
Ce guide de démarrage rapide présente l'API Entity Reconciliation. Dans ce guide de démarrage rapide, vous allez utiliser la Google Cloud console pour configurer votre Google Cloud projet et les autorisations, créer des fichiers de mappage de schéma, puis envoyer une requête à Enterprise Knowledge Graph pour exécuter un job de rapprochement d'entités.
Pour obtenir des instructions détaillées sur cette tâche directement dans la Google Cloud console, cliquez sur Visite guidée:
Identifier votre source de données
L'API Entity Reconciliation n'accepte que les tables BigQuery comme entrée. Si vos données ne sont pas stockées dans BigQuery, nous vous recommandons de les transférer vers BigQuery avant que d'autres connecteurs ne soient disponibles. Assurez-vous également que le compte de service ou le client OAuth que vous avez configuré dispose d'un accès en lecture aux tables que vous prévoyez d'utiliser, ainsi que d'une autorisation d'écriture dans l'ensemble de données de destination.
Créer un fichier de mappage de schéma
Pour chacune de vos sources de données, vous devez créer un fichier de mappage de schéma afin d'indiquer à Enterprise Knowledge Graph comment ingérer les données.
Enterprise Knowledge Graph utilise un langage de format simple lisible par l'homme appelé
YARRRML pour définir les mappages entre
le schéma source et les ontologies de graphe commun cibles,
schema.org.
Enterprise Knowledge Graph n'est compatible qu'avec les mappages simples 1:1.
Les types d'entités suivants, qui correspondent aux types de schema.org, sont acceptés :
Exemples de fichiers de mappage de schéma
Organisation
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Organization:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:company_$(record_id)
po:
- [a, schema:Organization]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
LocalBusiness
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
LocalBusiness:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:local_business_$(record_id)
po:
- [a, schema:LocalBusiness]
- [schema:name, $(company_name_in_source)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [schema:url, $(url)]
- [schema:telephone, $(telephone)]
- [schema:latitude, $(latitude)]
- [schema:longitude, $(longitude)]
- [ekg:recon.source_name, $(source_system)]
- [ekg:recon.source_key, $(source_key)]
Personne
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
Person:
sources:
- [example_project:example_dataset.example_table~bigquery]
s: ekg:person_$(record_id)
po:
- [a, schema:Person]
- [schema:postalCode, $(ZIP)]
- [schema:birthDate, $(BIRTHDATE)]
- [schema:name, $(NAME)]
- [schema:gender, $(GENDER)]
- [schema:streetAddress, $(ADDRESS)]
- [ekg:recon.source_name, (Patients)]
- [ekg:recon.source_key, $(source_key)]
Pour la chaîne source example_project:example_dataset.example_table~bigquery,
~bigquery est la chaîne fixe indiquant que la source de données provient de BigQuery.
Dans la liste des prédicats (po), ekg:recon.source_name et ekg:recon.source_key sont des noms de prédicats réservés utilisés par le système et doivent toujours être mentionnés dans le fichier de mappage. Normalement, le prédicat ekg:recon.source_name prend une valeur constante pour la source (dans cet exemple, (Patients)). Le prédicat ekg:recon.source_key prend la clé unique de la table source (dans cet exemple, $(source_key)), qui représente la valeur de la variable à partir de l'ID de la colonne source).
Si vous avez plusieurs tables ou sources à définir dans les fichiers de mappage ou différents fichiers de mappage dans un seul appel d'API, vous devez vous assurer que la valeur du sujet est unique pour les différentes sources. Vous pouvez utiliser un préfixe plus une clé de colonne source pour la rendre unique. Par exemple, si vous avez deux tables de personnes avec
le même schéma, vous pouvez attribuer différents formats à la valeur du sujet (s) :
ekg:person1_$(record_id) et ekg:person2_$(record_id).
