
מבוא למחבר BigQuery
המחבר של BigQuery עוזר לכם לייצא את המטא-נתונים של המסמך (כולל מאפיינים) שמאוחסנים ב-Document AI Warehouse לטבלה של BigQuery. אחרי שהנתונים שלכם יועברו ל-BigQuery, תוכלו להריץ ניתוחים, ליצור דוחות ומרכזי בקרה שיעזרו לכם לקבל החלטות עסקיות.
כדי להפעיל את מחבר BigQuery, צריך להגדיר טבלה ב-BigQuery עם ההרשאות הנדרשות, ולהגדיר את המשימות האסינכרוניות דרך ה-API. מחבר BigQuery מייצא את הנתונים מ-Document AI Warehouse לטבלאות BigQuery.
לפני שמתחילים
מגדירים את Document AI Warehouse ומטמיעים את המסמכים. מידע נוסף זמין במאמר מדריך למתחילים.
צריך לוודא שהפרויקט שמארח את הטבלה ב-BigQuery הוא אותו פרויקט שמשמש את Document AI Warehouse לאחסון המסמכים. במילים אחרות, הנתונים תמיד צריכים להיות מיוצאים מ-Document AI Warehouse לטבלה ב-BigQuery באותו פרויקט.
בפרויקט, צריך להיות לכם התפקיד Owner (roles/owner), או שצריכות להיות לכם ההרשאות resourcemanager.projects.getIamPolicy ו-resourcemanager.projects.setIamPolicy.
הרשאות.
הגדרת גישה ל-BigQuery
קישור חשבון השירות doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com
לתפקיד BigQuery Admin:
gcloud projects add-iam-policy-binding <var>PROJECT_ID</var> --member serviceAccount:doc-ai-warehouse-dw-bq-connector@system.gserviceaccount.com --role=roles/bigquery.admin
הגדרת מערך נתונים וטבלה ב-BigQuery
מגדירים מערך נתונים וטבלה ב-BigQuery כדי לייצא את הנתונים מ-Document AI Warehouse. אם אין לכם מערך נתונים ב-BigQuery, אתם צריכים ליצור אותו לפי ההוראות במאמר בנושא יצירת מערכי נתונים.
יוצרים טבלה ב-BigQuery במערך הנתונים של BigQuery. בהתאם להוראות של BigQuery, יוצרים טבלאות באמצעות הצהרות לדוגמה של DDL:
CREATE TABLE `PROJECT_ID.DATASET_NAME.TABLE_NAME`
(
project_number INT64,
location STRING,
mod_type STRING,
document_id STRING,
document_json JSON,
create_time TIMESTAMP,
creator STRING,
update_time TIMESTAMP,
updater STRING,
document_state STRING,
export_time TIMESTAMP
)
PARTITION BY TIMESTAMP_TRUNC(export_time, HOUR)
OPTIONS(
partition_expiration_days=150,
description="table partitioned by export_time on hour with expiry"
);
ה-DDL יוצר בשבילכם טבלה חדשה ב-BigQuery. הטבלה מחולקת למחיצות לפי שעה, והמחיצה נמחקת תוך 150 ימים.
הגדרת מחבר BigQuery
יצירת הגדרות לייצוא נתונים
ההוראות הבאות מתייחסות ליצירת משימה חדשה של ייצוא נתונים, שמגדירה את המשימות האסינכרוניות לייצוא נתונים. מומלץ להתחיל עם טבלה ריקה לכל משימה חדשה של ייצוא נתונים. לפרטים על ההגדרה, אפשר לעיין בהפניה ל-API.
אלה האפשרויות להפעלת התהליך. אפשר להגדיר אותם באמצעות FREQUENCY.
מידע נוסף על הפניית ה-API
- ADHOC: העבודה מורצת רק פעם אחת. כל הנתונים מיוצאים לטבלה ב-BigQuery.
- DAILY: העבודה מופעלת מדי יום. בהרצה הראשונה, כל הנתונים מיוצאים לטבלה ב-BigQuery. אחרי שהייצוא הראשוני מסתיים, רק השינויים בנתונים מהיום הקודם (או הדלתא מהסנכרון האחרון שהצליח) מיוצאים לטבלה ב-BigQuery.
- HOURLY: העבודה מופעלת מדי שעה. בהרצה הראשונה, כל הנתונים מיוצאים לטבלה ב-BigQuery. אחרי שהייצוא הראשוני מסתיים, רק שינויים בנתונים מהשעה הקודמת (או הדלתא מהסנכרון האחרון שהצליח) מיוצאים לטבלה ב-BigQuery.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT_NUMBER: מספר הפרויקט ב- Google Cloud
- LOCATION: המיקום של Document AI Warehouse (למשל, us)
- DATASET_LOCATION: המיקום של מערך הנתונים
- DATASET_NAME: שם מערך הנתונים
- TABLE_NAME: שם הטבלה
-
FREQUENCY: אחד מהערכים
ADHOC, DAILYאוHOURLY.
