
결과 이해
Enterprise Knowledge Graph는 모든 작업에 대해 새로운 BigQuery 테이블에 결과를 씁니다. 이는 작업이 실행될 때의 데이터 스냅샷입니다. 기본적으로 모든 작업은 각 항목 클러스터에 대해 임의의 cluster_id를 생성합니다. 하지만 여러 작업 실행 간에 ID를 안정적으로 유지하려면 previous BigQuery result table 고급 옵션을 사용하세요.
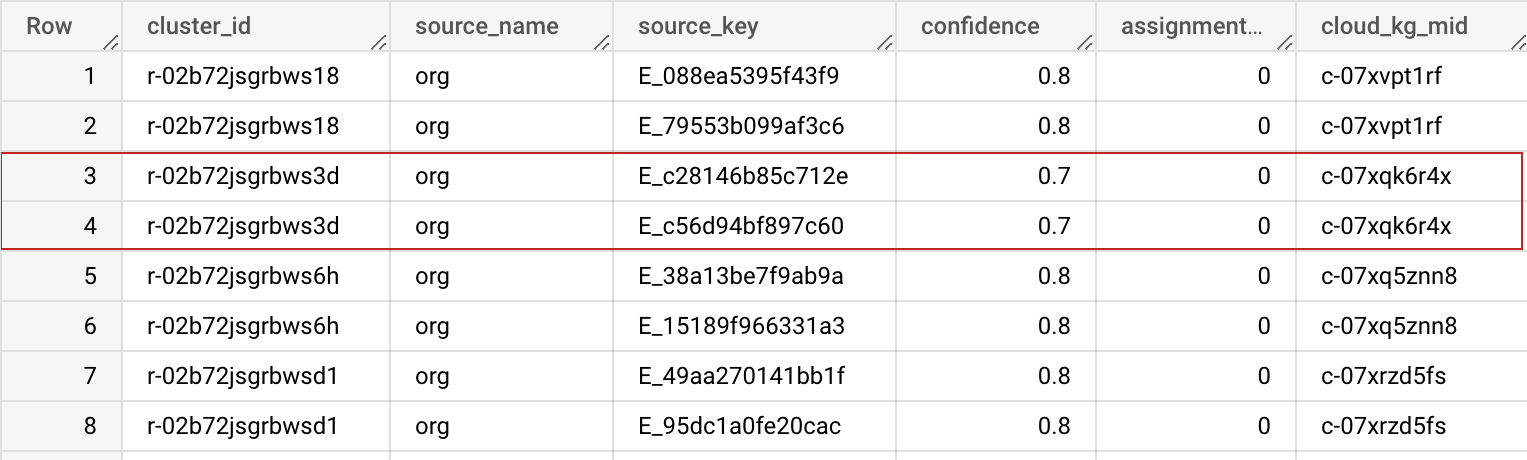
출력 스키마
| 필드 이름 | 유형 | 설명 |
|---|---|---|
| cluster_id | STRING | 이 클러스터 ID는 이 레코드 클러스터에 할당된 비공개 지식 그래프 머신 ID (MID)입니다. 데이터 세트에서 레코드를 고유하게 식별하는 데 사용할 수 있습니다. 고급 옵션의 이전 BigQuery 테이블 을 사용하여 여러 실행에서 이 cluster_id를 안정적이고 일관되게 유지할 수 있습니다. |
| source_name | STRING | 데이터 세트를 함께 조인하는 데 도움이 되도록 입력 구성에 지정된 소스 이름입니다. |
| source_key | STRING | 데이터 세트를 함께 조인하는 데 도움이 되도록 소스 테이블의 고유 키입니다. |
| confidence | FLOAT | 이러한 레코드가 이 클러스터에 속하는 정도를 결정하는 신뢰도 점수입니다. |
| assignment_age | INTEGER | 여러 작업에서 cluster_id (MID) 안정화를 위해 내부적으로 사용됩니다. |
| cloud_kg_mid | STRING | Google Cloud 지식 그래프 연결 항목 MID입니다. 이 MID를 영구 ID로 사용하거나 Cloud Knowledge Graph API에서 추가 세부정보를 조회할 수 있습니다. |
SQL을 사용하여 데이터 세트 함께 조인
Enterprise Knowledge Graph는 클러스터 ID별로 그룹화된 항목을 출력합니다. 결과를 보는 가장 간단한 방법은 클러스터 ID를 사용하여 결과를 '그룹화'하는 것입니다. 다음 예에서는 출력 테이블을 원래 테이블과 조인하여 빠른 상태 점검을 실행합니다.
# get all entity clusters
SELECT distinct (cluster_id) FROM `ekg-test.<dataset>.clusters_9425187210682344597` order by cluster_id LIMIT 1000;
# join data with original table
SELECT confidence, RS., SRC. FROM `ekg-test.<dataset>.clusters_9425187210682344597` as RS join `ekg-api-test.demo.organization` as SRC
on RS.source_key = SRC.source_key where cluster_id = "r-02b72jsgrbws18";
이 항목 클러스터는 동일한 클러스터에 속하는 두 개의 서로 다른 레코드를 나타냅니다. 동일한 cluster_id는 이러한 두 레코드를 조인하고 병합해야 함을 나타냅니다.

성공 측정
쌍별
정밀도: 유사한 거짓양성으로 잘못 식별된 고유 항목의 비율입니다 (수동 검사로 더 쉽게 감지할 수 있음).
재현율: 거짓음성으로 식별되지 않거나 감지하기 어려운 유사한 항목의 비율입니다.
클러스터 V 측정
클러스터 V 측정: (1 + 베타) * 동질성 * 완전성 / (베타 동질성 + 완전성) 여기서 베타=1입니다.
클러스터 동질성: 동일한 항목에 속하는 항목이 있는 클러스터의 비율입니다.
클러스터 완전성: 동일한 항목에 속하는 모든 항목이 동일한 클러스터에 배치되는 클러스터의 비율입니다.