
解讀結果
Enterprise Knowledge Graph 會為每個工作將結果寫入新的 BigQuery 資料表。這是工作執行時的資料快照。根據預設,每項工作都會為每個實體叢集產生隨機 cluster_id。不過,如要讓 ID 在不同工作執行期間保持穩定,請使用 previous BigQuery result table 進階選項。
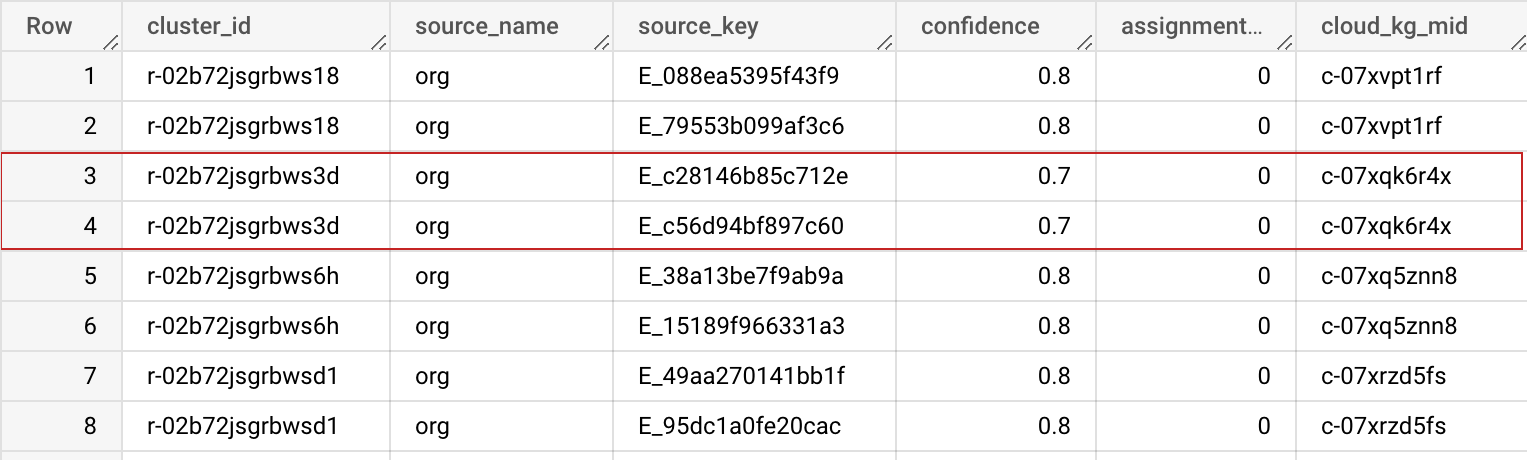
輸出內容的結構定義
| 欄位名稱 | 類型 | 說明 |
|---|---|---|
| cluster_id | STRING | 這個叢集 ID 是指派給這組記錄的私有知識圖譜機器 ID (MID)。可用於專門識別資料集中的記錄。您可以在「進階選項」中使用「過往 BigQuery 資料表」,確保 cluster_id 在多次執行時保持穩定一致。 |
| source_name | STRING | 輸入設定中指定的來源名稱,有助於彙整資料集。 |
| source_key | STRING | 來源資料表中的專屬鍵,可協助您合併資料集。 |
| 信賴度 | FLOAT | 信心分數,用於判斷這些記錄屬於這個叢集的程度。 |
| assignment_age | INTEGER | 在不同工作之間,用於叢集 ID (MID) 穩定性。 |
| cloud_kg_mid | STRING | Google Cloud 知識圖譜連結實體 MID。您可以將這個 MID 當成永久 ID,或透過 Cloud Knowledge Graph API 查詢其他詳細資料。 |
使用 SQL 彙整資料集
Enterprise Knowledge Graph 會依叢集 ID 將實體分組。如要查看結果,最簡單的方法是使用叢集 ID 將結果「分組依據」。以下範例會將輸出資料表與原始資料表聯結,快速執行健全性檢查。
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
這個實體叢集代表屬於同一叢集的兩筆不同記錄。這個 cluster_id 表示這兩筆記錄應合併。

評估成效
成對
精確度:錯誤識別為相似的相異實體偽陽性比率 (可透過人工檢查輕鬆偵測)。
召回率:未識別為偽陰性或較難偵測的相似實體比例。
叢集 V 測量
叢集 V 測量值:(1 + beta) * 同質性 * 完整性 / (beta * 同質性 + 完整性),其中 beta=1。
叢集同質性:含有屬於相同實體的實體的叢集比例。
叢集完整度:所有屬於同一實體的實體都放在同一叢集中的叢集比例。