
Memproses dokumen dengan parser tata letak Gemini
Parser tata letak Document AI adalah layanan pemahaman dokumen dan penguraian teks canggih yang mengonversi konten tidak terstruktur dari file kompleks menjadi informasi yang sangat terstruktur, akurat, dan dapat dibaca oleh mesin. Fitur ini menggabungkan model Pengenalan Karakter Objek (OCR) khusus Google dengan kemampuan AI generatif Gemini. Model ini memahami struktur dokumen lengkap, mengidentifikasi elemen seperti tabel, gambar, daftar, dan header sambil mempertahankan hubungan kontekstual di antara elemen tersebut, seperti paragraf mana yang termasuk dalam heading mana.
Model ini dirancang untuk memecahkan masalah penting bagi Penelusuran dan Retrieval-Augmented Generation (RAG): OCR standar meratakan dokumen, sehingga menghancurkan konteks dan struktur yang menambahkan makna berharga, seperti judul, tabel, dan daftar.
Kasus penggunaan utama
- OCR Dokumen: Layanan ini dapat mengurai teks dan elemen tata letak seperti judul, header, footer, struktur tabel, dan gambar dari dokumen PDF.
- Penelusuran & RAG dengan Akurasi Tinggi: Penggunaan utamanya adalah untuk menyiapkan dokumen bagi pipeline Penelusuran dan RAG. Dengan membuat potongan yang sadar konteks, kualitas pengambilan dan akurasi jawaban yang dihasilkan akan meningkat secara signifikan.
- Penyerapan Data Terstruktur: Layanan ini dapat mengurai dokumen kompleks (seperti pengajuan atau laporan 10-K) dan mengindeks konten terstruktur (seperti tabel yang diurai atau deskripsi gambar) ke dalam database, seperti yang ditunjukkan dengan BigQuery.
Cara Kerjanya
Pengurai tata letak Gemini memproses dokumen dalam pipeline multi-tahap yang dirancang untuk mempertahankan makna semantik:
- Mengurai dan Menyusun: Dokumen dimasukkan. Semua elemen diidentifikasi dan disusun dalam format pohon. Kolom proto
DocumentLayoutini mempertahankan hierarki inheren dokumen. - Anotasi dan Verbalisasi: Pratinjau Kemampuan generatif Gemini digunakan untuk memverbalisasi elemen visual yang kompleks. Gambar, diagram, dan tabel diberi anotasi dengan deskripsi tekstual yang lengkap.
- Potong dan Tingkatkan Kualitas: Dokumen yang diuraikan dan anotasinya digunakan untuk membuat potongan yang koheren secara semantik. Potongan ini dilengkapi dengan informasi kontekstual, seperti judul leluhur, untuk memastikan makna potongan tetap dipertahankan meskipun diambil secara terpisah.
Versi pemroses
Model berikut tersedia untuk parser tata letak. Untuk mengubah versi model, lihat Mengelola versi pemroses.
Untuk membuat permintaan penambahan kuota (QIR) untuk kuota prosesor default, ikuti langkah-langkah di Mengelola kuota Anda.
| Versi model | Deskripsi | Saluran rilis | Tanggal rilis |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
Versi ketersediaan umum untuk analisis tata letak dokumen. Ini adalah versi pemroses terlatih sebelumnya default. | Stabil | 3 Juni 2024 |
pretrained-layout-parser-v1.5-2025-08-25 |
Versi pratinjau yang didukung oleh LLM Gemini 2.5 Flash untuk analisis tata letak yang lebih baik pada file PDF. Direkomendasikan bagi mereka yang ingin bereksperimen dengan versi baru. | Kandidat Rilis | 25 Agustus 2025 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
Versi pratinjau yang didukung oleh LLM Gemini 2.5 Pro untuk analisis tata letak yang lebih baik pada file PDF. v1.5-pro memiliki latensi yang lebih tinggi daripada v1.5. | Kandidat Rilis | 25 Agustus 2025 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
Versi pratinjau yang didukung oleh LLM Gemini 3.0 Pro. | Kandidat Rilis | 1 Desember 2025 |
pretrained-layout-parser-v1.6-2026-01-13 |
Versi pratinjau yang didukung oleh LLM Gemini 3.0 Flash. | Kandidat Rilis | 13 Januari 2026 |
Kemampuan utama
Selanjutnya dalam dokumentasi ini, parser tata letak Gemini mengacu pada versi prosesor parser tata letak yang telah dilatih sebelumnya berbasis Gemini, seperti pretrained-layout-parser-v1.5-2025-08-25 dan pretrained-layout-parser-v1.5-pro-2025-08-25. Pengurai tata letak Gemini mendukung kemampuan utama berikut.
