
Procesa documentos con el analizador de diseño de Gemini
El analizador de diseño de Document AI es un servicio avanzado de análisis de texto y comprensión de documentos que convierte el contenido no estructurado de archivos complejos en información altamente estructurada, precisa y legible por máquina. Combina los modelos especializados de reconocimiento óptico de caracteres (OCR) de Google con las capacidades de IA generativa de Gemini. Comprende la estructura completa del documento y, al mismo tiempo, identifica elementos como tablas, figuras, listas y encabezados, y conserva las relaciones contextuales entre ellos, como qué párrafos pertenecen a qué encabezado.
Está diseñado para resolver un problema fundamental para la búsqueda y la generación aumentada por recuperación (RAG): el OCR estándar aplana los documentos y destruye el contexto y la estructura que agregan significado valioso, como encabezados, tablas y listas.
Casos de uso principales
- OCR de documentos: Puede analizar texto y elementos de diseño, como encabezados, pies de página, estructura de tablas y figuras de documentos PDF.
- Búsqueda y RAG de alta fidelidad: Su uso principal es preparar documentos para las canalizaciones de búsqueda y RAG. Al crear fragmentos sensibles al contexto, mejora significativamente la calidad de la recuperación y la exactitud de las respuestas generadas.
- Ingestión de datos estructurados: Puede analizar documentos complejos (como informes o presentaciones 10-K o informes) y, luego, indexar contenido estructurado (como tablas analizadas o descripciones de imágenes) en bases de datos, como se muestra con BigQuery.
Cómo funciona
El analizador de diseño de Gemini procesa documentos en una canalización de varias etapas diseñada para preservar el significado semántico:
- Análisis y estructura: Se ingiere el documento. Todos los elementos se identifican y organizan en un formato de árbol. Este
DocumentLayoutcampo proto conserva la jerarquía inherente del documento. - Anotación y verbalización: Se usa la vista previa de las capacidades generativas de Gemini para verbalizar elementos visuales complejos. Las figuras, los gráficos y las tablas se anotan con descripciones textuales enriquecidas.
- Fragmentación y aumento: El documento analizado y sus anotaciones se usan para crear fragmentos semánticamente coherentes. Estos fragmentos se aumentan con información contextual, como sus encabezados ancestrales, para garantizar que se conserve el significado del fragmento, incluso cuando se recupera de forma aislada.
Versiones del procesador
Los siguientes modelos están disponibles para el analizador de diseño. Para cambiar las versiones del modelo, consulta Administra versiones de procesadores.
Para realizar una solicitud de aumento de cuota (QIR) para la cuota predeterminada de procesadores, sigue los pasos que se indican en Administra tu cuota.
| Versión del modelo | Descripción | Canal de versiones | Fecha de lanzamiento |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
Versión de disponibilidad general para el análisis de diseño de documentos. Esta es la versión predeterminada del procesador previamente entrenado. | Estable | 3 de junio de 2024 |
pretrained-layout-parser-v1.5-2025-08-25 |
Versión preliminar potenciada por el LLM de Gemini 2.5 Flash para un mejor análisis de diseño en archivos PDF. Se recomienda para quienes desean experimentar con versiones nuevas. | Versión candidata para lanzamiento | 25 de agosto de 2025 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
Versión preliminar potenciada por el LLM de Gemini 2.5 Pro para un mejor análisis de diseño en archivos PDF. La versión 1.5-pro tiene una latencia más alta que la versión 1.5. | Versión candidata para lanzamiento | 25 de agosto de 2025 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
Versión preliminar potenciada por el LLM de Gemini 3.0 Pro. | Versión candidata para lanzamiento | 1 de diciembre de 2025 |
pretrained-layout-parser-v1.6-2026-01-13 |
Versión preliminar potenciada por el LLM de Gemini 3.0 Flash. | Versión candidata para lanzamiento | 13 de enero de 2026 |
Funciones clave
En adelante, en esta documentación, el analizador de diseño de Gemini se refiere a las versiones del procesador del analizador de diseño previamente entrenado basado en Gemini, como pretrained-layout-parser-v1.5-2025-08-25 y pretrained-layout-parser-v1.5-pro-2025-08-25. El analizador de diseño de Gemini admite las siguientes funciones clave.
