
Document AI memungkinkan Anda melatih versi pemroses baru menggunakan data pelatihan Anda sendiri dan mengevaluasi kualitas versi pemroses Anda terhadap data pengujian Anda sendiri.
Hal ini berguna jika Anda ingin menggunakan pemroses kustom. Ada pemroses Document AI untuk jenis dokumen Anda, tetapi Anda dapat melatih versi kustomnya untuk memenuhi kebutuhan Anda.
Pelatihan dan evaluasi biasanya dilakukan bersamaan untuk melakukan iterasi menuju versi pemroses yang berkualitas tinggi dan dapat digunakan.
Document AI
Document AI memungkinkan Anda membuat pengekstrak kustom Anda sendiri, yang mengekstrak entity dari dokumen jenis tertentu, misalnya, item dalam menu atau nama dan informasi kontak dari resume.
Tidak seperti pemroses lainnya, pemroses kustom tidak dilengkapi dengan versi pemroses terlatih dan oleh karena itu, tidak dapat memproses dokumen apa pun hingga Anda melatih versi dari awal.
Untuk mulai menggunakan Document AI, lihat Membuat pemroses kustom Anda sendiri.
Melatih pemroses
Anda dapat melatih versi pemroses baru untuk meningkatkan akurasi data Anda, mengekstrak kolom kustom tambahan dari dokumen Anda, dan menambahkan dukungan untuk bahasa baru.
Pelatihan berfungsi dengan menerapkan pemelajaran transfer pada versi pemroses terlatih Google dan umumnya memerlukan lebih sedikit data daripada pelatihan dari awal.
Untuk memulai, lihat Melatih pemroses terlatih.
Pemroses yang didukung
Tidak semua pemroses khusus mendukung pelatihan. Berikut adalah pemroses yang mendukung pelatihan.
Pertimbangan dan rekomendasi data
Kualitas dan jumlah data Anda menentukan kualitas pelatihan, pelatihan, dan evaluasi.
Mendapatkan kumpulan dokumen dunia nyata yang representatif dan memberikan label berkualitas tinggi yang memadai sering kali merupakan bagian yang paling memakan waktu dan sumber daya dalam proses ini.
Jumlah dokumen
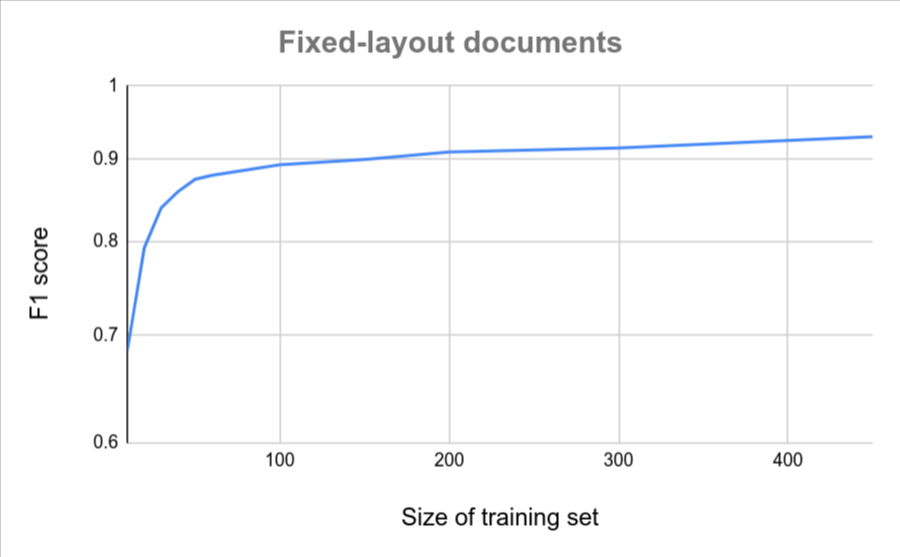
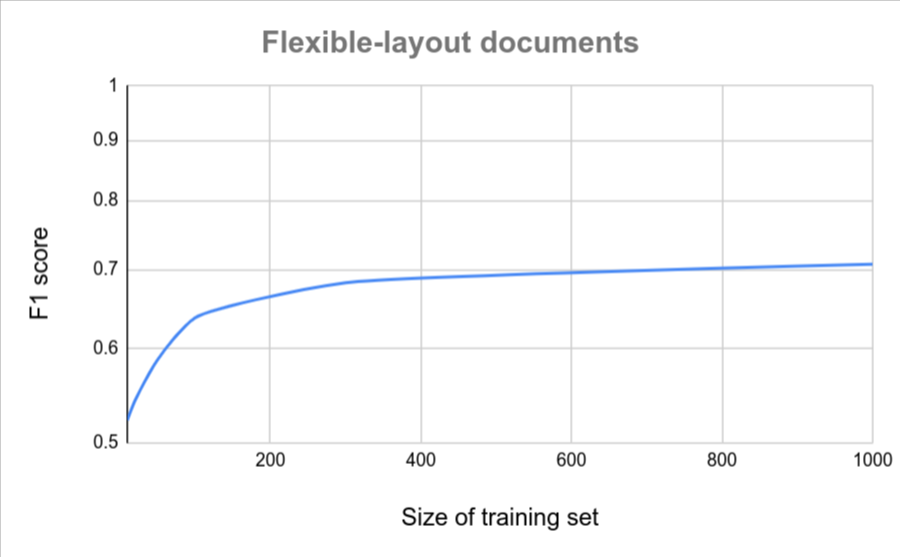