Penguraian tabel lanjutan
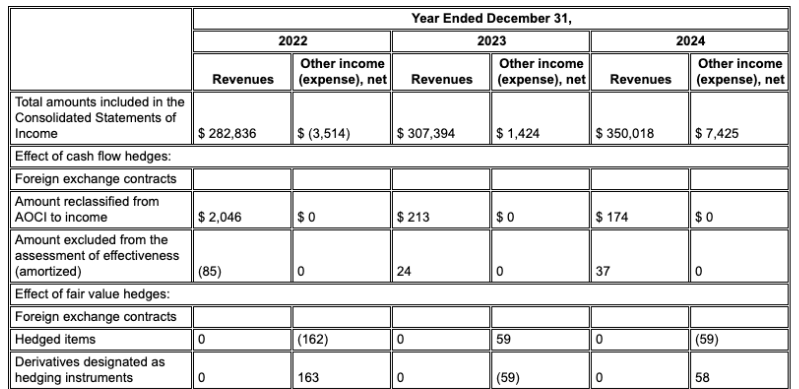
Tabel dalam laporan keuangan atau panduan teknis adalah titik kegagalan umum untuk RAG. Pengurai tata letak Gemini unggul dalam mengekstrak data dari tabel kompleks dengan sel gabungan dan header yang rumit.
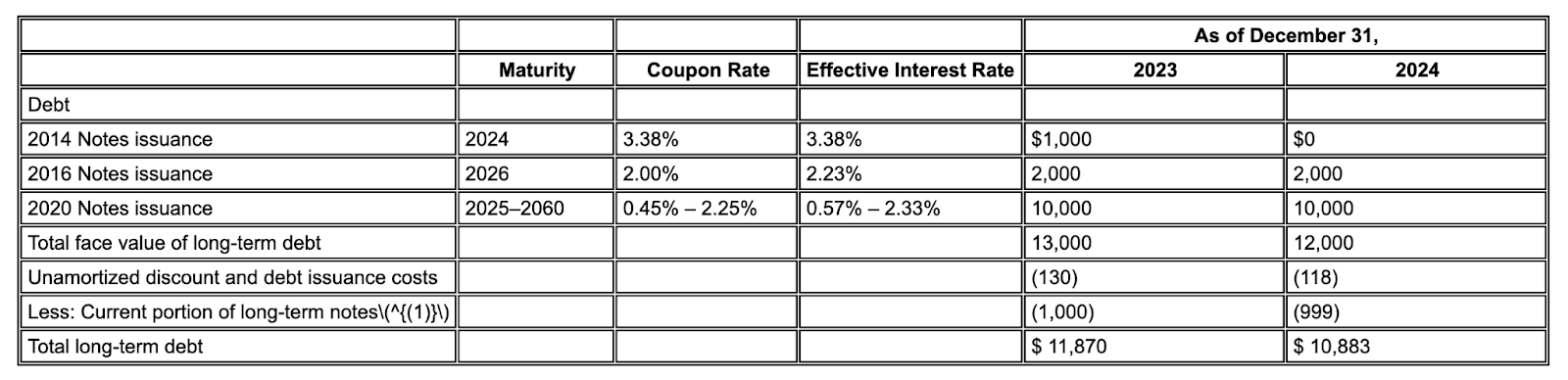
Contoh: Dalam pengajuan 10-K Alphabet ini, parser pesaing gagal menyelaraskan header dan sel dengan benar, sehingga salah menafsirkan data keuangan. Pengurai tata letak Gemini mengurai seluruh struktur tabel secara akurat, sehingga menjaga integritas data.
