
조정 (또는 클러스터링) 신뢰도 점수는 항목이 클러스터에 할당되는 신뢰도 수준을 나타내는 측정항목입니다. 그런 다음 클러스터링 모델이 불확실하다고 판단하는 예측을 필터링하고, 나머지 신뢰할 수 있는 결과를 기반으로 결정을 내릴 수 있습니다.
신뢰도 점수가 생성되는 방식
클러스터링은 하드 할당을 생성합니다. 각 항목은 정확히 하나의 클러스터에 할당됩니다. 신뢰도 점수는 노드가 할당된 클러스터에 속하는 신뢰도 수준을 설명하며, [0, 1] 사이의 값을 갖습니다.
1.0 = 항목이 할당된 클러스터에 속한다고 매우 확신함
0.0 = 엔티티가 할당된 클러스터에 속할 가능성이 매우 낮음
엔티티 쌍 간에 유사성/거리 개념이 있습니다. 클러스터 내의 엔티티 쌍은 서로 다른 클러스터에 걸쳐 있는 쌍보다 거리가 더 짧을 가능성이 높습니다. 엔티티가 클러스터의 다른 구성원과 멀리 떨어져 있을수록 신뢰도 값이 낮아집니다.
다른 클러스터도 신뢰도 점수에 영향을 줍니다. 엔티티 근처에 다른 클러스터가 있는 경우 해당 클러스터와의 거리에 따라 신뢰도가 감소합니다.
클러스터 밀도는 클러스터의 모든 엔티티 쌍 간의 거리와 관련이 있으며 신뢰도 값에도 영향을 미칩니다. 클러스터에서 고정된 거리에 있는 모든 엔티티의 경우 클러스터 밀도가 낮으면 신뢰도가 높고 클러스터 밀도가 높으면 신뢰도가 낮습니다.
조정 파이프라인이 수백만 또는 수십억 개의 항목으로 확장되도록 신뢰도 점수 계산에서는 무작위 샘플링 방법을 활용하여 계산 복잡성을 제한합니다. 따라서 신뢰도 점수는 0.1 크기의 구간으로 분류됩니다. 따라서 정확한 신뢰도 값을 기반으로 검토 또는 인간 참여형 결정을 내리지 않는 것이 좋습니다.
다이어그램 키
다음 설명을 사용하여 다이어그램을 이해하세요.
| 설명 | 다이어그램 |
|---|---|
| 항목 |  |
| 엔티티 클러스터입니다. 원으로 묘사된 항목 클러스터 클러스터 확산은 원의 크기로 표시됩니다. |
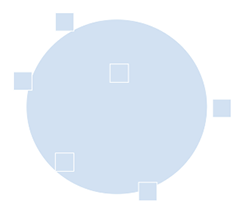 |
| 여러 항목 클러스터 색상 코딩: 항목과 할당된 클러스터가 동일한 색상을 공유합니다. | 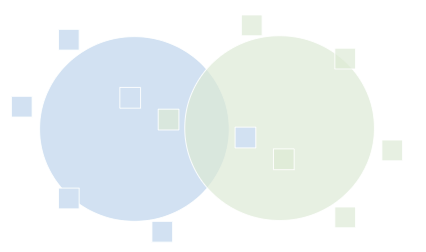 |
| 경우에 따라 단일 항목과 다른 클러스터와의 관계에 중점을 둡니다. 다른 모든 항목은 숨겨집니다. d_a: 항목에서 클러스터 A의 중심까지의 거리 d_b: 항목에서 클러스터 B의 중심까지의 거리 c: 항목의 클러스터 신뢰도 점수 |
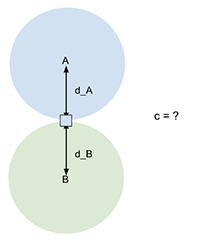 |
설명 예시
다음 다이어그램은 신뢰도 점수를 결정하는 대략적인 개념을 시각화하는 데 도움이 되는 예시입니다.
