
BigQuery 커넥터 소개
BigQuery 커넥터를 사용하면 Document AI Warehouse에 저장된 문서의 메타데이터 (속성 포함)를 BigQuery 테이블로 내보낼 수 있습니다. BigQuery에 데이터가 있으면 분석을 실행하고 보고서와 대시보드를 만들어 비즈니스 의사결정을 내릴 수 있습니다.
BigQuery 커넥터를 사용 설정하려면 필요한 권한이 부여된 BigQuery 테이블을 설정하고 API를 통해 비동기 작업을 구성해야 합니다. BigQuery 커넥터는 Document AI Warehouse의 데이터를 BigQuery 테이블로 내보냅니다.
시작하기 전에
Document AI Warehouse를 설정하고 문서를 수집합니다. 자세한 내용은 빠른 시작을 따르세요.
BigQuery 테이블을 호스팅하는 프로젝트가 Document AI Warehouse에서 문서를 저장하는 데 사용하는 프로젝트와 동일해야 합니다. 즉, 데이터는 항상 Document AI Warehouse에서 동일한 프로젝트의 BigQuery 테이블로 내보내야 합니다.
프로젝트에서 Owner (roles/owner) 역할이 있거나 resourcemanager.projects.getIamPolicy 및 resourcemanager.projects.setIamPolicy
권한이 있어야 합니다.
BigQuery 액세스 설정
서비스 계정 doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
BigQuery Admin 역할에 결합합니다.
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
BigQuery 데이터 세트 및 테이블 설정
Document AI Warehouse에서 데이터를 내보낼 BigQuery 데이터 세트 및 테이블을 설정합니다. BigQuery 데이터 세트가 없는 경우 데이터 세트 만들기에 따라 데이터 세트를 만듭니다.
BigQuery 데이터 세트에서 BigQuery 테이블을 만듭니다. BigQuery 안내에 따라 DDL 샘플 문을 사용하여 테이블을 만듭니다.
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
DDL은 새 BigQuery 테이블을 만듭니다. 테이블은 시간별로 파티션을 나누고 파티션은 150일 후에 삭제됩니다.
BigQuery 커넥터 구성
데이터 내보내기 구성 만들기
다음 안내에서는 데이터를 내보내는 비동기 작업을 설정하는 새 데이터 내보내기 작업을 만듭니다. 각 새 데이터 내보내기 작업에 빈 테이블로 시작하는 것이 좋습니다. 구성의 세부정보는 API 참조 를 확인하세요.
다음과 같은 실행 옵션이 있습니다. FREQUENCY를 사용하여 구성할 수 있습니다.
API
참조를 확인하세요.
- ADHOC: 작업이 한 번만 실행됩니다. 모든 데이터가 BigQuery 테이블로 내보내집니다.
- DAILY: 작업이 매일 실행됩니다. 첫 번째 실행에서는 모든 데이터가 BigQuery 테이블로 내보내집니다. 초기 내보내기가 완료되면 이전 날짜의 데이터 변경사항 (또는 마지막으로 성공한 동기화의 델타)만 BigQuery 테이블로 내보내집니다.
- HOURLY: 작업이 시간별로 실행됩니다. 첫 번째 실행에서는 모든 데이터가 BigQuery 테이블로 내보내집니다. 초기 내보내기가 완료되면 이전 시간의 데이터 변경사항 (또는 마지막으로 성공한 동기화의 델타)만 BigQuery 테이블로 내보내집니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_NUMBER: 프로젝트 번호입니다. Google Cloud
- LOCATION: Document AI Warehouse 위치 (예: `us`)
- DATASET_LOCATION: 데이터 세트 위치
- DATASET_NAME: 데이터 세트 이름
- TABLE_NAME: 테이블 이름
-
FREQUENCY:
ADHOC,DAILY,HOURLY중 하나입니다.
JSON 요청 본문:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
작업 실행
작업을 만든 후에는 구성에 따라 작업이 실행됩니다. 작업은 실행하는 데 시간이 걸리므로 비동기식으로 실행됩니다. 내보낼 데이터 양에 따라 첫 번째 실행이 완료되는 데 시간이 걸릴 수 있습니다. 일일 작업의 경우 BigQuery 테이블에 결과가 표시되는 데 24시간이 걸릴 수 있습니다.