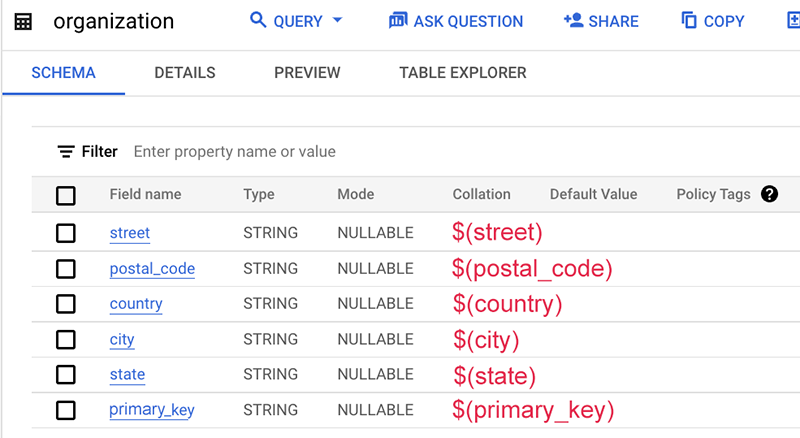
Voici un exemple de fichier de mappage :
prefixes:
ekg: http://cloud.google.com/ekg/0.0.1#
schema: https://schema.org/
mappings:
organization:
sources:
- [ekg-api-test:demo.organization~bigquery]
s: ekg:company_$(source_key)
po:
- [a, schema:Organization]
- [schema:name, $(source_name)]
- [schema:streetAddress, $(street)]
- [schema:postalCode, $(postal_code)]
- [schema:addressCountry, $(country)]
- [schema:addressLocality, $(city)]
- [schema:addressRegion, $(state)]
- [ekg:recon.source_name, (org)]
- [ekg:recon.source_key, $(primary_key)]
Dans cet exemple, le schéma de la table lui-même ne contient pas le nom de cette source de données, qui est généralement le nom de la table ou de la base de données. Par conséquent, nous utilisons une chaîne statique "org" sans le signe dollar $.
Créer un job de rapprochement d'entités
Utilisez la Google Cloud console pour créer un job de rapprochement.
Ouvrez le tableau de bord Enterprise Knowledge Graph.
Cliquez sur Mappage de schéma pour créer des fichiers de mappage à partir de notre modèle pour chacune de vos sources de données, puis enregistrez le fichier de mappage dans Cloud Storage.

Cliquez sur Job (Tâche) et Run A Job (Exécuter un job) pour configurer les paramètres du job avant de le démarrer.
Type d'entité
Valeur Nom du modèle Description Organizationgoogle_brasilRapprocher les entités au niveau Organization. Par exemple, le nom d'une entreprise en tant que société. Cela diffère deLocalBusiness, qui se concentre sur une branche, un point d'intérêt ou une présence physique particulière, par exemple, l'un des nombreux campus d'une entreprise.LocalBusinessgoogle_cyprusRapprocher l'entité en fonction d'une branche, d'un point d'intérêt ou d'une présence physique particulière. Il peut également prendre des coordonnées géographiques comme entrée de modèle. Persongoogle_atlantisRapprocher l'entité de la personne en fonction d'un ensemble d'attributs prédéfinis dans schema.org.Sources de données
Seules les tables BigQuery sont acceptées.
Destination
Le chemin de sortie doit être un ensemble de données BigQuery dans lequel Enterprise Knowledge Graph est autorisé à écrire.
Pour chaque job exécuté, Enterprise Knowledge Graph crée une table BigQuery avec un code temporel pour stocker les résultats.
Si vous utilisez l'API Entity Reconciliation, la réponse du job contient le nom et l'emplacement complets de la table de sortie.
Configurez les options avancées si nécessaire.
Pour démarrer le job, cliquez sur OK.
Surveiller l'état du job
Vous pouvez surveiller l'état du job à partir de la Google Cloud console et de l'API. L'exécution du job peut prendre jusqu'à 24 heures, selon le nombre d'enregistrements dans vos ensembles de données. Cliquez sur chaque job pour afficher sa configuration détaillée.
