
Elabora i documenti con l'analizzatore sintattico del layout di Gemini
Il parser del layout di Document AI è un servizio avanzato di analisi del testo e comprensione dei documenti che converte i contenuti non strutturati di file complessi in informazioni altamente strutturate, precise e leggibili dalla macchina. Combina i modelli di riconoscimento ottico dei caratteri (OCR) specializzati di Google con le funzionalità di AI generativa di Gemini. Comprende la struttura completa del documento, identificando elementi come tabelle, figure, elenchi e intestazioni, preservando le relazioni contestuali tra loro, ad esempio quali paragrafi appartengono a quale intestazione.
È progettato per risolvere un problema critico per la ricerca e la generazione aumentata del recupero (RAG): l'OCR standard appiattisce i documenti, distruggendo il contesto e la struttura che aggiungono significato prezioso, come intestazioni, tabelle ed elenchi.
Casi d'uso principali
- OCR del documento: può analizzare elementi di testo e layout come intestazione, piè di pagina, struttura della tabella e figure dai documenti PDF.
- Ricerca e RAG ad alta fedeltà: il suo utilizzo principale è preparare i documenti per le pipeline di ricerca e RAG. Creando blocchi sensibili al contesto, migliora notevolmente la qualità del recupero e l'accuratezza delle risposte generate.
- Importazione di dati strutturati:può analizzare documenti complessi (come i moduli 10-K o i report) e indicizzare contenuti strutturati (come tabelle analizzate o descrizioni di immagini) nei database, come dimostrato con BigQuery.
Come funziona
Il parser di layout di Gemini elabora i documenti in una pipeline a più fasi progettata per preservare il significato semantico:
- Analizza e struttura:il documento viene importato. Tutti gli elementi vengono identificati e
organizzati in una struttura ad albero. Questo
campo proto
DocumentLayoutmantiene la gerarchia intrinseca del documento. - Annota e verbalizza:anteprima Le funzionalità generative di Gemini vengono utilizzate per verbalizzare elementi visivi complessi. Figure, grafici e tabelle sono annotati con descrizioni testuali dettagliate.
- Chunk and Augment (Dividi e arricchisci):il documento analizzato e le relative annotazioni vengono utilizzati per creare chunk semanticamente coerenti. Questi blocchi vengono arricchiti con informazioni contestuali, come i titoli ancestrali, per garantire che il significato del blocco venga preservato anche quando viene recuperato in isolamento.
Versioni del processore
Per l'analizzatore del layout sono disponibili i seguenti modelli. Per modificare le versioni del modello, consulta Gestione delle versioni del processore.
Per inviare una richiesta di aumento della quota (QIR) per la quota predefinita del processore, segui i passaggi descritti in Gestire la quota.
| Versione del modello | Descrizione | Canale di rilascio | Data di uscita |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
Versione in disponibilità generale per l'analisi del layout dei documenti. Questa è la versione preaddestrata predefinita del processore. | Stabile | 3 giugno 2024 |
pretrained-layout-parser-v1.5-2025-08-25 |
Versione di anteprima basata sul modello LLM Gemini 2.5 Flash per una migliore analisi del layout dei file PDF. Consigliato per chi vuole sperimentare nuove versioni. | Candidato per la release | 25 agosto 2025 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
Versione di anteprima basata sul modello LLM Gemini 2.5 Pro per una migliore analisi del layout dei file PDF. La versione 1.5-pro ha una latenza superiore rispetto alla versione 1.5. | Candidato per la release | 25 agosto 2025 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
Versione di anteprima basata sul modello LLM Gemini 3.0 Pro. | Candidato per la release | 1° dicembre 2025 |
pretrained-layout-parser-v1.6-2026-01-13 |
Versione di anteprima basata sul modello LLM Gemini 3.0 Flash. | Candidato per la release | 13 gennaio 2026 |
Funzionalità chiave
In questa documentazione, l'analizzatore di layout Gemini
si riferisce alle versioni preaddestrate dell'analizzatore di layout basato su Gemini, come pretrained-layout-parser-v1.5-2025-08-25 e pretrained-layout-parser-v1.5-pro-2025-08-25. Il parser del layout di Gemini supporta le seguenti funzionalità chiave.
Analisi avanzata tabella
Le tabelle nei report finanziari o nei manuali tecnici sono un punto di errore comune per RAG. Gemini Layout Parser è ottimo per estrarre dati da tabelle complesse con celle unite e intestazioni intricate.
