
במאמר הזה מוסבר איך לבצע העלאה בכמות גדולה, שגורמת להפעלת צינור ההזנה של Cloud Storage ברקע.
אפשרויות לעיבוד מקדים
נכון לעכשיו, ההעלאה בכמות גדולה מספקת שלוש אפשרויות לעיבוד מקדים:
העלאה בכמות גדולה ללא עיבוד מוקדם: הפעולה הזו מפעילה את runPipeline API עם GcsIngestPipeline בלי לעבד את המסמכים באמצעות מעבדים של Document AI.
חילוץ ישויות באמצעות מעבדים של Document AI: הפעולה הזו מפעילה את runPipeline API עם GcsIngestWithDocAiProcessorsPipeline. הצינור יקרא קודם למעבד Document AI שצוין, ואז יטמיע את המסמכים עם התוצאות המעובדות.
סיווג סוגי מסמכים וחילוץ ישויות לכל סוג: הפעולה הזו מפעילה גם את runPipeline API עם GcsIngestWithDocAiProcessorsPipeline, שקודם קורא לסיווג. לאחר מכן, לכל סוג מסמך, אפשר לציין סכימה ומעבד מתאימים לעיבוד של סוגי המסמכים הספציפיים האלה. הם מוזנים עם התוצאות ומוגדרים לסכימה הזו.
כל אחד מסוגי העיבוד המקדים תואם לאחת מהאפשרויות הבאות בממשק המשתמש:
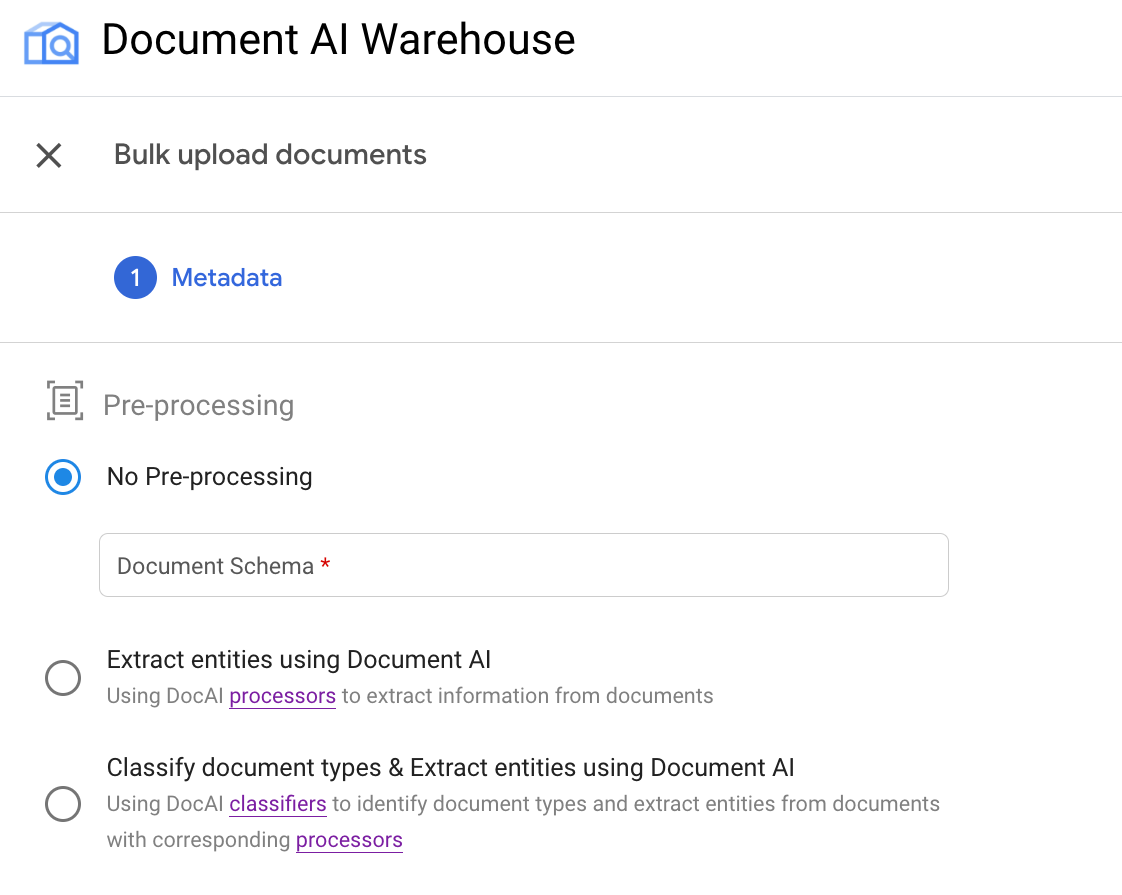
דוגמה: הפעלת העלאה בכמות גדולה באמצעות מעבד OCR
בדוגמה הזו מוצג השימוש השני בצינור העיבוד.