데이터 내보내기 구성 삭제
다음 명령어는 만든 작업을 삭제 (보관처리)합니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_NUMBER: 프로젝트 번호입니다. Google Cloud
- LOCATION: Document AI Warehouse 위치 (예: `us`)
- JOB_ID: 작업 ID(만들 때 응답에 있음)
JSON 요청 본문:
{}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
이후 내보내기 작업이 삭제 (보관처리)되고 Document AI Warehouse에서 더 이상 실행되지 않습니다.
BigQuery로 수집된 데이터 살펴보기
분석 요구사항에 따라 문서 메타데이터와 속성을 BigQuery의 개별 테이블 필드로 추출하려면 아래 샘플 DDL 쿼리를 사용하면 됩니다. 이러한 추출된 필드는 데이터 스튜디오 또는 BI 대시보드 도구에서 데이터를 시각화하는 데 사용할 수도 있습니다.
document_json에서 키 필드 추출
이 쿼리는 문서 메타데이터 (document_json 필드에 저장됨)의 키 필드를 포함하여 데이터 내보내기에서 관련 필드를 선택합니다.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
document_json에서 속성 언네스팅
이 쿼리는 문서 메타데이터 (document_json)에서 속성을 언네스팅하여 키-값 쌍 (속성 이름, 값)을 만듭니다. 이러한 키-값 쌍은 다음 쿼리에서 개별 테이블 필드로 변환되어 속성 수준 데이터 탐색 및 대시보드 시각화를 지원합니다.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
document_json에서 속성을 피벗하여 BigQuery에서 테이블 필드 만들기
다음 절차에서는 속성과 연결된 값을 피벗하여 모든 문서 속성이 개별 테이블 필드로 변환된 테이블을 만듭니다. 이 테이블의 결과를 활용하여 데이터 스튜디오 및 기타 BI 시각화 도구의 후속 쿼리를 통해 추가 통계를 도출할 수 있습니다.
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
데이터 정리 및 변환 절차 (비즈니스 사례별)
BigQuery로 수집된 데이터에 따라 추가 분석을 사용 설정하기 위해 추가 데이터 정리 및 변환 절차를 실행해야 할 수 있습니다. 이러한 절차는 사례마다 (데이터 세트마다) 다르며 적절하게 실행해야 합니다.
데이터 정리 절차의 몇 가지 예는 다음과 같습니다 (이에 국한되지 않음).
- 날짜 형식 통합
- 속성 값 통합
- 예를 들어 데이터 유형을 문자열, 부동 소수점, 정수로 캐스팅
데이터 스튜디오에서 데이터 시각화
BigQuery에서 데이터를 추출, 정리, 변환한 후 최종 데이터 세트를 데이터 스튜디오로 내보내 시각적 분석을 실행할 수 있습니다.
Looker 대시보드
설명된 샘플 대시보드는 데이터 세트에서 만들 수 있는 시각화를 보여줍니다. 이 시나리오에서 Document AI Warehouse의 샘플 데이터 내보내기는 W2 및 인보이스 (두 가지 스키마)로 구성됩니다.
샘플 뷰: Document AI Warehouse 분석 개요
다음 대시보드는 Document AI Warehouse 인스턴스로 수집된 다양한 문서에 대한 대략적인 통계를 제공합니다.