תוכן בקשת JSON:
{
"projectNumber": PROJECT_NUMBER,
"location": "DATASET_LOCATION",
"dataset": "DATASET_NAME",
"table": "TABLE_NAME",
"frequency": "FREQUENCY",
"state": "ACTIVE"
}
כדי לשלוח את הבקשה צריך להרחיב אחת מהאפשרויות הבאות:
אתם אמורים לקבל תגובת JSON שדומה לזו:
ביצוע של משימה
אחרי שיוצרים את העבודה, היא מופעלת בהתאם להגדרות. שימו לב שהעבודות מופעלות באופן אסינכרוני כי לוקח זמן להפעיל אותן. הריצה הראשונה יכולה להימשך זמן מה, בהתאם לכמות הנתונים שמייצאים. אם מריצים את העבודה מדי יום, צריך להמתין 24 שעות עד שהתוצאות יופיעו בטבלה ב-BigQuery.
מחיקת ההגדרות האישיות של ייצוא הנתונים
הפקודה הבאה מוחקת (על ידי העברה לארכיון) משימה שיצרתם.
לפני שמשתמשים בנתוני הבקשה, צריך להחליף את הנתונים הבאים:
- PROJECT_NUMBER: מספר הפרויקט ב- Google Cloud
- LOCATION: המיקום של Document AI Warehouse (למשל, us)
- JOB_ID: מזהה המשימה, בתגובה שקיבלתם כשנוצרה המשימה
תוכן בקשת JSON:
{}
כדי לשלוח את הבקשה צריך להרחיב אחת מהאפשרויות הבאות:
אתם אמורים לקבל תגובת JSON שדומה לזו:
לאחר מכן, משימת הייצוא נמחקת (מועברת לארכיון) ו-Document AI Warehouse לא מריץ אותה יותר.
סקירת הנתונים שהועברו ל-BigQuery
כדי לחלץ מטא-נתונים ומאפיינים של מסמכים לשדות נפרדים בטבלה ב-BigQuery לצורך ניתוח, אפשר להשתמש בשאילתות DDL לדוגמה שבהמשך. אפשר גם להשתמש בשדות שחולצו ב-Data Studio או בכל כלי ללוח בקרה של BI כדי להציג את היחסים בתוך הנתונים.
חילוץ שדות מפתח מ-document_json
השאילתה הזו בוחרת שדות רלוונטיים מייצוא הנתונים, כולל שדות מפתח ממטא-נתונים של מסמכים (מאוחסנים בשדה document_json).
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_1`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_1` AS
SELECT
project_number,
document_id,
mod_type,
create_time,
update_time,
location,
creator,
updater,
document_state,
SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')[SAFE_OFFSET(ARRAY_LENGTH(SPLIT(JSON_EXTRACT_SCALAR(document_json,'$.documentSchemaName' ), '/')) - 1)] AS document_schema_name,
JSON_EXTRACT_SCALAR(document_json,'$.name') AS document_name,
JSON_EXTRACT_SCALAR(document_json,'$.rawDocumentFileType')
AS raw_document_file_type,
JSON_EXTRACT(document_json,'$.properties') AS properties
FROM
`DATASET_NAME.SYSTEM_METADATA_AND_DOC_PROPERTIES_TABLE_EXPORT_NAME`;
ביטול הקינון של מאפיינים מ-document_json
השאילתה הזו מבטלת את הקינון של מאפיינים ממטא-הנתונים של המסמך (document_json) כדי ליצור צמדים של מפתח וערך (שם המאפיין, ערך). צמדי מפתח/ערך האלה יומרו לשדות נפרדים בטבלה בשאילתה הבאה, כדי לאפשר ניתוח נתונים ברמת הנכס ותצוגה חזותית בלוח הבקרה.
DROP VIEW IF EXISTS
`DATASET_NAME.VIEW_NAME_2`;
CREATE VIEW
`DATASET_NAME.VIEW_NAME_2` AS
SELECT
* EXCEPT(key_value_pair,
properties,raw_document_file_type)
FROM (
SELECT
*,
REPLACE(JSON_VALUE(key_value_pair,'$.name'),'/','-') property_name,
-- Note: values are either text OR float values
CASE
WHEN JSON_VALUE(key_value_pair,'$.textValues.values[0]') IS NULL THEN JSON_VALUE(key_value_pair,'$.floatValues.values[0]')
ELSE
JSON_VALUE(key_value_pair,'$.textValues.values[0]')
END
AS value,
CASE
WHEN raw_document_file_type IS NULL THEN "RAW_DOCUMENT_FILE_TYPE_UNSPECIFIED"
ELSE
raw_document_file_type
END
AS document_file_type
FROM
`DATASET_NAME.VIEW_NAME_1`,
UNNEST(JSON_EXTRACT_ARRAY(properties)) AS key_value_pair);
שינוי ציר המאפיינים מ-document_json כדי ליצור שדות בטבלה ב-BigQuery
התהליכים הבאים יוצרים טבלה עם כל מאפייני המסמך שהומרו לשדות טבלה נפרדים על ידי ציר המאפיינים והערכים המשויכים. אפשר להשתמש בתוצאות של הטבלה הזו כדי להפיק תובנות נוספות באמצעות שאילתות עוקבות ב-Data Studio ובכלי הדמיה אחרים של BI.
