
Gemini レイアウト パーサーでドキュメントを処理する
Document AI レイアウト パーサーは、高度なテキスト解析とドキュメント理解のサービスです。複雑なファイルから非構造化コンテンツを抽出して、高度に構造化された正確な機械可読情報に変換します。Google の特殊なオブジェクト文字認識(OCR)モデルと Gemini の生成 AI 機能を組み合わせています。ドキュメント全体の構造を理解し、表、図、リスト、ヘッダーなどの要素を識別しながら、段落がどの見出しに属するかなど、要素間のコンテキスト関係を維持します。
これは、検索と検索拡張生成(RAG)の重要な問題を解決するように設計されています。標準の OCR ではドキュメントがフラット化され、見出し、表、リストなど、価値のある意味を追加するコンテキストと構造が失われます。
主なユースケース:
- ドキュメント OCR: PDF ドキュメントから、見出し、ヘッダー、フッター、表構造、図などのテキストとレイアウト要素を解析できます。
- 高精度な検索と RAG: 主な用途は、検索と RAG パイプライン用のドキュメントを準備することです。コンテキストを認識するチャンクを作成することで、検索の品質と生成される回答の精度が大幅に向上します。
- 構造化データの取り込み: 複雑なドキュメント(10-K の提出書類 やレポートなど)を解析し、解析された表や画像の説明などの構造化コンテンツを データベースにインデックス登録できます。これはBigQueryで示されています。
仕組み
Gemini レイアウト パーサーは、意味を保持するように設計されたマルチステージ パイプラインでドキュメントを処理します。
- 解析と構造化: ドキュメントが取り込まれます。すべての要素が識別され、ツリー形式で整理されます。この
DocumentLayoutproto フィールド は、ドキュメントの固有の階層を保持します。 - アノテーションと音声化: プレビュー Gemini の生成機能を使用して、複雑な視覚 要素を音声化します。図、グラフ、表には、豊富なテキストの説明がアノテーションとして追加されます。
- チャンク化と拡張: 解析されたドキュメントとそのアノテーションを使用して、意味的に一貫性のあるチャンクを作成します。これらのチャンクには、祖先の見出しなどのコンテキスト情報が追加されます。これにより、チャンクが単独で取得された場合でも、チャンクの意味が保持されます。
プロセッサのバージョン
レイアウト パーサーでは、次のモデルを使用できます。モデル バージョンを変更するには、 プロセッサ バージョンを管理するをご覧ください。
デフォルトのプロセッサ割り当てに対する割り当て増加リクエスト(QIR)を行うには、 割り当てを管理するの手順に沿って操作してください。
| モデル バージョン | 説明 | リリース チャンネル | リリース日 |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