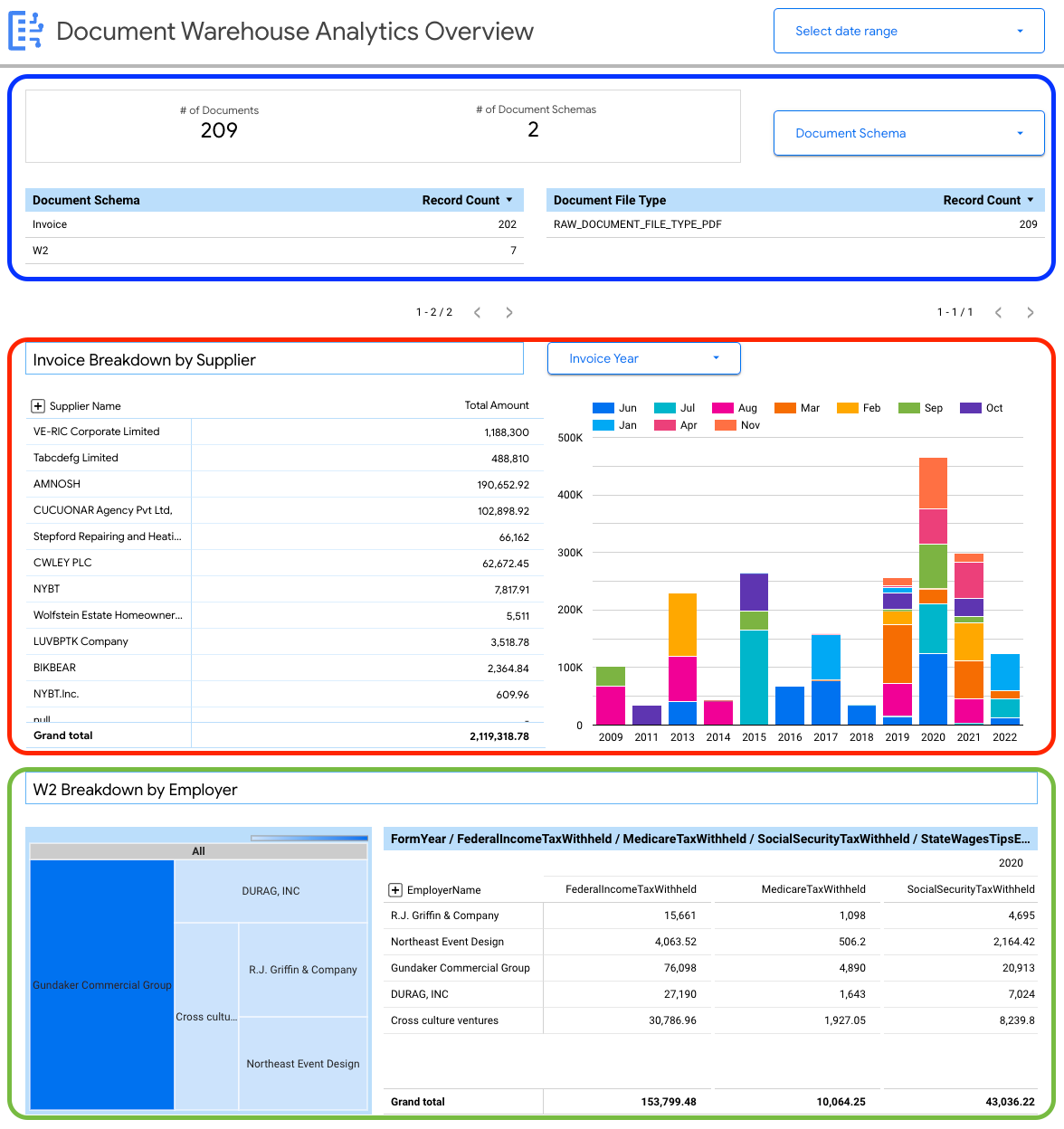
다음과 같은 문서 수준 세부정보를 볼 수 있습니다.
- 총 문서 수
- 총 문서 스키마 수
- 문서 스키마별 레코드 수
- 문서 파일 형식 (예: PDF, 텍스트, 지정되지 않은 유형)
문서 메타데이터(document_json)에서 추출한 속성을 사용하여 BigQuery로 수집된 인보이스 및 W2의 주요 분석을 빌드할 수도 있습니다.
샘플 뷰: 비즈니스별 통계 대시보드 (인보이스)
다음 대시보드는 사용자에게 단일 문서 스키마 (인보이스)에 대한 자세한 정보를 제공하여 Document AI Warehouse로 수집된 모든 인보이스에 대한 통계를 제공합니다.
