprobaciones de cuota, y también gestiona las transacciones. Este servicio de Firestore incluye un cliente de almacenamiento que interactúa con la capa de almacenamiento para las lecturas y escrituras de datos.
Capa de almacenamiento de Firestore
La capa de almacenamiento de Firestore se encarga de almacenar tanto los datos como los metadatos, así como las funciones de base de datos asociadas que proporciona Firestore. En las siguientes secciones se describe cómo se organizan los datos en la capa de almacenamiento de Firestore y cómo se escala el sistema. Saber cómo se organizan los datos puede ayudarte a diseñar un modelo de datos escalable y a entender mejor las prácticas recomendadas de Firestore.
Intervalos y divisiones de claves
Firestore es una base de datos NoSQL orientada a documentos. Los datos se almacenan en documentos, que se organizan en colecciones. El nombre de la colección y el ID del documento forman una clave única para un documento. Los documentos de la misma colección se almacenan juntos en el espacio de claves. En ese espacio de claves, se cifra el ID del documento. El término intervalo de claves hace referencia a un intervalo contiguo de claves en el almacenamiento.
Firestore particiona automáticamente los datos de las colecciones en varios servidores de almacenamiento. Estas particiones se denominan divisiones.
Los documentos pueden generar entradas de índice que se ordenan lexicográficamente y participan en el mismo tipo de división y colocación que los datos del documento.
Replicación síncrona
Cada escritura se replica de forma síncrona en la mayoría de las réplicas mediante Paxos. Una réplica por división se considera líder y coordina el proceso de replicación. En caso de que falle el líder, se elige uno nuevo. Las réplicas se encuentran en zonas diferentes para que sean resistentes a posibles fallos de zona. El resultado general es un sistema escalable y de alta disponibilidad que proporciona latencias bajas tanto para las lecturas como para las escrituras, independientemente de las cargas de trabajo pesadas y a una escala muy grande.
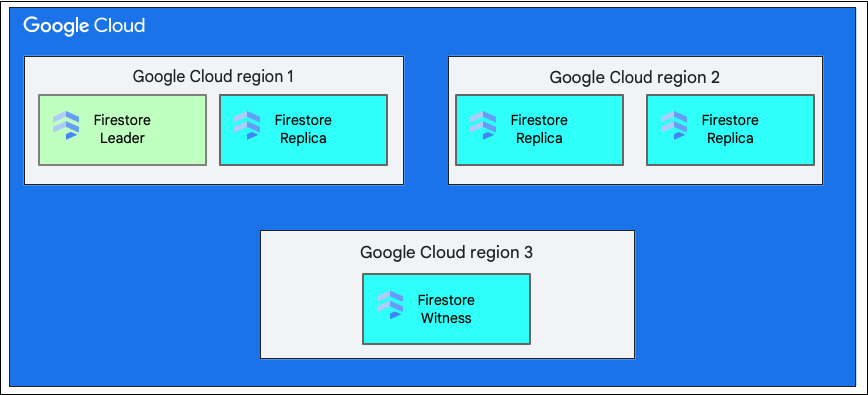
Una región frente a varias regiones
Cuando creas una base de datos, debes seleccionar una ubicación regional única o una ubicación multirregional.
Una ubicación regional es una ubicación geográfica específica, como us-west1. Las divisiones de datos de una base de datos de Firestore tienen réplicas en diferentes zonas de la región seleccionada, como se ha explicado anteriormente.
Una ubicación multirregional consta de un conjunto definido de regiones en las que Firestore almacena réplicas de la base de datos. En una implementación multirregional de Firestore, dos regiones tienen réplicas completas de todos los datos de la base de datos. Una tercera región tiene una réplica testigo que no mantiene un conjunto completo de datos, pero participa en la replicación. Los datos se pueden escribir y leer incluso si se pierde una región completa, ya que Firestore replica los datos entre varias regiones.