יצירת מעבד OCR וקבלת מזהה המעבד
אם יצרתם בעבר מעבד OCR, פשוט חפשו אותו ברשימת המעבדים, עברו לדף הפרטים של המעבד והעתיקו את מזהה המעבד.
אם לא יצרתם חשבון, אתם צריכים לפעול לפי השלבים הבאים:
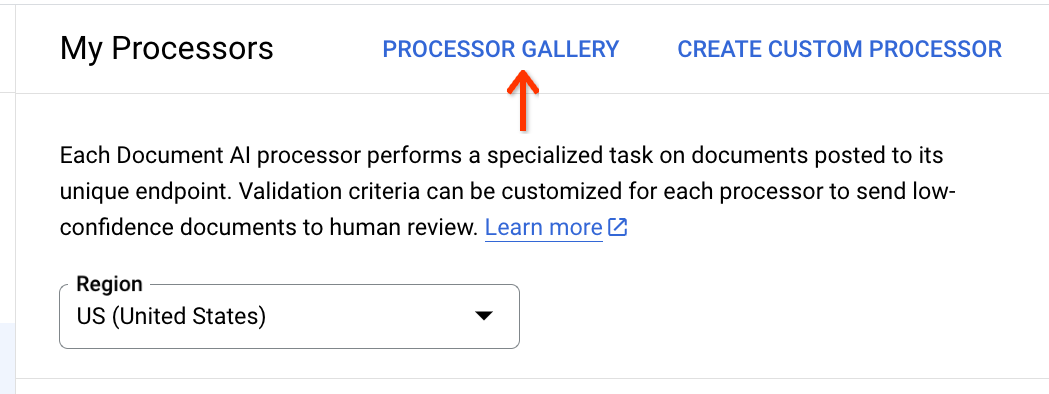
בחלק העליון של רשימת המעבדים, לוחצים על גלריית המעבדים:
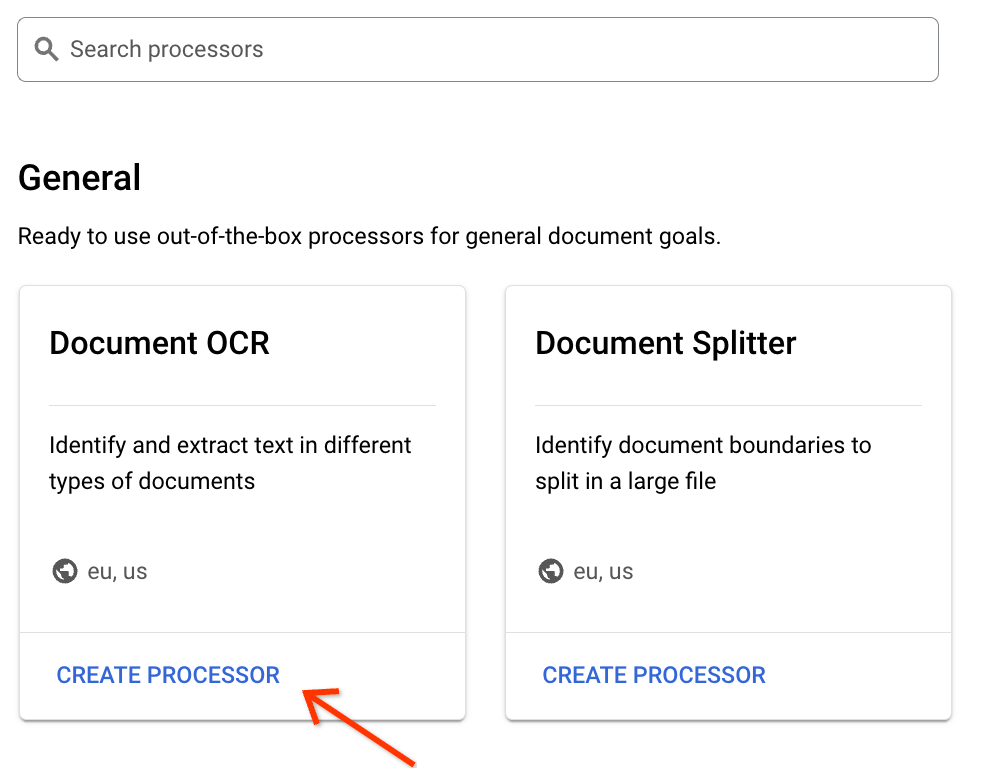
מוצאים את מעבד ה-OCR של המסמכים בגלריה, ובחלק התחתון של הכרטיס לוחצים על יצירת מעבד:
מזינים שם מוצג למעבד:
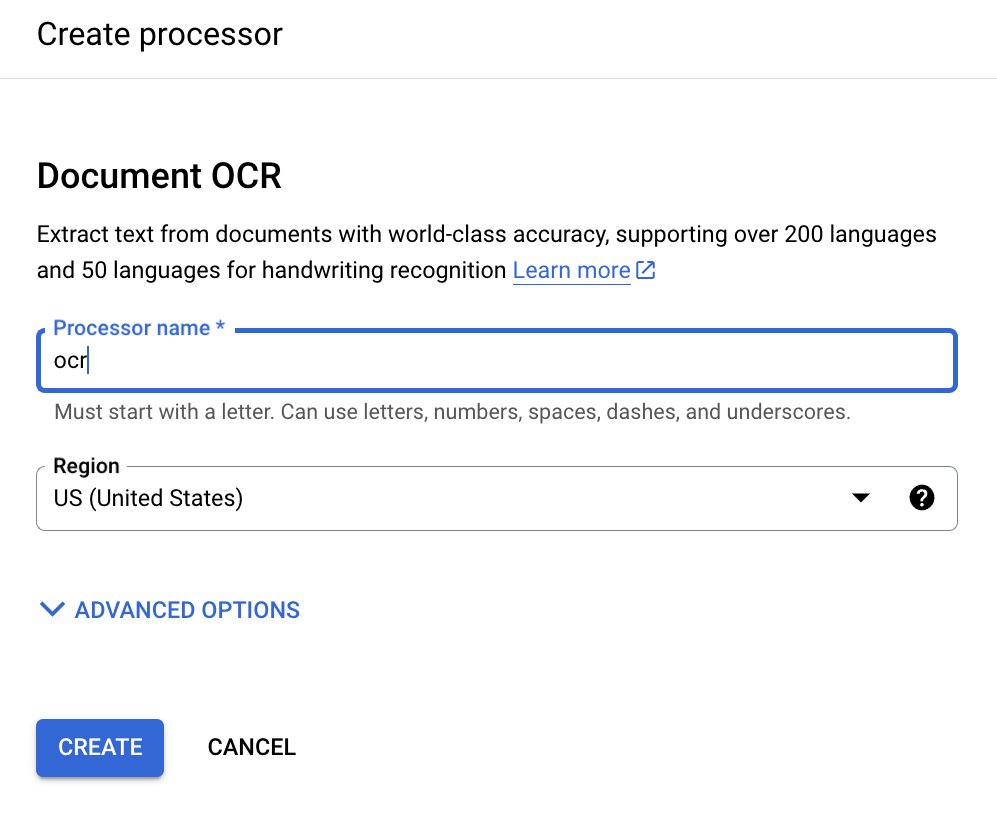
לוחצים על יצירה. כשמועברים לדף פרטי מעבד, מאתרים את המזהה:
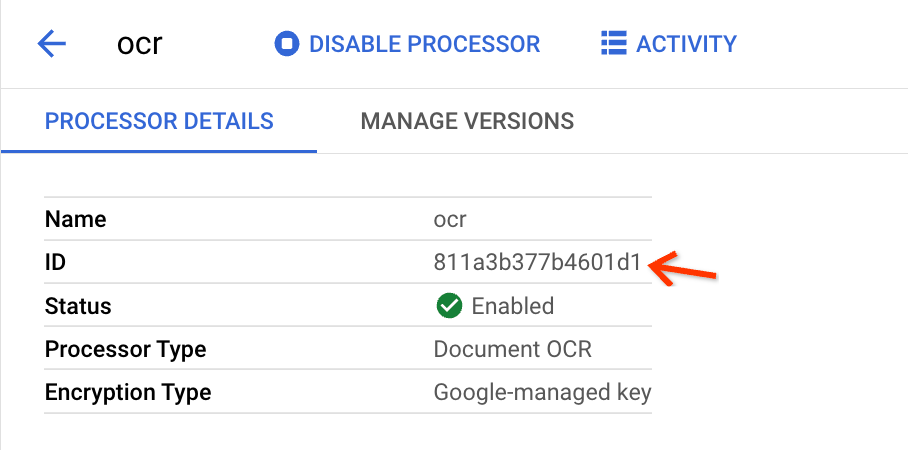
זה מה שצריך להעתיק לשדות הקלט בתצוגת ההעלאה בכמות גדולה.
הפעלת העלאה בכמות גדולה
פותחים את התצוגה של העלאה בכמות גדולה.
לצד הוספת פריט חדש, לוחצים על העלאה בכמות גדולה:
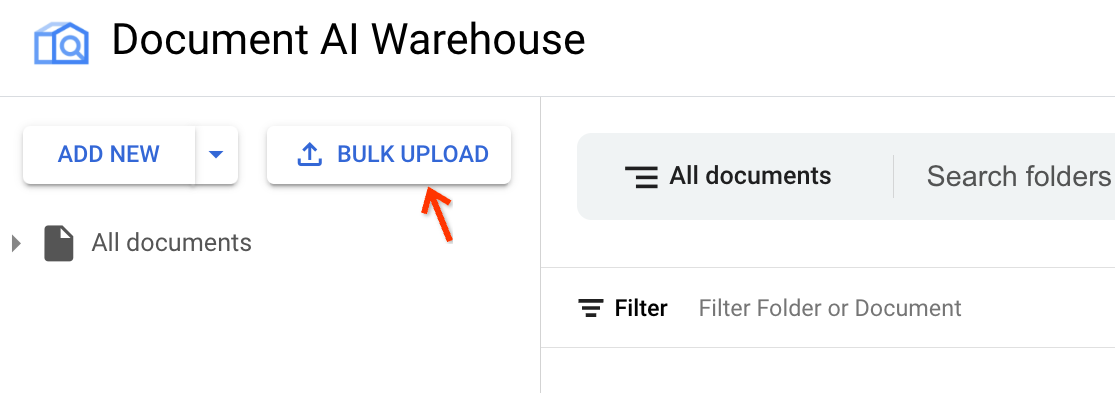
מאתרים את המעבד הנכון.
