
本快速入門導覽課程將介紹 Entity Reconciliation API。在本快速入門導覽課程中,您將使用 Google Cloud 控制台設定Google Cloud 專案和授權、建立結構定義對應檔案,然後要求 Enterprise Knowledge Graph 執行實體比對工作。
如要直接在 Google Cloud 控制台中,按照這項工作的逐步指南操作,請按一下「Guide me」(逐步引導):
找出資料來源
Entity Reconciliation API 僅支援 BigQuery 資料表做為輸入內容。如果資料未儲存在 BigQuery 中,建議您在更多連結器推出前,先將資料轉移至 BigQuery。此外,請確認您設定的服務帳戶或 OAuth 用戶端具有您打算使用的資料表讀取權限,以及目的地資料集的寫入權限。
建立結構定義對應檔案
您必須為每個資料來源建立結構定義對應檔,通知 Enterprise Knowledge Graph 如何擷取資料。
Enterprise Knowledge Graph 使用稱為 YARRRML 的簡單格式語言 (可供人閱讀),定義來源結構定義與目標常見圖形本體之間的對應關係 schema.org。
Enterprise Knowledge Graph 僅支援 1:1 的簡單對應。
系統支援下列對應至 schema.org 中類型的實體類型:
結構定義對應檔範例
機構
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
人物
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
在來源字串 example_project:example_dataset.example_table~bigquery 中,~bigquery 是固定字串,表示資料來源來自 BigQuery。
在述詞清單 (po) 中,ekg:recon.source_name 和 ekg:recon.source_key 是系統使用的保留述詞名稱,且一律須在對應檔案中提及。通常,述詞 ekg:recon.source_name 會採用來源的常數值 (在本例中為 (Patients))。述詞 ekg:recon.source_key 會採用來源資料表的不重複鍵 (在本例中為 $(source_key)),代表來源資料欄 ID 的變數值。
如果您有多個資料表或來源要在對應檔案中定義,或在一次 API 呼叫中有多個不同的對應檔案,請務必確保不同來源的主體值不重複。你可以使用前置字串加上來源資料欄鍵,確保鍵值不重複。舉例來說,如果您有兩個結構定義相同的「人員」資料表,可以為主體 (s) 值指派不同格式:ekg:person1_$(record_id) 和 ekg:person2_$(record_id)。
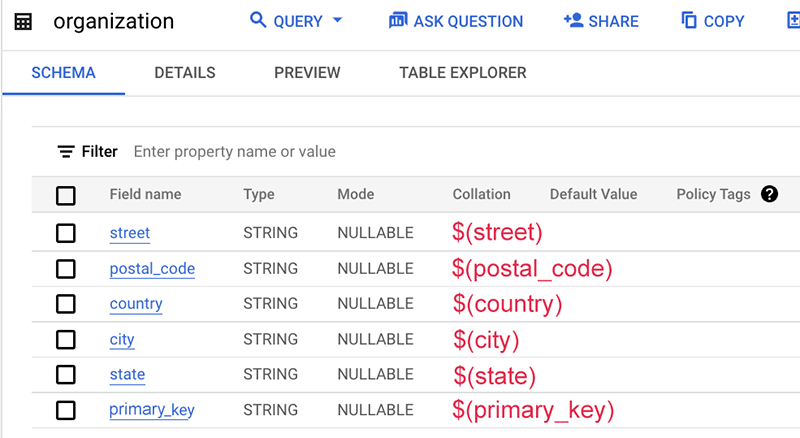
以下是對應檔案的範例:
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
在本例中,資料表結構定義本身不含這個資料來源的名稱 (通常是資料表名稱或資料庫名稱)。因此,我們使用不含貨幣符號 $ 的靜態字串「org」。
建立實體協調工作
使用 Google Cloud 控制台建立對帳工作。
開啟 Enterprise Knowledge Graph 資訊主頁。
按一下「結構定義對應」,為每個資料來源建立範本對應檔,然後將對應檔儲存在 Cloud Storage。

按一下「工作」和「執行工作」,即可設定工作參數,然後啟動工作。
實體類型
值 模型名稱 說明 Organizationgoogle_brasil在 Organization層級比對實體。例如公司名稱。這與LocalBusiness不同,後者著重於特定分店、搜尋點或實體位置,例如公司眾多園區中的其中一個。LocalBusinessgoogle_cyprus根據特定分店、搜尋點或實體店面調解實體。也可以將地理座標做為模型輸入內容。 Persongoogle_atlantis根據 schema.org中一組預先定義的屬性,比對人員實體。資料來源
僅支援 BigQuery 資料表。
目的地
輸出路徑應為 BigQuery 資料集,且 Enterprise Knowledge Graph 具有寫入權限。
每執行一項工作,Enterprise Knowledge Graph 就會建立新的 BigQuery 資料表,並加上時間戳記來儲存結果。
如果您使用實體對帳 API,工作回應會包含完整的輸出表格名稱和位置。
視需要設定「進階選項」。
按一下「完成」即可開始作業。
監控工作狀態
您可以透過 Google Cloud 控制台和 API 監控工作狀態。視資料集中的記錄數量而定,這項工作最多可能需要 24 小時才能完成。按一下個別工作,即可查看工作詳細設定。
您也可以檢查工作狀態,瞭解目前步驟。
| 工作顯示狀態 | 程式碼狀態 | 說明 |
|---|---|---|
| 執行中 | JOB_STATE_RUNNING |
工作正在進行中。 |
| 擷取知識 | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph 會從 BigQuery 擷取資料並建立特徵。 |
| 預先處理協調作業 | JOB_STATE_RECON_PREPROCESSING |
工作處於對帳預先處理步驟。 |
| 分群 | JOB_STATE_CLUSTERING |
工作處於叢集步驟。 |
| 匯出叢集 | JOB_STATE_EXPORTING_CLUSTERS |
這項工作會將輸出內容寫入 BigQuery 目的地資料集。 |
每項工作的執行時間會因多項因素而異,例如資料複雜度、資料集大小,以及同時執行的平行工作數量。以下是作業執行時間與資料集大小的粗略估算,供您參考。實際完成時間會有所不同。
| 記錄總數 | 執行時間 |
|---|---|
| 10 萬 | 約 2 小時 |
| 100M | 約 16 小時 |
| 3 億 | 約 24 小時 |
取消對帳工作
您可以透過 Google Cloud 控制台 (在工作詳細資料頁面) 和 API cancel 執行中的工作;Enterprise Knowledge Graph 會盡快停止工作。我們不保證 cancel 指令會成功執行。
進階選項
| 設定 | 說明 |
|---|---|
| 過往結果 BigQuery 資料表 | 指定先前的結果資料表,可確保不同工作使用相同的叢集 ID。然後將叢集 ID 做為永久 ID。 |
| 鄰近傳播分群法 | 這是大多數情況下的建議選項。這是階層聚合式分群法的平行版本,擴充性極佳。您可以在 [1, 5] 範圍內指定叢集回合 (疊代) 數。數字越高,演算法就越容易過度合併叢集。
|
| 連線元件叢集 | 預設選項。這是替代的舊版選項,只有在親和性叢集無法順利處理資料集時,才建議使用這個選項。權重門檻可以是 [0.6, 1] 範圍內的數字。 |
| 地理編碼分隔 | 這個選項可確保不同地理區域的實體不會聚集在一起。 |