
Für Training, Aufbautraining oder Bewertung einer Prozessorversion ist ein Dataset aus Dokumenten mit Labels erforderlich.
Auf dieser Seite wird beschrieben, wie Sie Labels aus Ihrem Prozessorschema auf importierte Dokumente in Ihrem Dataset anwenden.
Auf dieser Seite wird davon ausgegangen, dass Sie bereits einen Prozessor erstellt haben, der Training, Aufbautraining oder Bewertung unterstützt. Wenn Ihr Prozessor unterstützt wird, sehen Sie jetzt den Tab Trainieren in der Google Cloud Console. Außerdem wird davon ausgegangen, dass Sie ein Dataset erstellt, Dokumente importiert und ein Prozessorschema definiert haben.
Namensfelder für die Extraktion mit generativer KI
Die Art und Weise, wie Felder benannt werden, beeinflusst, wie genau Felder mit generativer KI extrahiert werden. Wir empfehlen die folgenden Best Practices für die Benennung von Feldern:
Benennen Sie das Feld in derselben Sprache, die zur Beschreibung im Dokument verwendet wird. Wenn ein Dokument beispielsweise ein Feld mit der Beschreibung
Employer Addressenthält, benennen Sie das Feldemployer_address. Verwenden Sie keine Abkürzungen wieemplr_addr.Leerzeichen werden derzeit in Feldnamen nicht unterstützt: Verwenden Sie stattdessen
_. Beispiel:First Namewürde den Namenfirst_nameerhalten.Namen iterieren, um die Genauigkeit zu verbessern: Bei Document AI können Feldnamen nicht geändert werden. Wenn Sie verschiedene Namen testen möchten, verwenden Sie das Tool zum Umbenennen von Entitätsnamen, um den Namen der alten Entität im Dataset zu aktualisieren. Importieren Sie das Dataset, aktivieren Sie die neuen Entitäten im Prozessor und deaktivieren oder löschen Sie die vorhandenen Felder.
Zero-Shot- und Few-Shot-Lernen
Modelle mit Gemini unterstützen Zero-Shot- und Few-Shot-Learning. So lassen sich leistungsstarke Modelle mit wenig bis gar keinen Trainingsdaten erstellen.
Zero-Shot-Learning ist ein Beispiel für maschinelles Lernen, bei dem ein vortrainiertes Modell ohne zusätzliches Training lernt, Klassen und Entitäten zu erkennen und zu klassifizieren, die es während des Tests noch nicht gesehen hat.
Beim Few-Shot-Learning lernt ein Modell, neue Klassen und Entitäten mit nur wenigen Trainingsbeispielen pro Klasse zu erkennen und zu klassifizieren. Dabei wird Wissen aus vortrainierten Modellen für große, gut gelabelte Datasets genutzt, um die Leistung bei Few-Shot-Aufgaben zu verbessern.
Few-Shot-Lernen ist effektiver, wenn das Trainingsdataset übersichtlich und sorgfältig gelabelt ist. In der Regel sind mindestens 10 Test- und 10 Trainingsbeispiele erforderlich, damit das Modell lernen kann.
Optionen für die Kennzeichnung
Sie haben folgende Möglichkeiten, Dokumente zu kennzeichnen:
Manuell: Sie kennzeichnen Ihre Dokumente manuell in der Google Cloud -Konsole.
Automatische Labelerstellung: Mit einer vorhandenen Prozessorversion Labels generieren
Dokumente mit Labels importieren: Zeit sparen, wenn Sie bereits Dokumente mit Labels haben
Manuelles Hinzufügen von Labels in der Google Cloud -Console
Wählen Sie auf dem Tab Trainieren ein Dokument aus, um das Labeling-Tool zu öffnen.
Wählen Sie in der Liste der Schemalabels auf der linken Seite des Labeling-Tools das Symbol „Hinzufügen“ aus, um das Tool Begrenzungsrahmen auszuwählen. Damit können Sie Entitäten im Dokument hervorheben und ihnen ein Label zuweisen.
Im folgenden Screenshot wurden den Feldern EMPL_SSN EMPLR_ID_NUMBER, EMPLR_NAME_ADDRESS, FEDERAL_INCOME_TAX_WH, SS_TAX_WH, SS_WAGES und WAGES_TIPS_OTHER_COMP im Dokument Labels zugewiesen.