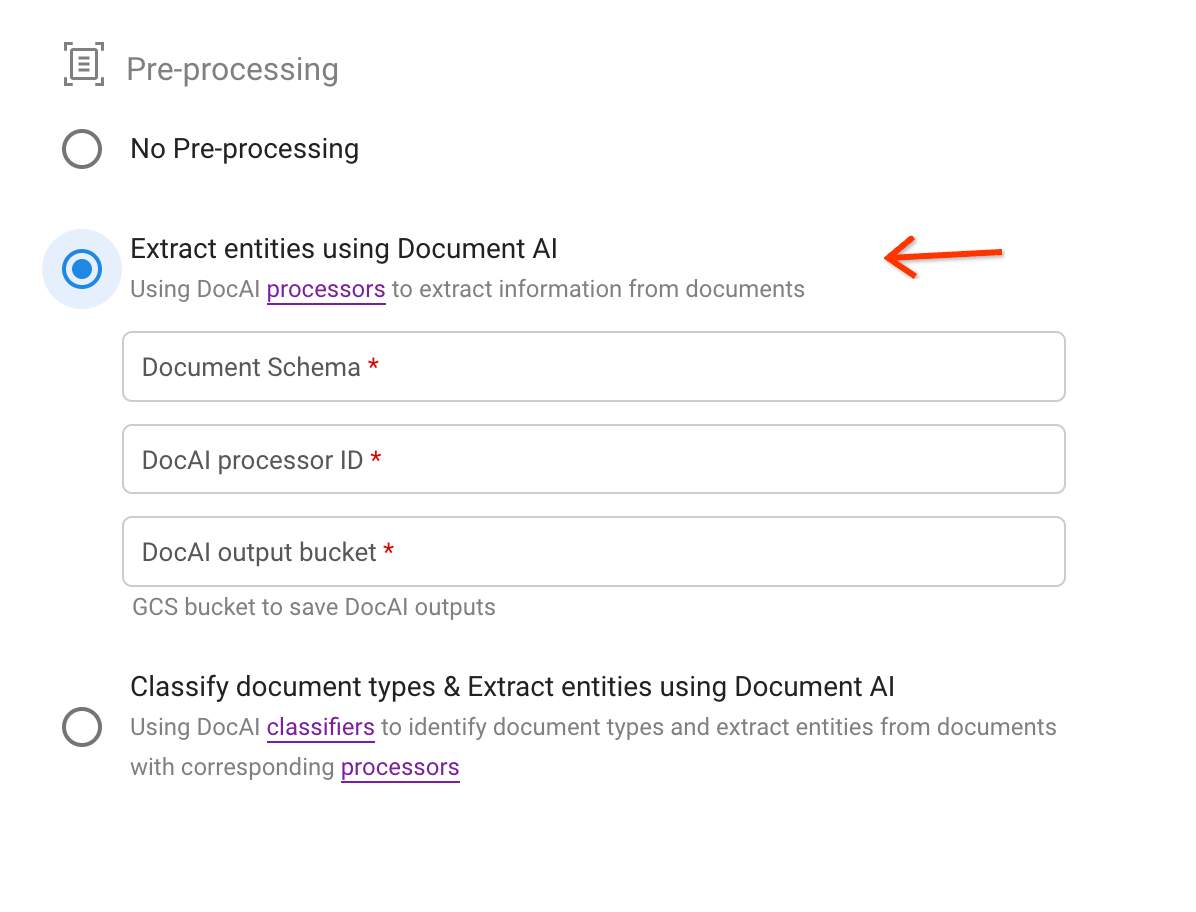
בוחרים באפשרות השנייה של עיבוד מקדים.
בוחרים סכימה ומציינים מעבד ונתיב לקטגוריה של Cloud Storage כדי לשמור את תוצאות החילוץ בפורמט JSON.
אפשר למצוא את מזהה המעבד באמצעות הקישור בתיאור:
הפעלת העלאה:
מעתיקים את מזהה המעבד מהשלב הקודם ומציינים את שדות הקלט. נתיב הדלי של קובץ המקור יכול להיות דלי, תיקייה או תיקיית משנה בדלי.
