
Introduzione al connettore BigQuery
Il connettore BigQuery ti aiuta a esportare i metadati del documento (incluse le proprietà) archiviati in Document AI Warehouse nella tua BigQuery. Con i dati in BigQuery, puoi eseguire analisi, creare report e dashboard per prendere decisioni aziendali.
Per abilitare il connettore BigQuery, devi configurare una tabella BigQuery con le autorizzazioni necessarie e configurare le attività asincrone tramite l'API. Il connettore BigQuery esporta i dati da Document AI Warehouse alle tabelle BigQuery.
Prima di iniziare
Configura Document AI Warehouse e importa i documenti. Per ulteriori informazioni, segui la guida rapida.
Devi assicurarti che il progetto che ospita la tabella BigQuery sia lo stesso progetto utilizzato da Document AI Warehouse per archiviare i documenti. In altre parole, i dati devono sempre essere esportati da Document AI Warehouse alla tabella BigQuery nello stesso progetto.
Nel progetto devi avere il ruolo di Owner (roles/owner) oppure le autorizzazioni resourcemanager.projects.getIamPolicy e resourcemanager.projects.setIamPolicy.
autorizzazioni aggiuntive.
Configurare l'accesso a BigQuery
Associa l'account di servizio doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
al ruolo BigQuery Admin:
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
Configurare il set di dati e la tabella BigQuery
Configura un set di dati e una tabella BigQuery per Document AI Warehouse per esportare i dati. Se non hai un set di dati BigQuery, segui la procedura per creare i set di dati.
Crea una tabella BigQuery nel set di dati BigQuery. Seguendo le istruzioni di BigQuery , puoi creare tabelle con le istruzioni DDL di esempio:
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
DDL crea una nuova tabella BigQuery. La tabella è partizionata in base all'ora e la partizione viene eliminata dopo 150 giorni.
Configurare il connettore BigQuery
Creare la configurazione di esportazione dei dati
Le seguenti istruzioni creano un nuovo job di esportazione dei dati, che configura i job asincroni per esportare i dati. Ti consigliamo di iniziare con una tabella vuota per ogni nuovo job di esportazione dei dati. Per i dettagli della configurazione, consulta il riferimento API.
Sono disponibili le seguenti opzioni di esecuzione. Possono essere configurate utilizzando FREQUENCY.
Consulta il riferimento API.
- ADHOC:il job viene eseguito una sola volta. Tutti i dati vengono esportati nella tabella BigQuery.
- DAILY:il job viene eseguito ogni giorno. Alla prima esecuzione, tutti i dati vengono esportati nella tabella BigQuery. Al termine dell'esportazione iniziale, nella tabella BigQuery vengono esportate solo le modifiche dei dati del giorno precedente (o il delta dall'ultima sincronizzazione riuscita).
- HOURLY:il job viene eseguito ogni ora. Alla prima esecuzione, tutti i dati vengono esportati nella tabella BigQuery. Al termine dell'esportazione iniziale, nella tabella BigQuery vengono esportate solo le modifiche dei dati dell'ora precedente (o il delta dall'ultima sincronizzazione riuscita).
Prima di utilizzare i dati della richiesta, apporta le sostituzioni seguenti:
- PROJECT_NUMBER: il Google Cloud numero del progetto
- LOCATION: la località di Document AI Warehouse (ad esempio `us`)
- DATASET_LOCATION: la località del set di dati
- DATASET_NAME: il nome del set di dati
- TABLE_NAME: il nome della tabella
-
FREQUENCY: uno tra
ADHOC,DAILYoHOURLY.
Corpo JSON della richiesta:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
Esecuzione del job
Una volta creato correttamente un job, questo viene eseguito in base alla configurazione. Tieni presente che i job vengono eseguiti in modo asincrono perché l'esecuzione richiede tempo. A seconda della quantità di dati da esportare, la prima esecuzione può richiedere tempo per essere completata. Per il job giornaliero, attendi 24 ore prima che i risultati vengano visualizzati nella tabella BigQuery.
Eliminare la configurazione di esportazione dei dati
Il seguente comando elimina (archiviando) un job che hai creato.