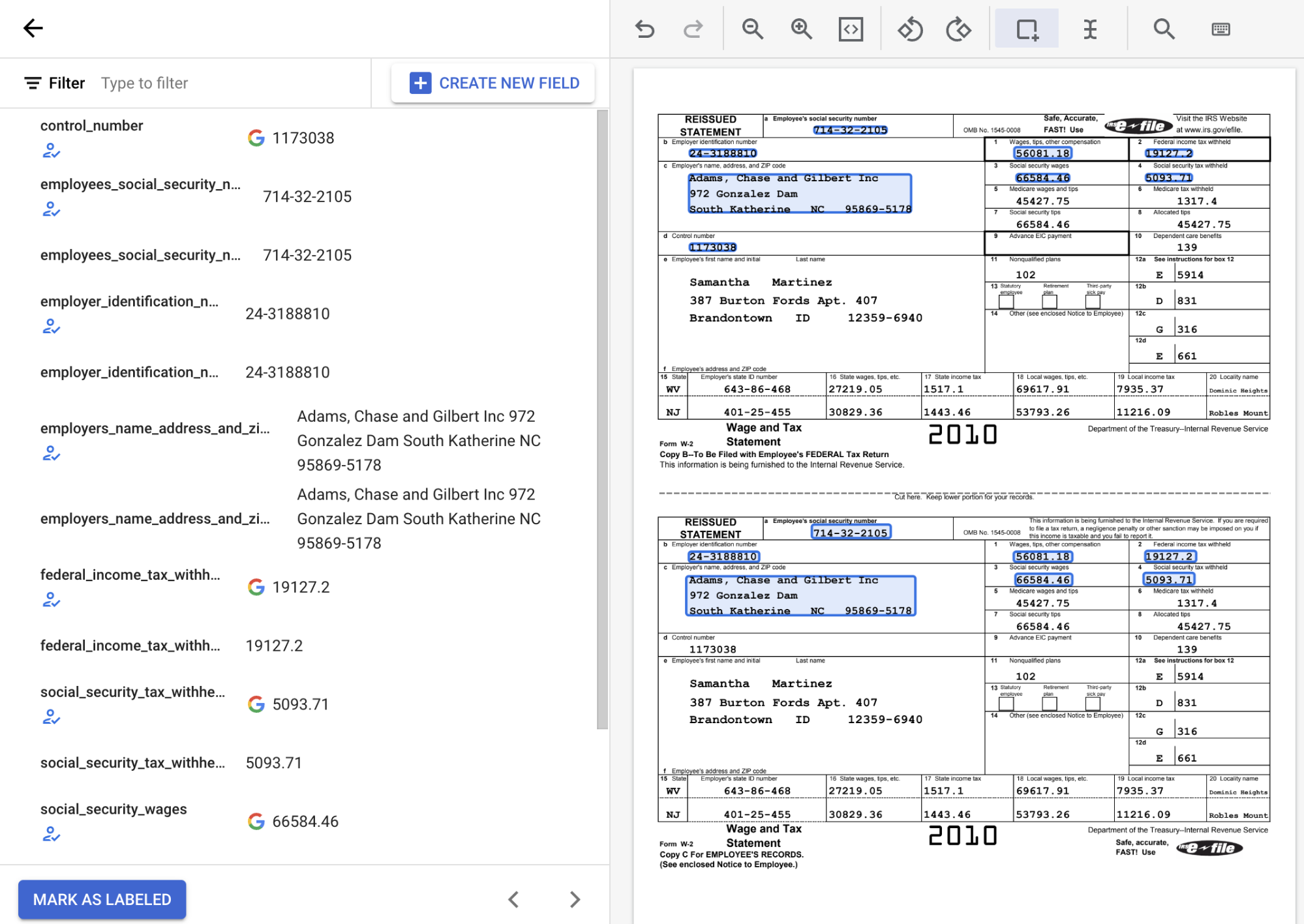
Wenn Sie mit dem Tool Begrenzungsrahmen ein Kästchen auswählen, wählen Sie nur das Kästchen selbst und nicht den zugehörigen Text aus. Achten Sie darauf, dass das Kästchen links entweder ausgewählt oder deaktiviert ist, je nachdem, was im Dokument steht.

Wenn Sie über- und untergeordnete Entitäten kennzeichnen, kennzeichnen Sie nicht die übergeordneten Entitäten. Die übergeordneten Einheiten sind nur Container der untergeordneten Einheiten. Kennzeichnen Sie nur die untergeordneten Entitäten. Die übergeordneten Einheiten werden automatisch aktualisiert.
Wenn Sie untergeordnete Einheiten kennzeichnen, kennzeichnen Sie die erste untergeordnete Einheit und verknüpfen Sie dann die zugehörigen untergeordneten Einheiten mit dieser Zeile. Das sehen Sie bei der zweiten untergeordneten Einheit, wenn Sie solche Einheiten zum ersten Mal kennzeichnen. Wenn Sie beispielsweise eine Rechnung mit dem Label description versehen, wird sie wie jede andere Einheit behandelt. Wenn Sie jedoch als Nächstes quantity (Menge) auswählen, werden Sie aufgefordert, das übergeordnete Element auszuwählen.
Wiederholen Sie diesen Schritt für jede Position, indem Sie für jede neue Position Neue übergeordnete Einheit auswählen.
Über- und untergeordnete Entitäten werden für Tabellen mit bis zu drei Verschachtelungsebenen unterstützt. Foundation Models unterstützen drei Ebenen von Feldern (übergeordnetes Element, übergeordnetes Element und untergeordnetes Element), sodass untergeordnete Einheiten eine Ebene von untergeordneten Elementen haben können. Weitere Informationen zum Verschachteln finden Sie unter Verschachtelung auf drei Ebenen.
Kurze Übersichten
Wenn Sie eine Tabelle mit Labels versehen, kann es mühsam sein, jede Zeile immer wieder neu zu labeln. Es gibt ein sehr praktisches Tool, mit dem sich die Struktur einer Zeilenentität replizieren lässt. Diese Funktion funktioniert nur bei horizontal ausgerichteten Zeilen.
- Kennzeichnen Sie zuerst die erste Zeile wie gewohnt.
Halten Sie dann den Mauszeiger über die übergeordnete Entität, die die Zeile darstellt. Wählen Sie Weitere Zeilen hinzufügen aus. Die Zeile wird zu einer Vorlage, mit der weitere Zeilen erstellt werden können.