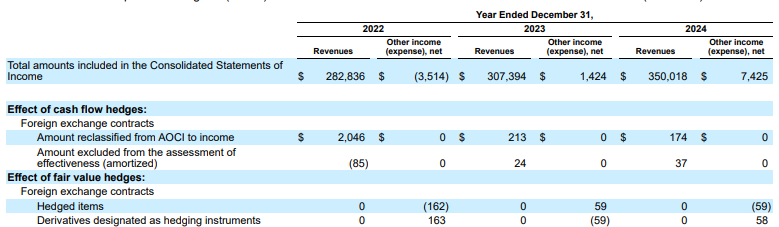
Gambar 1. Sumber dokumen input ini adalah "Alphabet 2024 SEC Form 10-K", halaman 72.
Pengurai data pesaing tidak mendeteksi dengan benar perataan sel dan kolom serta membuat nilai halusinasi.
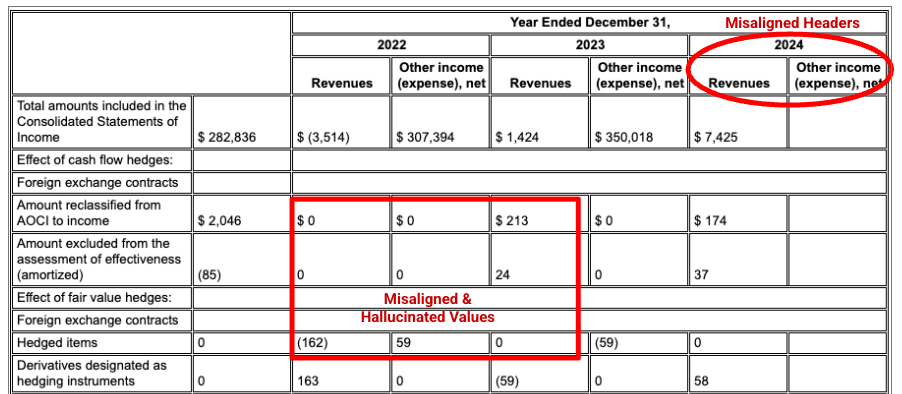
Parser tata letak Gemini menyelaraskan kolom dengan benar, dan memberikan nilai yang akurat.
Halusinasi berkurang
Tidak seperti parser berbasis LLM murni yang mencoba membaca teks yang tidak ada, parser tata letak Gemini yang didasarkan pada OCR canggih memungkinkannya memahami konten dokumen yang sebenarnya. Hal ini menghasilkan halusinasi yang jauh lebih sedikit.
Contoh: Dalam kutipan 10-K ini, model pesaing berhalusinasi dan menyisipkan teks yang salah. Pengurai tata letak Gemini memberikan ekstraksi yang bersih dan akurat hanya untuk teks yang ada di halaman.
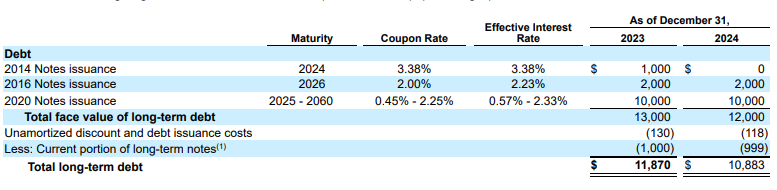
Gambar 2. Dokumen Input (Alphabet 2024 10k p75)
Model pesaing akan berhalusinasi nilai.
