
Este guia de início rápido apresenta a API Entity Reconciliation. Neste guia de início rápido, você vai usar o Google Cloud console para configurar o Google Cloud projeto e a autorização, criar arquivos de mapeamento de esquema e, em seguida, fazer uma solicitação para que o Enterprise Knowledge Graph execute um job de reconciliação de entidades.
Para seguir as instruções detalhadas desta tarefa diretamente no Google Cloud console, clique em Orientações:
Identificar a fonte de dados
A API Entity Reconciliation aceita apenas tabelas do BigQuery como entrada. Se os dados não estiverem armazenados no BigQuery, recomendamos que você os transfira para o BigQuery antes que mais conectores fiquem disponíveis. Além disso, verifique se a conta de serviço ou o cliente OAuth configurado tem acesso de leitura às tabelas que você planeja usar e permissão de gravação no conjunto de dados de destino.
Criar um arquivo de mapeamento de esquema
Para cada uma das suas fontes de dados, é necessário criar um arquivo de mapeamento de esquema para informar ao Enterprise Knowledge Graph como ingerir os dados.
O Enterprise Knowledge Graph usa uma linguagem de formato simples legível por humanos chamada
YARRRML para definir os mapeamentos entre o
esquema de origem e as ontologias de gráfico comum de destino,
schema.org.
O Enterprise Knowledge Graph aceita apenas mapeamentos simples 1:1.
Os seguintes tipos de entidades que correspondem a tipos em schema.org são aceitos:
Exemplos de arquivos de mapeamento de esquema
Organização
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
Pessoa
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
Para a string de origem example_project:example_dataset.example_table~bigquery,
~bigquery é a string fixa que indica que a fonte de dados vem do BigQuery.
Na lista de predicados (po), ekg:recon.source_name e ekg:recon.source_key são nomes de predicados reservados usados pelo sistema e sempre precisam ser mencionados no arquivo de mapeamento. Normalmente, o predicado ekg:recon.source_name usa um valor constante para a origem (neste exemplo, (Patients)). O predicado ekg:recon.source_key usa a chave exclusiva da tabela de origem (neste exemplo, $(source_key)), que representa o valor da variável do ID da coluna de origem).
Se você tiver várias tabelas ou fontes a serem definidas nos arquivos de mapeamento ou arquivos de mapeamento diferentes em uma chamada de API, verifique se o valor do assunto é exclusivo em diferentes fontes. É possível usar o prefixo mais a chave da coluna de origem para torná-lo exclusivo. Por exemplo, se você tiver duas tabelas de pessoas com
o mesmo esquema, poderá atribuir formatos diferentes ao valor do assunto (s):
ekg:person1_$(record_id) e ekg:person2_$(record_id).
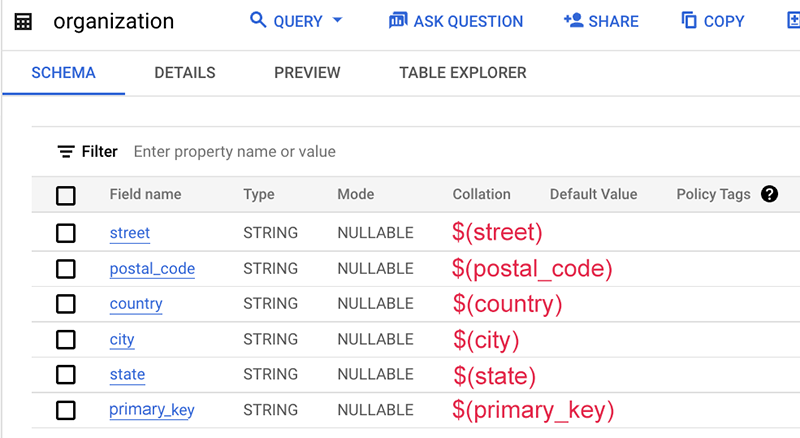
Confira um exemplo do arquivo de mapeamento:
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
Neste exemplo, o esquema da tabela não contém o nome dessa fonte de dados, que normalmente é o nome da tabela ou do banco de dados. Portanto, usamos uma string estática "org" sem o cifrão $.
Criar um job de reconciliação de entidades
Use o Google Cloud console para criar um job de reconciliação.
Abra o painel do Enterprise Knowledge Graph.
Clique em Mapeamento de esquema para criar arquivos de mapeamento com base no nosso modelo para cada uma das suas fontes de dados e salve o arquivo de mapeamento no Cloud Storage.

Clique em Job e Executar um job para configurar os parâmetros do job antes de iniciá-lo.
Tipo de entidade
Valor Nome do modelo Descrição Organizationgoogle_brasilReconciliar entidades no nível Organization. Por exemplo, o nome de uma corporação como uma empresa. Isso é diferente deLocalBusiness, que se concentra em uma filial, ponto de interesse ou presença física específica, por exemplo, um dos muitos campi da empresa.LocalBusinessgoogle_cyprusReconciliar a entidade com base em uma filial, ponto de interesse ou presença física específica. Também é possível usar coordenadas geográficas como entrada do modelo. Persongoogle_atlantisReconciliar a entidade da pessoa com base em um conjunto de atributos predefinidos em schema.org.Fontes de dados
Apenas tabelas do BigQuery são aceitas.