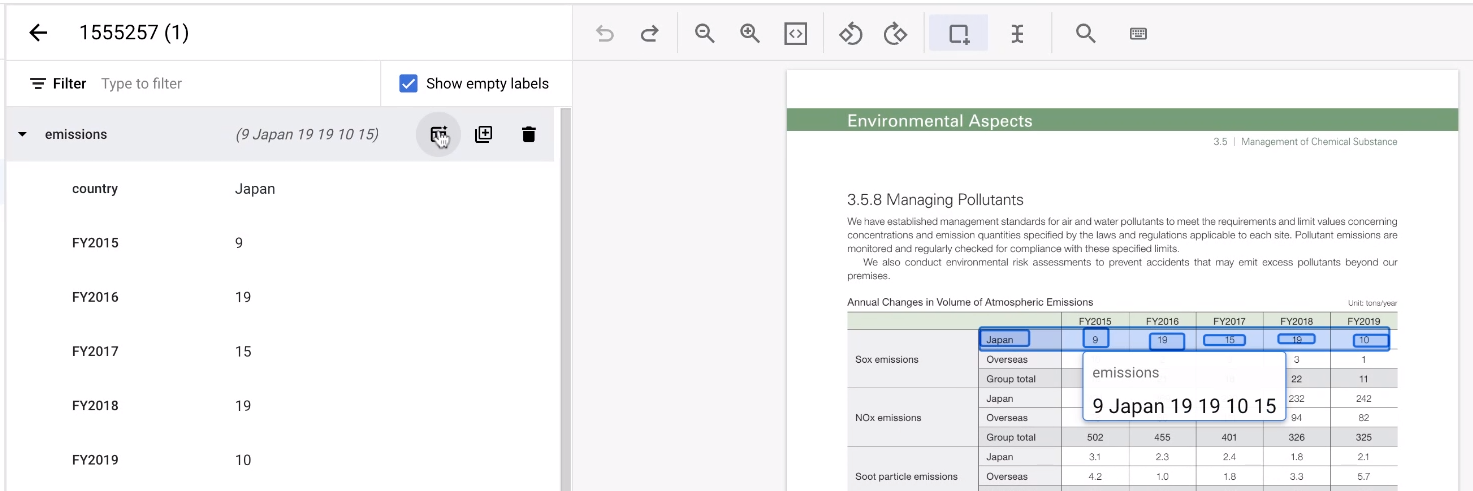
Wählen Sie den restlichen Bereich der Tabelle aus.
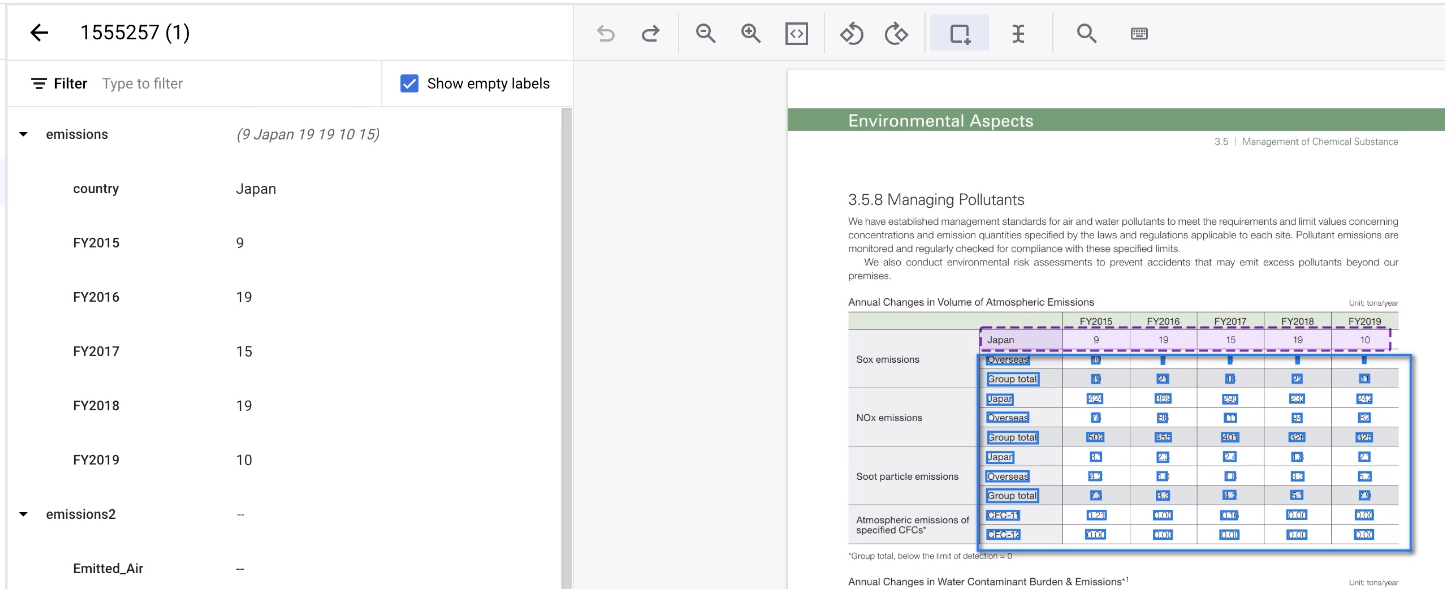
Das Tool schätzt die Anmerkungen und das funktioniert in der Regel. Tabellen, die nicht verarbeitet werden können, müssen manuell annotiert werden.