Jika semua dokumen Anda memiliki format yang serupa (misalnya, formulir tetap dengan variasi yang sangat rendah), maka lebih sedikit dokumen yang diperlukan untuk mencapai akurasi. Semakin tinggi variasi, semakin banyak dokumen yang diperlukan.
Diagram berikut memberikan perkiraan kasar jumlah dokumen yang diperlukan agar Pengekstrak Dokumen Kustom mencapai skor kualitas tertentu.
| Variasi rendah | Variasi tinggi |
|---|---|
 |
 |
Pelabelan data
Pertimbangkan opsi Anda untuk memberi label pada dokumen dan pastikan Anda memiliki cukup sumber daya untuk menganotasi dokumen dalam set data Anda.
Melatih model
Pemroses pengekstrak kustom dapat menggunakan jenis model yang berbeda, bergantung pada kasus penggunaan tertentu dan data pelatihan yang tersedia.
- Model kustom: model menggunakan data pelatihan berlabel.
- Berbasis template: dokumen dengan tata letak tetap.
- Berbasis model: dokumen dengan beberapa variasi tata letak.
- Model AI generatif: berdasarkan model dasar terlatih yang memerlukan pelatihan tambahan minimal.
Tabel berikut mengilustrasikan kasus penggunaan mana yang sesuai dengan setiap jenis model.
| Model kustom | AI Generatif | ||
|---|---|---|---|
| Berbasis template | Berbasis model | ||
| Variasi tata letak | Tidak ada | Rendah hingga sedang | Tinggi |
| Jumlah teks bentuk bebas (misalnya, paragraf dalam kontrak) | Rendah | Rendah | Tinggi |
| Jumlah data pelatihan yang diperlukan | Rendah | Tinggi | Rendah |
| Akurasi dengan data pelatihan terbatas | Lebih tinggi | Lebih rendah | Lebih tinggi |
Pelajari cara Menyesuaikan pemroses dengan deskripsi properti.
Kapan harus menggunakan pemroses lain
Berikut adalah beberapa contoh kasus saat Anda mungkin ingin mempertimbangkan opsi selain Document AI Document AI Workbench, atau menyesuaikan alur kerja Anda.
- Format input berbasis teks tertentu (.txt, .html, .docx, .md, dan sebagainya) tidak didukung oleh Document AI Document AI Workbench. Pertimbangkan penawaran pemrosesan bahasa kustom atau bawaan lainnya di Google Cloud, seperti Cloud Natural Language API.
