
Dokumente mit dem Gemini-Layoutparser verarbeiten
Der Document AI-Layoutparser ist ein fortschrittlicher Dienst zum Parsen von Text und zum Verständnis von Dokumenten, der unstrukturierte Inhalte aus komplexen Dateien in hochstrukturierte, präzise und maschinenlesbare Informationen umwandelt. Es kombiniert die speziellen Modelle zur optischen Zeichenerkennung (OCR) von Google mit den generativen KI-Funktionen von Gemini. Er versteht die vollständige Dokumentstruktur und identifiziert Elemente wie Tabellen, Abbildungen, Listen und Überschriften, wobei die kontextuellen Beziehungen zwischen ihnen erhalten bleiben, z. B. welche Absätze zu welcher Überschrift gehören.
Sie wurde entwickelt, um ein kritisches Problem für die Suche und Retrieval Augmented Generation (RAG) zu lösen: Die Standard-OCR flacht Dokumente ab und zerstört den Kontext und die Struktur, die wertvolle Informationen wie Überschriften, Tabellen und Listen liefern.
Primäre Anwendungsfälle
- Document OCR:Text- und Layoutelemente wie Überschriften, Kopf- und Fußzeilen, Tabellenstrukturen und Abbildungen können aus PDF-Dokumenten geparst werden.
- High-Fidelity Search & RAG:Die primäre Verwendung besteht darin, Dokumente für Such- und RAG-Pipelines vorzubereiten. Durch das Erstellen kontextbezogener Chunks wird die Qualität des Abrufs und die Genauigkeit der generierten Antworten erheblich verbessert.
- Aufnahme strukturierter Daten:Das Tool kann komplexe Dokumente (z. B. 10-K-Einreichungen oder Berichte) parsen und strukturierte Inhalte (z. B. geparste Tabellen oder Bildbeschreibungen) in Datenbanken indexieren, wie mit BigQuery demonstriert.
So funktioniert's
Der Gemini-Layoutparser verarbeitet Dokumente in einer mehrstufigen Pipeline, die darauf ausgelegt ist, die semantische Bedeutung beizubehalten:
- Parsen und Strukturieren:Das Dokument wird aufgenommen. Alle Elemente werden identifiziert und in einem Baumformat organisiert. Mit diesem
DocumentLayout-Protofeld wird die inhärente Hierarchie des Dokuments beibehalten. - Anmerkungen und Verbalisierung:Vorabversion Die generativen Funktionen von Gemini werden verwendet, um komplexe visuelle Elemente zu verbalisieren. Abbildungen, Diagramme und Tabellen werden mit ausführlichen Textbeschreibungen versehen.
- Chunking und Augmentierung:Das geparste Dokument und seine Anmerkungen werden verwendet, um semantisch zusammenhängende Chunks zu erstellen. Diese Chunks werden mit Kontextinformationen wie den übergeordneten Überschriften angereichert, damit die Bedeutung des Chunks auch dann erhalten bleibt, wenn er isoliert abgerufen wird.
Prozessorversionen
Für den Layout-Parser sind die folgenden Modelle verfügbar. Informationen zum Ändern von Modellversionen finden Sie unter Prozessorversionen verwalten.
Wenn Sie eine Anfrage zur Kontingenterhöhung für das Standardkontingent für Prozessoren stellen möchten, folgen Sie der Anleitung unter Kontingent verwalten.