Tastenkombinationen in der Konsole verwenden
Wenn Sie die verfügbaren Tastenkombinationen aufrufen möchten, wählen Sie rechts oben in der Kennzeichnungs-Konsole das -Menü aus. Es wird eine Liste mit Tastenkombinationen angezeigt, wie in der folgenden Tabelle dargestellt.
| Aktion | Tastenkombination |
|---|---|
| Heranzoomen | Alt + = (Wahltaste + = unter macOS) |
| Herauszoomen | Alt + - (Wahltaste + - unter macOS) |
| Passend zum Anzeigen zoomen | Alt + 0 (Wahltaste + 0 unter macOS) |
| Scrollen, um zu zoomen | Alt + Scrollen (Wahltaste + Scrollen unter macOS) |
| Schwenken | Scrollen |
| Umgekehrtes Schwenken | Umschalttaste + Scrollen |
| Ziehen, um zu schwenken | Leertaste + Mauszeiger ziehen |
| Rückgängig machen | Strg + Z (Strg + Z unter macOS) |
| Wiederholen | Strg + Umschalt + Z (Ctrl + Umschalt + Z unter macOS) |
Labels automatisch hinzufügen
Falls verfügbar, können Sie eine vorhandene Version Ihres Prozessors verwenden, um mit dem Labeling zu beginnen.
Das automatische Labeling kann während des Imports gestartet werden. Alle Dokumente werden mit der angegebenen Prozessorversion mit Anmerkungen versehen.
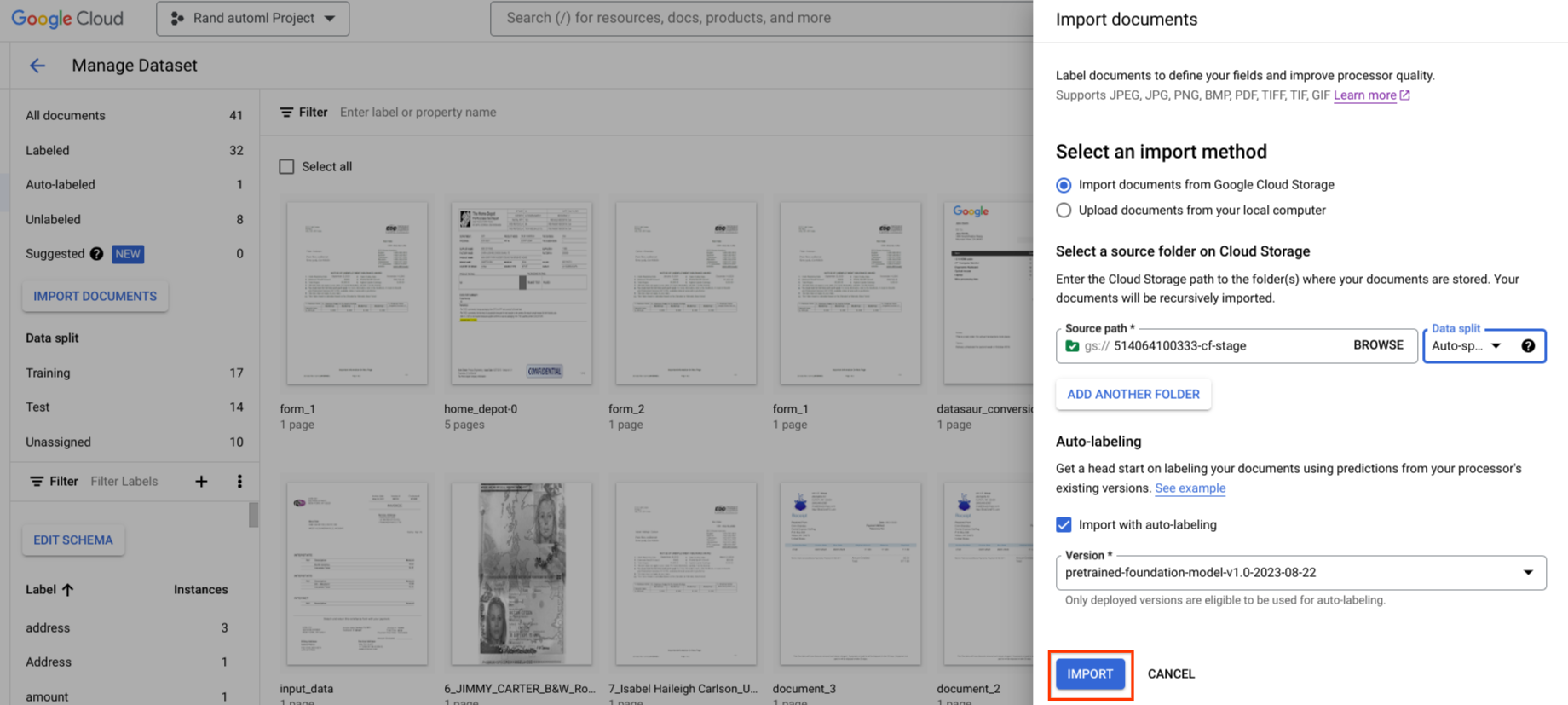
Das automatische Labeling kann nach dem Import für Dokumente in der Kategorie „Ohne Label“ oder „Automatisch mit Label versehen“ gestartet werden. Alle ausgewählten Dokumente werden mit der angegebenen Prozessorversion annotiert.
Sie können automatisch mit Labels versehene Dokumente nicht für das Training oder Aufbautraining verwenden oder sie im Testset verwenden, ohne sie als „Mit Label versehen“ zu markieren. Überprüfen und korrigieren Sie die automatisch gelabelten Anmerkungen manuell und wählen Sie dann Als gelabelt markieren aus, um die Korrekturen zu speichern. Anschließend können Sie die Dokumente entsprechend zuweisen.
Dokumente mit Labels importieren
Sie können JSON-Dateien Document importieren. Wenn die entity im Dokument mit dem Label im Prozessorschema übereinstimmt, wird die entity vom Importer in eine Label-Instanz konvertiert. Es gibt mehrere Möglichkeiten, JSON-Dokumentdateien zu erhalten:
Exportieren eines Datasets von einem anderen Prozessor Weitere Informationen finden Sie unter Dataset exportieren.