- Skema Pengekstrak Dokumen Kustom mendukung hingga 150 label entity. Jika logika bisnis Anda memerlukan lebih dari 150 entity dalam definisi skema, pertimbangkan untuk melatih beberapa pemroses, yang masing-masing menargetkan subset entity.
Cara melatih pemroses
Dengan asumsi Anda telah membuat pemroses yang mendukung pelatihan atau pelatihan dan memberi label pada set data Anda, Anda dapat melatih versi pemroses baru dari awal. Atau, Anda dapat melatih versi pemroses baru berdasarkan versi yang ada.
Melatih versi pemroses
UI Web
Di Google Cloud konsol, buka tab Train pemroses Anda.
Klik Edit Schema untuk membuka halaman Manage Labels. Verifikasi label pemroses.
Label yang diaktifkan pada saat pelatihan menentukan entity yang diekstrak oleh versi pemroses baru Anda. Jika label tidak aktif dalam skema, versi pemroses tidak akan mengekstrak label tersebut, meskipun dokumen diberi label.
Di tab Train, klik View Label Stats dan verifikasi set pengujian dan set pelatihan Anda. Dokumen yang diberi label otomatis, tidak berlabel, atau tidak ditetapkan dikecualikan dari pelatihan dan evaluasi.
Klik Train new version.
Version Name menentukan kolom
namedariprocessorVersion.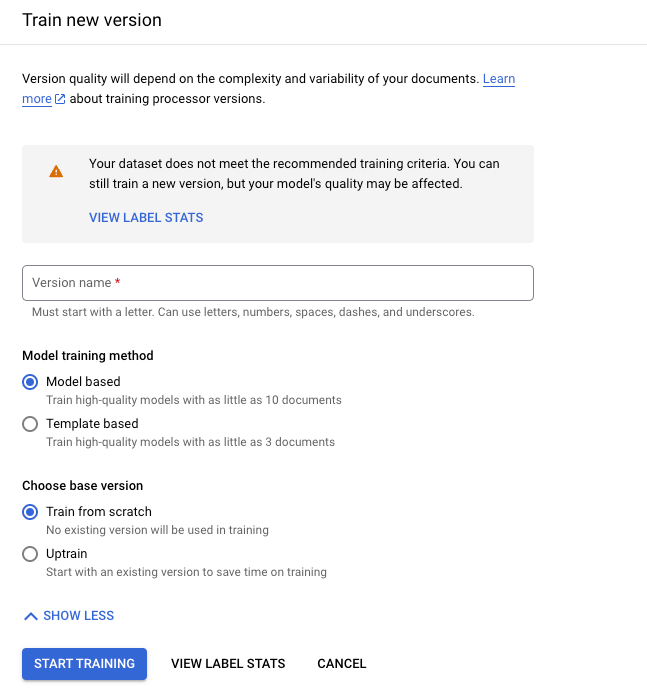
Klik Start training dan tunggu hingga versi pemroses baru Anda dilatih dan dievaluasi.
