
Gemini 레이아웃 파서로 문서 처리
Document AI 레이아웃 파서는 복잡한 파일의 비정형 콘텐츠를 고도로 구조화되고 정확하며 머신 리더블 정보로 변환하는 고급 텍스트 파싱 및 문서 이해 서비스입니다. Google의 전문 객체 문자 인식 (OCR) 모델과 Gemini의 생성형 AI 기능을 결합합니다. 전체 문서 구조를 이해하고 테이블, 그림, 목록, 헤더와 같은 요소를 식별하는 동시에 단락이 속한 제목과 같은 요소 간의 컨텍스트 관계를 유지합니다.
검색 및 검색 증강 생성 (RAG)의 중요한 문제를 해결하도록 설계되었습니다. 표준 OCR은 문서를 평면화하여 제목, 표, 목록과 같은 중요한 의미를 더하는 컨텍스트와 구조를 파괴합니다.
주요 사용 사례
- 문서 OCR: PDF 문서에서 제목, 머리글, 바닥글, 표 구조, 그림과 같은 텍스트 및 레이아웃 요소를 파싱할 수 있습니다.
- 고품질 검색 및 RAG: 검색 및 RAG 파이프라인을 위해 문서를 준비하는 것이 주요 용도입니다. 컨텍스트 인식 청크를 만들어 검색 품질과 생성된 답변의 정확성을 크게 개선합니다.
- 구조화된 데이터 수집: BigQuery에서 보여준 것처럼 복잡한 문서(예: 10-K 제출 또는 보고서)를 파싱하고 파싱된 표 또는 이미지 설명과 같은 구조화된 콘텐츠를 데이터베이스에 색인 생성할 수 있습니다.
작동 방식
Gemini 레이아웃 파서는 시맨틱 의미를 보존하도록 설계된 다단계 파이프라인에서 문서를 처리합니다.
- 파싱 및 구조화: 문서가 수집됩니다. 모든 요소가 식별되고 트리 형식으로 구성됩니다. 이
DocumentLayout프로토 필드는 문서의 고유 계층 구조를 보존합니다. - 주석 달기 및 구두 설명: 미리보기 Gemini의 생성 기능을 사용하여 복잡한 시각적 요소를 구두로 설명합니다. 그림, 차트, 표에 서식 있는 텍스트 설명이 주석으로 추가됩니다.
- 청크 처리 및 증강: 파싱된 문서와 주석을 사용하여 시맨틱으로 일관된 청크를 만듭니다. 이러한 청크는 조상 제목과 같은 컨텍스트 정보로 증강되어 청크의 의미가 격리된 상태로 검색되더라도 보존되도록 합니다.
프로세서 버전
다음 모델을 레이아웃 파서에 사용할 수 있습니다. 모델 버전을 변경하려면 프로세서 버전 관리를 참고하세요.
기본 프로세서 할당량에 대한 할당량 증가 요청 (QIR)을 하려면 할당량 관리의 단계를 따르세요.
| 모델 버전 | 설명 | 출시 채널 | 출시일 |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
문서 레이아웃 분석을 위한 정식 버전입니다. 기본 선행 학습된 프로세서 버전입니다. | 정식 | 2024년 6월 3일 |
pretrained-layout-parser-v1.5-2025-08-25 |
PDF 파일의 레이아웃 분석을 개선하기 위해 Gemini 2.5 Flash LLM으로 구동되는 프리뷰 버전입니다. 새 버전을 실험해 보려는 사용자에게 권장됩니다. | 출시 후보 | 2025년 8월 25일 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
PDF 파일의 레이아웃 분석을 개선하기 위해 Gemini 2.5 Pro LLM으로 구동되는 프리뷰 버전입니다. v1.5-pro는 v1.5보다 지연 시간이 깁니다. | 출시 후보 | 2025년 8월 25일 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
Gemini 3.0 Pro LLM으로 구동되는 프리뷰 버전입니다. | 출시 후보 | 2025년 12월 1일 |
pretrained-layout-parser-v1.6-2026-01-13 |
Gemini 3.0 Flash LLM으로 구동되는 프리뷰 버전입니다. | 출시 후보 | 2026년 1월 13일 |
주요 기능
이 문서에서는 Gemini 레이아웃 파서가 pretrained-layout-parser-v1.5-2025-08-25 및 pretrained-layout-parser-v1.5-pro-2025-08-25와 같은 Gemini 기반 선행 학습된 레이아웃 파서 프로세서 버전을 의미합니다. Gemini 레이아웃 파서는 다음과 같은 주요 기능을 지원합니다.