Prima di utilizzare i dati della richiesta, apporta le sostituzioni seguenti:
- PROJECT_NUMBER: il Google Cloud numero del progetto
- LOCATION: la località di Document AI Warehouse (ad esempio `us`)
- JOB_ID: l'ID del job, nella risposta quando l'hai creato
Corpo JSON della richiesta:
{}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
A questo punto, il job di esportazione viene eliminato (archiviato) e Document AI Warehouse non lo esegue più.
Esplorare i dati importati in BigQuery
Per estrarre i metadati e le proprietà dei documenti in campi di tabella distinti in BigQuery per le tue esigenze di analisi, puoi utilizzare le query DDL di esempio riportate di seguito. Questi campi estratti possono essere utilizzati anche in Data Studio o in qualsiasi strumento di dashboard di BI per visualizzare le relazioni all'interno dei dati.
Estrarre i campi chiave da document_json
Questa query seleziona i campi pertinenti dall'esportazione dei dati, inclusi i campi chiave dei metadati dei documenti (archiviati nel campo document_json).
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
Annullare l'annidamento delle proprietà da document_json
Questa query annulla l'annidamento delle proprietà dai metadati del documento (document_json) per creare coppie chiave-valore (nome proprietà, valore). Queste coppie chiave-valore verranno trasformate in singoli campi di tabella nella query successiva per consentire l'esplorazione dei dati a livello di proprietà e la visualizzazione della dashboard.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
Pivot delle proprietà da document_json per creare campi di tabella in BigQuery
Le seguenti procedure creano una tabella con tutte le proprietà del documento trasformate in singoli campi di tabella mediante il pivot delle proprietà e dei valori associati. I risultati di questa tabella possono essere utilizzati per ricavare ulteriori approfondimenti tramite query successive in Data Studio e in altri strumenti di visualizzazione di BI.
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
Procedure di pulizia e trasformazione dei dati (specifiche per il caso d'uso aziendale)
A seconda dei dati importati in BigQuery, potrebbe essere necessario eseguire ulteriori procedure di pulizia e trasformazione dei dati per consentire ulteriori analisi. Queste procedure variano da caso a caso (da set di dati a set di dati) e devono essere eseguite in modo appropriato.
Ecco alcuni esempi di procedure di pulizia dei dati (a titolo esemplificativo):
- Unificare i formati della data.
- Consolidare i valori delle proprietà.
- Eseguire il cast dei tipi di dati in stringhe, numeri in virgola mobile e numeri interi, ad esempio.
Visualizzare i dati in Data Studio
Una volta estratti, puliti e trasformati i dati in BigQuery, il set di dati finale può essere esportato in Data Studio per l'analisi visiva.
Dashboard di Looker
Le dashboard di esempio descritte mostrano le possibili visualizzazioni che possono essere create dal set di dati. In questo scenario, l'esportazione di dati di esempio da Document AI Warehouse è costituita da W2 e fatture (due schemi).
Visualizzazione di esempio: panoramica dell'analisi di Document AI Warehouse
La seguente dashboard fornisce informazioni di alto livello sulla varietà di documenti importati nell'istanza di Document AI Warehouse.