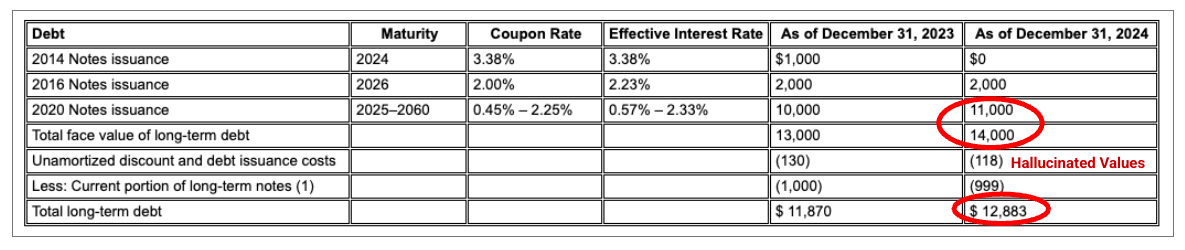
Pengurai tata letak Gemini mengidentifikasi nilai dalam gambar dan tabel dengan benar.
Pengelompokan sesuai tata letak
Parser standar sering kali membuat potongan yang dihapus dari konteks aslinya, memisahkan paragraf dari judulnya. Parser tata letak Gemini memahami hierarki dokumen. Fitur ini membuat potongan kontekstual yang menyertakan konten dari judul induk dan header tabel. Chunk yang diambil tidak hanya berisi teks, tetapi juga konteks struktural yang diperlukan untuk respons LLM yang akurat.
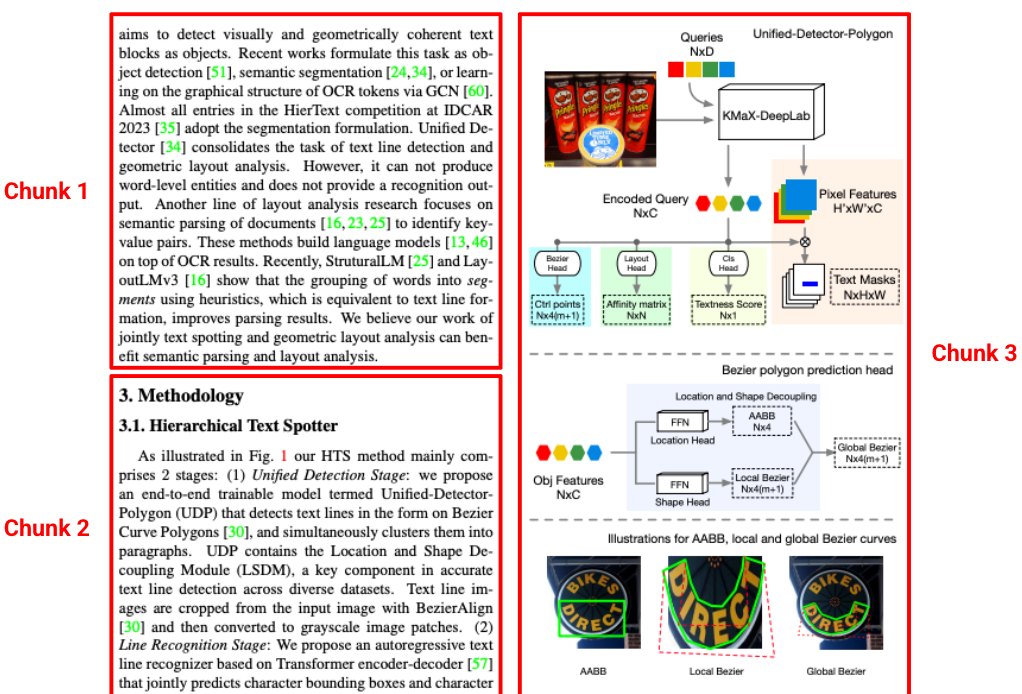
Gambar 3. Sumber gambar ini berasal dari "Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis", oleh Shangbang Long, Siyang Qin, Yasuhisa Fujii, Alessandro Bissacco, dan Michalis Raptis.