고급 테이블 파싱
재무 보고서 또는 기술 매뉴얼의 표는 RAG의 일반적인 실패 지점입니다. Gemini 레이아웃 파서는 병합된 셀과 복잡한 헤더가 있는 복잡한 표에서 데이터를 추출하는 데 탁월합니다.
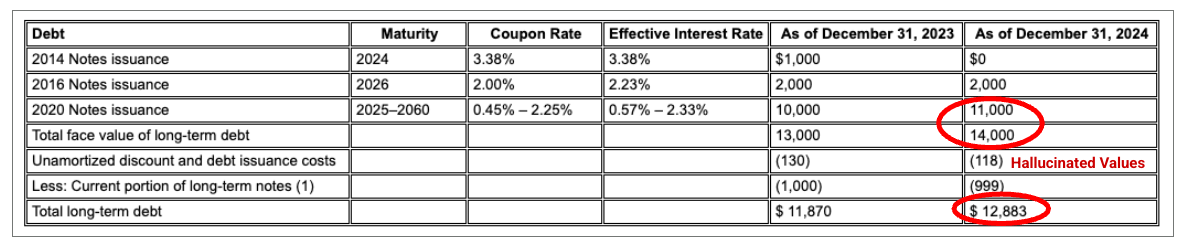
예: 이 Alphabet 10-K 제출에서 경쟁업체의 파서는 헤더와 셀을 올바르게 정렬하지 못하고 재무 데이터를 잘못 해석합니다. Gemini 레이아웃 파서는 전체 표 구조를 정확하게 파싱하여 데이터의 무결성을 보존합니다.
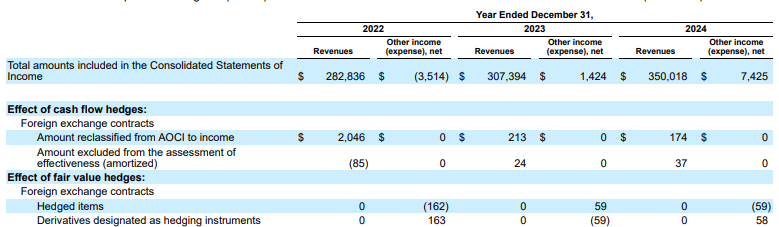
그림 1. 이 입력 문서의 소스는 "Alphabet 2024 SEC Form 10-K", 72페이지입니다.
경쟁업체 파서는 셀 및 열 정렬을 제대로 감지하지 못하고 값을 할루시네이션합니다.
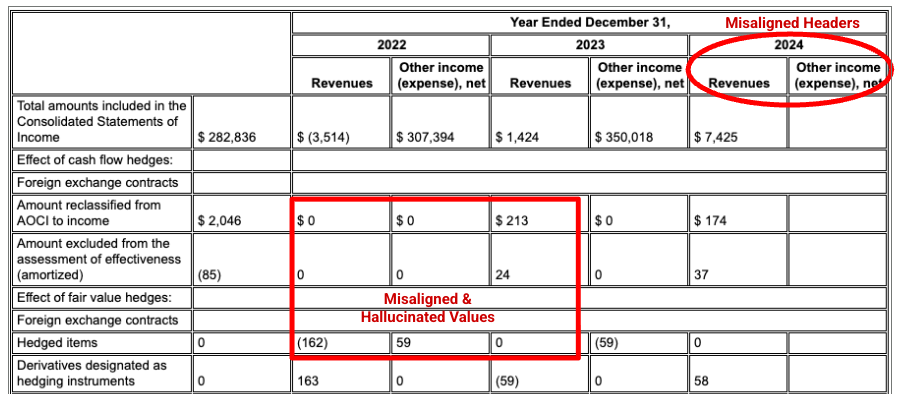
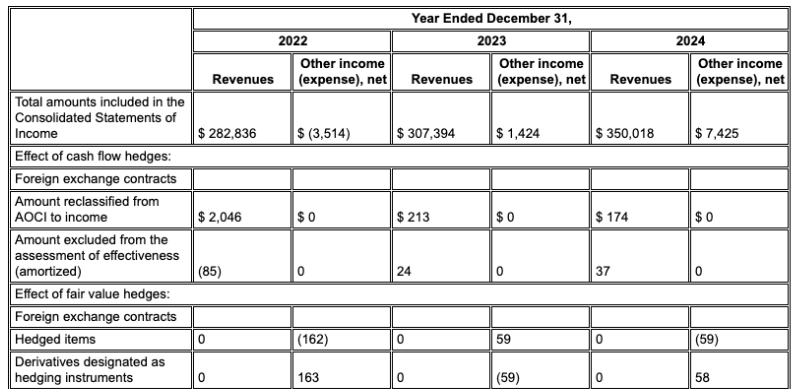
Gemini 레이아웃 파서는 열을 올바르게 정렬하고 정확한 값을 제공합니다.