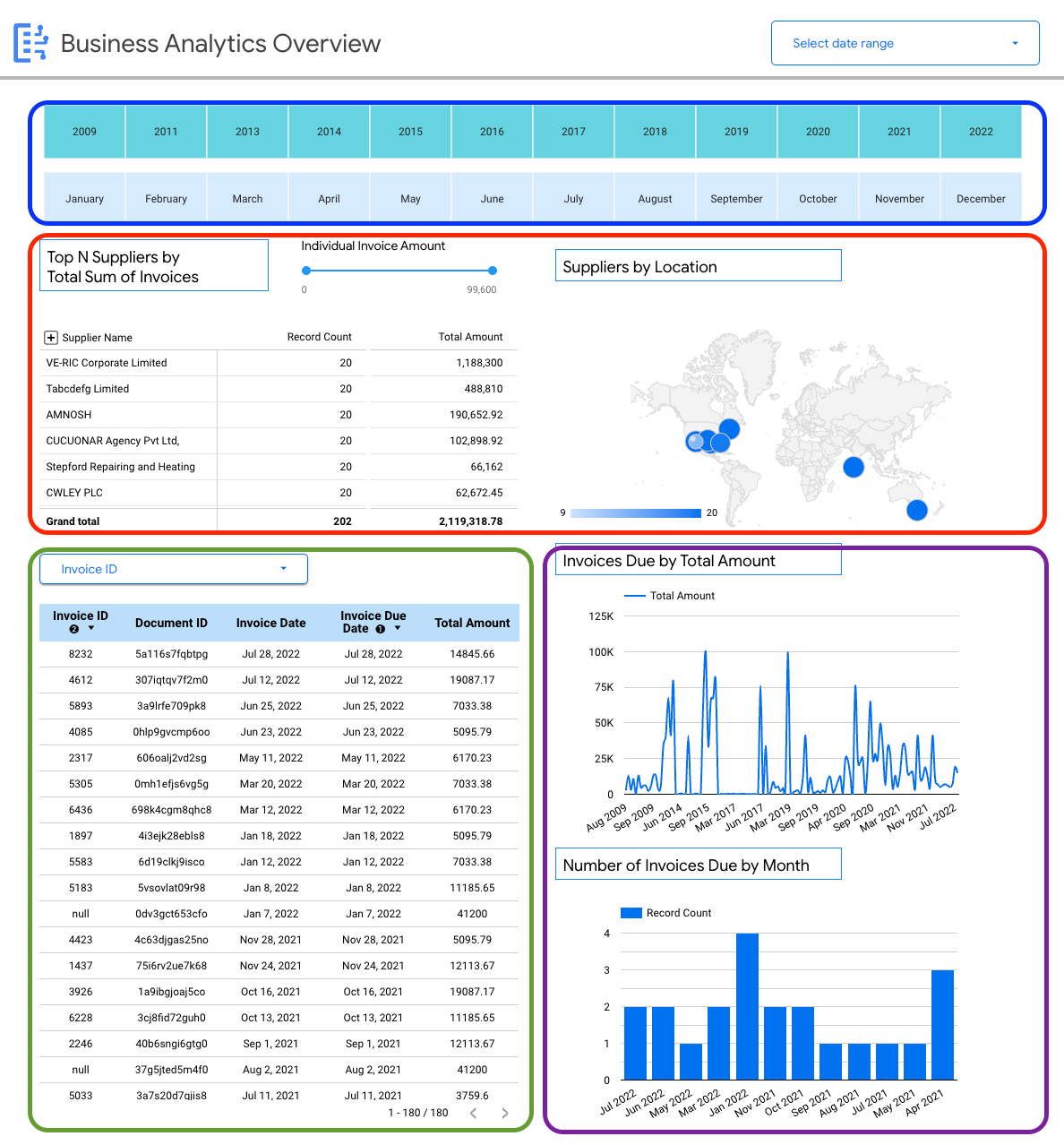
예를 들어 인보이스에 대한 스키마별 세부정보를 볼 수 있습니다.
- 인보이스 금액 기준 상위 공급업체
- 위치별 공급업체
- 인보이스 날짜 및 해당 기한
- 금액 및 레코드 수 기준 월별 인보이스 추세
대시보드에 데이터 소스 연결
이러한 대시보드 샘플 을 데이터 세트를 시각화하는 시작점으로 사용하려면 BigQuery에서 데이터 소스를 연결하면 됩니다.
샘플 대시보드를 BigQuery 데이터 소스에 연결하기 전에, 환경과 연결된 계정에 로그인했는지 확인하세요. Google Cloud

강조 표시된 버튼을 선택하여 드롭다운 옵션을 표시합니다.

사본 만들기 를 선택합니다.