Para obtener más información sobre las ubicaciones de una región, consulta Ubicaciones de Firestore.
Entender el ciclo de vida de una escritura
Un controlador puede escribir datos creando, actualizando o eliminando un solo documento. Para escribir en un solo documento, es necesario actualizar de forma atómica tanto el documento como sus entradas de índice asociadas en la capa de almacenamiento. Firestore también admite operaciones atómicas que consisten en varias lecturas y escrituras en uno o varios documentos.
En todos los tipos de escritura, Firestore proporciona las propiedades ACID (atomicidad, coherencia, aislamiento y durabilidad) de las bases de datos relacionales. Firestore también proporciona serialización, lo que significa que todas las transacciones se ejecutan en orden secuencial.
Pasos generales de una transacción de escritura
Cuando el controlador emite una escritura o confirma una transacción mediante cualquiera de los métodos mencionados anteriormente, internamente se ejecuta como una transacción de lectura y escritura de la base de datos en la capa de almacenamiento. La transacción permite que Firestore proporcione las propiedades ACID mencionadas anteriormente.
Como primer paso de una transacción, Firestore lee el documento y determina las mutaciones que se deben realizar en los datos del documento.
Esto también incluye la actualización de los índices pertinentes:
- Los campos indexados que se añaden a los documentos necesitan las inserciones correspondientes en los índices.
- Los campos indexados que se van a eliminar de los documentos deben tener las eliminaciones correspondientes en los índices.
- Los campos indexados que se modifican en los documentos necesitan tanto eliminaciones (para los valores antiguos) como inserciones (para los valores nuevos) en los índices.
Para calcular las mutaciones mencionadas anteriormente, Firestore lee la configuración de indexación del proyecto. La configuración de indexación almacena información sobre los índices de un proyecto.
Una vez que se han calculado las mutaciones, Firestore las recoge en una transacción y, a continuación, la confirma.
Entender una transacción de escritura en la capa de almacenamiento
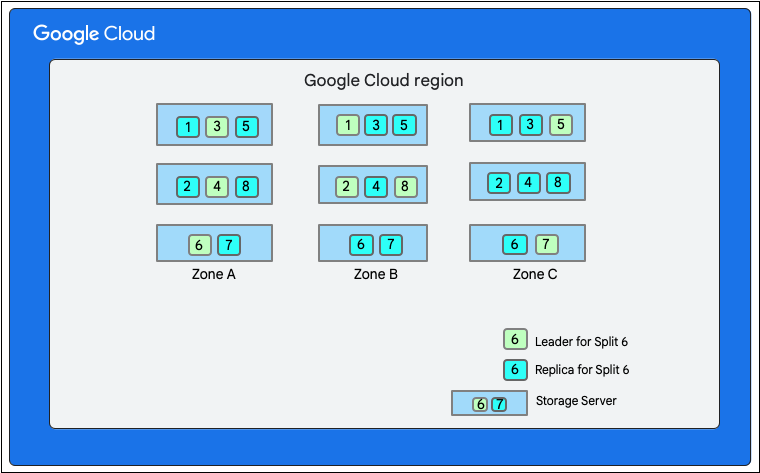
Como hemos comentado anteriormente, una escritura en Firestore implica una transacción de lectura y escritura en la capa de almacenamiento. En función del diseño de los datos, una escritura puede implicar una o varias divisiones.
En el siguiente diagrama, la base de datos de Firestore tiene ocho divisiones (marcadas del 1 al 8) alojadas en tres servidores de almacenamiento diferentes en una sola zona, y cada división se replica en tres(o más) zonas diferentes. Cada división tiene un líder de Paxos, que puede estar en una zona diferente para cada división.