| Modellversion | Beschreibung | Release-Version | Releasedatum |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
Version mit allgemeiner Verfügbarkeit für die Analyse des Dokumentlayouts. Dies ist die Standardversion des vortrainierten Prozessors. | Stabil | 3. Juni 2024 |
pretrained-layout-parser-v1.5-2025-08-25 |
Die Vorschauversion basiert auf dem Gemini 2.5 Flash LLM und bietet eine verbesserte Layoutanalyse von PDF-Dateien. Empfohlen für Nutzer, die neue Versionen ausprobieren möchten. | Releasekandidat | 25. August 2025 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
Die Vorschauversion basiert auf dem Gemini 2.5 Pro-LLM und bietet eine bessere Layoutanalyse von PDF-Dateien. Die Latenz von v1.5-pro ist höher als die von v1.5. | Releasekandidat | 25. August 2025 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
Vorschauversion, die auf dem Gemini 3.0 Pro-LLM basiert. | Releasekandidat | 1. Dezember 2025 |
pretrained-layout-parser-v1.6-2026-01-13 |
Vorabversion, die auf dem LLM Gemini 3.0 Flash basiert. | Releasekandidat | 13. Januar 2026 |
Hauptmerkmale
Im weiteren Verlauf dieser Dokumentation bezieht sich „Gemini-Layoutparser“ auf vortrainierte Layoutparser-Prozessorversionen, die auf Gemini basieren, z. B. pretrained-layout-parser-v1.5-2025-08-25 und pretrained-layout-parser-v1.5-pro-2025-08-25. Der Gemini-Layoutparser unterstützt die folgenden wichtigen Funktionen.
Erweitertes Parsen von Tabellen
Tabellen in Finanzberichten oder technischen Handbüchern sind ein häufiger Schwachpunkt für RAG. Der Gemini-Layout-Parser ist hervorragend geeignet, um Daten aus komplexen Tabellen mit zusammengeführten Zellen und komplizierten Kopfzeilen zu extrahieren.
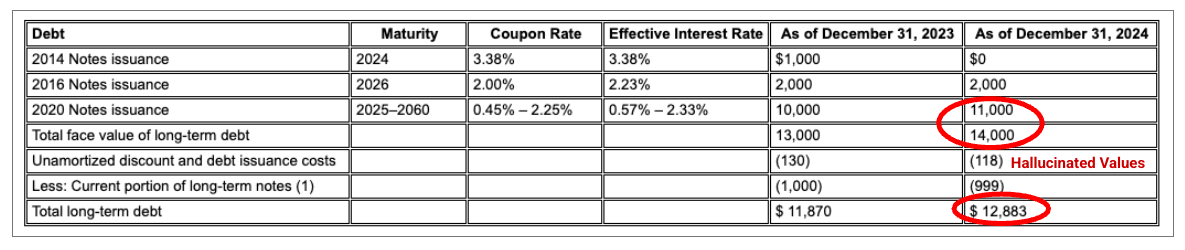
Beispiel: In dieser 10-K-Einreichung von Alphabet kann der Parser eines Mitbewerbers Header und Zellen nicht richtig ausrichten, wodurch die Finanzdaten falsch interpretiert werden. Der Gemini-Layout-Parser parst die gesamte Tabellenstruktur genau und bewahrt die Datenintegrität.
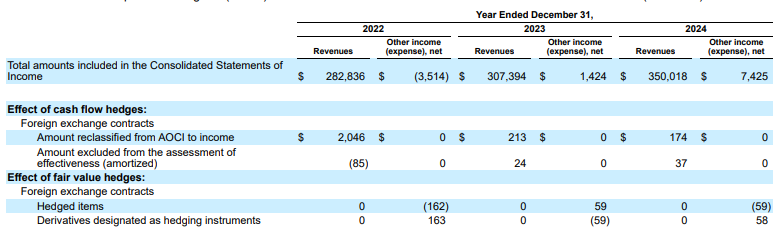
Abbildung 1. Die Quelle dieses Eingabedokuments ist Alphabet 2024 SEC Form 10-K, Seite 72.
Der Parser für Wettbewerber erkennt die Ausrichtung von Zellen und Spalten nicht richtig und halluziniert Werte.