Análisis avanzado de tablas
Las tablas en informes financieros o manuales técnicos son un punto de falla común para RAG. El analizador de diseño de Gemini se destaca en la extracción de datos de tablas complejas con celdas combinadas y encabezados intrincados.
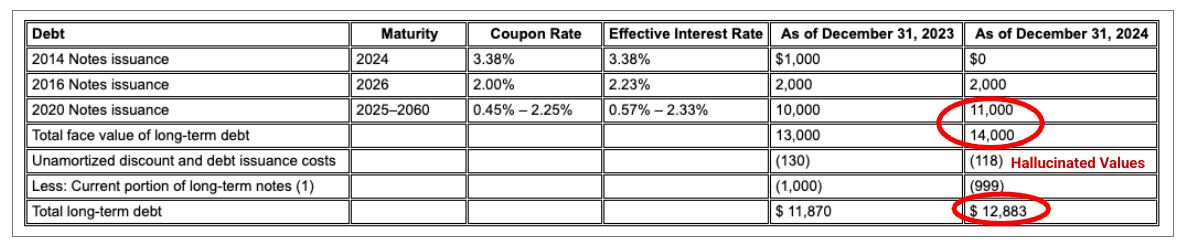
Ejemplo: En esta presentación 10-K de Alphabet, el analizador de un competidor no alinea correctamente los encabezados y las celdas, lo que malinterpreta los datos financieros. El analizador de diseño de Gemini analiza con precisión toda la estructura de la tabla y conserva la integridad de los datos.
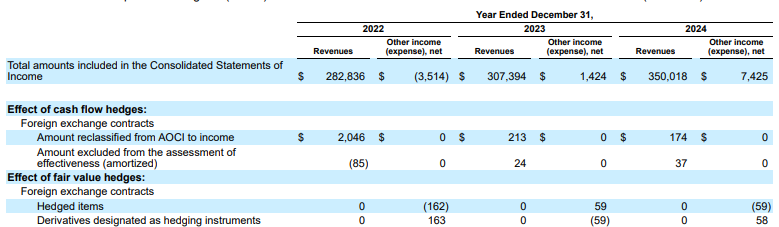
Figura 1. La fuente de este documento de entrada es "Alphabet 2024 SEC Form 10-K", página 72.
El analizador de la competencia no detecta correctamente la alineación de celdas y columnas, y alucina valores.
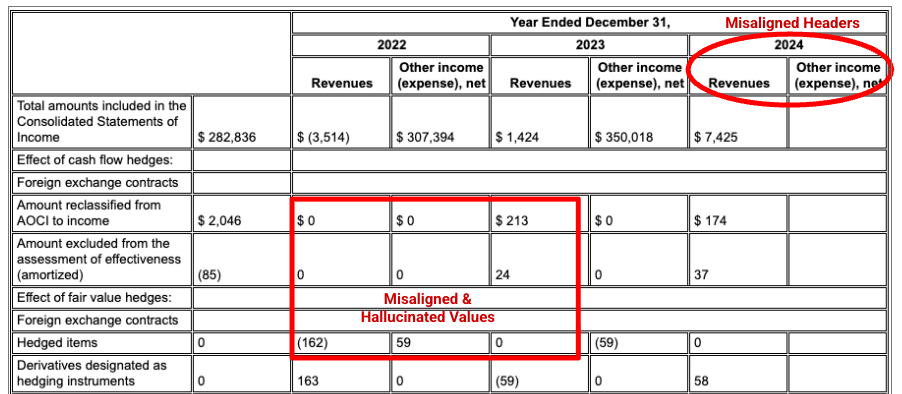
El analizador de diseño de Gemini alinea las columnas correctamente y proporciona valores precisos.