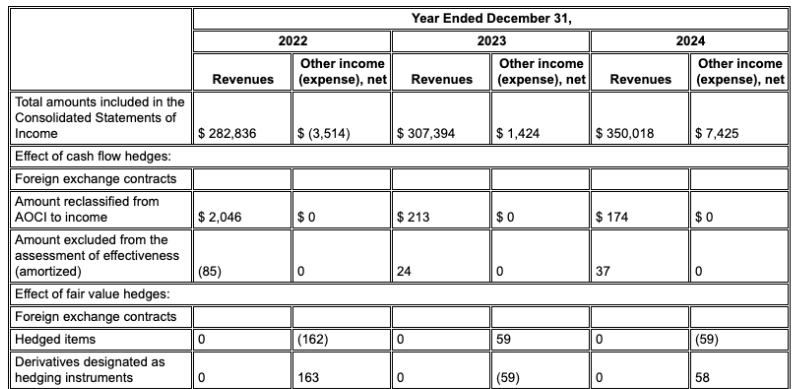
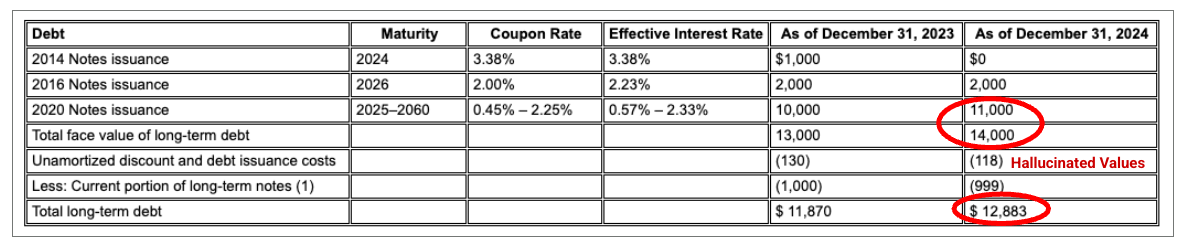
Esempio: in questo deposito del modulo 10-K di Alphabet, l'analizzatore di un concorrente non riesce ad allineare correttamente le intestazioni e le celle, interpretando in modo errato i dati finanziari. Il parser di layout di Gemini analizza con precisione l'intera struttura della tabella, preservando l'integrità dei dati.
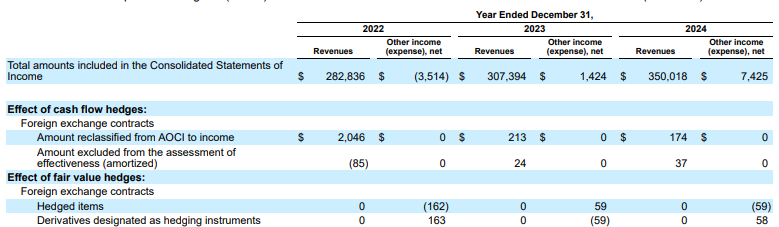
Figura 1. L'origine di questo documento di input è "Alphabet 2024 SEC Form 10-K", pagina 72.
Il parser dei concorrenti non rileva correttamente l'allineamento di celle e colonne e inventa valori.
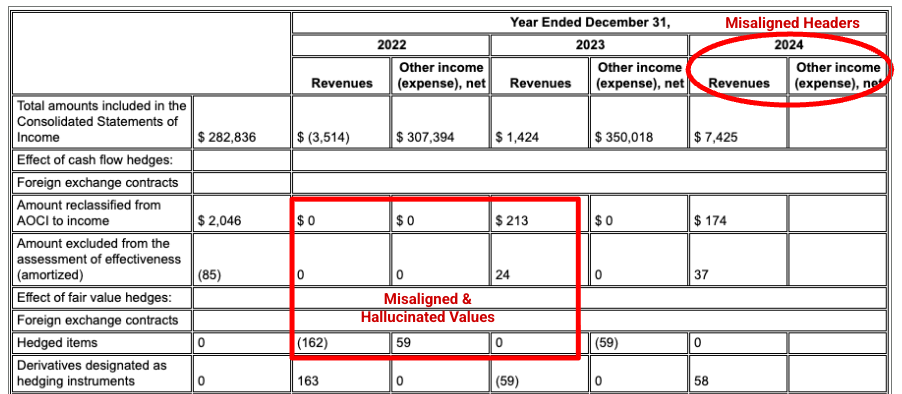
Il parser del layout di Gemini allinea correttamente le colonne e fornisce valori accurati.
Allucinazioni ridotte
A differenza dei parser basati su LLM puri che tentano di leggere un testo inesistente, il parser di layout di Gemini si basa su un OCR avanzato che lo ancora ai contenuti effettivi del documento. Ciò comporta un numero significativamente inferiore di allucinazioni.