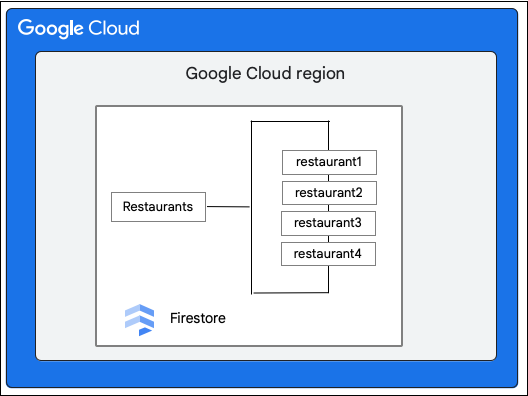
Supongamos que tienes una base de datos de Firestore con la colección Restaurants de la siguiente manera:
El controlador solicita el siguiente cambio en un documento de la colección Restaurant actualizando el valor del campo priceCategory.
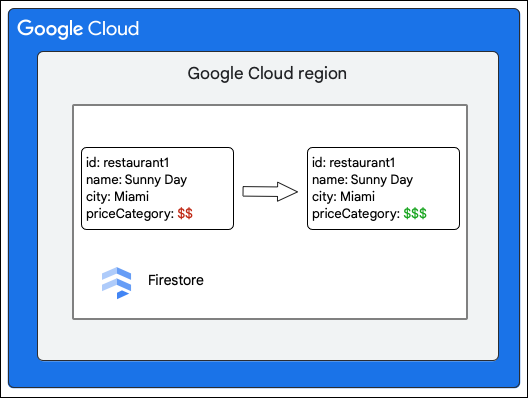
En los siguientes pasos generales se describe lo que ocurre durante la escritura:
- Crea una transacción de lectura y escritura.
- Lee el documento
restaurant1de la colecciónRestaurants. - Lee los índices del documento.
- Calcula las mutaciones que se deben hacer en los datos. En este caso, hay cinco mutaciones:
- M1: Actualiza la fila de
restaurant1para reflejar el cambio en el valor del campopriceCategory. - M2 y M3: elimina las entradas de índice antiguas de
priceCategory. - M4 y M5: añade nuevas entradas de índice para
priceCategory.
- M1: Actualiza la fila de
- Confirma estas mutaciones.
El cliente de almacenamiento del servicio Firestore busca las divisiones que poseen las claves de las filas que se van a cambiar. Supongamos que la división 3 sirve M1 y la división 6 sirve M2-M5. Hay una transacción distribuida que implica a todas estas divisiones como participantes. Las divisiones de participantes también pueden incluir cualquier otra división de la que se hayan leído datos anteriormente como parte de la transacción de lectura y escritura.
En los siguientes pasos se describe lo que ocurre durante la confirmación:
- El cliente de almacenamiento emite una confirmación. La confirmación contiene las mutaciones M1-M5.
- Los splits 3 y 6 son los participantes de esta transacción. Se elige a uno de los participantes como coordinador, como en la división 3. El coordinador se encarga de que la transacción se confirme o se cancele de forma atómica en todos los participantes.
- Las réplicas líderes de estas divisiones son responsables del trabajo realizado por los participantes y los coordinadores.
- Cada participante y coordinador ejecuta un algoritmo de Paxos con sus respectivas réplicas.
- El líder ejecuta un algoritmo Paxos con las réplicas. Se alcanza el quórum si la mayoría de las réplicas responden al líder con una respuesta
ok to commit. - A continuación, cada participante notifica al coordinador que está preparado (primera fase de la confirmación en dos fases). Si algún participante no puede confirmar la transacción, se cancelará toda la transacción
aborts.
- El líder ejecuta un algoritmo Paxos con las réplicas. Se alcanza el quórum si la mayoría de las réplicas responden al líder con una respuesta
- Una vez que el coordinador sabe que todos los participantes, incluido él mismo, están preparados, comunica el resultado de la transacción
accepta todos los participantes (segunda fase de la confirmación en dos fases). En esta fase, cada participante registra la decisión de confirmación en un almacenamiento estable y se confirma la transacción. - El coordinador responde al cliente de almacenamiento en Firestore que la transacción se ha confirmado. Paralelamente, el coordinador y todos los participantes aplican las mutaciones a los datos.