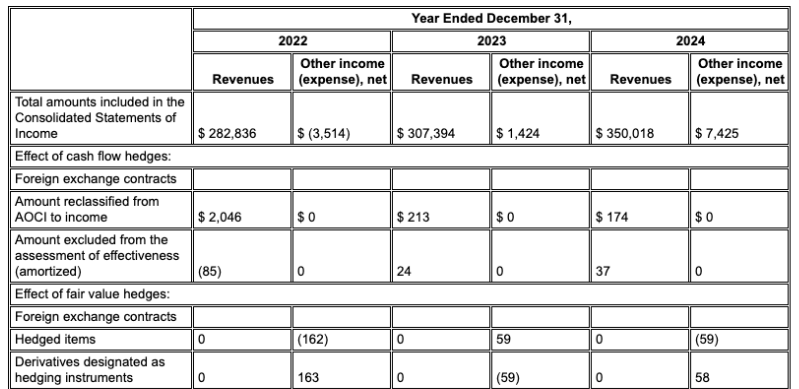
Alucinaciones reducidas
A diferencia de los analizadores basados en LLM puros que intentan leer texto que no está allí, la base del analizador de diseño de Gemini en OCR avanzado lo fundamenta en el contenido real del documento. Esto genera muchas menos alucinaciones.
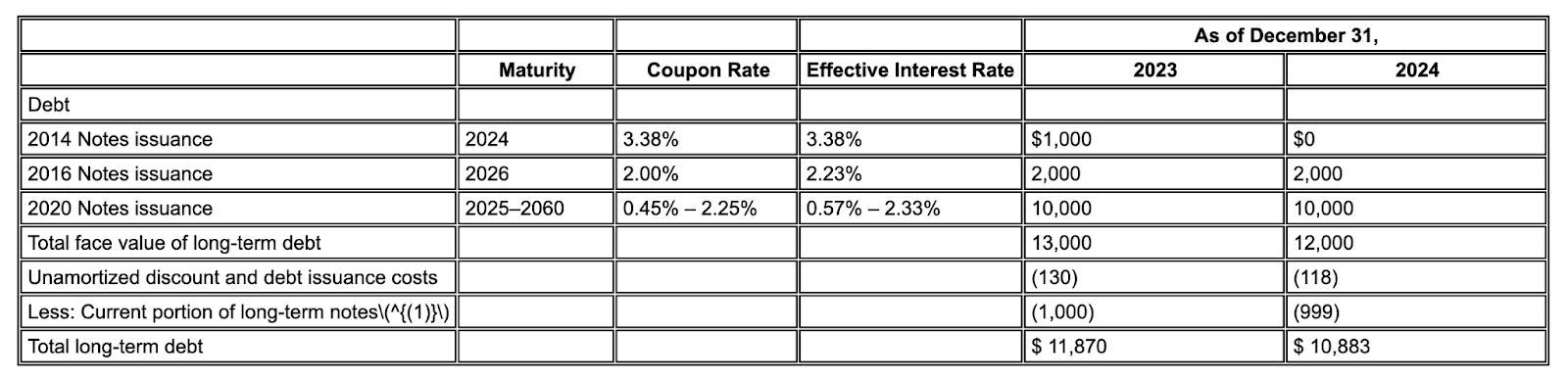
Ejemplo: En este fragmento de 10-K, un modelo de la competencia alucina e inserta texto incorrecto. El analizador de diseño de Gemini proporciona una extracción limpia y precisa de solo el texto presente en la página.
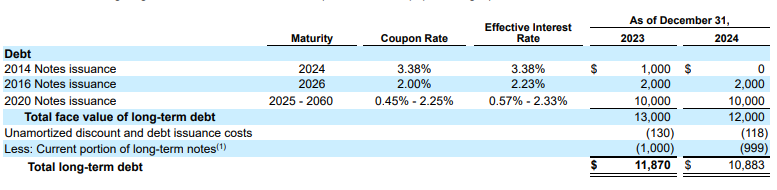
Figura 2. Documento de entrada (Alphabet 2024 10k p75)
Los modelos de la competencia alucinarán valores.
El analizador de diseño de Gemini identifica correctamente los valores en imágenes y tablas.
Fragmentación sensible al diseño
Los analizadores estándar suelen crear fragmentos que se quitan de su contexto original, separando un párrafo de su encabezado. El analizador de diseño de Gemini comprende la jerarquía del documento. Crea fragmentos sensibles al contexto que incluyen contenido de encabezados ancestrales y encabezados de tablas. Un fragmento recuperado no solo contiene el texto, sino también el contexto estructural necesario para una respuesta precisa del LLM.