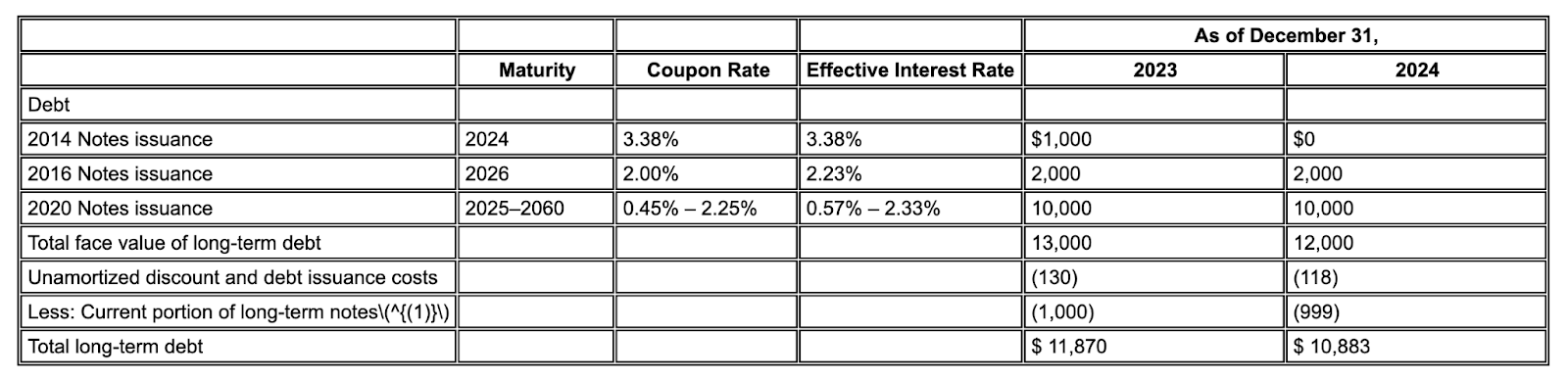
Esempio: in questo estratto del modulo 10-K, un modello concorrente ha allucinazioni e inserisce testo errato. Il parser del layout di Gemini fornisce un'estrazione pulita e accurata solo del testo presente nella pagina.
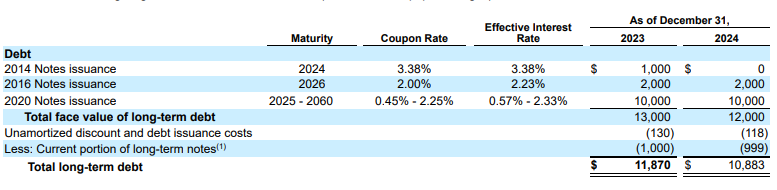
Figura 2. Documento di input (Alphabet 2024 10k p75)
I modelli concorrenti genereranno valori inventati.
Il parser del layout di Gemini identifica correttamente i valori in immagini e tabelle.
Segmentazione basata sul layout
I parser standard spesso creano blocchi rimossi dal loro contesto originale, separando un paragrafo dal relativo titolo. Il parser del layout di Gemini comprende la gerarchia del documento. Crea blocchi sensibili al contesto che includono contenuti di intestazioni e intestazioni di tabelle ancestrali. Un chunk recuperato contiene non solo il testo, ma anche il contesto strutturale necessario per una risposta accurata dell'LLM.
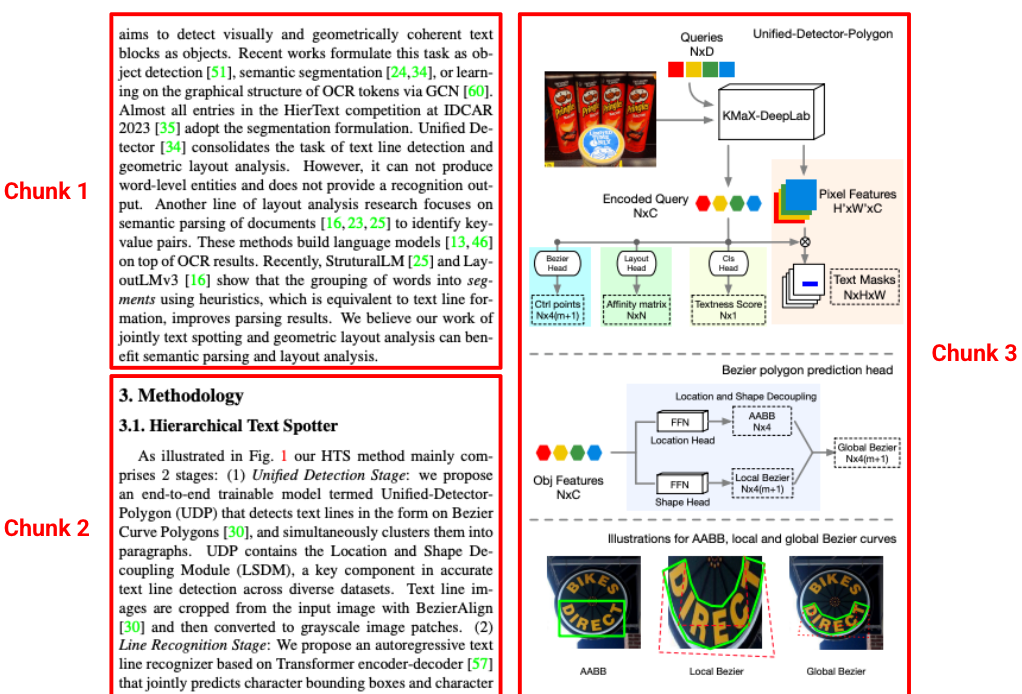
Figura 3. La fonte di questa immagine è "Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis", di Shangbang Long, Siyang Qin, Yasuhisa Fujii, Alessandro Bissacco e Michalis Raptis.