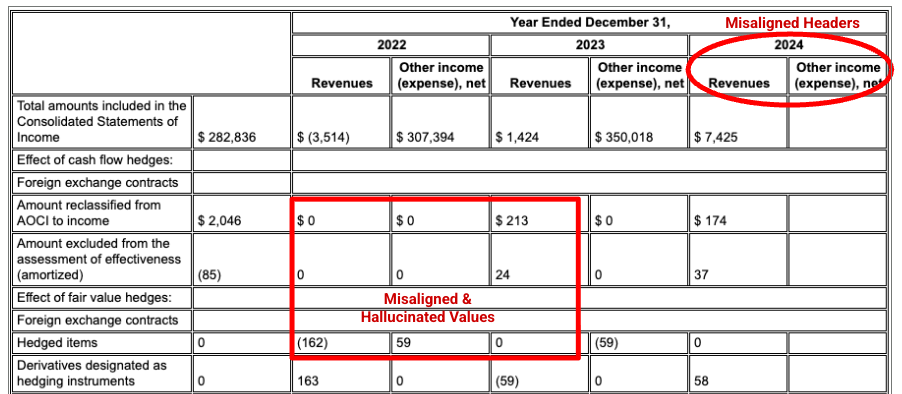
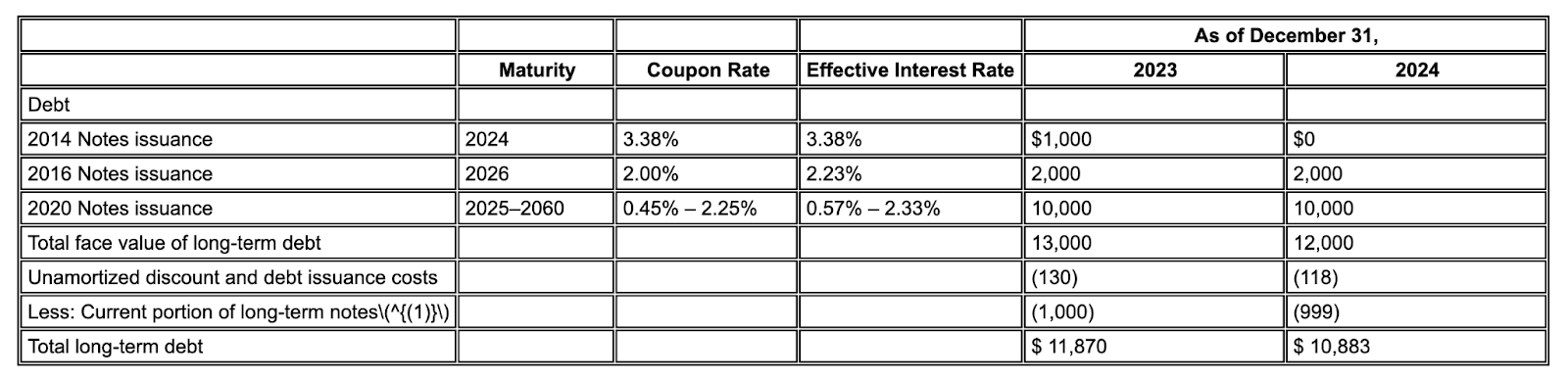
Der Gemini-Layoutparser richtet Spalten richtig aus und liefert genaue Werte.
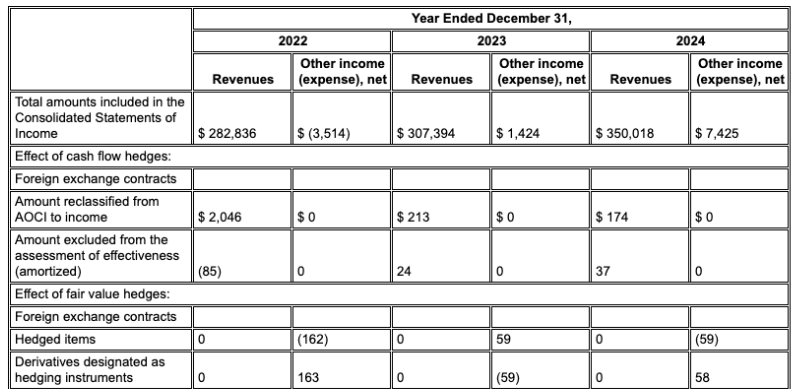
Weniger Halluzinationen
Im Gegensatz zu reinen LLM-basierten Parsern, die versuchen, nicht vorhandenen Text zu lesen, basiert der Gemini-Layout-Parser auf fortschrittlicher OCR und damit auf dem tatsächlichen Inhalt des Dokuments. Dies führt zu deutlich weniger Halluzinationen.