DECLARE
property_field STRING;
-- Extracting distinct property_names from the previous view and storing it in property_field, declared above
EXECUTE IMMEDIATE
"""SELECT string_agg(CONCAT("'",property_name,"'")) from (select distinct property_name from DATASET.VIEW_NAME_2)""" INTO property_field;
DROP TABLE IF EXISTS `DATASET_NAME.ANALYTICS_TABLE_NAME`;
-- Creating pivot table with the aid of extracted distinct property_names
-- Casting numerical values to float/int
-- Pivot on property_name and value (ie. create a new column for each of the property_name, substitute the value)
EXECUTE IMMEDIATE
FORMAT ("""
CREATE TABLE `DATASET_NAME.ANALYTICS_TABLE_NAME` AS
SELECT * FROM `DATASET_NAME.VIEW_NAME_2`
PIVOT(min(value) FOR property_name IN (%s))""", property_field);
תהליכים לניקוי נתונים ולטרנספורמציה שלהם (ספציפי לתרחיש עסקי)
בהתאם לנתונים שמועברים ל-BigQuery, יכול להיות שתצטרכו לבצע פעולות נוספות של ניקוי ושינוי נתונים כדי לאפשר ניתוח נוסף. ההליכים האלה משתנים ממקרה למקרה (ממערך נתונים אחד למשנהו) וצריך לבצע אותם לפי הצורך.
דוגמאות לתהליכי ניקוי נתונים (זו רשימה חלקית):
- איחוד פורמטים של תאריכים.
- איחוד ערכי המאפיינים.
- לדוגמה, המרה של סוגי נתונים למחרוזות, למספרים עשרוניים ולמספרים שלמים.
המחשה ויזואלית של הנתונים ב-Data Studio
אחרי ששולפים את הנתונים, מנקים אותם ומשנים את הפורמט שלהם ב-BigQuery, אפשר לייצא את מערך הנתונים הסופי ל-Data Studio כדי לבצע ניתוח חזותי.
מרכזי בקרה ב-Looker
לוחות הבקרה לדוגמה שמתוארים כאן מציגים תצוגות חזותיות אפשריות שאפשר ליצור ממערך הנתונים שלכם. בתרחיש הזה, ייצוא נתוני הדוגמה מ-Document AI Warehouse כולל טפסי W2 וחשבוניות (שתי סכימות).