Anotasi tata letak
Anotasi parser tata letak dapat mengidentifikasi apakah ada gambar atau tabel dalam dokumen yang di-parse. Jika ditemukan, teks tersebut akan diberi anotasi sebagai blok teks deskriptif dengan informasi yang digambarkan dalam gambar dan tabel.
Misalnya, saat memproses laporan bank, parser tidak hanya melihat gambar. Langkah ini akan menghasilkan deskripsi mendetail dan mengekstrak titik data dari ketiga diagram lingkaran, sehingga data tersebut tersedia untuk diambil.
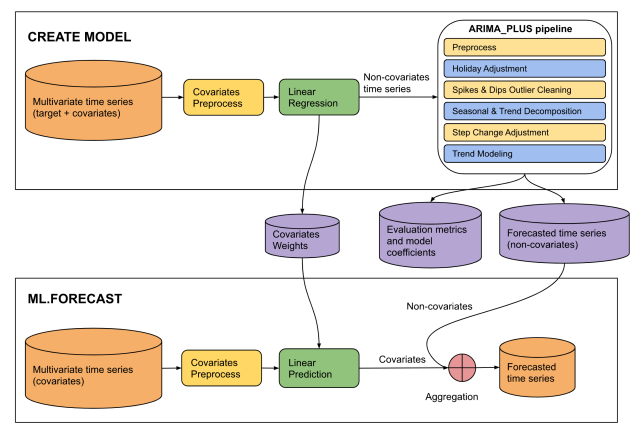
Gambar 4. Sumber input ini adalah PDF tersimpan dari "Pernyataan CREATE MODEL untuk model ARIMA_ PLUS_XREG" di situs Google Cloud.
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
Batasan
Batasan berikut berlaku:
- Pemrosesan online:
- Ukuran file input maksimum 20 MB untuk semua jenis file
- Maksimum 15 halaman per file PDF
- Batch processing:
- Ukuran file tunggal maksimum 1 GB untuk file PDF
- Maksimum 500 halaman per file PDF
Deteksi tata letak per jenis file
Tabel berikut mencantumkan elemen yang dapat dideteksi parser tata letak per jenis file dokumen.
| Jenis file | Jenis MIME | Elemen yang terdeteksi | Batasan |
|---|---|---|---|
| HTML | text/html |
paragraf, tabel, daftar, judul, heading, header halaman, footer halaman | Perhatikan bahwa penguraian sangat bergantung pada tag HTML, sehingga pemformatan berbasis CSS mungkin tidak tercakup. |
application/pdf |
gambar, paragraf, tabel, judul, heading, header halaman, footer halaman | Tabel yang mencakup beberapa halaman dapat dibagi menjadi dua tabel. | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
paragraf, tabel di beberapa halaman, daftar, judul, elemen heading | Tabel bertingkat tidak didukung. |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
paragraf, tabel, daftar, judul, elemen heading | Agar judul dapat diidentifikasi secara akurat, judul harus ditandai sebagai judul dalam file PowerPoint. Tabel bertingkat dan slide tersembunyi tidak didukung. |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
tabel dalam spreadsheet Excel, yang mendukung nilai INT,
FLOAT, dan STRING |
Deteksi beberapa tabel tidak didukung. Sheet, baris, atau kolom yang tersembunyi juga dapat memengaruhi deteksi. File dengan hingga 5 juta sel dapat diproses. |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
spreadsheet dengan makro diaktifkan, yang mendukung nilai INT,
FLOAT, dan STRING |
Deteksi beberapa tabel tidak didukung. Sheet, baris, atau kolom yang tersembunyi juga dapat memengaruhi deteksi. |
Langkah berikutnya
- Tinjau daftar pemroses.
- Buat pengklasifikasi kustom.
- Gunakan Enterprise Document OCR untuk mendeteksi dan mengekstrak teks.
- Tinjau Mengirim permintaan dokumen batch processing untuk mempelajari cara menangani respons.