Anda dapat memantau progres pelatihan di tab Manage Versions:
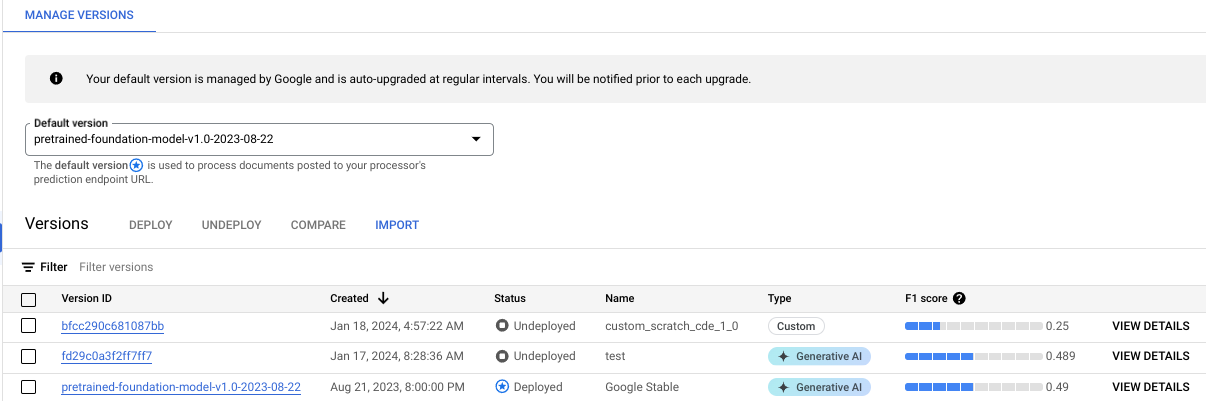
Klik tab Evaluate &Test untuk melihat performa versi pemroses baru Anda pada set pengujian. Untuk mengetahui informasi selengkapnya, lihat Mengevaluasi versi pemroses.
Python
Untuk mengetahui informasi selengkapnya, lihat Document AI Python API dokumentasi referensi.
Untuk melakukan autentikasi ke Document AI, siapkan Kredensial Default Aplikasi. Untuk mengetahui informasi selengkapnya, lihat Menyiapkan autentikasi untuk lingkungan pengembangan lokal.
Men-deploy dan menggunakan versi pemroses
Anda dapat men-deploy dan mengelola versi pemroses Anda seperti versi pemroses lainnya. Untuk mengetahui informasi selengkapnya, lihat Mengelola versi pemroses.
Setelah di-deploy, Anda dapat Mengirim permintaan pemrosesan ke pemroses kustom Anda.
Menonaktifkan atau menghapus pemroses
Jika tidak ingin lagi menggunakan pemroses, Anda dapat menonaktifkan atau menghapusnya. Jika menonaktifkan pemroses, Anda dapat mengaktifkannya kembali. Jika menghapus pemroses, Anda tidak dapat memulihkannya.
Di panel Document AI di sebelah kiri, klik My processors.
Klik titik vertikal di sebelah kanan nama pemroses. Klik Disable processor atau Delete processor.
Untuk mengetahui informasi selengkapnya, lihat Mengelola versi pemroses.
Mengupgrade versi pemroses yang disesuaikan
Anda dapat mengupgrade versi pemroses pengekstrak kustom yang disesuaikan ke versi dasar yang lebih baru. Konfigurasi versi dasar yang lebih baru akan didasarkan pada versi yang lebih lama. Versi ini akan menggunakan data pelatihan pemroses yang ada di versi aslinya.
Di konsol Google Google Cloud , buka tab Deploy & use pemroses Anda, lalu centang kotak untuk versi pemroses yang didukung untuk diupgrade. Konfigurasi versi pemroses baru akan didasarkan pada versi ini.