Destino
O caminho de saída precisa ser um conjunto de dados do BigQuery, em que o Enterprise Knowledge Graph tenha permissão para gravar.
Para cada job executado, o Enterprise Knowledge Graph cria uma nova tabela do BigQuery com carimbo de data/hora para armazenar os resultados.
Se você usar a API Entity Reconciliation, a resposta do job vai conter o nome e o local completos da tabela de saída.
Configure as Opções avançadas , se necessário.
Para iniciar o job, clique em Concluído.
Monitorar o status do job
É possível monitorar o status do job no Google Cloud console e na API. O job pode levar até 24 horas para ser concluído, dependendo do número de registros nos conjuntos de dados. Clique em cada job individual para conferir a configuração detalhada dele.
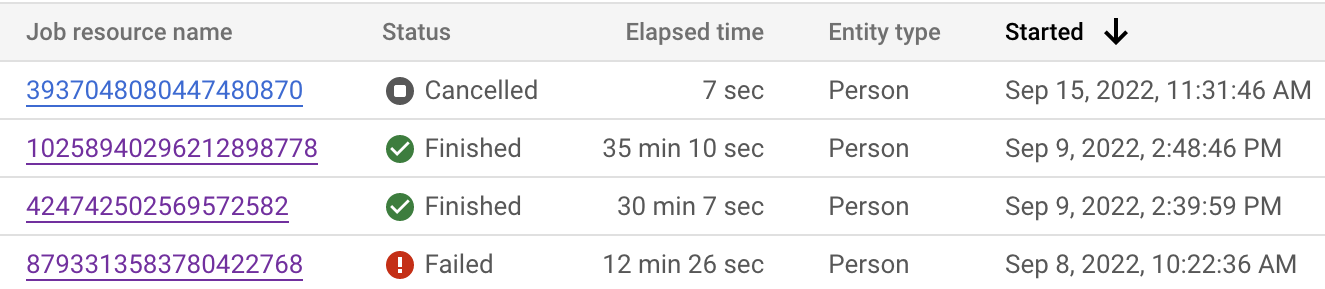
Também é possível inspecionar o status do job para conferir a etapa atual.
| Estado de exibição do job | Estado do código | Descrição |
|---|---|---|
| Em execução | JOB_STATE_RUNNING |
O job está em andamento. |
| Extração de conhecimento | JOB_STATE_KNOWLEDGE_EXTRACTION |
O Enterprise Knowledge Graph está extraindo dados do BigQuery e criando recursos. |
| Pré-processamento de reconciliação | JOB_STATE_RECON_PREPROCESSING |
O job está na etapa de pré-processamento de reconciliação. |
| Clustering | JOB_STATE_CLUSTERING |
O job está na etapa de clustering. |
| Exportando clusters | JOB_STATE_EXPORTING_CLUSTERS |
O job está gravando a saída no conjunto de dados de destino do BigQuery. |
O tempo de execução de cada job varia dependendo de muitos fatores, como a complexidade dos dados, o tamanho do conjunto de dados e quantos outros jobs paralelos estão em execução ao mesmo tempo. Confira uma estimativa aproximada do tempo de execução do job em relação ao tamanho do conjunto de dados para sua referência. O tempo real de conclusão do job será diferente.
| Número total de registros | Tempo de execução |
|---|---|
| 100.000 | ~2 horas |
| 100 milhões | ~16 horas |
| 300 milhões | ~24 horas |
Cancelar um job de reconciliação
É possível cancel um job em execução no Google Cloud console (na página de detalhes do job) e na API. O Enterprise Knowledge Graph interrompe o job na primeira oportunidade, com base no melhor esforço. O sucesso do comando cancel não é garantido.
Opções avançadas
| Configuração | Descrição |
|---|---|
| Tabela do BigQuery do resultado anterior | Especificar uma tabela de resultados anterior mantém o ID do cluster estável em diferentes jobs. Em seguida, é possível usar o ID do cluster como ID permanente. |
| Clustering de afinidade | Opção recomendada para a maioria dos casos. É uma versão paralela do clustering hierárquico aglomerativo e é muito bem dimensionada. O número de rodadas de clustering (iterações) pode ser especificado no intervalo [1, 5]. Quanto maior o número, mais o algoritmo tende a mesclar o cluster.
|
| Clustering de componentes conectados | Opção padrão. Essa é uma opção alternativa e legada. Tente essa opção apenas se o clustering de afinidade não funcionar bem no seu conjunto de dados. O limite de peso pode ser um número no intervalo [0.6, 1]. |
| Separação por geocodificação | Essa opção garante que entidades de diferentes regiões geográficas não sejam agrupadas. |