לוחות בקרה של Looker שגלויים לכולם
תצוגה לדוגמה: סקירה כללית של ניתוח נתונים ב-Document AI Warehouse
לוח הבקרה הבא מספק תובנות כלליות לגבי מגוון המסמכים שנקלטים במופע של Document AI Warehouse.
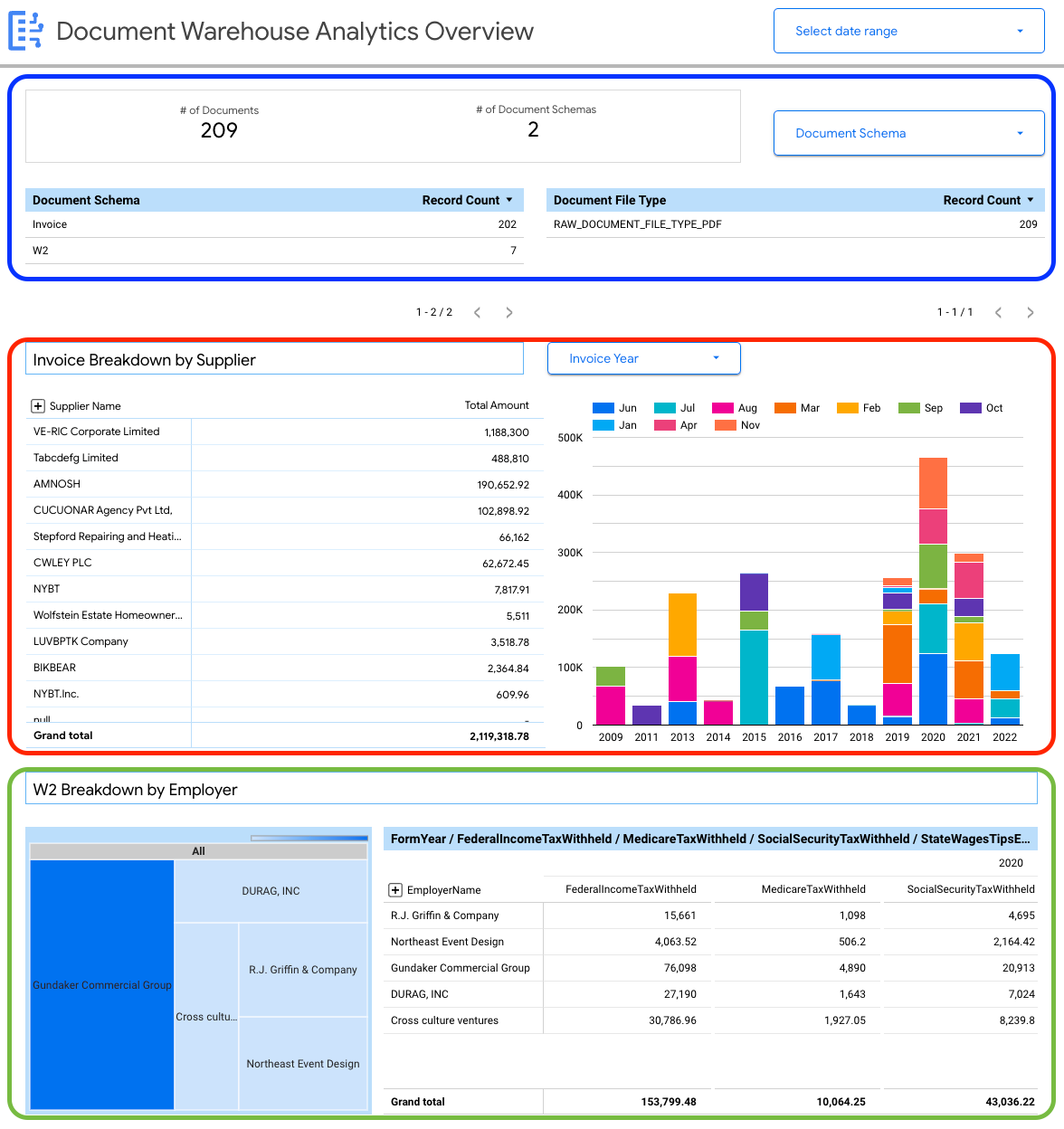
אתם יכולים לראות פרטים ברמת המסמך, כולל:
- המספר הכולל של המסמכים.
- המספר הכולל של סכימות המסמכים.
- מספר הרשומות לפי סכימת המסמך.
- סוג קובץ המסמך (למשל, PDF, טקסט, סוג לא מוגדר).
בנוסף, אתם יכולים להשתמש במאפיינים שחולצו ממטא-הנתונים של המסמך (document_json) כדי ליצור פירוטים של מפתחות עבור החשבוניות וטופסי W2 שהועלו ל-BigQuery.
תצוגה לדוגמה: מרכז בקרה עם תובנות ספציפיות לעסק (חשבוניות)
לוח הבקרה הבא מספק למשתמשים תצוגה מפורטת של סכימת מסמך יחידה (חשבוניות), כדי לאפשר תובנות לגבי כל החשבוניות שנקלטו ב-Document AI Warehouse.