Verarbeitungsanfrage an einen vorhandenen Auftragsverarbeiter senden
Mit dem Import-Toolkit können Sie vorhandene Labels aus einem anderen System, z. B. Labels im CSV-Format, in JSON-Dokumente konvertieren.
Best Practices für das Labeln von Dokumenten
Für das Training eines hochwertigen Prozessors ist eine konsistente Kennzeichnung erforderlich. Wir empfehlen Folgendes:
Anleitung zum Labeln erstellen: Ihre Anleitung sollte Beispiele für häufige und Grenzfälle enthalten. Einige Tipps:
- Erkläre, welche Felder annotiert werden sollten und wie die Kennzeichnung konsistent erfolgen kann. Wenn Sie beispielsweise „amount“ (Betrag) kennzeichnen, geben Sie an, ob das Währungssymbol gekennzeichnet werden soll. Wenn die Labels nicht einheitlich sind, wird die Prozessorqualität beeinträchtigt.
- Sie müssen alle Vorkommen einer Entität mit einem Label versehen, auch wenn der Labeltyp
REQUIRED_ONCEoderOPTIONAL_ONCEist. Wenninvoice_idbeispielsweise zweimal im Dokument vorkommt, müssen Sie alle Vorkommen kennzeichnen. - Im Allgemeinen wird empfohlen, zuerst das Standardtool für Begrenzungsrahmen zu verwenden. Wenn das nicht funktioniert, verwenden Sie das Tool zum Auswählen von Text.
- Wenn der Wert des Labels nicht korrekt per OCR erkannt wird, korrigieren Sie ihn nicht manuell. Dadurch wäre es für Trainingszwecke unbrauchbar.
Hier sind einige Beispiele für Anleitungen zur Kennzeichnung:
- Kommentatoren schulen: Achten Sie darauf, dass die Kommentatoren die Richtlinien verstehen und ohne systematische Fehler befolgen können. Eine Möglichkeit, dies zu erreichen, besteht darin, dass verschiedene Mitarbeiter in der Ausbildung denselben Satz von Dokumenten annotieren. Der Trainer kann dann die Qualität der Annotierungsarbeit jedes Lernenden überprüfen. Möglicherweise müssen Sie diesen Vorgang wiederholen, bis die Lernenden ein bestimmtes Maß an Genauigkeit erreichen.
- Erste Überprüfungen: Die ersten etwa zehn Dokumente, die von einem neuen Labeler für einen Anwendungsfall gekennzeichnet werden, sollten überprüft werden, bevor eine große Anzahl von Dokumenten gekennzeichnet wird. So lässt sich eine große Anzahl von Fehlern vermeiden, die korrigiert werden müssen.
- Überprüfungen der Annotationsqualität: Da das Annotieren sehr aufwendig ist, können auch erfahrene Annotatoren Fehler machen. Wir empfehlen, dass Anmerkungen von mindestens einem weiteren geschulten Annotator überprüft werden.
Beschreibungsprompt hinzufügen
Wenn Sie dem Schema im benutzerdefinierten Extraktor und benutzerdefinierten Klassifikator Labels hinzufügen, können Sie eine Beschreibung für das Label hinzufügen. So wird der Prozessor trainiert, indem ein Prompt bereitgestellt wird, mit dem das Label identifiziert werden kann. Sie können verschiedene Varianten ausprobieren, um die Qualität der Antworten zu testen. Beispiele: „Gesamtbetrag“, „Gesamtrechnungsbetrag“ oder „Gesamtbetrag der Rechnung“.
Dataset neu synchronisieren
Durch die erneute Synchronisierung wird der Cloud Storage-Ordner Ihres Datasets mit dem internen Metadatenindex von Document AI synchronisiert. Das ist nützlich, wenn Sie versehentlich Änderungen am Cloud Storage-Ordner vorgenommen haben und die Daten synchronisieren möchten.
So synchronisieren Sie die Daten noch einmal:
Wählen Sie auf dem Tab Prozessordetails neben der Zeile Speicherort die Option und dann Dataset neu synchronisieren aus.
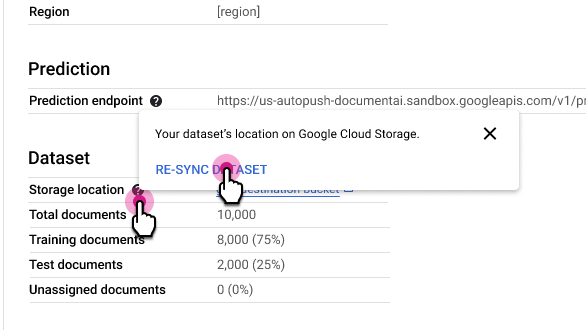
Verwendungshinweise:
- Wenn Sie ein Dokument aus dem Cloud Storage-Ordner löschen, wird es durch die erneute Synchronisierung aus dem Dataset entfernt.
- Wenn Sie dem Cloud Storage-Ordner ein Dokument hinzufügen, wird es durch die erneute Synchronisierung nicht dem Dataset hinzugefügt. Wenn Sie Dokumente hinzufügen möchten, müssen Sie sie importieren.
- Wenn Sie Dokumentlabels im Cloud Storage-Ordner ändern, werden die Dokumentlabels im Dataset durch die erneute Synchronisierung aktualisiert.
Dataset migrieren
Mit der Import- und Exportfunktion können Sie alle Dokumente in einem Dataset von einem Prozessor zu einem anderen verschieben. Das kann nützlich sein, wenn Sie Prozessoren in verschiedenen Regionen oder Google Cloud Projekten haben, wenn Sie verschiedene Prozessoren für Staging und Produktion oder für den allgemeinen Offline-Gebrauch haben.