Beispiel: In diesem Auszug aus einem 10-K-Bericht halluziniert ein Konkurrenzmodell und fügt falschen Text ein. Der Gemini-Layout-Parser ermöglicht eine saubere und genaue Extraktion des Texts, der auf der Seite vorhanden ist.
Abbildung 2. Eingabedokument (Alphabet 2024 10k, Seite 75)
Bei Konkurrenzmodellen werden Werte halluziniert.
Der Gemini-Layout-Parser erkennt Werte in Bildern und Tabellen korrekt.
Layoutbezogene Segmentierung
Standardparser erstellen oft Chunks, die aus ihrem ursprünglichen Kontext entfernt werden, z. B. indem ein Absatz von seiner Überschrift getrennt wird. Der Gemini-Layoutparser versteht die Hierarchie des Dokuments. Es werden kontextsensitive Blöcke erstellt, die Inhalte aus übergeordneten Überschriften und Tabellenüberschriften enthalten. Ein abgerufener Chunk enthält nicht nur den Text, sondern auch den strukturellen Kontext, der für eine genaue LLM-Antwort erforderlich ist.
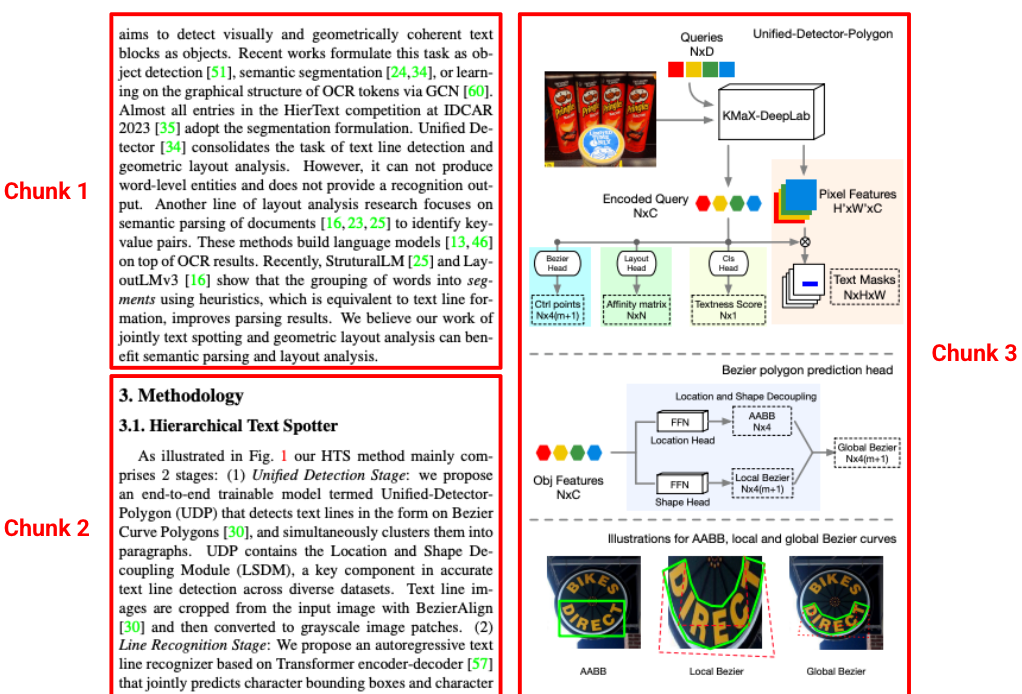
Abbildung 3. Die Quelle dieses Bildes ist „Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis“ von Shangbang Long, Siyang Qin, Yasuhisa Fujii, Alessandro Bissacco und Michalis Raptis.
Layoutanmerkung
Mit der Layoutparser-Anmerkung kann ermittelt werden, ob in geparsten Dokumenten Bilder oder Tabellen vorhanden sind. Wenn sie gefunden werden, werden sie als beschreibender Textblock mit den im Bild und in der Tabelle dargestellten Informationen annotiert.