ドキュメント レイアウト分析の一般提供バージョン。これがデフォルトのトレーニング済みプロセッサ バージョンです。 | Stable | 2024 年 6 月 3 日 |
pretrained-layout-parser-v1.5-2025-08-25 |
Gemini 2.5 Flash LLM を活用したプレビュー バージョン。PDF ファイルのレイアウト分析が向上します。新しいバージョンを試したい方におすすめです。 | リリース候補 | 2025 年 8 月 25 日 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
Gemini 2.5 Pro LLM を活用したプレビュー バージョン。PDF ファイルのレイアウト分析が向上します。v1.5-pro は v1.5 よりもレイテンシが高くなります。 | リリース候補 | 2025 年 8 月 25 日 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
Gemini 3.0 Pro LLM を活用したプレビュー バージョン。 | リリース候補 | 2025 年 12 月 1 日 |
pretrained-layout-parser-v1.6-2026-01-13 |
Gemini 3.0 Flash LLM を活用したプレビュー バージョン。 | リリース候補 | 2026 年 1 月 13 日 |
主な機能
このドキュメントでは、Gemini レイアウト パーサーは、pretrained-layout-parser-v1.5-2025-08-25 や pretrained-layout-parser-v1.5-pro-2025-08-25 などの Gemini ベースのトレーニング済みレイアウト パーサー プロセッサ バージョンを指します。Gemini レイアウト パーサーは、次の主な機能をサポートしています。
高度なテーブル解析
財務レポートや技術マニュアルの表は、RAG の一般的な失敗点です。Gemini レイアウト パーサーは、結合されたセルと複雑なヘッダーを含む複雑な表からデータを抽出するのに優れています。
例: この Alphabet 10-K の提出書類では、競合他社のパーサーがヘッダーとセルを正しく配置できず、財務データを誤って解釈しています。Gemini レイアウト パーサーは、表構造全体を正確に解析し、データの整合性を維持します。
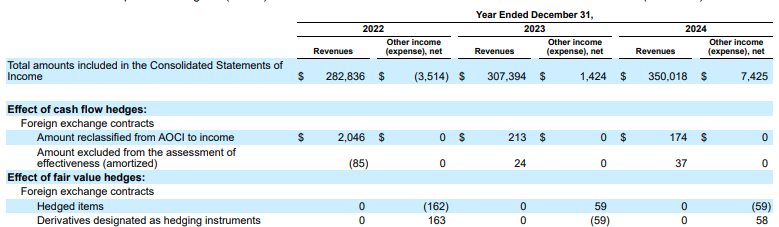
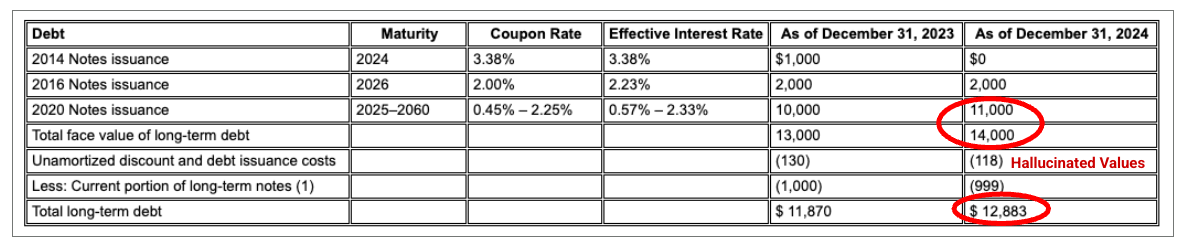
図 1.この入力ドキュメントのソースは、「Alphabet 2024 SEC Form 10-K」の 72 ページです。
競合他社のパーサーは、セルと列の配置を正しく検出せず、値をハルシネーションします。