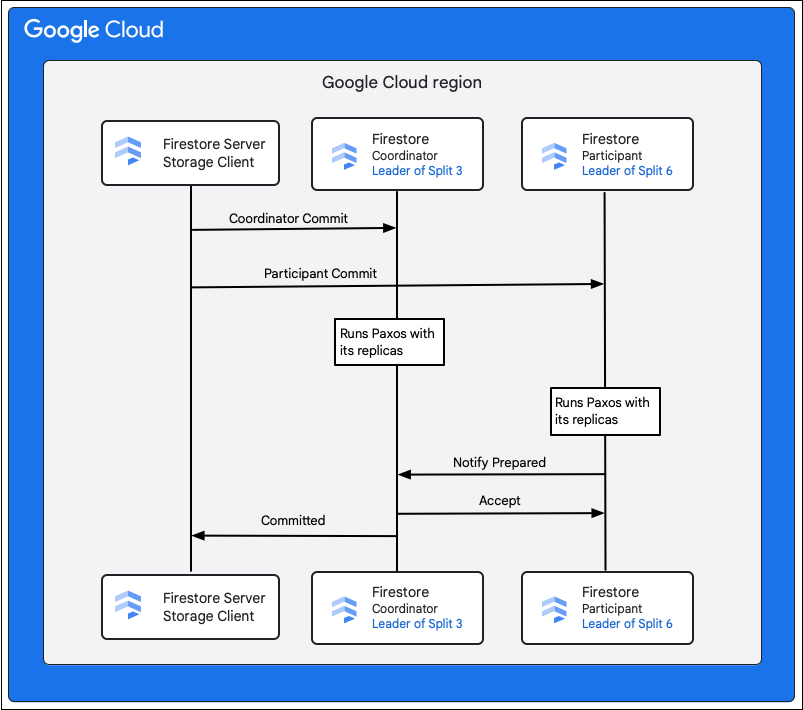
Cuando la base de datos de Firestore es pequeña, puede ocurrir que una sola división tenga todas las claves de las mutaciones M1-M5. En ese caso, solo hay un participante en la transacción y no es necesario el commit de dos fases mencionado anteriormente, por lo que las escrituras son más rápidas.
Escrituras en varias regiones
En una implementación multirregional, la distribución de réplicas en varias regiones aumenta la disponibilidad, pero tiene un coste de rendimiento. La comunicación entre réplicas de diferentes regiones requiere más tiempo de ida y vuelta. Por lo tanto, la latencia de referencia de las operaciones de Firestore es ligeramente superior a la de las implementaciones de una sola región.
Configuramos las réplicas de forma que el liderazgo de las divisiones siempre se mantenga en la región principal. La región principal es aquella desde la que se recibe el tráfico en el servidor de Firestore. Esta decisión de liderazgo reduce el retraso de ida y vuelta en la comunicación entre el cliente de almacenamiento de Firestore y el líder de la réplica (o el coordinador de las transacciones de división múltiple).
Entender el ciclo de vida de una lectura
En esta sección se profundiza en las lecturas de Firestore. En concreto, las consultas se componen de una combinación de lecturas de documentos y de entradas de índice.
Las lecturas de datos de la capa de almacenamiento se realizan internamente mediante una transacción de base de datos para asegurar la coherencia de las lecturas. Sin embargo, a diferencia de las transacciones que se usan para las escrituras, estas transacciones no toman bloqueos. En su lugar, funcionan eligiendo una marca de tiempo y, a continuación, ejecutando todas las lecturas en esa marca de tiempo. Como no adquieren bloqueos, no bloquean las transacciones de lectura y escritura simultáneas. Para ejecutar esta transacción, el cliente de almacenamiento de Firestore especifica un límite de marca de tiempo, que indica a la capa de almacenamiento cómo elegir una marca de tiempo de lectura. El tipo de marca de tiempo elegido por el cliente de almacenamiento en Firestore se determina mediante las opciones de lectura de la solicitud de lectura.