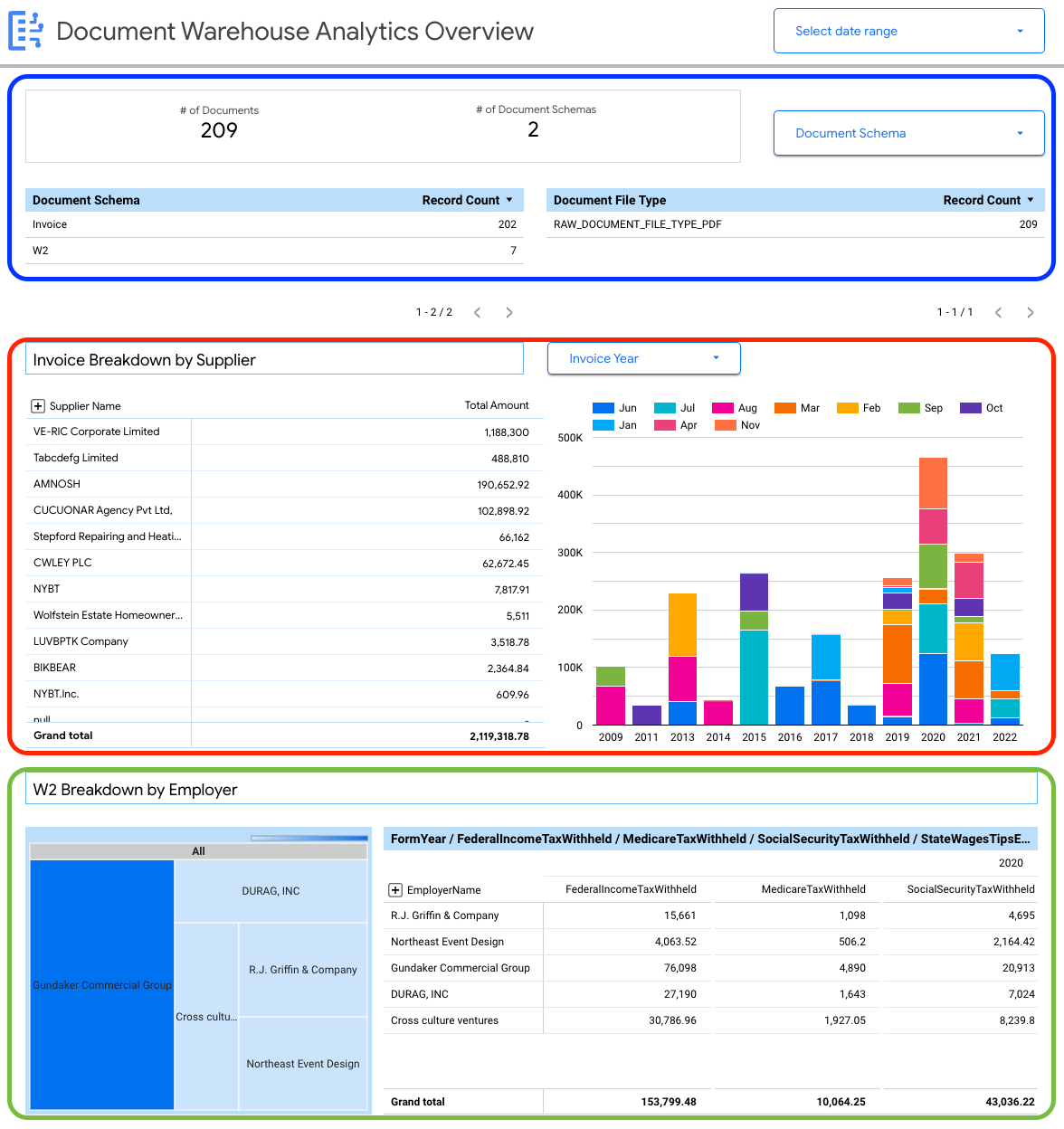
Puoi visualizzare i dettagli a livello di documento, tra cui:
- Numero totale di documenti.
- Numero totale di schemi di documenti.
- Conteggio dei record per schema di documento.
- Tipo di file del documento (ad esempio PDF, testo, tipo non specificato).
Puoi anche utilizzare le proprietà estratte dai metadati del documento (document_json) per creare suddivisioni chiave per le fatture e i W2 importati in BigQuery.
Visualizzazione di esempio: dashboard degli approfondimenti specifici per l'attività (fatture)
La seguente dashboard fornisce all'utente una visualizzazione dettagliata di un singolo schema di documento (fatture) per consentire di ottenere approfondimenti su tutte le fatture importate in Document AI Warehouse.