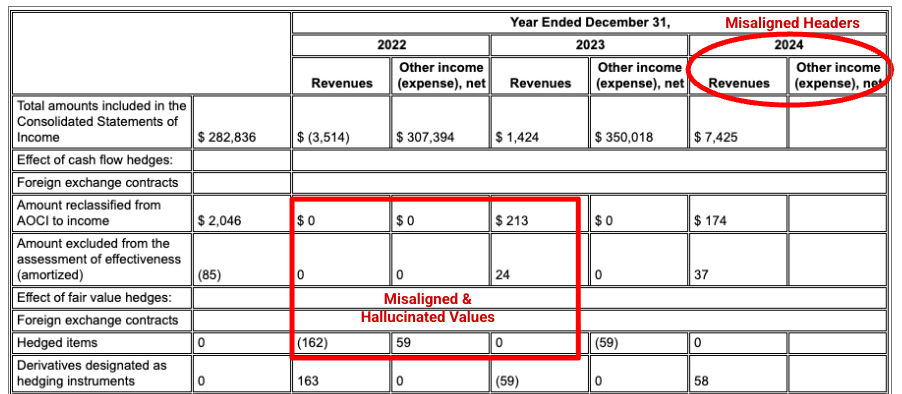
Gemini レイアウト パーサーは列を正しく配置し、正確な値を提供します。
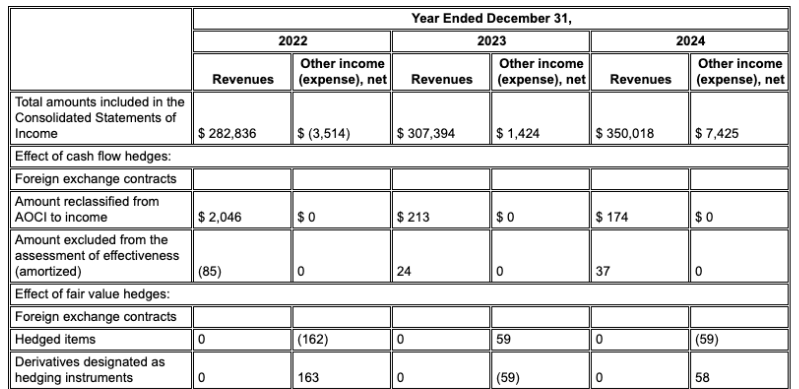
ハルシネーションの低減
存在しないテキストを読み取ろうとする純粋な LLM ベースのパーサーとは異なり、Gemini レイアウト パーサーは高度な OCR を基盤としているため、ドキュメントの実際のコンテンツに基づいています。これにより、ハルシネーションが大幅に減少します。
例: この 10-K の抜粋では、競合他社のモデルがハルシネーションし、誤ったテキストを挿入しています。Gemini レイアウト パーサーは、ページに存在するテキストのみを正確に抽出します。
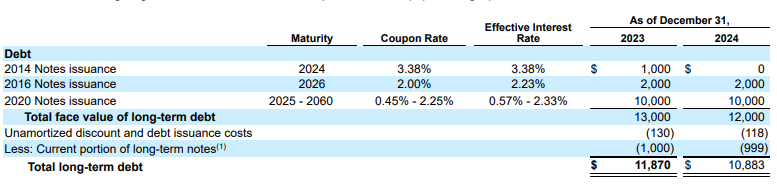
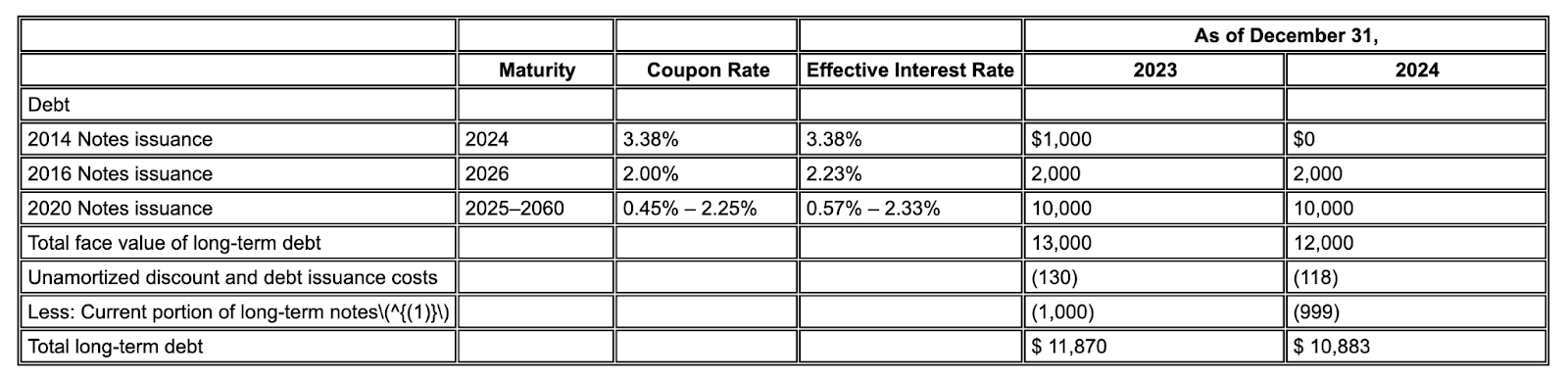
図 2.入力ドキュメント(Alphabet 2024 10k p75)
競合他社のモデルは値をハルシネーションします。
Gemini レイアウト パーサーは、画像と表の値を正しく識別します。
レイアウトを認識したチャンク化
標準のパーサーでは、元のコンテキストから削除されたチャンクが作成され、段落が見出しから分離されることがよくあります。Gemini レイアウト パーサーは、ドキュメントの階層を理解します。祖先の見出しと表ヘッダーのコンテンツを含む、コンテキストを認識するチャンクを作成します。取得されたチャンクには、テキストだけでなく、正確な LLM レスポンスに必要な構造コンテキストも含まれています。
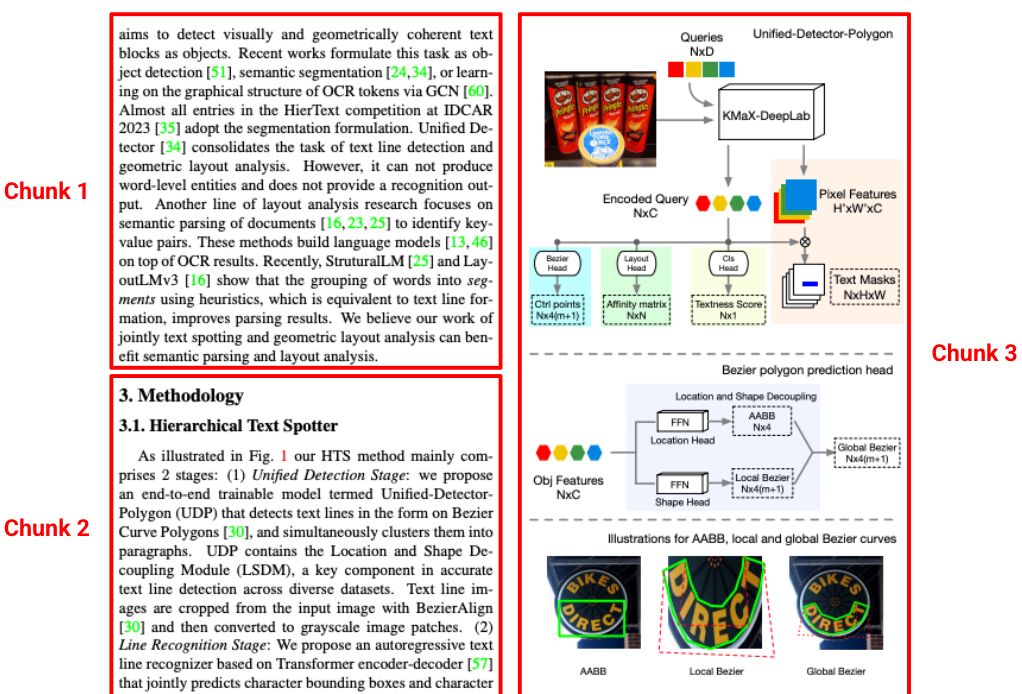
図 3.この画像の出典は、Shangbang Long、Siyang Qin、Yasuhisa Fujii、Alessandro Bissacco、Michalis Raptis による「Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis」です。
レイアウト アノテーション
レイアウト パーサーのアノテーションでは、解析されたドキュメントに画像や表が含まれているかどうかを識別できます。見つかった場合は、画像と表に示されている情報を含む説明テキスト ブロックとしてアノテーションが追加されます。
たとえば、銀行のレポートを処理する場合、パーサーは画像だけを認識しません。詳細な説明を生成し、3 つの円グラフすべてからデータポイントを抽出して、そのデータを取得できるようにします。
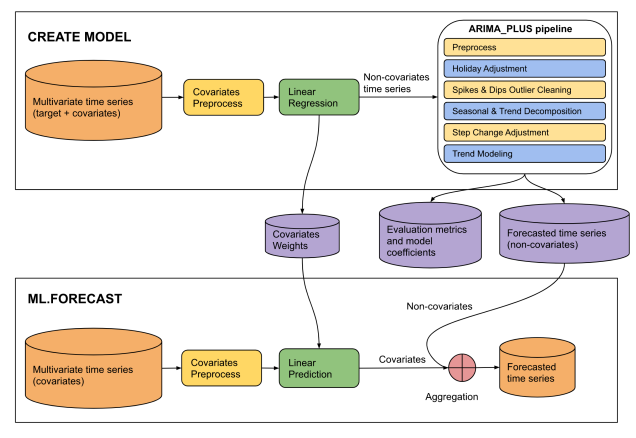
図 4.この入力のソースは、Google Cloud サイトの「ARIMA_PLUS_XREG モデルの CREATE MODEL ステートメント」の保存済み PDF です。