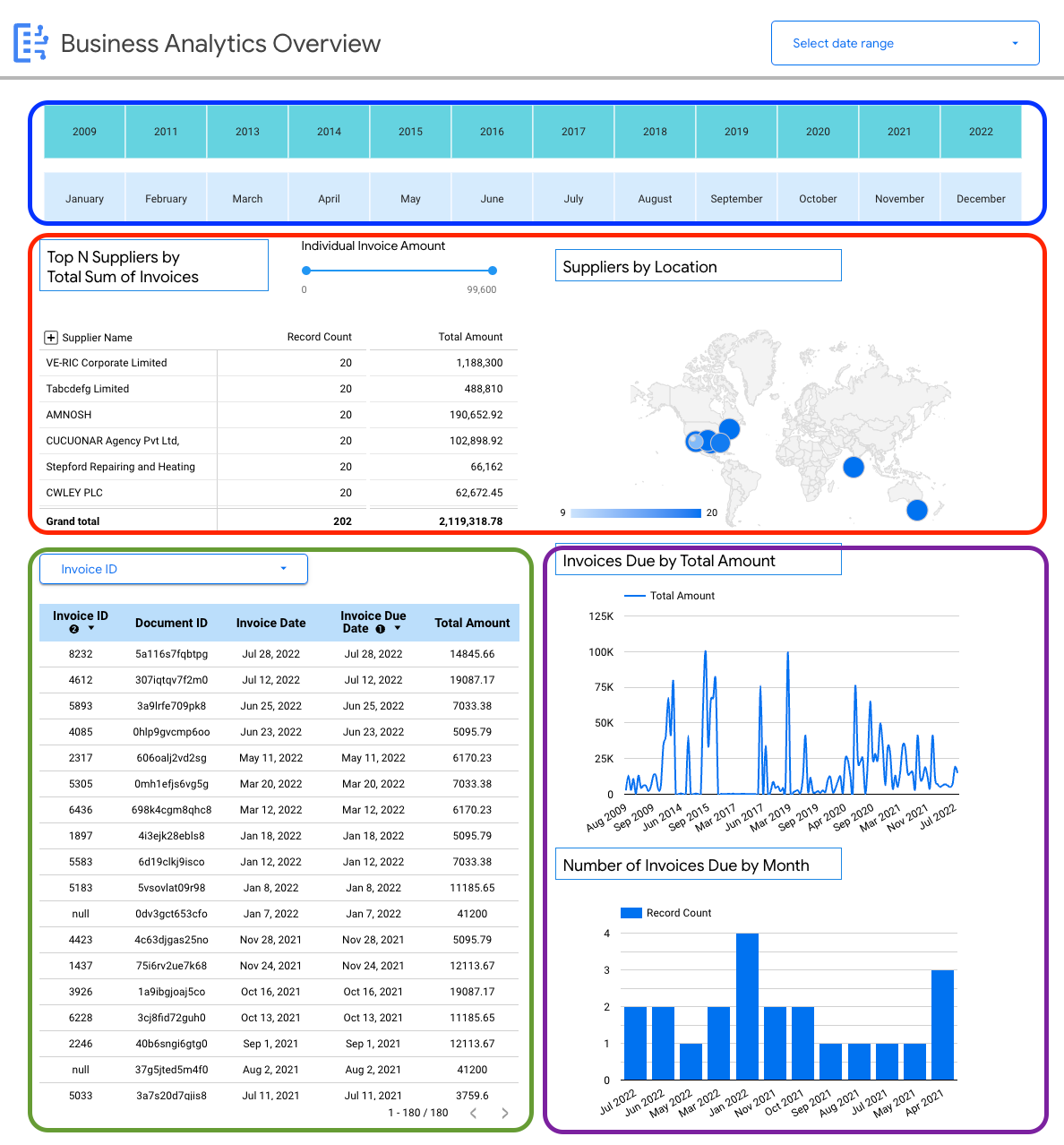
אתם יכולים לראות בחשבוניות פרטים ספציפיים לגבי סכימות, למשל:
- ספקים מובילים לפי סכומי חשבוניות.
- ספקים לפי מיקום.
- תאריכי החשבוניות והתאריכים האחרונים לתשלום שלהן.
- מגמות בחשבוניות מחודש לחודש לפי סכום ומספר רשומות.
קישור מקור נתונים ללוחות בקרה
כדי להשתמש בדוגמאות של מרכזי בקרה כנקודת התחלה להצגת מערך הנתונים שלכם, אתם יכולים לקשר את מקור הנתונים מ-BigQuery.
לפני שמקשרים את מרכזי הבקרה לדוגמה למקור הנתונים ב-BigQuery, צריך לוודא שאתם מחוברים לחשבון שמשויך לסביבת Google Cloud.

בוחרים את הלחצן המודגש כדי להציג את האפשרויות בתפריט הנפתח.

בוחרים באפשרות יצירת עותק.
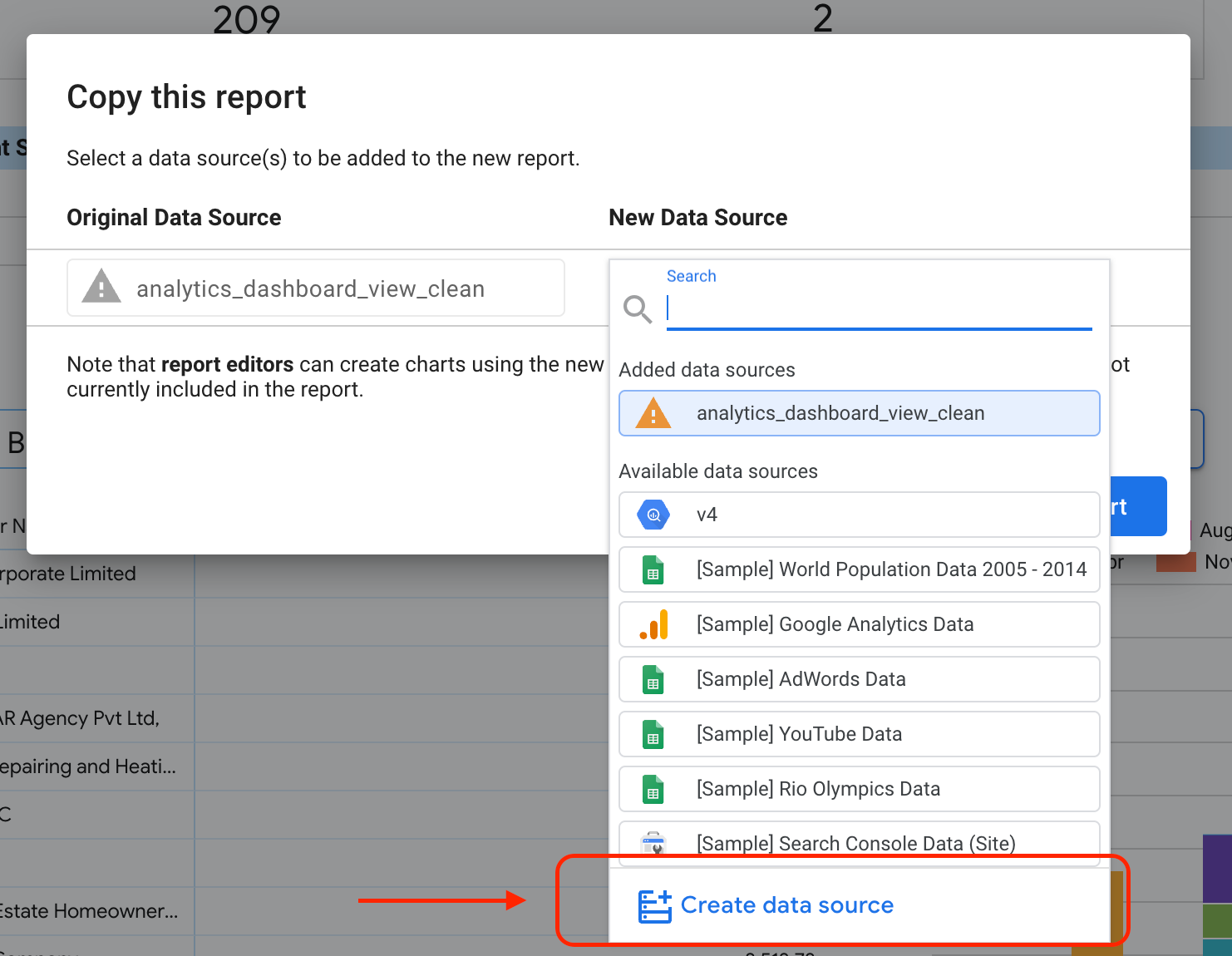
בקטע המשנה 'מקור נתונים חדש', בוחרים באפשרות יצירת מקור נתונים.
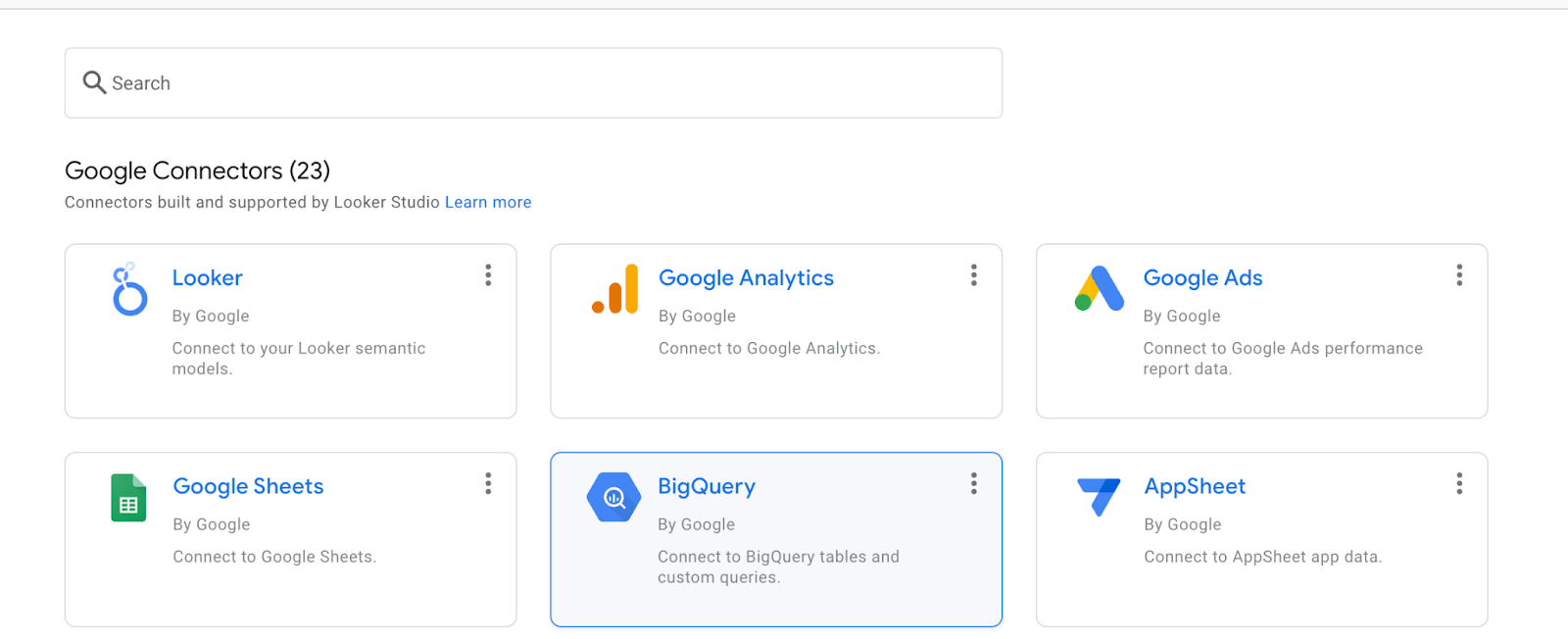
בוחרים באפשרות BigQuery.