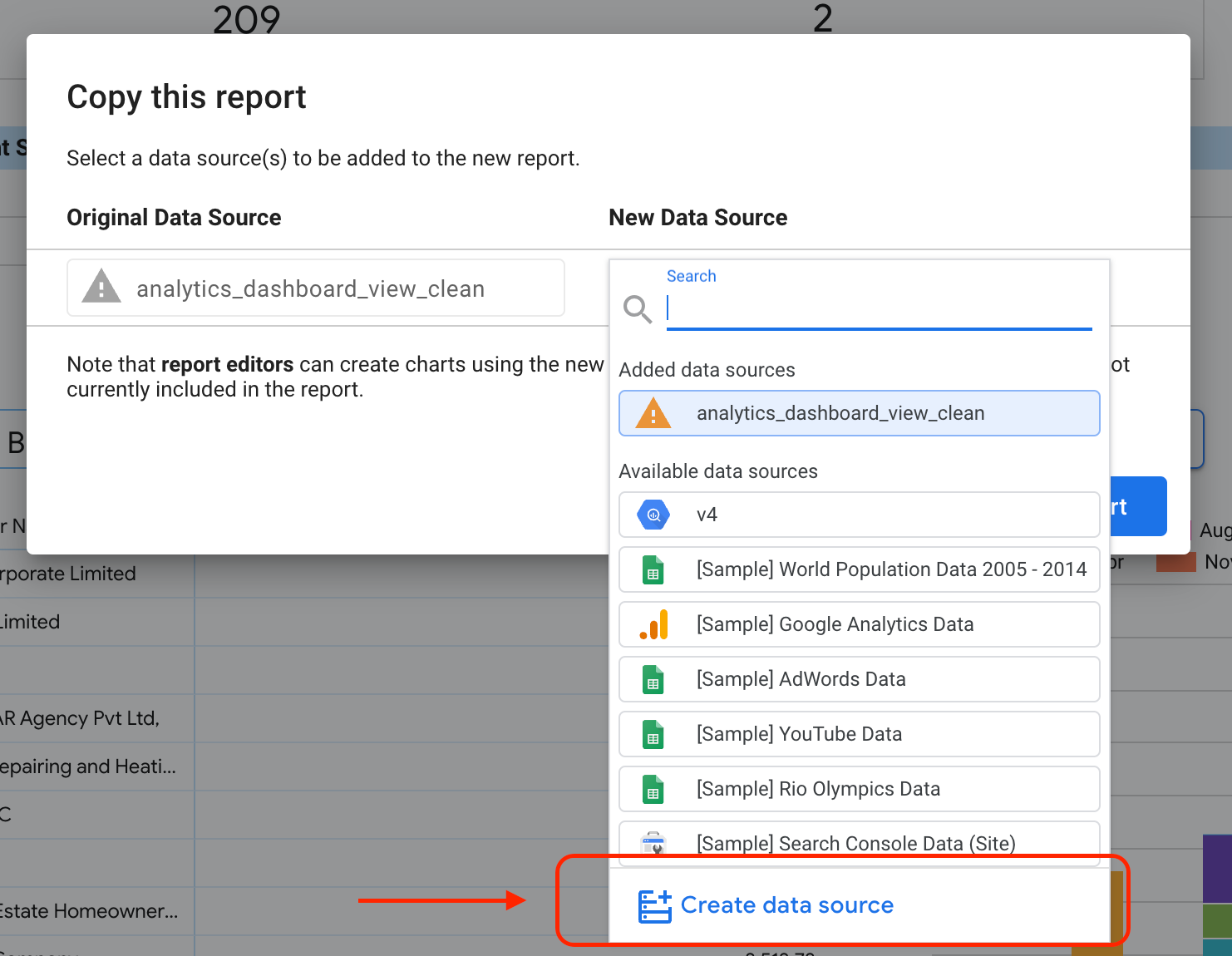
새 데이터 소스 하위 섹션에서 데이터 소스 만들기 를 선택합니다.