Es werden nur die Dokumente und ihre Labels exportiert. Metadaten von Datasets wie Prozessorschema, Dokumentzuweisungen (Training/Test/Nicht zugewiesen) und Dokumentlabelstatus (Mit Label versehen, Nicht mit Label versehen, Automatisch mit Label versehen) werden nicht exportiert.
Das Kopieren und Importieren des Datasets und das anschließende Trainieren des Zielprozessors ist nicht dasselbe wie das Trainieren des Quellprozessors. Das liegt daran, dass zu Beginn des Trainingsprozesses zufällige Werte verwendet werden. Verwenden Sie den importProcessorVersion-API-Aufruf, um genau dasselbe Modell zwischen Projekten zu importieren und zu migrieren. Dies ist die beste Vorgehensweise für die Migration von Prozessoren in höhere Umgebungen (z. B. von der Entwicklung über die Staging- zur Produktionsumgebung), sofern die Richtlinien dies zulassen.
Dataset exportieren
Wenn Sie alle Dokumente als JSON-Dateien Document in einen Cloud Storage-Ordner exportieren möchten, wählen Sie Dataset exportieren aus.
Wichtige Hinweise:
Beim Export werden drei Unterordner erstellt: Test, Train und Unassigned. Ihre Dokumente werden entsprechend in diesen Unterordnern abgelegt.
Der Kennzeichnungsstatus eines Dokuments wird nicht exportiert. Wenn Sie die Dokumente später importieren, werden sie nicht als automatisch gelabelt gekennzeichnet.
Wenn sich Ihr Cloud Storage-Bucket in einem anderen Google Cloud Projekt befindet, müssen Sie Zugriff gewähren, damit Document AI Dateien an diesen Speicherort schreiben darf. Sie müssen dem Hauptdienst-Agent von Document AI,
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com, die Rolle Storage-Objekt-Ersteller zuweisen. Weitere Informationen finden Sie unter Dienst-Agents.
Dataset importieren
Die Vorgehensweise ist dieselbe wie beim Importieren von Dokumenten.
Anleitung zum selektiven Labeling
Das selektive Labeling hilft bei Empfehlungen, welche Dokumente gelabelt werden sollten. Sie können verschiedene Trainings- und Test-Datasets erstellen, um repräsentative Modelle zu trainieren. Jedes Mal, wenn selektive Kennzeichnung durchgeführt wird, werden die vielfältigsten (bis zu 30) Dokumente aus dem Dataset ausgewählt.
Vorgeschlagene Dokumente abrufen
Erstellen Sie einen CDE-Prozessor und importieren Sie Dokumente.
- Für das Training sind mindestens 100 Satzpaare erforderlich (25 für das Testen).
- Sobald genügend Dokumente importiert wurden und nach dem selektiven Labeling sollte die Informationsleiste angezeigt werden.
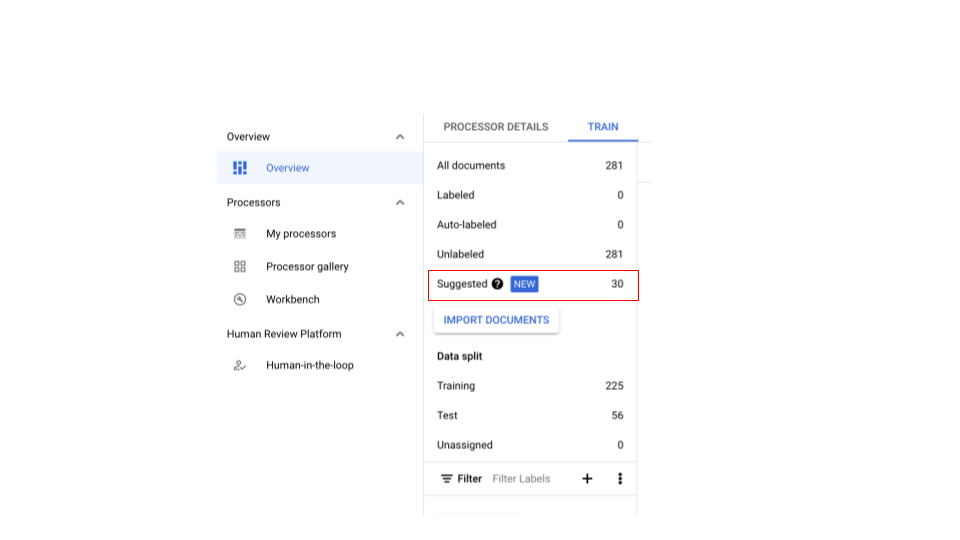
Wenn für einen CDE-Prozessor keine Dokumente vorgeschlagen werden, importieren Sie mehr, damit in beiden Splits genügend Dokumente für die Stichprobenerhebung vorhanden sind.
- Dadurch sollten die vorgeschlagenen Dokumente in der Kategorie „Vorschläge“ angezeigt werden. Sie sollten vorgeschlagene Dokumente manuell anfordern können.
- Oben gibt es einen neuen Filter, mit dem Sie vorgeschlagene Dokumente herausfiltern können.