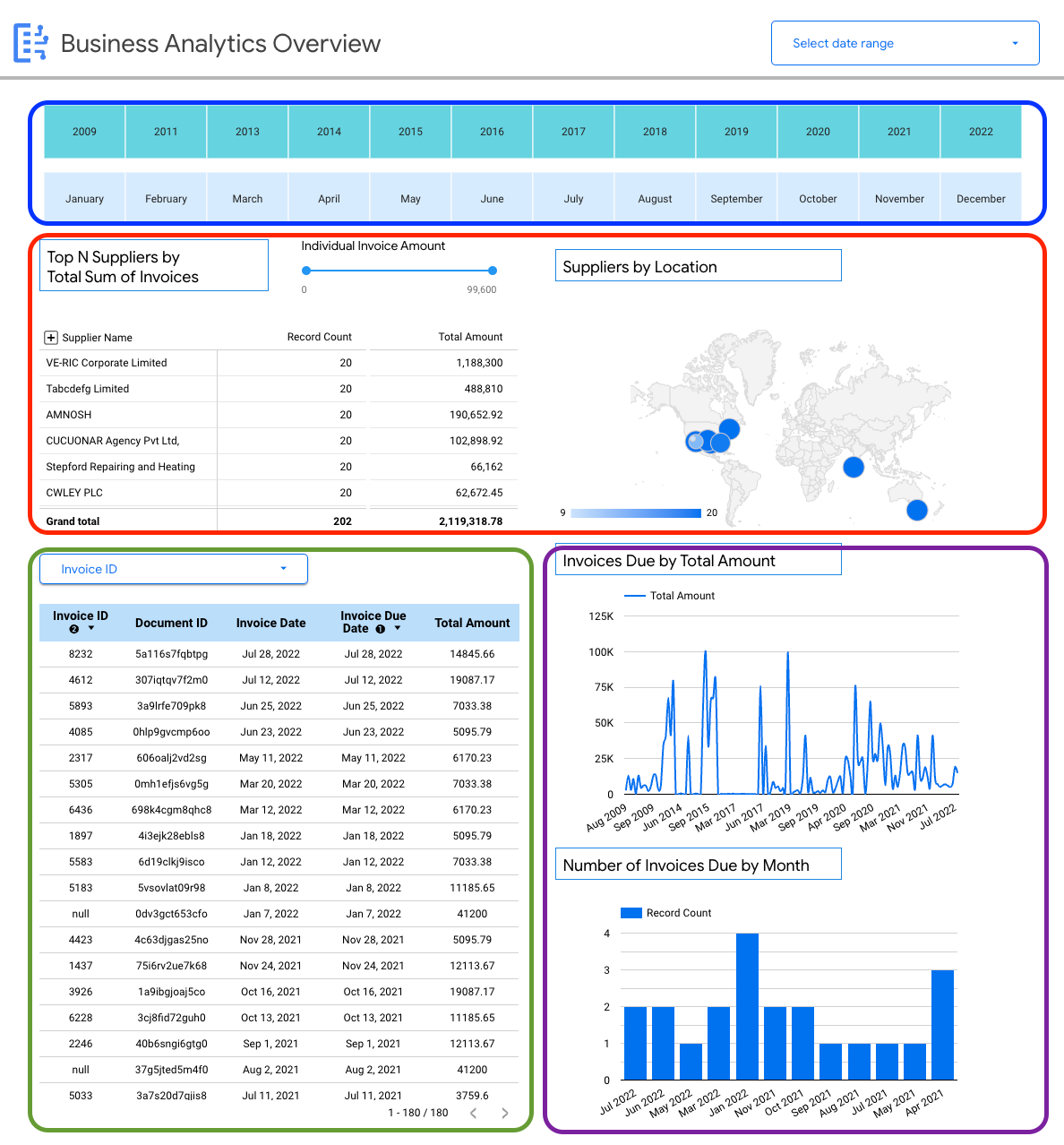
Puoi visualizzare i dettagli specifici dello schema delle fatture, ad esempio:
- Fornitori principali per importi delle fatture.
- Fornitori per località.
- Date delle fatture e relative date di scadenza.
- Tendenze delle fatture di mese in mese per importo e conteggio dei record.
Collegare l'origine dati alle dashboard
Per utilizzare questi esempi di dashboard come punto di partenza per visualizzare il set di dati, puoi collegare l'origine dati da BigQuery.
Prima di collegare le dashboard di esempio all'origine dati BigQuery, assicurati di aver eseguito l'accesso all'account associato al tuo Google Cloud ambiente.

Seleziona il pulsante evidenziato per visualizzare le opzioni del menu a discesa.

Seleziona Crea una copia.