Entender una transacción de lectura en la capa de almacenamiento
En esta sección se describen los tipos de lecturas y cómo se procesan en la capa de almacenamiento de Firestore.
Lecturas intensas
De forma predeterminada, las lecturas de Firestore son fuertemente coherentes. Esta coherencia sólida significa que una lectura de Firestore devuelve la versión más reciente de los datos, que refleja todas las escrituras que se han confirmado hasta el inicio de la lectura.
Lectura de una sola división
El cliente de almacenamiento de Firestore busca las divisiones que tienen las claves de las filas que se van a leer. Supongamos que tiene que leer de Split 3 de la sección anterior. El cliente envía la solicitud de lectura a la réplica más cercana para reducir la latencia de ida y vuelta.
En este punto, pueden darse los siguientes casos en función de la réplica elegida:
- La solicitud de lectura se dirige a una réplica líder (zona A).
- Como el líder siempre está actualizado, la lectura puede continuar directamente.
- La solicitud de lectura se dirige a una réplica que no es líder (por ejemplo, la zona B).
- Es posible que la partición 3 sepa por su estado interno que tiene suficiente información para servir la lectura y lo haga.
- Split 3 no sabe si ha visto los datos más recientes. Envía un mensaje al líder para solicitar la marca de tiempo de la última transacción que necesita aplicar para servir la lectura. Una vez que se aplique esa transacción, se podrá realizar la lectura.
A continuación, Firestore devuelve la respuesta a su cliente.
Lectura de varios splits
En el caso de que las lecturas se tengan que hacer desde varias divisiones, se aplica el mismo mecanismo en todas las divisiones. Una vez que se han devuelto los datos de todas las divisiones, el cliente de almacenamiento de Firestore combina los resultados. A continuación, Firestore responde a su cliente con estos datos.
Evitar puntos de acceso
Las divisiones de Firestore se dividen automáticamente en partes más pequeñas para distribuir el trabajo de servir tráfico a más servidores de almacenamiento cuando sea necesario o cuando se amplíe el espacio de claves. Las divisiones creadas para gestionar el exceso de tráfico se conservan durante unas 24 horas, aunque el tráfico desaparezca. Por lo tanto, si hay picos de tráfico recurrentes, las divisiones se mantienen y se introducen más divisiones cuando sea necesario. Estos mecanismos ayudan a las bases de datos de Firestore a autoescalarse cuando aumenta la carga de tráfico o el tamaño de la base de datos. Sin embargo, hay algunas limitaciones que debes tener en cuenta.
Dividir el almacenamiento y la carga lleva tiempo, y aumentar el tráfico demasiado rápido puede provocar una latencia alta o errores de tiempo de espera agotado, que se conocen como puntos de acceso, mientras el servicio se ajusta. La práctica recomendada es distribuir las operaciones en el intervalo de claves y aumentar el tráfico gradualmente en una colección de una base de datos.
Aunque las divisiones se crean automáticamente a medida que aumenta la carga, Firestore solo puede dividir un intervalo de claves hasta que sirva un único documento mediante un conjunto específico de servidores de almacenamiento replicados. Por lo tanto, un volumen alto y constante de operaciones simultáneas en un solo documento puede provocar un punto de acceso en ese documento. Si detecta latencias altas continuas en un solo documento, debería modificar su modelo de datos para dividir o replicar los datos en varios documentos.
Los errores de contención se producen cuando varias operaciones intentan leer y escribir el mismo documento simultáneamente.
Ten en cuenta que, si sigues las prácticas descritas en esta página, Firestore puede adaptarse a cargas de trabajo arbitrariamente grandes sin que tengas que ajustar ninguna configuración.