| 상황 | 다이어그램 |
|---|---|
| 항목이 클러스터 A에 할당됩니다. A가 전체 삽입 공간에서 유일한 클러스터인 경우 두 클러스터 간 거리에 관계없이 신뢰도 점수는 항상 1입니다. | 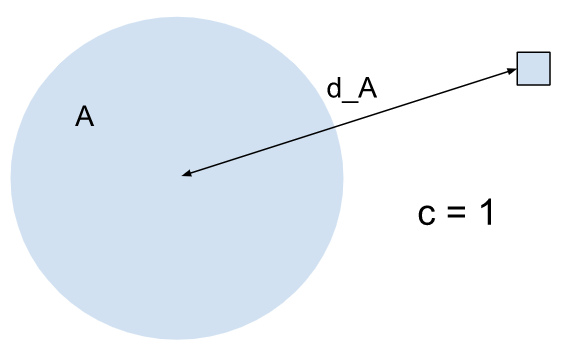 |
A와 B는 스프레드가 동일한 클러스터이며 중심이 항목에서 동일한 거리에 있습니다. 두 클러스터 모두 엔티티에 동일한 영향을 미치므로 신뢰도 점수는 0.5입니다. |
 |
근처에 다른 클러스터가 있으면 엔티티에 영향을 미치고 신뢰도 점수가 희석됩니다. 동일한 확산의 클러스터가 3개 있고 항목이 세 클러스터 모두에서 동일한 거리에 있는 경우 신뢰도 점수는 0.33입니다. |
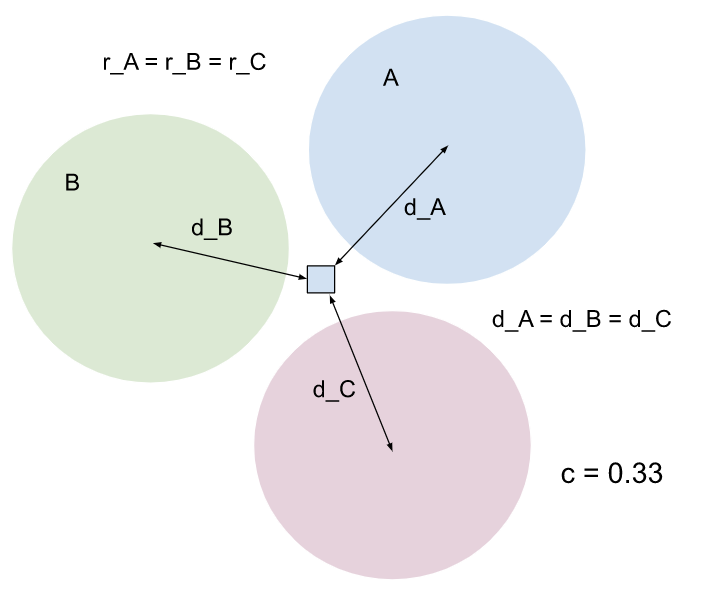 |
A와 B는 스프레드가 동일한 클러스터이지만 항목이 B보다 A에 더 가깝습니다. A가 항목에 더 큰 영향을 미칩니다. 엔티티가 A에도 할당되므로 신뢰도 점수가 0.5보다 커집니다. |
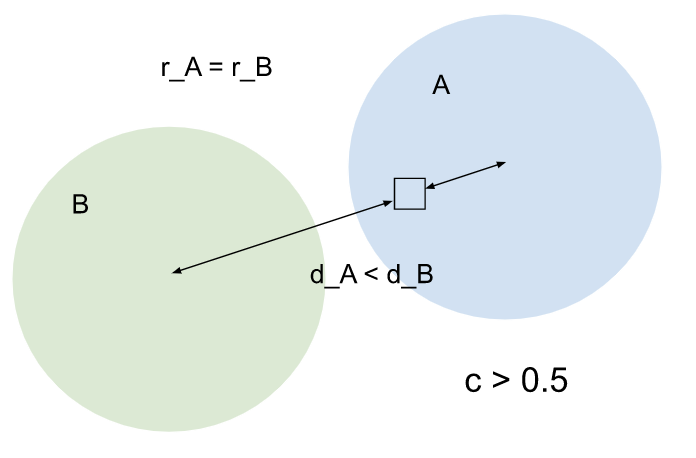 |
A와 B는 스프레드가 동일한 클러스터이지만 항목이 A보다 B에 더 가깝습니다. 따라서 A가 엔티티에 미치는 영향이 줄어듭니다. 신뢰도 점수가 0.5 미만입니다. |
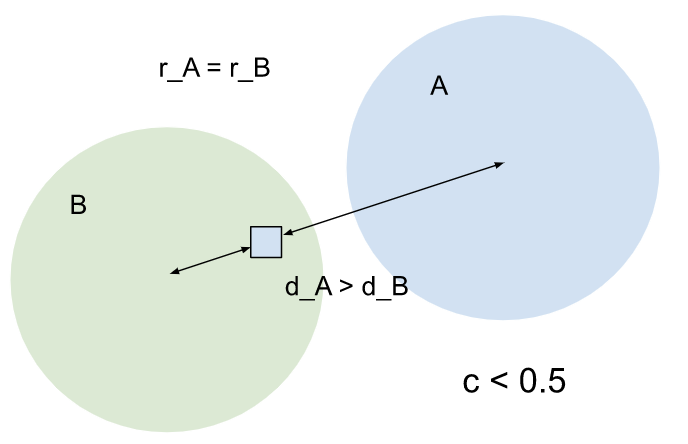 |
A의 분산이 B보다 크지만 중심점은 항목에서 동일한 거리에 있습니다. A가 항목에 더 큰 영향을 미칩니다. 엔티티가 A에도 할당되므로 신뢰도 점수가 0.5보다 커집니다. |
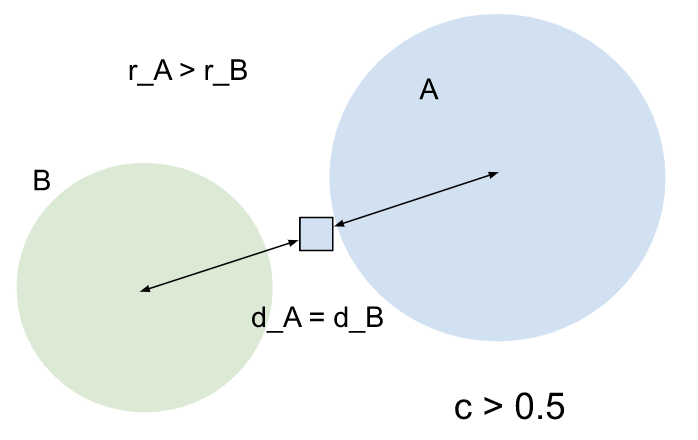 |