אם שדות הקלט תקינים, כדי להפעיל העלאה בכמות גדולה, לוחצים על העלאה בפינה השמאלית העליונה.
בדיקת ההתקדמות בדף הסטטוס
אחרי שמפעילים את ההעלאה בכמות גדולה, מועברים לדף מעקב הסטטוס:
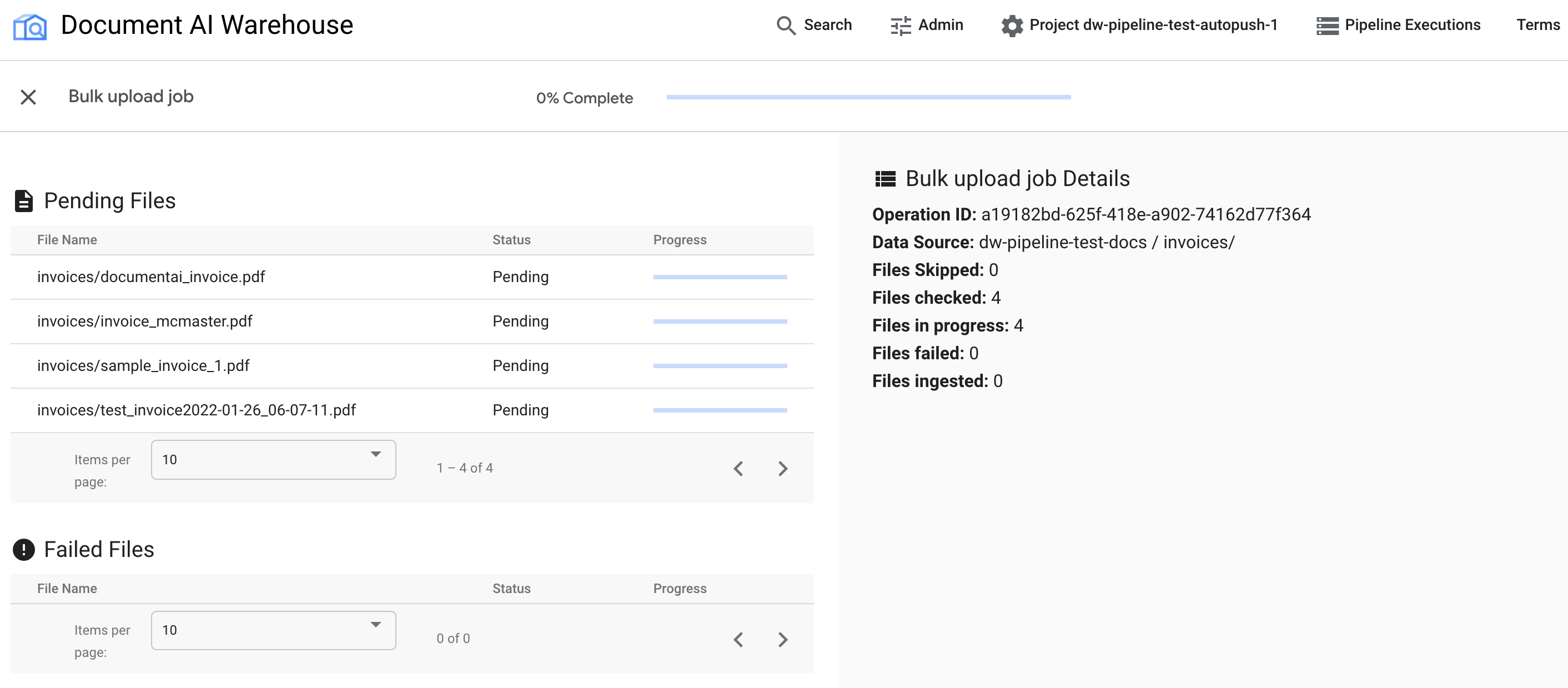
בטבלה הראשונה מוצגים מסמכים בהמתנה או מסמכים שעברו עיבוד. אחרי שהמסמך נטען, הוא לא מופיע יותר בטבלה הראשונה. מסמכים שלא הועלו מופיעים בטבלה השנייה. בצד שמאל, הנתונים הסטטיסטיים מראים את מספר המסמכים שהועלו, המסמכים שנכשלו והמסמכים שממתינים לאישור.