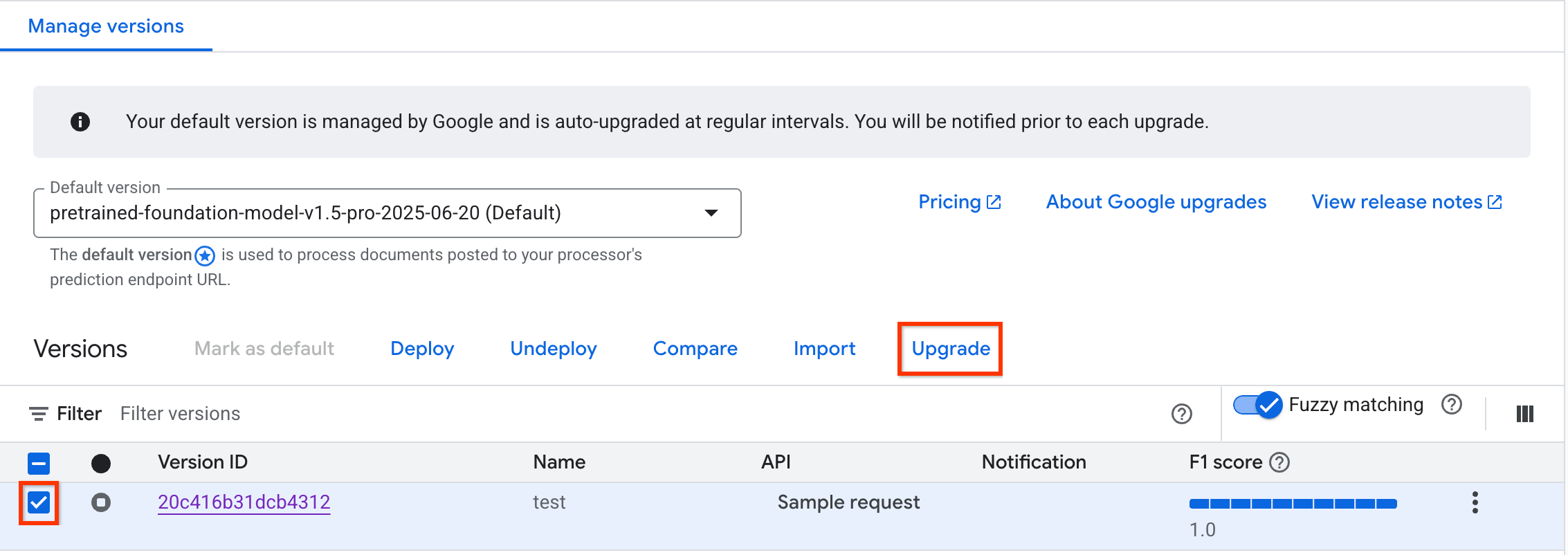
Pilih Upgrade yang diaktifkan. Masukkan nama dan versi dasar untuk versi pemroses baru.
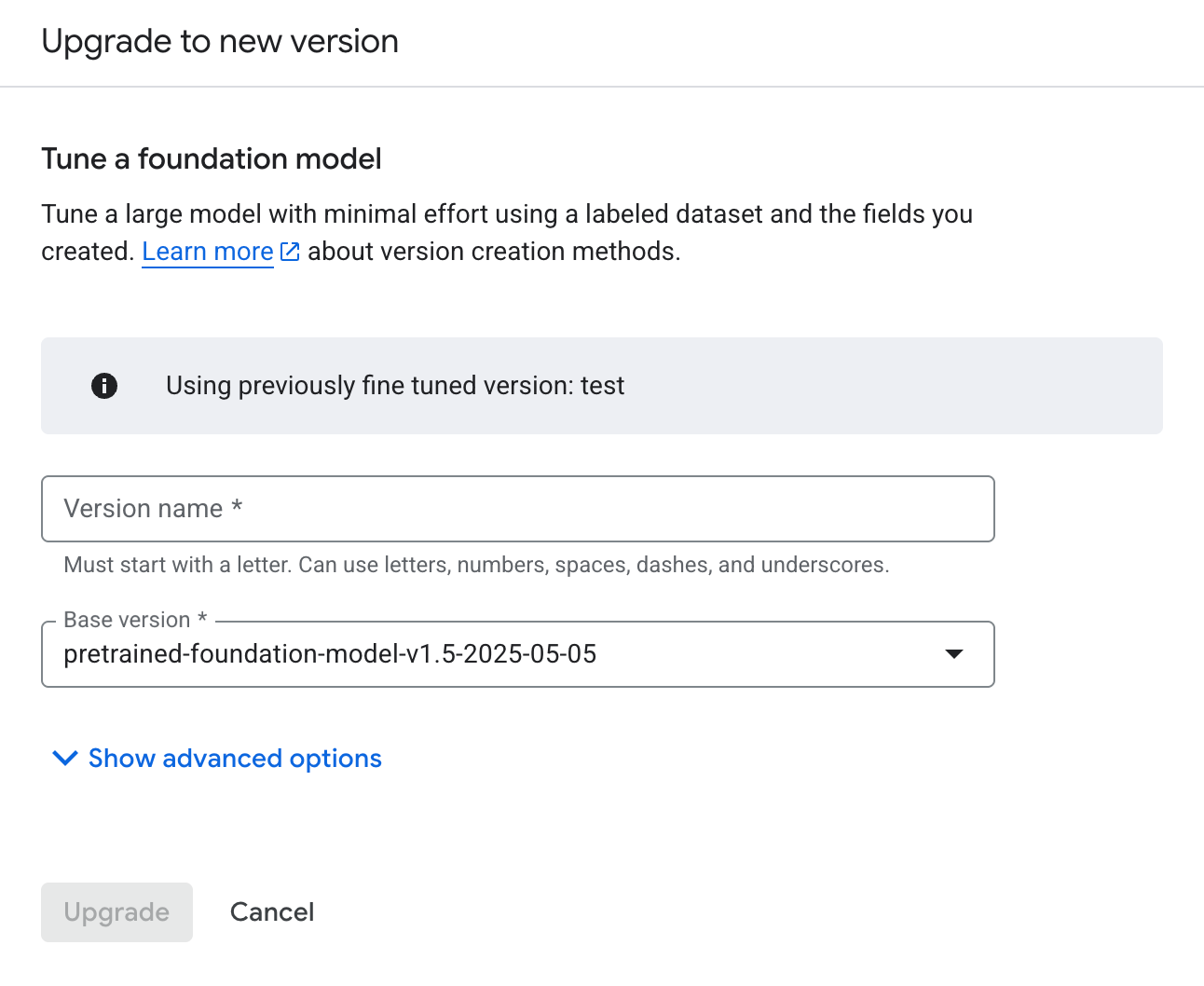
Klik Upgrade dan tunggu hingga versi pemroses baru Anda dilatih.
Menggunakan API untuk mengupgrade
curl
Contoh ini menunjukkan cara memigrasikan processor yang disesuaikan menggunakan kolom FoundationModelTuningOptions
di TrainingMethod.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut dengan informasi di konsol Document AI tab Google Cloud Overview untuk pemroses Anda.
- LOCATION: Lokasi pemroses Anda.
- PROJECT_ID: Project ID Anda.
- PROCESSOR_ID: ID pemroses Anda.
- DISPLAY_NAME: Nama tampilan baru pemroses Anda.
- BASE_PROCESSOR_VERSION: Nama versi pemroses model saat ini
PROCESSOR_VERSION: ID pemroses Anda saat ini yang akan diupgrade
curl -X POST -v -H "Authorization: Bearer $(gcloud auth print-access-token)" \ -H "Content-Type: application/json" \ "https://LOCATION-documentai.googleapis.com/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions:train" \ -d '{ "processor_version": { "display_name": "DISPLAY_NAME" }, "base_processor_version": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/BASE_PROCESSOR_VERSION", "foundation_model_tuning_options": { "train_steps": 10, "learning_rate_multiplier": 1, "previous_fine_tuned_processor_version_name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION", } }'
Enkripsi data pelatihan
Data pelatihan Document AI disimpan di Cloud Storage dan dapat di enkripsi dengan Kunci enkripsi yang dikelola pelanggan jika diperlukan.
Penghapusan data pelatihan
Setelah tugas pelatihan Document AI selesai, semua data pelatihan yang disimpan di Cloud Storage akan berakhir setelah periode retensi dua hari. Aktivitas penghapusan data berikutnya akan mengikuti proses yang dijelaskan dalam Penghapusan data di Google Cloud.
Harga
Tidak ada biaya untuk pelatihan atau pelatihan. Anda membayar untuk hosting dan prediksi. Untuk mengetahui informasi selengkapnya, lihat Harga Document AI.