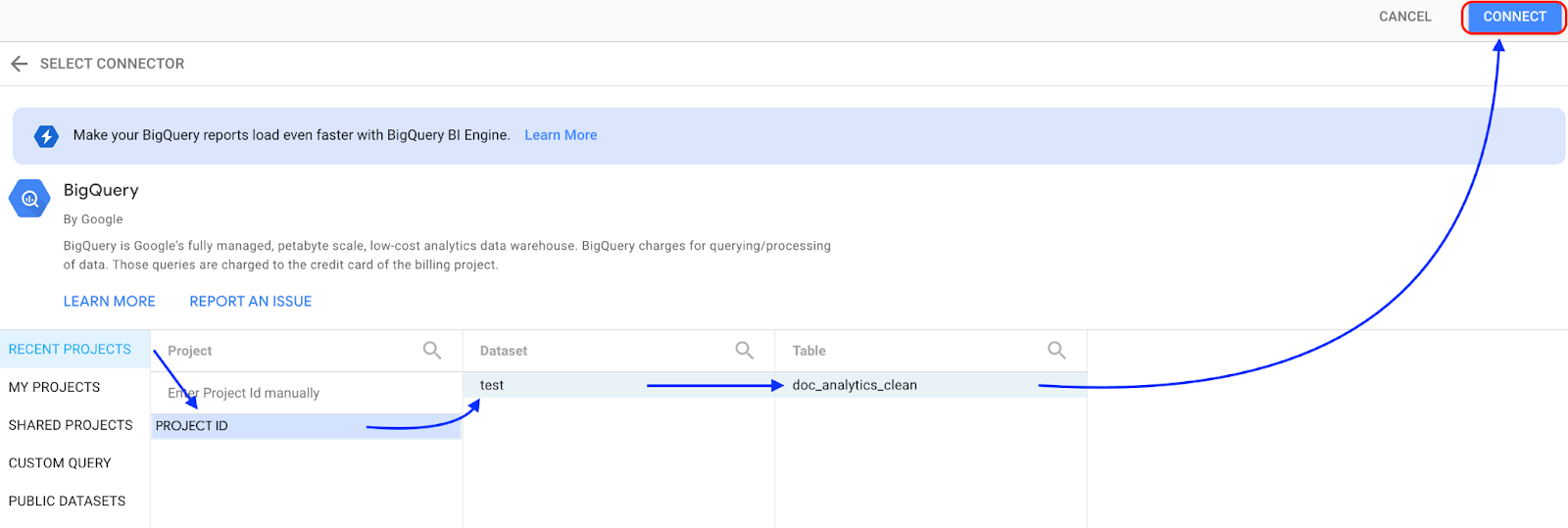
בוחרים את הפרויקט שבו מאוחסן מערך הנתונים ופועלים לפי ההנחיות כדי לבחור את מערך הנתונים והטבלה. לוחצים על Connect.

לוחצים על הוספה לדוח.
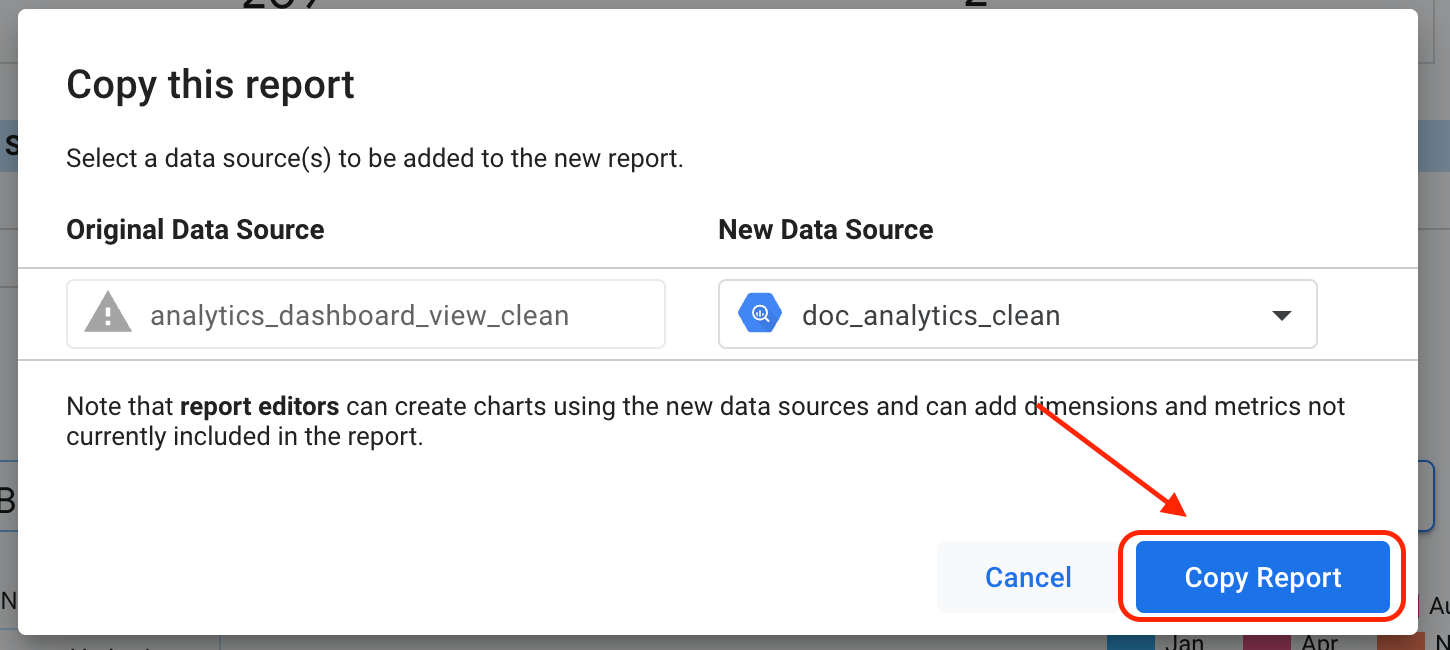
לוחצים על העתקת הדוח.