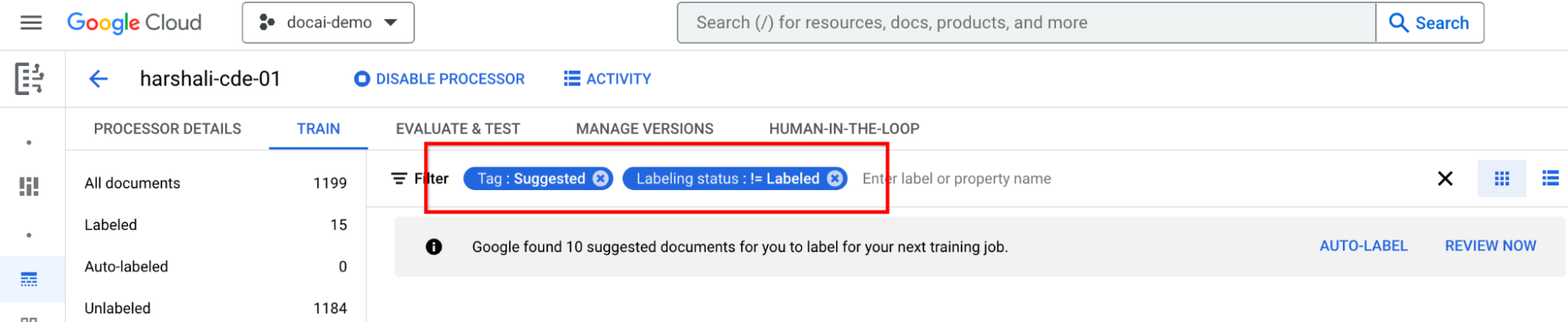
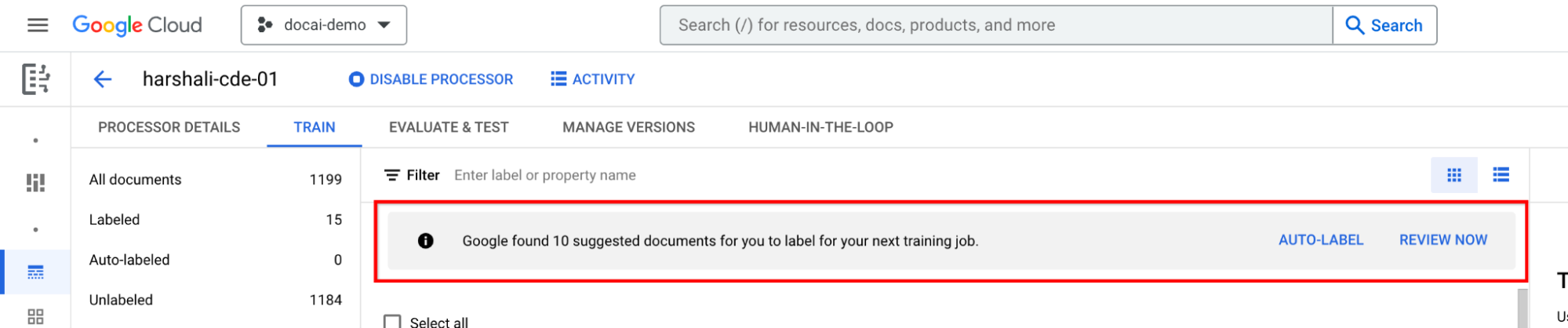
Vorgeschlagene Dokumente mit Labels versehen
Klicken Sie im Bereich mit der Label-Liste auf der linken Seite auf Vorgeschlagene Kategorie. Beginnen Sie mit dem Labeln dieser Dokumente.
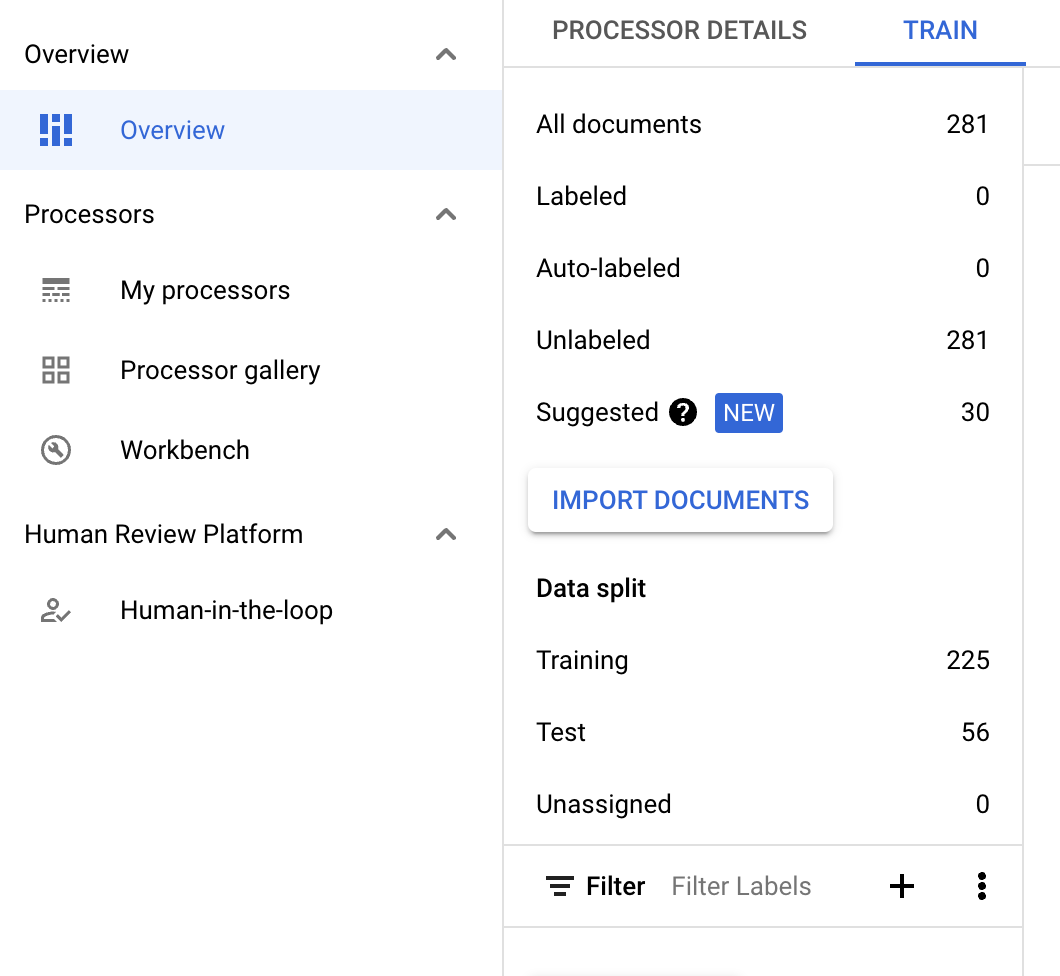
Wählen Sie in der Infoleiste Automatisch labeln aus, wenn der Prozessor trainiert wurde. Vorgeschlagene Dokumente mit einem Label versehen
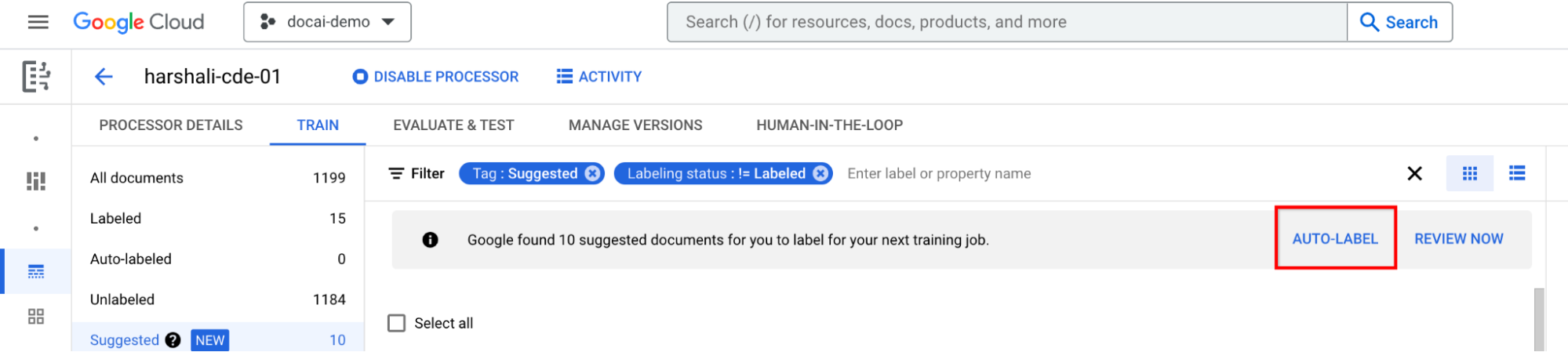
Sie können dann in der Leiste Jetzt überprüfen auswählen, wenn Sie Dokumente im Prozessor vorgeschlagen haben, zu denen Sie navigieren möchten. Alle automatisch mit Labels versehenen Dokumente sollten auf Richtigkeit überprüft werden. Beginnen Sie mit der Überprüfung.