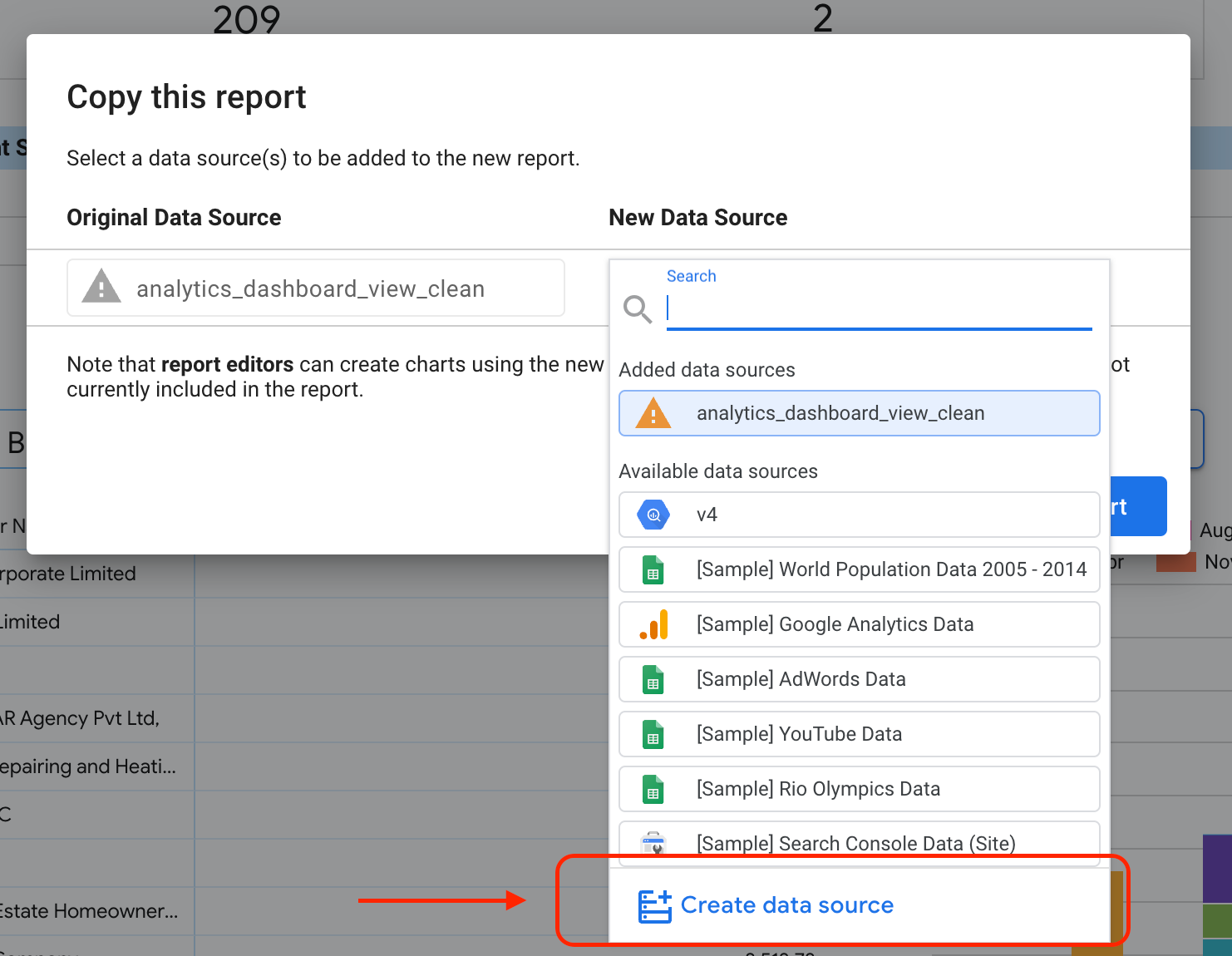
Nella sottosezione Nuova origine dati, seleziona Crea origine dati.