할루시네이션 감소
없는 텍스트를 읽으려고 하는 순수 LLM 기반 파서와 달리 Gemini 레이아웃 파서는 고급 OCR을 기반으로 문서의 실제 콘텐츠에 기반합니다. 따라서 할루시네이션이 훨씬 적습니다.
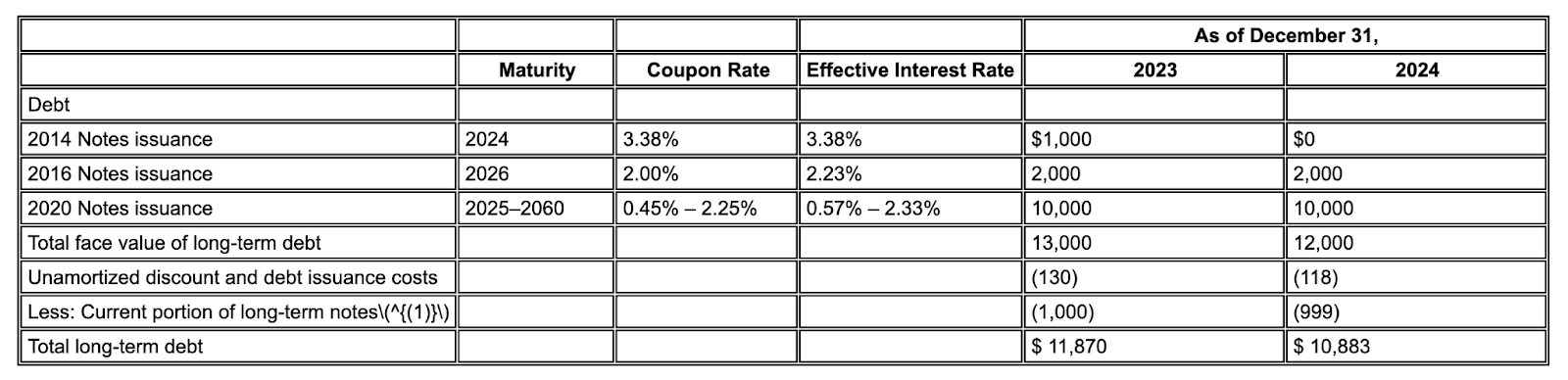
예: 이 10-K 발췌문에서 경쟁업체 모델은 할루시네이션하고 잘못된 텍스트를 삽입합니다. Gemini 레이아웃 파서는 페이지에 있는 텍스트만 깔끔하고 정확하게 추출합니다.
그림 2. 입력 문서 (Alphabet 2024 10k p75)
경쟁업체 모델은 값을 할루시네이션합니다.
Gemini 레이아웃 파서는 이미지와 표의 값을 올바르게 식별합니다.
레이아웃 인식 청크 처리
표준 파서는 종종 원래 컨텍스트에서 삭제된 청크를 만들어 단락을 제목에서 분리합니다. Gemini 레이아웃 파서는 문서의 계층 구조를 이해합니다. 조상 제목과 표 헤더의 콘텐츠를 포함하는 컨텍스트 인식 청크를 만듭니다. 검색된 청크에는 텍스트뿐만 아니라 정확한 LLM 응답에 필요한 구조적 컨텍스트도 포함됩니다.