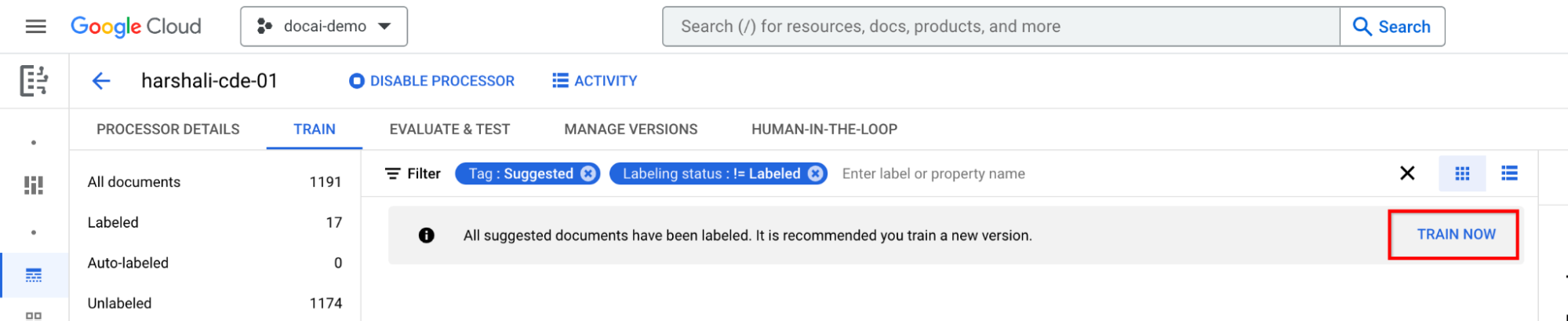
Nachdem alle vorgeschlagenen Dokumente mit Labels versehen wurden, trainieren
Bewegen Sie den Mauszeiger in der Informationsleiste auf Jetzt trainieren. Wenn die vorgeschlagenen Dokumente gekennzeichnet sind, wird die folgende Informationsleiste mit einer Empfehlung für das Training angezeigt.
Unterstützte Funktionen und Einschränkungen
| Funktion | Beschreibung | Unterstützt |
|---|---|---|
| Unterstützung alter Prozessoren | Funktioniert möglicherweise nicht gut mit alten Prozessoren mit zuvor importiertem Dataset |