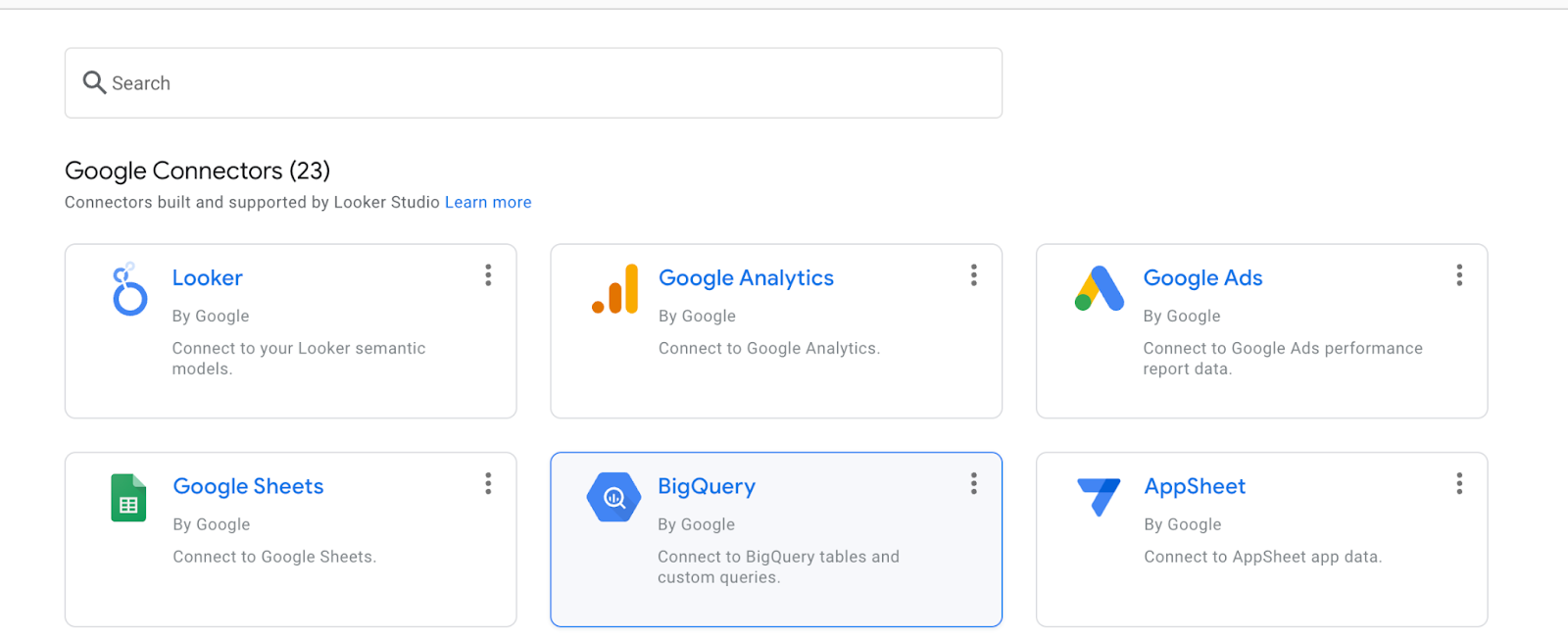
Seleziona BigQuery.
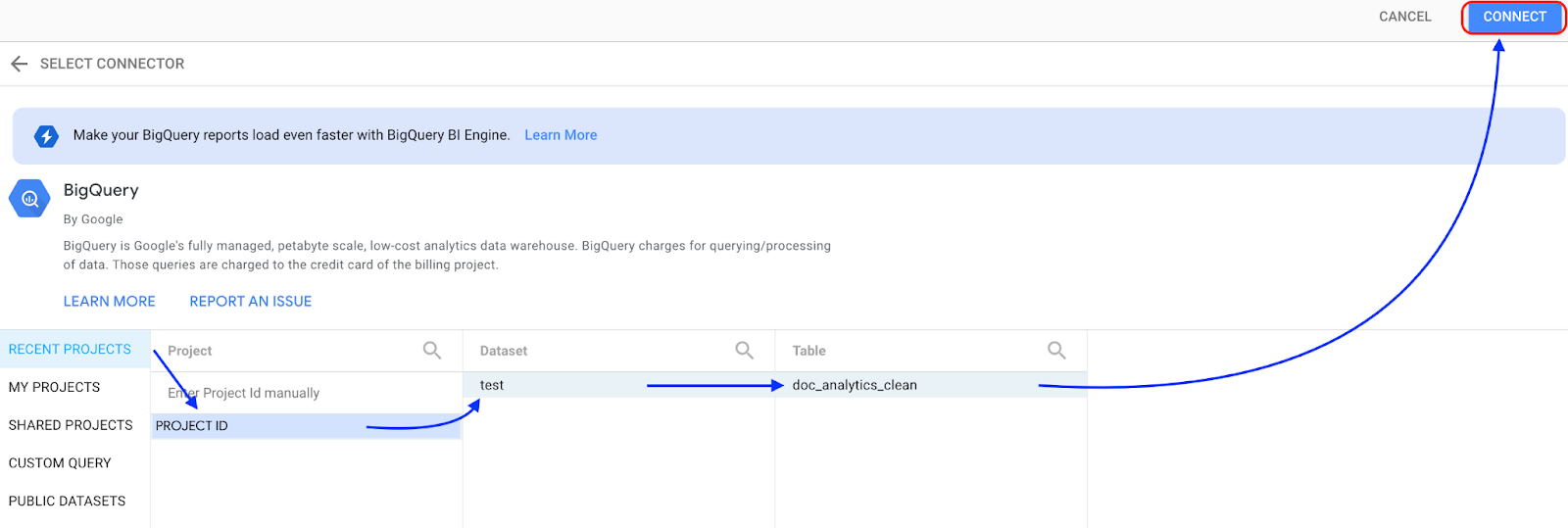
Seleziona il progetto in cui è archiviato il set di dati, quindi segui le istruzioni per selezionare il set di dati e la tabella. Fai clic su Connetti.