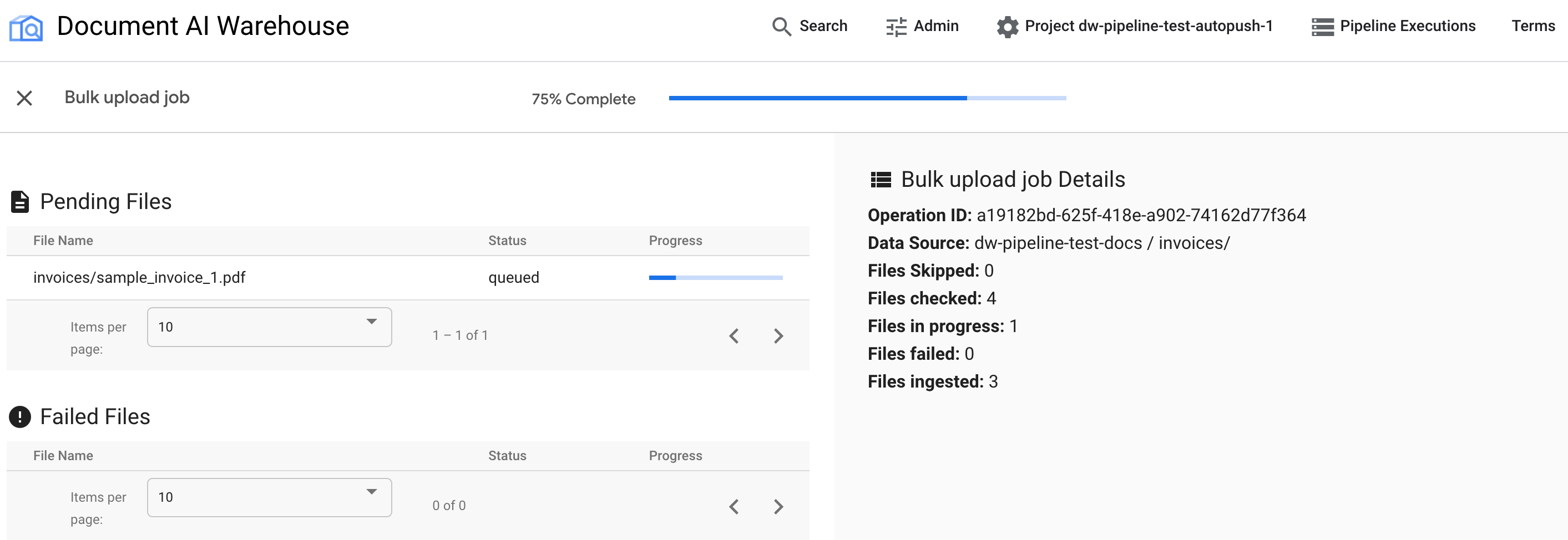
אחרי שהעבודה מסתיימת, בדף הסטטוס מוצג שהעבודה הושלמה ב-100% בלי מסמכים בהמתנה:
בדיקת המסמכים שהועלו
כדי למצוא את המסמכים החדשים שהועלו, חוזרים לתצוגת החיפוש. לוחצים על הלוגו של Document AI Warehouse או על חיפוש בסרגל הניווט העליון:

פותחים אחד מהמסמכים החדשים שהועלו על ידי לחיצה על שם המסמך. בתצוגת המסמך, אפשר לפתוח את תצוגת ה-AI.
עוברים לכרטיסייה בלוק טקסט. תוצאות ה-OCR מאוחסנות במסמך:
השלב הבא
עדכון מסמכים קיימים באמצעות צינור הנתונים extract with Document AI.