그림 3. 이 이미지의 소스는 "Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis", by Shangbang Long, Siyang Qin, Yasuhisa Fujii, Alessandro Bissacco, and Michalis Raptis입니다.
레이아웃 주석
레이아웃 파서 주석은 파싱된 문서에 이미지나 표가 있는지 식별할 수 있습니다. 발견되면 이미지와 표에 묘사된 정보가 포함된 설명 텍스트 블록으로 주석이 추가됩니다.
예를 들어 은행 보고서를 처리할 때 파서는 이미지만 보는 것이 아닙니다. 자세한 설명을 생성하고 세 개의 원형 차트에서 데이터 포인트를 추출하여 검색에 사용할 수 있도록 합니다.
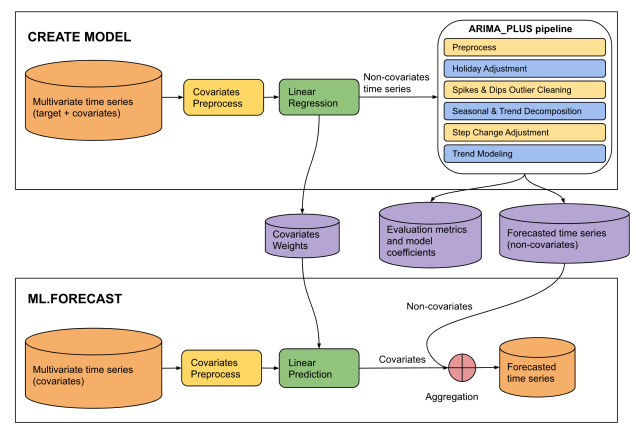
그림 4. 이 입력의 소스는 Google Cloud 사이트의 "ARIMA_ PLUS_XREG 모델의 CREATE MODEL 문"의 저장된 PDF입니다.
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
제한사항
다음과 같은 제한사항이 적용됩니다.
- 온라인 처리:
- 모든 파일 형식의 최대 입력 파일 크기는 20MB입니다.
- PDF 파일당 최대 15페이지
- 일괄 처리:
- PDF 파일의 최대 단일 파일 크기는 1GB입니다.
- PDF 파일당 최대 500페이지
파일 형식별 레이아웃 감지
다음 표에는 문서 파일 형식별로 레이아웃 파서가 감지할 수 있는 요소가 나와 있습니다.
| 파일 형식 | MIME 유형 | 감지된 요소 | 제한사항 |
|---|---|---|---|
| HTML | text/html |
단락, 표, 목록, 제목, 머리글, 페이지 머리글, 페이지 바닥글 | 파싱은 HTML 태그에 크게 의존하므로 CSS 기반 형식 은 캡처되지 않을 수 있습니다. |
application/pdf |
그림, 단락, 표, 제목, 머리글, 페이지 머리글, 페이지 바닥글 | 여러 페이지에 걸쳐 있는 표는 두 개의 표로 분할될 수 있습니다. | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
단락, 여러 페이지에 걸쳐 있는 표, 목록, 제목, 머리글 요소 | 중첩된 표는 지원되지 않습니다. |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
단락, 표, 목록, 제목, 머리글 요소 | 머리글이 정확하게 식별되려면 PowerPoint 파일 내에서 머리글로 표시되어야 합니다. 중첩된 표와 숨겨진 슬라이드는 지원되지 않습니다. |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
Excel 스프레드시트 내의 표로, INT,
FLOAT, and STRING 값을 지원합니다. |
여러 표 감지는 지원되지 않습니다. 숨겨진 시트, 행 또는 열도 감지에 영향을 미칠 수 있습니다. 최대 500만 개의 셀이 있는 파일을 처리할 수 있습니다. |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
매크로가 사용 설정된 스프레드시트로, INT,
FLOAT, 및 STRING 값을 지원합니다. |
여러 표 감지는 지원되지 않습니다. 숨겨진 시트, 행 또는 열도 감지에 영향을 미칠 수 있습니다. |
다음 단계
- 프로세서 목록을 검토합니다.
- 커스텀 분류기를 만듭니다.
- Enterprise Document OCR을 사용하여 텍스트를 감지하고 추출합니다.
- 응답을 처리하는 방법을 알아보려면 일괄 처리 문서 요청 전송 을 검토하세요.