Fai clic su Aggiungi al report.
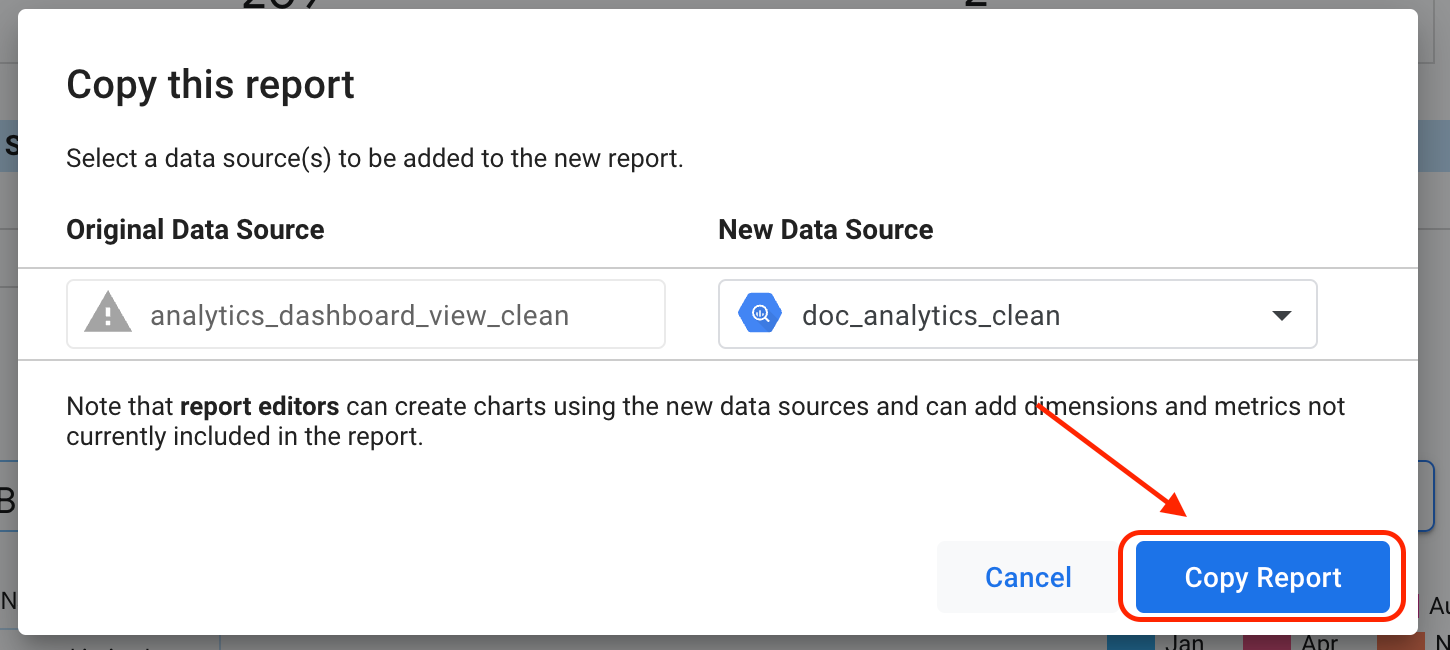
Fai clic su Copia report.