Wenn beispielsweise ein Bankbericht verarbeitet wird, sieht der Parser nicht nur ein Bild. Es wird eine detaillierte Beschreibung generiert und die Datenpunkte aus allen drei Kreisdiagrammen werden extrahiert, sodass die Daten abgerufen werden können.
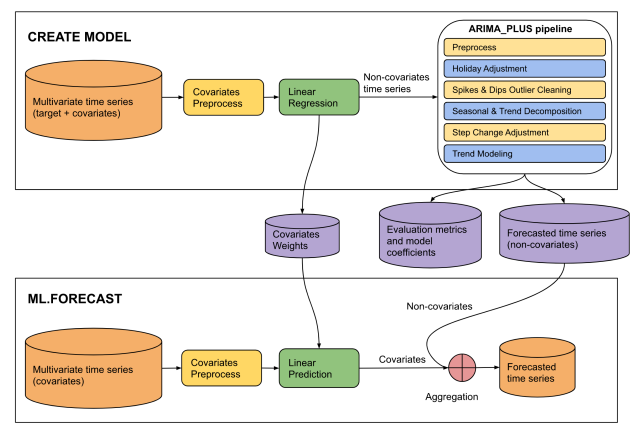
Abbildung 4. Die Quelle dieser Eingabe ist eine gespeicherte PDF-Datei von CREATE MODEL-Anweisung für ARIMA_PLUS_XREG-Modelle auf der Google Cloud-Website.
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
Beschränkungen
Es gelten folgende Einschränkungen:
- Onlineverarbeitung:
- Maximale Größe der Eingabedatei: 20 MB für alle Dateitypen
- Maximal 15 Seiten pro PDF-Datei
- Batchverarbeitung:
- Maximale Größe einer einzelnen Datei: 1 GB für PDF-Dateien
- Maximal 500 Seiten pro PDF-Datei
Layout-Erkennung nach Dateityp
In der folgenden Tabelle sind die Elemente aufgeführt, die der Layoutparser für die einzelnen Dokumentdateitypen erkennen kann.
| Dateityp | MIME-Typ | Erkannte Elemente | Beschränkungen |
|---|---|---|---|
| HTML | text/html |
Absatz, Tabelle, Liste, Titel, Überschrift, Seitenkopf, Seitenfuß | Das Parsen hängt stark von HTML-Tags ab. CSS-basierte Formatierungen werden daher möglicherweise nicht erfasst. |
application/pdf |
Abbildung, Absatz, Tabelle, Titel, Überschrift, Seitenkopf, Seitenfuß | Tabellen, die sich über mehrere Seiten erstrecken, werden möglicherweise in zwei Tabellen aufgeteilt. | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
Absatz-, Tabellen-, Listen-, Titel- und Überschriftenelemente auf mehreren Seiten | Verschachtelte Tabellen werden nicht unterstützt. |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
Absatz-, Tabellen-, Listen-, Titel- und Überschriftenelemente | Damit Überschriften richtig erkannt werden, müssen sie in der PowerPoint-Datei als solche gekennzeichnet sein. Verschachtelte Tabellen und ausgeblendete Folien werden nicht unterstützt. |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
Tabellen in Excel-Tabellen, die INT-, FLOAT- und STRING-Werte unterstützen |
Die Erkennung mehrerer Tabellen wird nicht unterstützt. Auch ausgeblendete Tabellenblätter, Zeilen oder Spalten können sich auf die Erkennung auswirken. Es können Dateien mit bis zu 5 Millionen Zellen verarbeitet werden. |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
Tabelle mit aktiviertem Makro, die die Werte INT, FLOAT und STRING unterstützt |
Die Erkennung mehrerer Tabellen wird nicht unterstützt. Auch ausgeblendete Tabellenblätter, Zeilen oder Spalten können sich auf die Erkennung auswirken. |
Nächste Schritte
- Sehen Sie sich die Liste der Prozessoren an.
- Benutzerdefinierten Klassifikator erstellen
- Verwenden Sie Enterprise Document OCR, um Text zu erkennen und zu extrahieren.
- Informationen zum Verarbeiten von Antworten finden Sie unter Batchverarbeitungsanfrage für Dokumente senden.