Annotazione del layout
L'annotazione del parser del layout può identificare se sono presenti immagini o tabelle nei documenti analizzati. Quando vengono trovati, vengono annotati come un blocco di testo descrittivo con le informazioni rappresentate nell'immagine e nella tabella.
Ad esempio, durante l'elaborazione di un estratto conto bancario, il parser non vede solo un'immagine. Genera una descrizione dettagliata ed estrae i punti dati da tutti e tre i grafici a torta, rendendo i dati disponibili per il recupero.
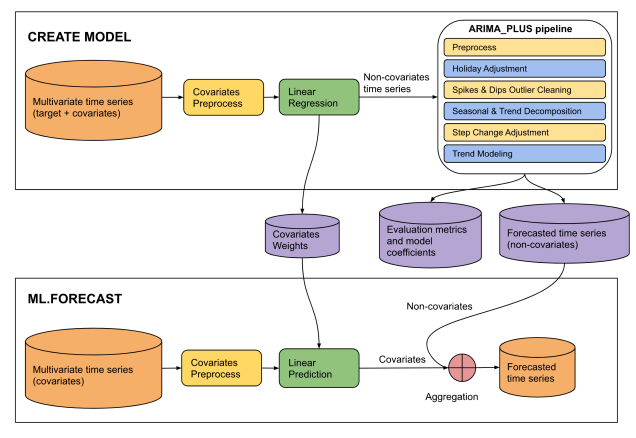
Immagine 4. L'origine di questo input è un PDF salvato di "Istruzione CREATE MODEL per i modelli ARIMA_ PLUS_XREG" sul sito di Google Cloud.
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
Limitazioni
Si applicano le seguenti limitazioni:
- Elaborazione online:
- Dimensione massima del file di input di 20 MB per tutti i tipi di file
- Massimo 15 pagine per file PDF
- Elaborazione batch:
- Dimensione massima di un singolo file di 1 GB per i file PDF
- Massimo 500 pagine per file PDF
Rilevamento del layout per tipo di file
La tabella seguente elenca gli elementi che il parser del layout può rilevare per tipo di file del documento.
| Tipo di file | Tipo MIME | Elementi rilevati | Limitazioni |
|---|---|---|---|
| HTML | text/html |
paragrafo, tabella, elenco, titolo, intestazione, intestazione di pagina, piè di pagina | Tieni presente che l'analisi si basa in gran parte sui tag HTML, pertanto la formattazione basata su CSS potrebbe non essere acquisita. |
application/pdf |
figura, paragrafo, tabella, titolo, intestazione, intestazione di pagina, piè di pagina | Le tabelle che si estendono su più pagine potrebbero essere divise in due tabelle. | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
paragrafo, tabelle su più pagine, elenco, titolo, elementi di intestazione | Le tabelle nidificate non sono supportate. |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
elementi paragrafo, tabella, elenco, titolo e intestazione | Affinché i titoli vengano identificati con precisione, devono essere contrassegnati come tali all'interno del file PowerPoint. Le tabelle nidificate e le slide nascoste non sono supportate. |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
tabelle all'interno dei fogli di lavoro Excel, che supportano i valori INT,
FLOAT e STRING |
Il rilevamento di più tabelle non è supportato. Anche i fogli, le righe o le colonne nascosti potrebbero influire sul rilevamento. È possibile elaborare file con un massimo di 5 milioni di celle. |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
foglio di lavoro con macro abilitata, che supporta i valori INT,
FLOAT e STRING |
Il rilevamento di più tabelle non è supportato. Anche i fogli, le righe o le colonne nascosti potrebbero influire sul rilevamento. |
Passaggi successivi
- Esamina l'elenco dei processori.
- Crea una categoria di classificazione personalizzata.
- Utilizza la funzionalità di Enterprise Document OCR per rilevare ed estrarre il testo.
- Consulta la sezione Inviare una richiesta di elaborazione batch dei documenti per scoprire come gestire le risposte.