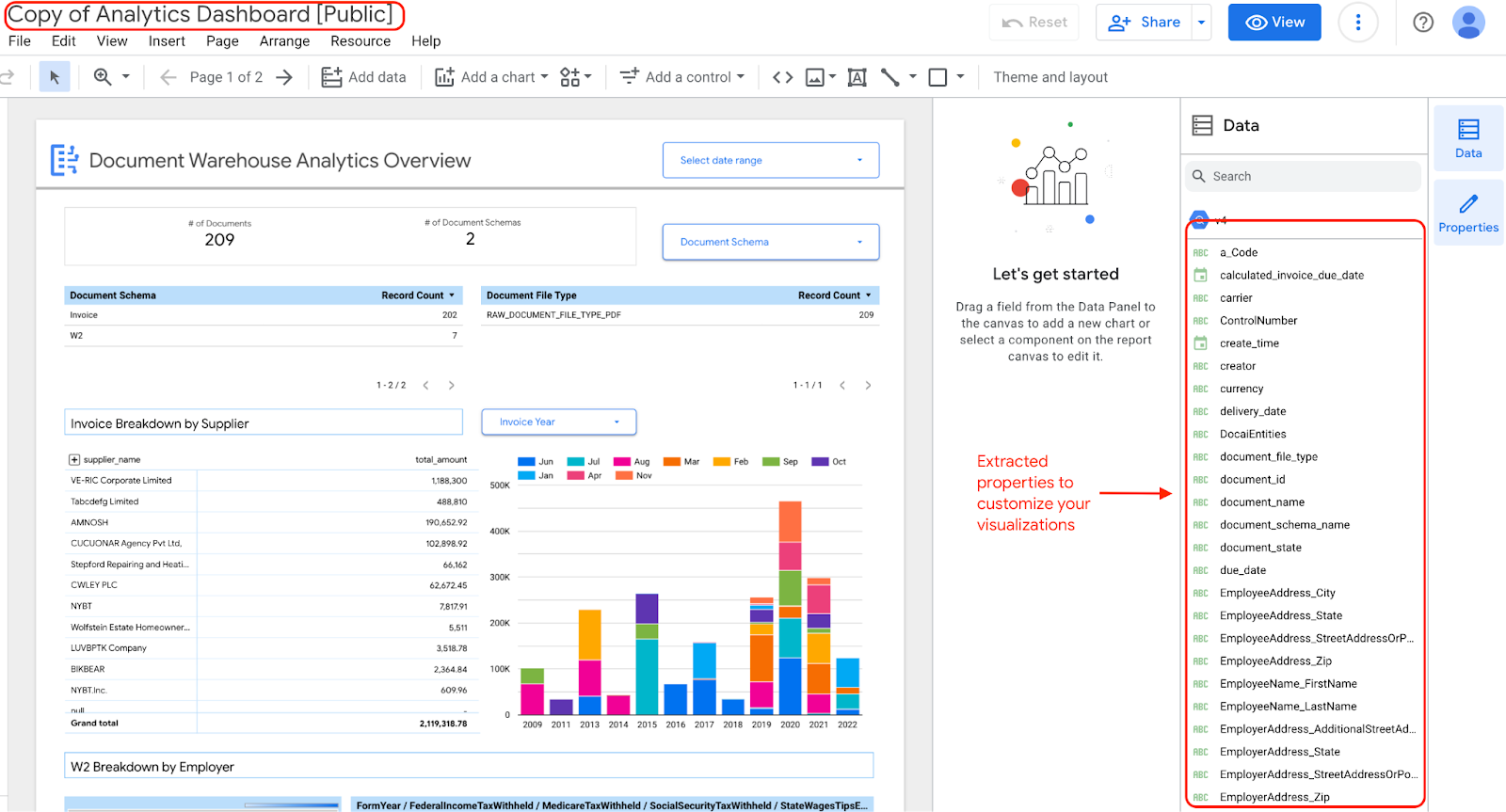
Se scegli di modificare e aggiornare i widget nella dashboard, puoi farlo perché hai una copia della dashboard con le proprietà estratte.