Figura 3. La fuente de esta imagen es "Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis", de Shangbang Long, Siyang Qin, Yasuhisa Fujii, Alessandro Bissacco y Michalis Raptis.
Anotación de diseño
La anotación del analizador de diseño puede identificar si hay imágenes o tablas en los documentos analizados. Cuando se encuentran, se anotan como un bloque de texto descriptivo con la información que se muestra en la imagen y la tabla.
Por ejemplo, cuando se procesa un informe bancario, el analizador no solo ve una imagen. Genera una descripción detallada y extrae los puntos de datos de los tres gráficos circulares, lo que hace que esos datos estén disponibles para su recuperación.
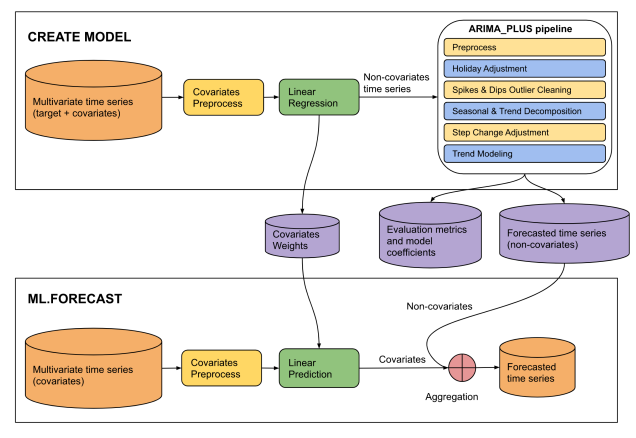
Figura 4. La fuente de esta entrada es un PDF guardado de "The CREATE MODEL statement for ARIMA_ PLUS_XREG models" en el sitio de Google Cloud.
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
Limitaciones
Se aplica la siguiente limitación:
- Procesamiento en línea:
- Tamaño máximo del archivo de entrada de 20 MB para todos los tipos de archivos
- Máximo de 15 páginas por archivo PDF
- Procesamiento por lotes:
- Tamaño máximo de un solo archivo de 1 GB para archivos PDF
- Máximo de 500 páginas por archivo PDF
Detección de diseño por tipo de archivo
En la siguiente tabla, se enumeran los elementos que el analizador de diseño puede detectar por tipo de archivo de documento.
| Tipo de archivo | Tipo MIME | Elementos detectados | Limitaciones |
|---|---|---|---|
| HTML | text/html |
párrafo, tabla, lista, título, encabezado, encabezado de página, pie de página | Ten en cuenta que el análisis depende en gran medida de las etiquetas HTML, por lo que es posible que no se capture el formato basado en CSS. |
application/pdf |
figura, párrafo, tabla, título, encabezado, encabezado de página, pie de página | Las tablas que abarcan varias páginas pueden dividirse en dos tablas. | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
párrafo, tablas en varias páginas, lista, título, elementos de encabezado | Las tablas anidadas no son compatibles. |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
párrafo, tabla, lista, título, elementos de encabezado | Para que los encabezados se identifiquen con precisión, deben marcarse como tales en el archivo de PowerPoint. Las tablas anidadas y las diapositivas ocultas no son compatibles. |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
tablas dentro de hojas de cálculo de Excel, que admiten valores INT,
FLOAT, y STRING |
No se admite la detección de varias tablas. Las hojas, filas o columnas ocultas también pueden afectar la detección. Se pueden procesar archivos con hasta 5 millones de celdas. |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
hoja de cálculo con macro habilitada, que admite valores INT,
FLOAT, y STRING |
No se admite la detección de varias tablas. Las hojas, filas o columnas ocultas también pueden afectar la detección. |
¿Qué sigue?
- Revisa la lista de procesadores.
- Crea un clasificador personalizado.
- Usa el Enterprise Document OCR para detectar y extraer texto.
- Consulta Envía una solicitud de procesamiento por lotes de documentos para obtener información sobre cómo controlar las respuestas.