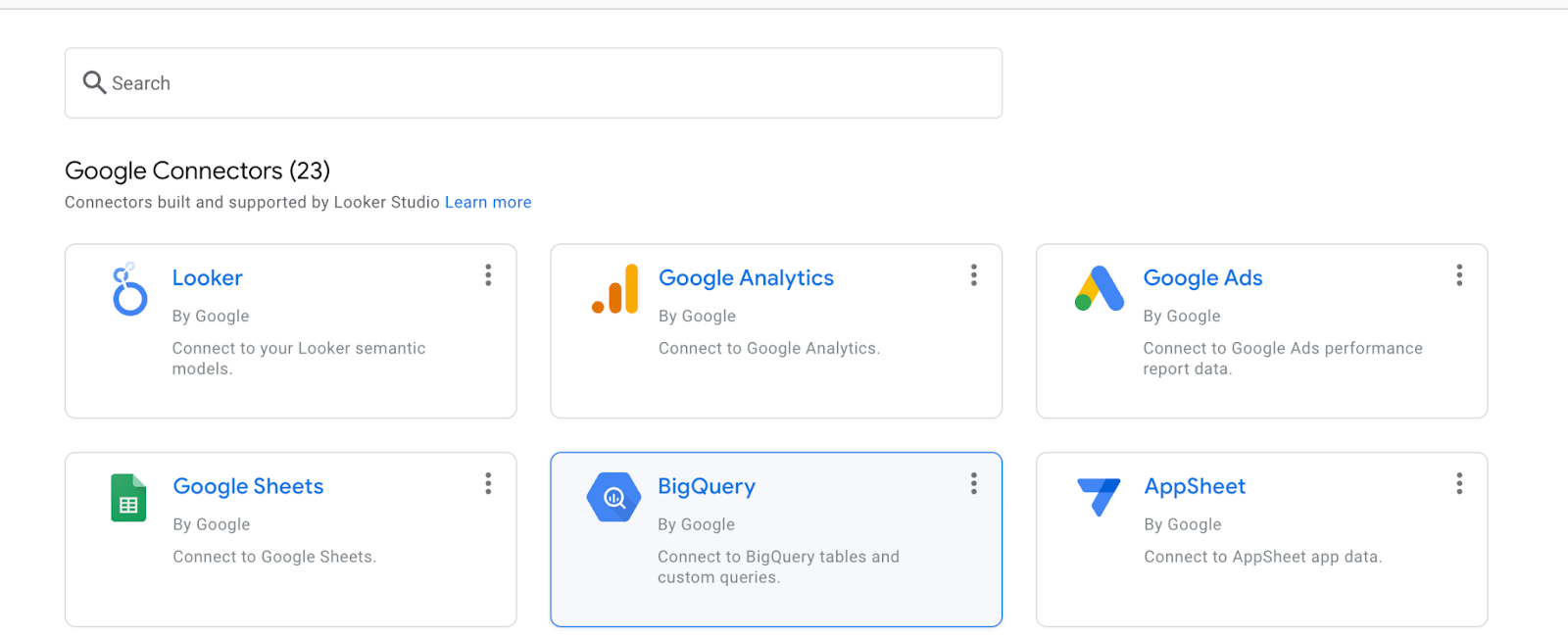
BigQuery 를 선택합니다.
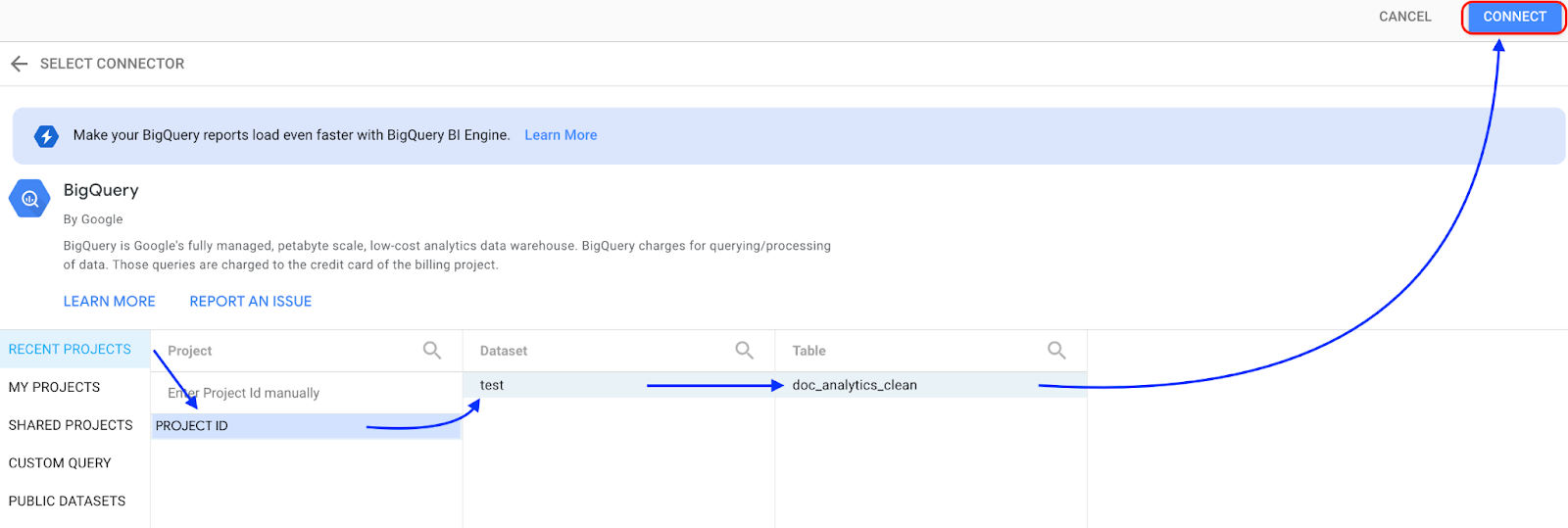
데이터 세트가 저장된 프로젝트를 선택한 후 메시지에 따라 데이터 세트와 테이블을 선택합니다. 연결 을 클릭합니다.