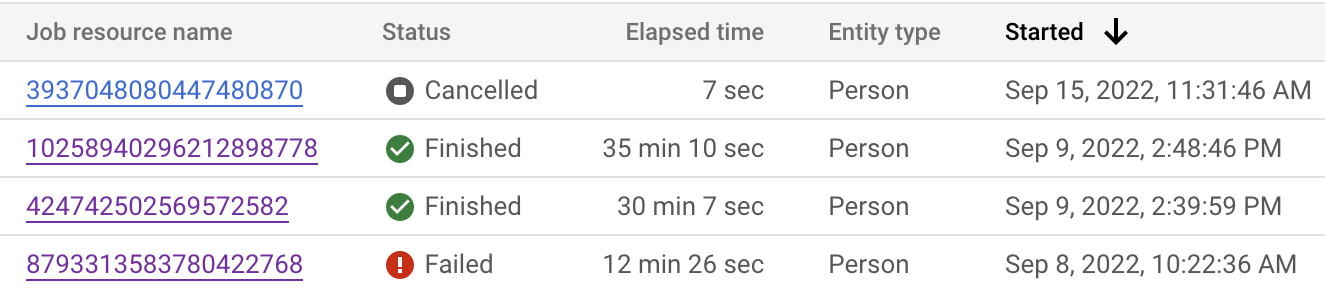
Vous pouvez également inspecter l'état du job pour voir où se trouve l'étape actuelle.
| État d'affichage du job | État du code | Description |
|---|---|---|
| En cours d'exécution | JOB_STATE_RUNNING |
Le job est en cours. |
| Extraction de connaissances | JOB_STATE_KNOWLEDGE_EXTRACTION |
Enterprise Knowledge Graph extrait des données de BigQuery et crée des fonctionnalités. |
| Prétraitement du rapprochement | JOB_STATE_RECON_PREPROCESSING |
Le job se trouve à l'étape de prétraitement du rapprochement. |
| Clustering | JOB_STATE_CLUSTERING |
Le job se trouve à l'étape de clustering. |
| Exportation des clusters | JOB_STATE_EXPORTING_CLUSTERS |
Le job écrit la sortie dans l'ensemble de données de destination BigQuery. |
La durée d'exécution de chaque job varie en fonction de nombreux facteurs, tels que la complexité des données, la taille de l'ensemble de données et le nombre d'autres jobs parallèles exécutés en même temps. Voici une estimation approximative de la durée d'exécution du job par rapport à la taille de l'ensemble de données à titre de référence. La durée réelle d'exécution de votre job sera différente.
| Nombre total d'enregistrements | Durée d'exécution |
|---|---|
| 100 000 | environ 2 heures |
| 100M | environ 16 heures |
| 300M | environ 24 heures |
Annuler un job de rapprochement
Vous pouvez cancel un job en cours d'exécution à partir de la Google Cloud console (sur la page d'informations du job) et de l'API. Enterprise Knowledge Graph arrête le job dès que possible, dans la mesure du possible. La réussite de la commande cancel n'est pas garantie.
Options avancées
| Configuration | Description |
|---|---|
| Table BigQuery des résultats précédents | La spécification d'une table de résultats précédente permet de maintenir l'ID de cluster stable pour différents jobs. Vous pouvez ensuite utiliser l'ID de cluster comme ID permanent. |
| Clustering d'affinité | Option recommandée dans la plupart des cas. Il s'agit d'une version parallèle du clustering agglomératif hiérarchique qui s'adapte très bien. Le nombre de cycles de clustering (itérations) peut être spécifié dans la plage [1, 5]. Plus le nombre est élevé, plus l'algorithme a tendance à fusionner le cluster.
|
| Clustering de composants connectés | Option par défaut. Il s'agit d'une option alternative et héritée. N'essayez cette option que si le clustering d'affinité ne fonctionne pas correctement sur votre ensemble de données. Le seuil de pondération peut être un nombre compris entre [0.6, 1]. |
| Séparation de géocodage | Cette option permet de s'assurer que les entités de différentes régions géographiques ne sont pas regroupées. |