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
制限事項
次の制限が適用されます。
- オンライン処理:
- すべてのファイル形式で、入力ファイルの最大サイズは 20 MB
- PDF ファイルあたりの最大ページ数: 15
- バッチ処理:
- PDF ファイルの最大ファイルサイズ: 1 GB
- PDF ファイルあたりの最大ページ数: 500
ファイル形式ごとのレイアウト検出
次の表に、ドキュメントのファイル形式ごとにレイアウト パーサーが検出できる要素を示します。
| ファイル形式 | MIME タイプ | 検出された要素 | 制限事項 |
|---|---|---|---|
| HTML | text/html |
段落、表、リスト、タイトル、見出し、ページヘッダー、ページフッター | 解析は HTML タグに大きく依存するため、CSS ベースの書式設定 はキャプチャされない可能性があります。 |
application/pdf |
図、段落、表、タイトル、見出し、ページヘッダー、ページフッター | 複数ページにまたがる表は、2 つの表に分割されることがあります。 | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
段落、複数ページにまたがる表、リスト、タイトル、見出しの要素 | ネストされた表はサポートされていません。 |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
段落、表、リスト、タイトル、見出しの要素 | 見出しを正確に識別するには、PowerPoint ファイル内で見出しとしてマークする必要があります。 ネストされた表と非表示のスライドはサポートされていません。 |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
Excel スプレッドシート内の表(INT,
FLOAT, および STRING 値をサポート) |
複数の表の検出はサポートされていません。非表示のシート、行、列 も検出に影響する可能性があります。最大 500 万個のセルを含むファイルを処理できます。 |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
マクロが有効なスプレッドシート(INT
FLOAT、および STRING 値をサポート) |
複数の表の検出はサポートされていません。非表示のシート、行、列 も検出に影響する可能性があります。 |
次のステップ
- プロセッサ リストを確認します。
- カスタム分類子を作成します。
- Enterprise Document OCR を使用して、テキストを検出して抽出します。
- レスポンスの処理方法については、ドキュメントのバッチ処理リクエストを送信する をご覧ください。