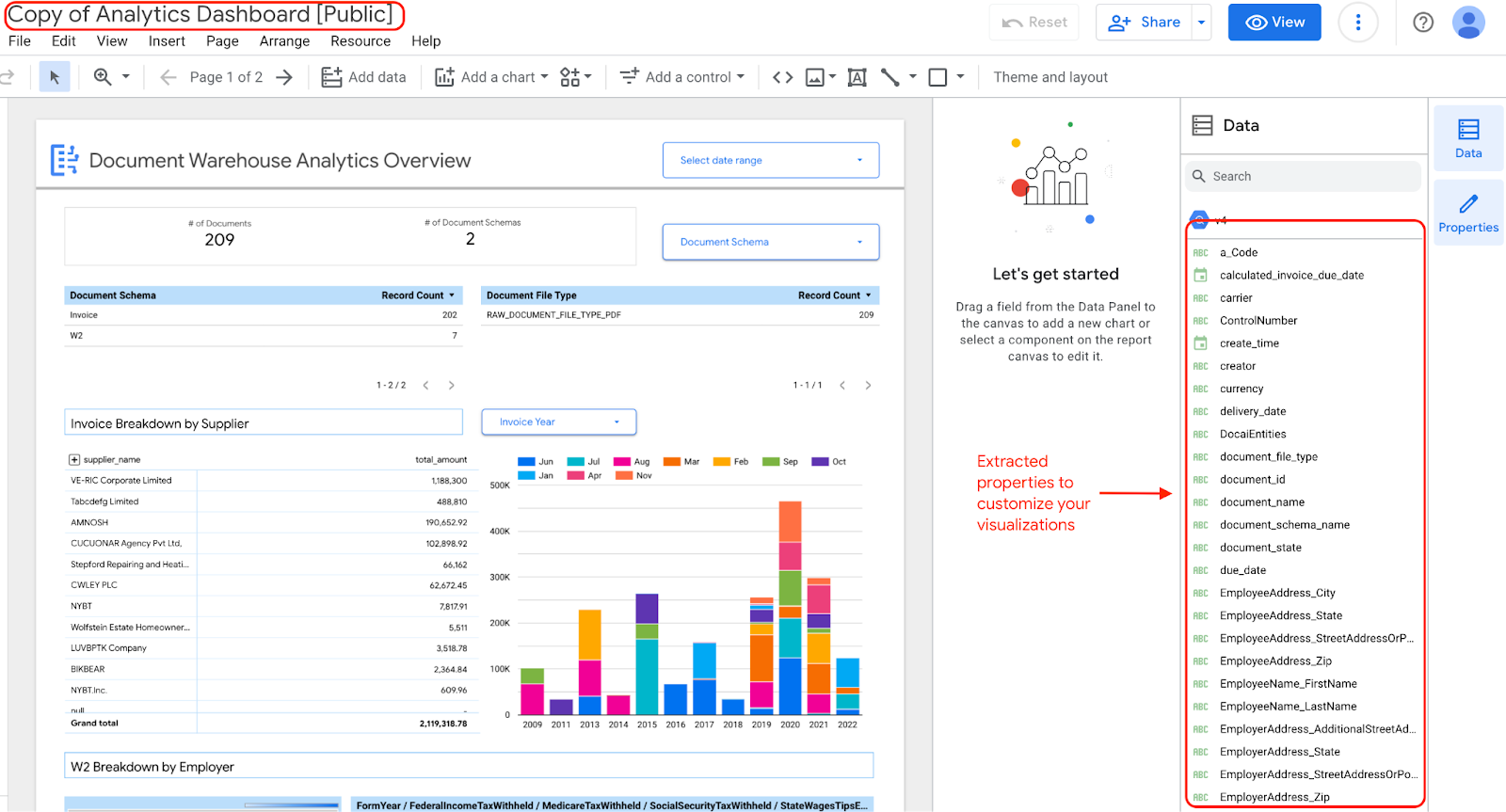
אם תבחרו לערוך ולעדכן את הווידג'טים בלוח הבקרה, תוכלו לערוך אותו כי יש לכם עותק של לוח הבקרה עם המאפיינים שחולצו.