보고서에 추가 를 클릭합니다.
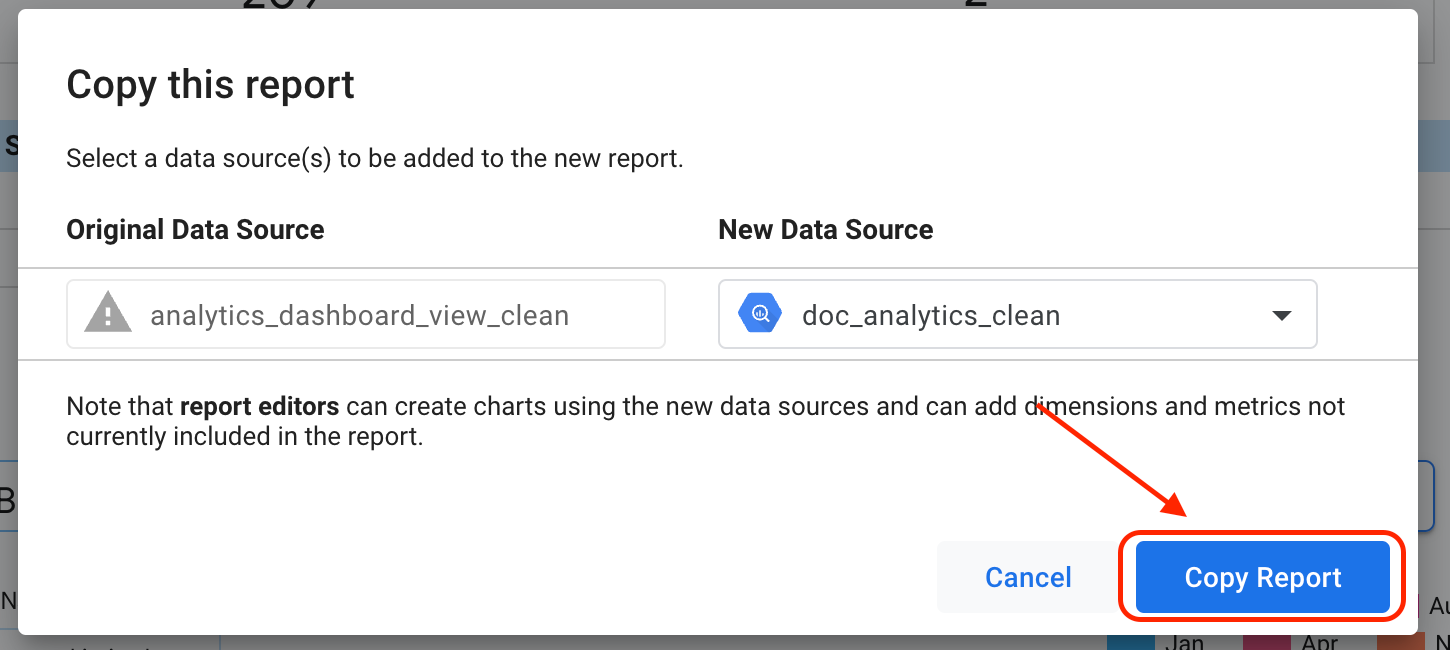
보고서 복사 를 클릭합니다.
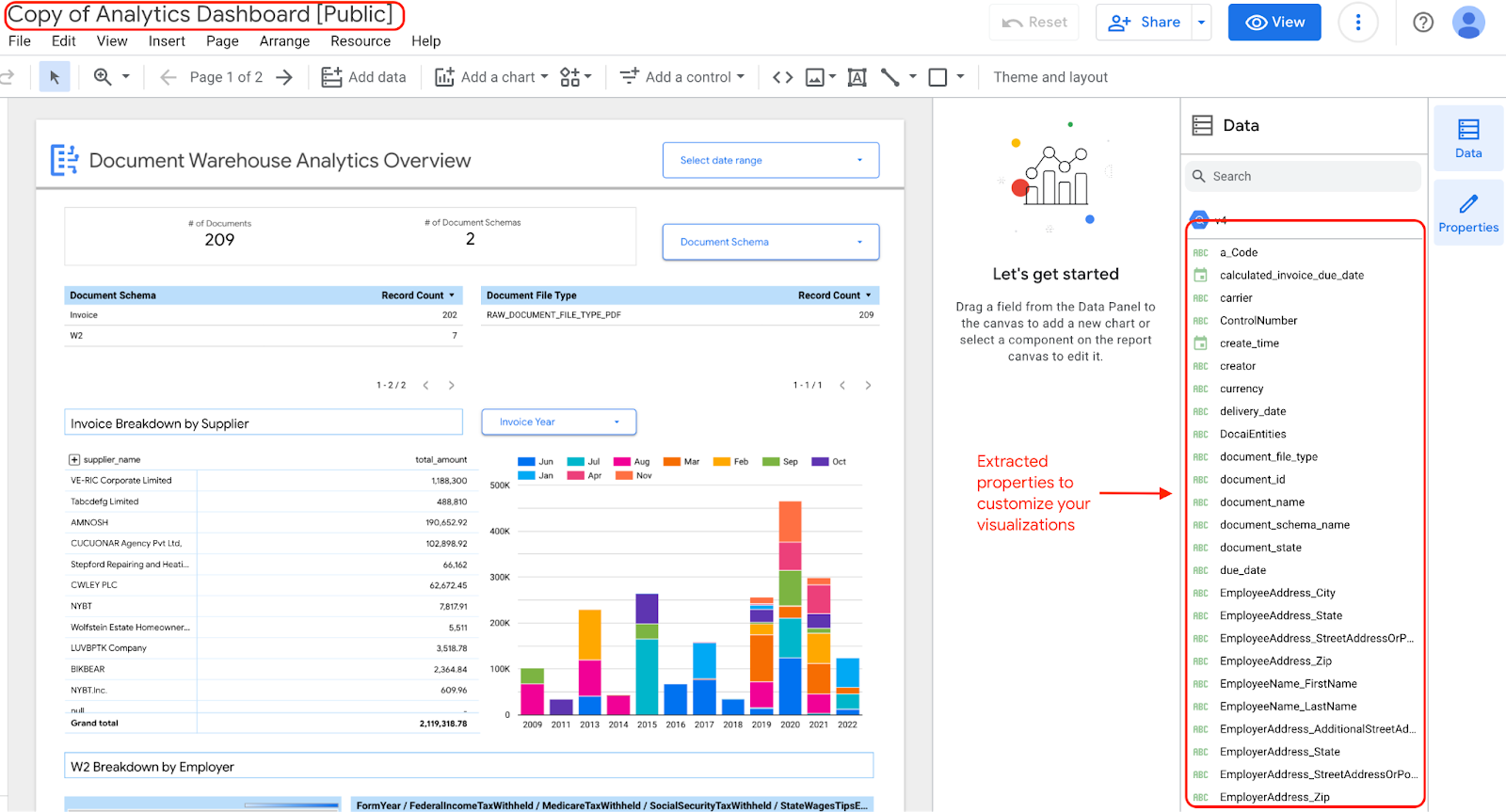
대시보드의 위젯을 수정하고 업데이트하도록 선택하면 추출된 속성이 포함된 대시보드 사본이 있으므로 수정할 수 있습니다.